

到2025年末,AI编程已经全面从辅助工具Copilot,转向以AI为主、人类监督的Agent时代。
如果只是写一段函数、修一个孤立的Bug,现在的顶尖模型几乎能给出满意的答案。
然而随着2026年初OpenClaw的兴起,Agent又开始从执行单一任务的会话,演进为长周期运行的系统。要想从能用、好用,到最终替代并超越人类,AI必须依照需求与环境,持续自主迭代一切与真实世界交互的软件接口。

然而,这一愿景落地的最大障碍,恰恰在于真实软件开发并非一次性的代码生成,而是一场关于时间与复杂度的持久博弈。代码库会随着需求变更不断膨胀,早期埋下的隐患也可能在数月后被放大为系统性风险。当开发跨越多个大版本,AI真的能在这种持续演进中保持可靠吗?
最近,USC邓港大、UCR陈炤伶、Stanford丛乐、Princeton王梦迪、Haven唐相儒、OpenHands王星尧等联合发布了全新的重磅评估基准EvoClaw。研究团队从开源项目中提取真实的代码演进历史,并将其重构为里程碑任务依赖图(Milestone DAG)。它将零散的提交聚合为功能内聚的里程碑,并严格保留了任务间的代码时序依赖。

基于这一全新基准,研究发现,一旦脱离“单点修复”,进入“持续演进”的真实开发场景,AI的表现就会出现断崖式下跌(从得分>80%到最高不到40%)。这意味着AI距离真正胜任长期、连续、自主的软件演进工作,仍有明显差距。
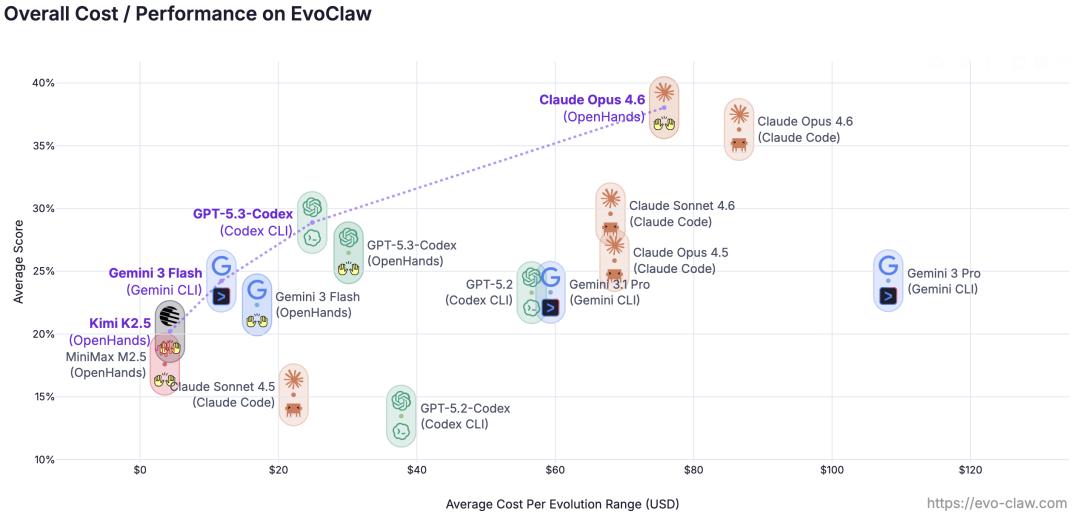
EvoClaw各模型框架综合性能(y轴)与推理开销(x轴)总览
编程评测2.0:从单点修复到持续演进
为什么现有的AI编程评测(如SWE-bench)往往会高估Coding Agent的真实能力?
