

AI做科学推理,可能不该总靠“把步骤写出来”。
过去几年,大模型一旦进入“推理模式”,几乎都会走同一条路线:
先输出一大段思维链,再给出最终答案。
这套方法在数学题、代码题、复杂问答里很常见,也确实有效。但到了化学场景,它未必还是最顺手的方式。

Haven团队叶新武、唐相儒等联合斯坦福大学丛乐、普林斯顿大学王梦迪最新提出的LatentChem,想做的就是一件事:
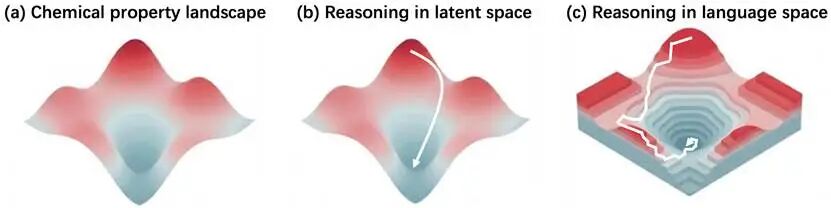
把化学推理从“文本表面”挪到“模型内部”。
模型不一定要把每一步都翻译成文字,也可以先在连续隐空间里完成多步计算,最后再输出自然语言。
这不是“取消推理”,而是换了一种推理介质。
用文字描述化学,为什么不够好?
做过分子优化、分子编辑、反应预测的人,大多见过这种情况:
模型前面能写得头头是道。
电子效应、位阻、官能团、反应位点,说得都很专业。
但到了最后,生成出来的SMILES或分子结构,却和前面的分析对不上。
看起来像是在认真思考,结果却经常“说一套,做一套”。
LatentChem论文给出的解释很直接:
化学推理本身,更像是在连续、结构化的空间中进行搜索、调整和更新;
而自然语言token,本质上是离散的。
当模型被要求把这些本来更适合在连续表征中完成的过程,硬拆成一句一句自然语言时,就会出现论文提出的那个核心问题:
continuity–discretization gap
简单说,本来应该在连续空间里顺滑完成的化学推理,被强行切成了一格一格的文本步骤。
这不仅慢,还容易让“推理描述”和“最终结果”脱节。
LatentChem在做什么?
LatentChem的核心思路可以概括成一句话:
先在隐空间里思考,再在语言空间里回答。
它并不是简单把CoT删掉,而是重新设计了化学推理发生的位置。
整个系统大致可以理解为四步:
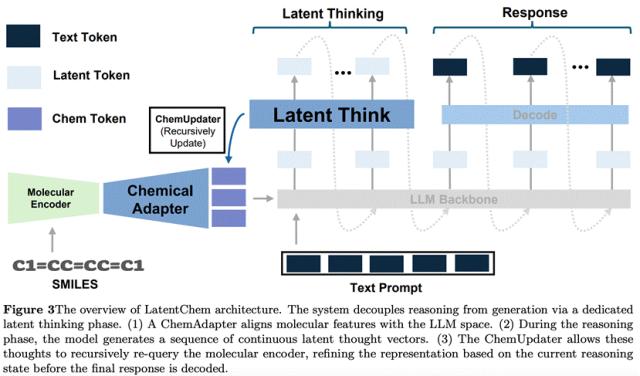
1、先把分子信息变成模型能用的“软提示”
LatentChem先通过分子编码器提取结构表示,再把它压缩成固定数量的ChemTokens。
这些ChemTokens会和文本指令一起送进模型,相当于先把分子上下文交给模型。
2、真正的中间推理,不再主要靠文字完成
和传统CoT一步步生成文本不同,LatentChem会在隐空间里生成一串latent thought向量。
这些向量不是“解释给人看的思路”,而是模型内部真正用于推进推理的中间状态。
3、推理过程中,模型还能不断“回看分子”
这是LatentChem很关键的一点。
它不是把分子读一遍就开始闭门推理,而是通过一个叫ChemUpdater的模块,让每一步latent thought都能重新作用到ChemTokens上。
换句话说,模型在推理过程中可以不断回看分子表示,动态聚焦到不同关键信息上。
4、把内部状态继续映射回下一轮推理输入
通过Latent Projector,模型可以把当前隐状态再映射回可继续迭代的输入空间,形成多步连续更新的闭环。
一句话概括就是:
LatentChem把“推理”和“表达”拆开了
推理先在内部完成,再依托语言进行输出。
更有意思的是:模型不是被强迫“别写CoT”,而是自己慢慢不写了
这篇论文里,最有意思的观察之一,发生在强化学习阶段。
作者采用GRPO训练时,
奖励并不关心模型有没有写出漂亮的思维链,也不要求解释过程多完整。它只看结果:
- 输出格式对不对
- 答案是不是有效
- 最终结果准不准
结果出现了一个很有代表性的现象:
模型会自发减少显式CoT。
它通常先在内部完成latent thinking,然后只输出一个极短的过渡符号,比如“.”或者“:”,接着直接给答案。
这说明什么?