过去几年,编程benchmark的重点大多放在“独立任务”上:修一个issue、完成一个大PR,然后在一个相对静态的代码快照里验证结果。这种评测方式当然有价值,但它天然会弱化一个关键的问题:软件工程从来不是独立任务的集合,而是一个持续演进的过程。前面的实现选择,会约束后面的开发空间;早期留下的小问题,也可能在后续版本里不断放大。
论文指出,现有评测普遍忽略了软件演进的时间维度,经常导致很多AI刷榜分数都虚高,但真正上手开发时,立刻原形毕露,差距一下就被拉开。
EvoClaw在评测设计上做出了一个关键调整:它要求AI必须在同一个代码库中连续执行多个相互依赖的任务。除了外部提供任务需求,其余的一切开发维护都由AI自主完成。这种“开发环境持久化”的设计,直接揭示了AI在连续自主迭代场景下的脆弱性。
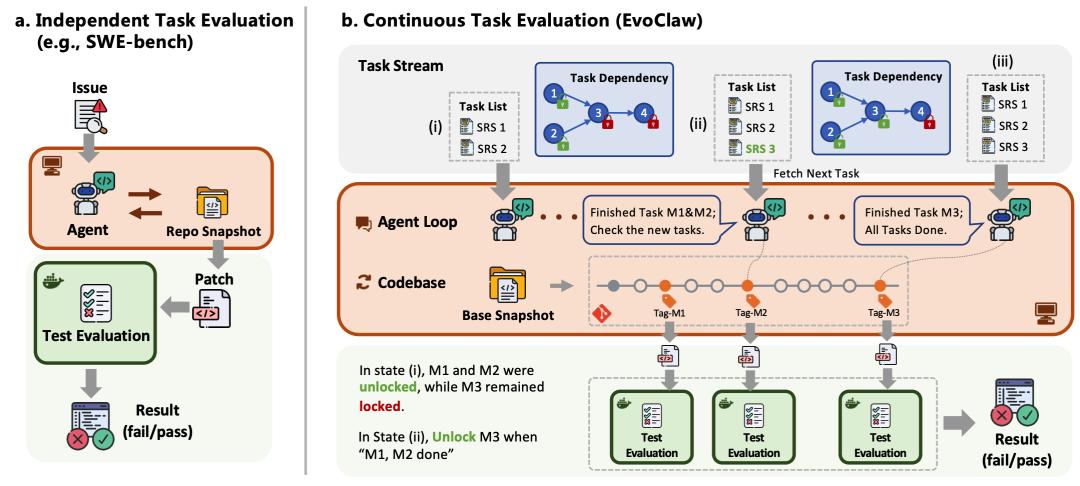
独立任务(例如SWE-bench)与持续演进(EvoClaw)的评测范式对比
DeepCommit:用Agent重建软件演进的“里程碑”
一个很重要的问题是,如何从现有的软件项目中提取出演进历史?研究团队没有直接使用现成的commit、release粒度来切分任务,而是提出了里程碑(milestone)这一层级。
原因很简单:单个commit往往太碎,包含大量琐碎修改,难以代表一个完整的开发目标;而release又太粗,会把大量中间依赖和演进路径压缩掉。
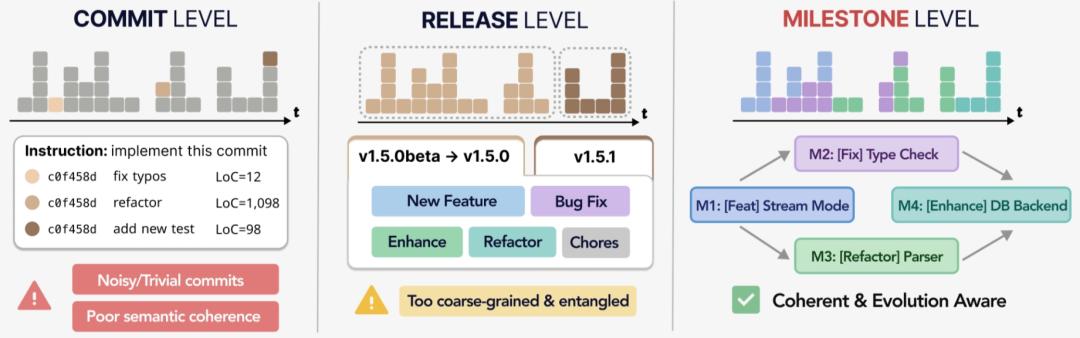
Commit、Release、Milestone三种粒度对比,Milestone在语义完整性与依赖保留之间取得平衡
milestone则被定义为“语义上完整、同时保留演进依赖关系的功能单元”,更适合作为评估AI代码演进能力强弱的任务粒度。
围绕这个思路,论文进一步提出了DeepCommit,一个Agent驱动的自动化流水线,把原本噪声很大的git历史重构成可验证的Milestone DAG。
第一阶段:静态分析与去噪(Preprocessing)
首先过滤掉与核心功能无关的修改(如文档、CI/CD配置等),并通过静态分析提取出代码行级别和符号级别的commit间依赖关系,为后续的图构建打下基础。
第二阶段:Agent驱动的DAG构建(DAG Construction)
大模型Agent充当“架构师”,通过四个子步骤来重构历史:首先寻找具有开创性的“种子”提交;然后将语义相关的提交聚拢并合并为一个完整的Milestone;接着推理出它们之间的依赖关系;最后动态拆分过大的Milestone以保证颗粒度均匀。
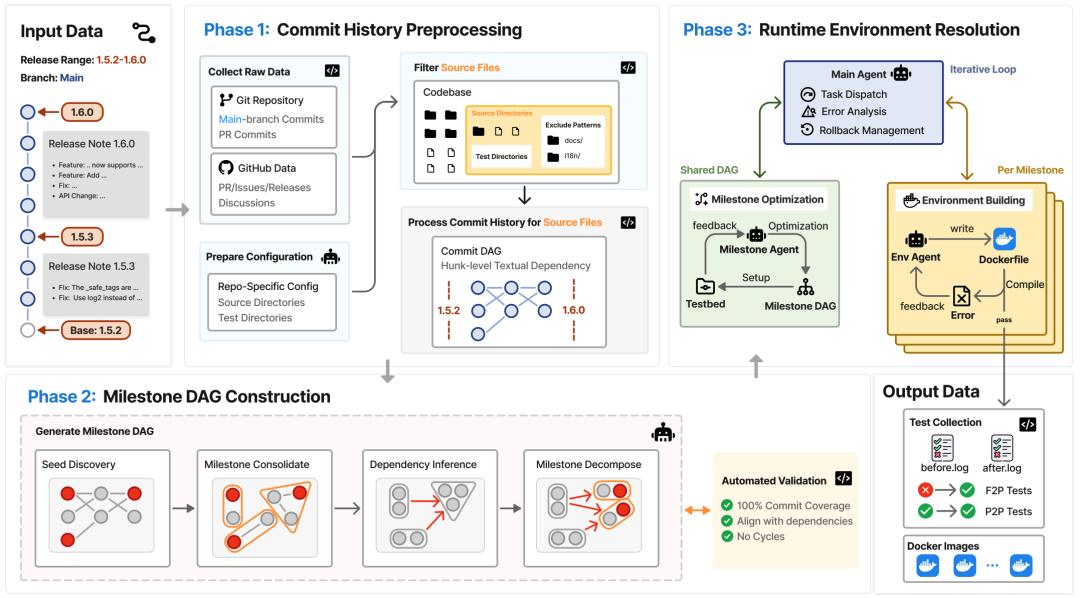
DeepCommit流水线架构图,展示如何从原始提交中提取Milestone DAG
第三阶段:基于Agent的运行环境解析与验证(Runtime Resolution)
纸上谈兵的图谱没有意义,真正的难点在于如何让重构后的演进历史在真实环境中跑通。
由于新的Milestone DAG打乱了原本Git时间线,当按照新拓扑顺序重新应用Commit时,容易遭遇接口不匹配、编译大面积报错的惨状。如果简单粗暴地跳过报错模块,又会导致测试用例收集率暴跌,失去评测价值。