说明一旦训练目标不再明确鼓励“把推理写出来”,模型就会自然把主要计算留在内部完成。
它不是不思考了,而是不再依赖把思考全部说出来。
这不是“偷懒”,论文还专门做了验证
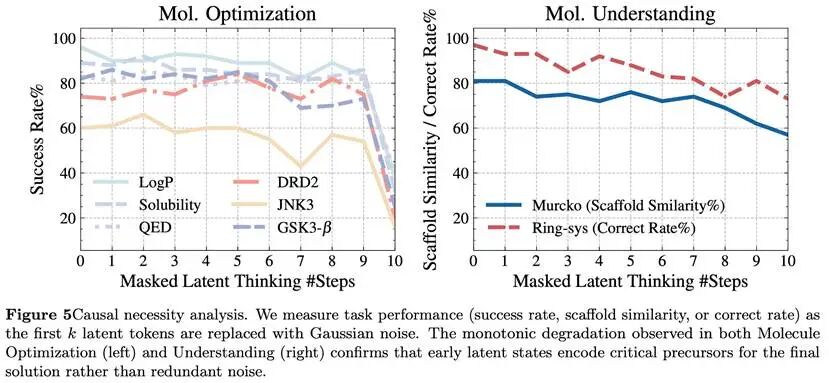
为了证明latent thinking不是摆设,论文还做了一个很关键的实验:
研究团队把前面若干latent steps用高斯噪声替换,然后观察模型表现。
结果发现,被替换掉的latent steps越多,模型性能下降得越明显。
这意味着,这些latent states并不是无关紧要的中间变量,而是真的承载了推理所需的关键信息。
也就是说:
显式CoT少了,不等于推理少了。
很多推理,其实只是被“收进去了”。
还有一个细节特别值得注意
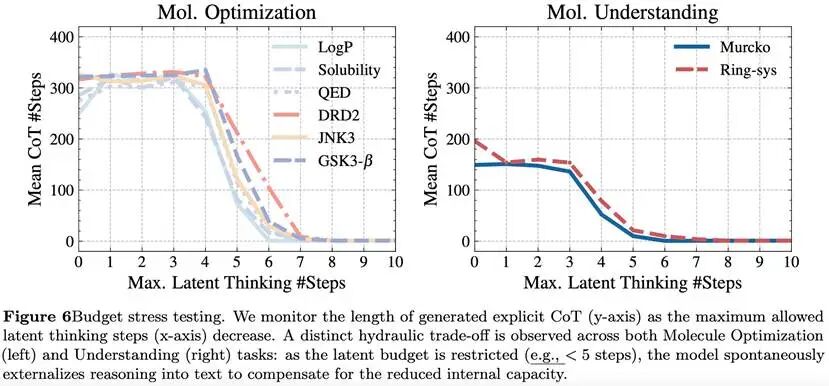
LatentChem并没有学成一个死规则。
如果它只是简单“禁止输出CoT”,那模型就应该始终不写长推理。
但论文观察到的现象更微妙:
当latent thinking的预算不够时,模型会重新把部分推理写出来。
也就是说,如果给它足够的内部推理空间,它就更多在隐空间里完成思考;
如果内部预算被压缩,它就会重新启用显式文本推理来补足能力。
这其实很重要。
它说明LatentChem学到的不是“别写”,而是一种更灵活的分配策略:
能在内部算,就尽量内部算;内部不够,再把一部分外显成文字。
所以,这项工作的真正意义,不是“让模型闭嘴”,而是证明:
CoT只是推理的一种外在表现,不一定是推理本体。
不只是快,而且更准
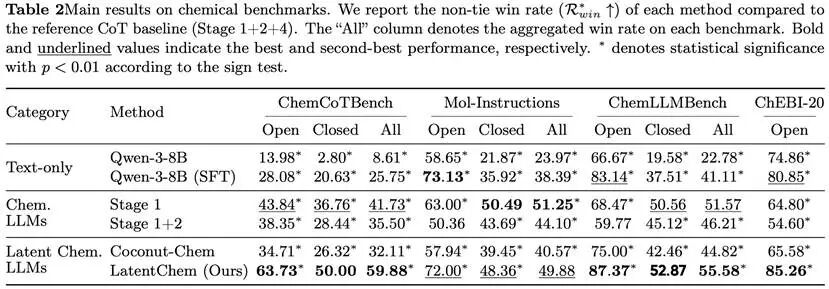
这种“只做不说”的内部推理范式,带来了实打实的性能红利。在各大化学基准测试中,LatentChem交出了亮眼的答卷:
在高度依赖推理的ChemCoTBench测试中,面对强大的显式CoT基线模型,拿下了高59.88%的非平局胜率。
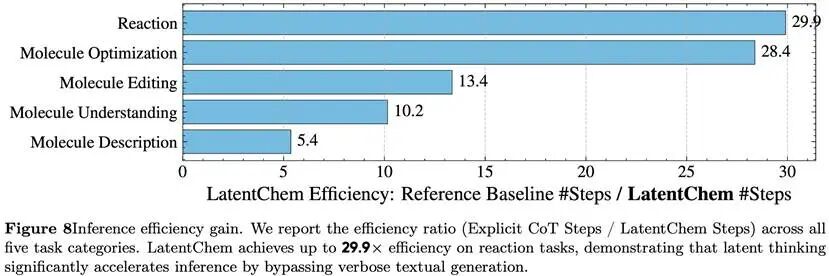
通过将啰嗦的文本转化为紧凑的隐状态,大幅破除了生成延迟的瓶颈,平均推理速度暴涨10.84倍。在特定的反应任务上,效率甚至飙升了近30倍。
对于致力于打造未来AI Scientist的团队而言,LatentChem证明了一件事:显式的自然语言可能只是科学推理的一种外壳。把沉重的逻辑计算收回到隐空间中,不仅打破了效率与深度的权衡悖论,更为下一代科学AI奠定了更符合底层规律的计算基础。
从LatentChem到AI Scientist
对Haven来说,LatentChem的意义并不仅仅是一个新的化学模型。它更像是AI Scientist系统的一块关键组件。
Haven正在构建能够自动执行科学工作流的AI系统,包括:
- 分子设计
- 文献分析
- 实验规划
- 假设生成
- 结果验证
在这些复杂任务中,推理往往发生在结构化的连续空间,而不是自然语言中。
LatentChem展示了一种新的可能:让AI在隐空间中完成科学推理,再在需要时输出可解释结果。
同时,LatentChem提出了一个值得思考的问题:显式CoT是否只是推理的一种外化形式,而不是推理本身?
LatentChem展示的并不是“去掉推理”,而是:把推理从文本表面,收回到模型内部。
未来的AI Scientist,或许不会把每一步思考写出来,
但它们仍然在持续推理、探索和发现。
只是这些推理发生在隐空间中。
论文标题:LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning
论文链接:https://arxiv.org/abs/2602.07075
代码链接:https://github.com/xinwuye/LatentChem