为此,研究团队设计了一套“迭代式修复循环”。面对编译失败,Agent会主动分析报错日志,动态修改Dockerfile确保可执行;更关键的是,它会顺藤摸瓜地在原有Milestone DAG的基础上补充原本遗漏的隐式依赖,通过调整Milestone的先后制约关系来彻底解决接口冲突。
通过不断迭代修复,最终确保能收集到至少85%的原有测试用例,为评估提供充足的测试基础。
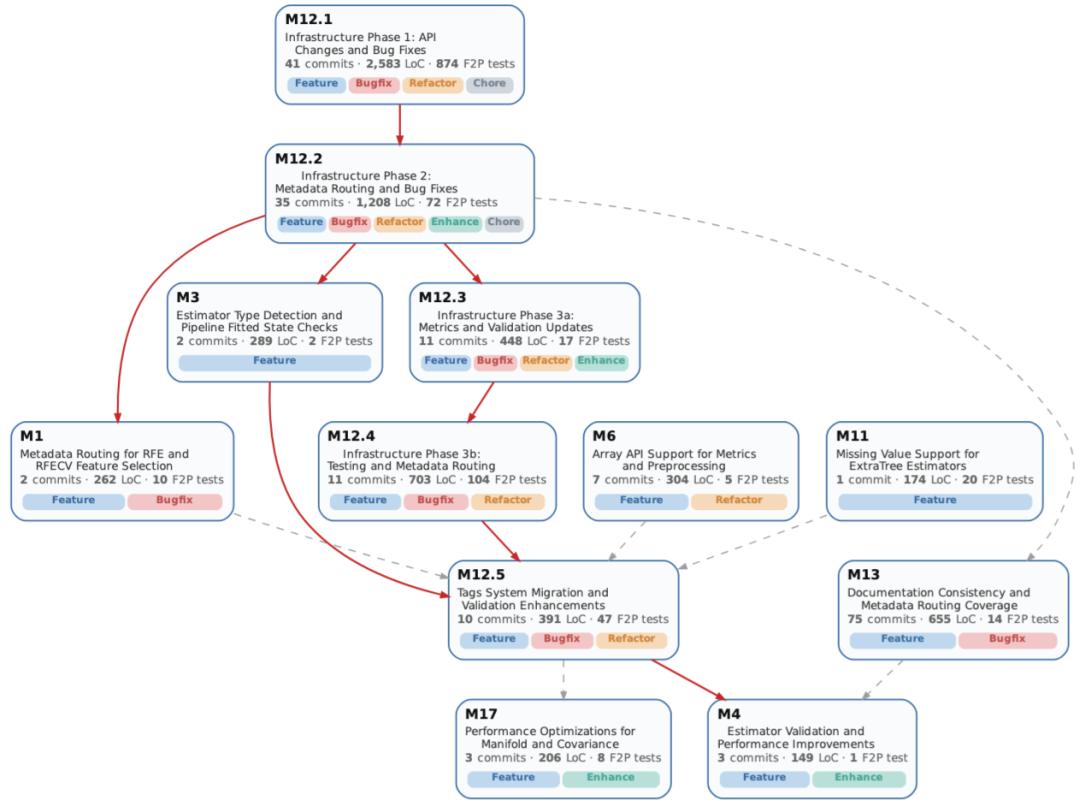
scikit-learn仓库1.5.2 → 1.6.0 release区间的DeepCommit Milestone DAG示例
值得一提的是,论文作者还对比了DeepCommit自动生成的演进图与人类专家手动标注的演进图。结果非常有趣:人类专家倾向于按照“战略意图(如重构、兼容性)”进行自上而下的语义划分;而DeepCommit则展现出了截然不同的底层逻辑——它完全基于代码层面的真实依赖关系,以自下而上的拓扑思维重组了软件演进的骨架。
这套严苛的自动化流水线,成功保证了最终筛选的所有Milestone任务都是100%标注出前置依赖且真实可执行的。
EvoClaw:把“持续演进”真正纳入评测
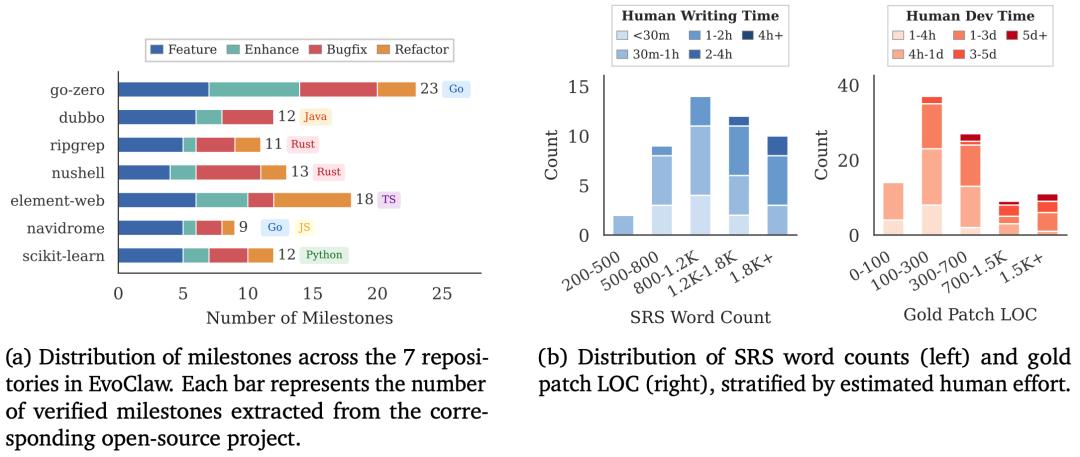
为了确保评测需求明确,作者利用Agent基于正确代码(Gold Patch)为每一个Milestone逆向生成了软件需求规格说明书(SRS),并严格对齐验收测试。随后由人类专家逐一校验,确保未泄露实现细节,且任务绝对可解,同时剔除了所有不稳定的测试用例。
最终得到的EvoClaw覆盖5种主流编程语言,每个项目均选取横跨多个release区间的真实开发周期(最长750天)。同时整体开销也控制在合理范围内,以Claude Opus 4.5为例,完整运行一次数据集的成本约为500美元。
EvoClaw数据集概览
因此,EvoClaw没有简单粗暴地只看单一的通过率,而是额外加入两个核心维度来评估Agent表现:
Recall(召回率):衡量功能实现的完备性。即在目标任务要求的变更中,Agent到底搞定了多少。
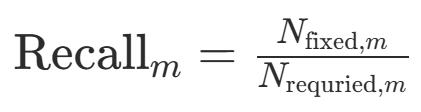
Precision(精确率):衡量修改行为的可靠性,量化Agent在“实现新功能”的同时“破坏了多少旧代码”
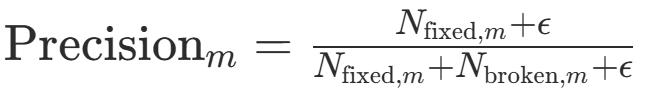
最后,评测将这两个指标通过F1加权平均为综合得分Scorem,作为每个milestone的分数。
持续演进场景下,模型表现显著下滑
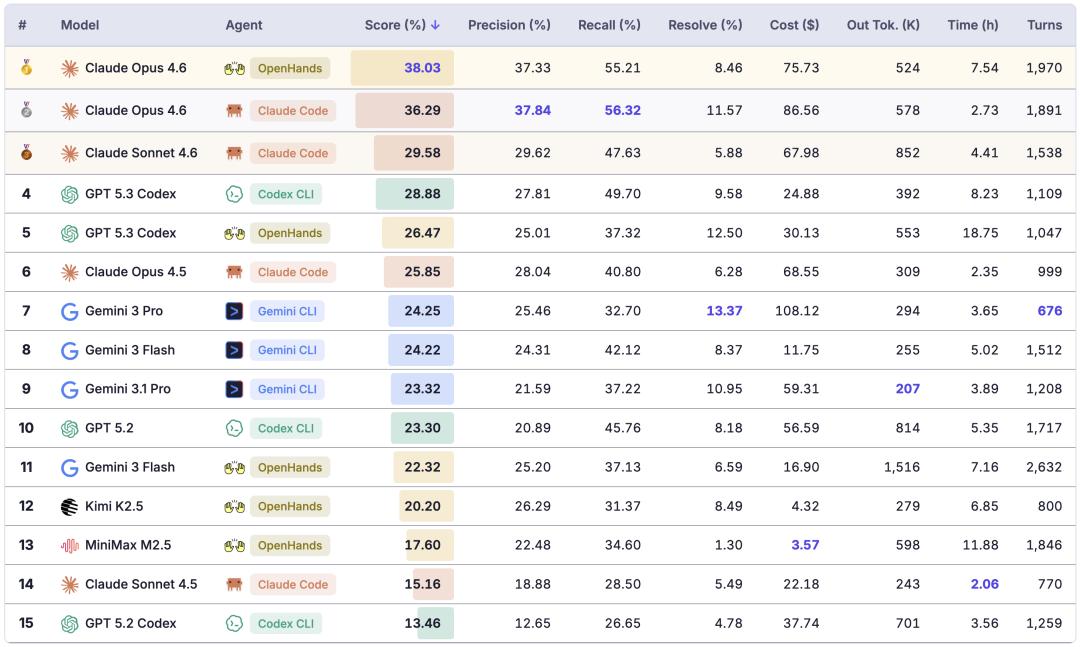
EvoClaw主要实验结果
论文测试了Claude Code、OpenHands等多种框架与模型组合。当任务是独立评测时,顶尖模型的得分普遍在80%~90%。然而,一旦进入EvoClaw的“持续演进”模式:
综合得分(Score):最高分(Claude Opus 4.6)仅为38.03%。
完整解决率(Resolve Rate):最高仅有13.37%(Gemini 3 Pro),而且模型能正确实现的,绝大部分都只是那些没有前置依赖的任务。
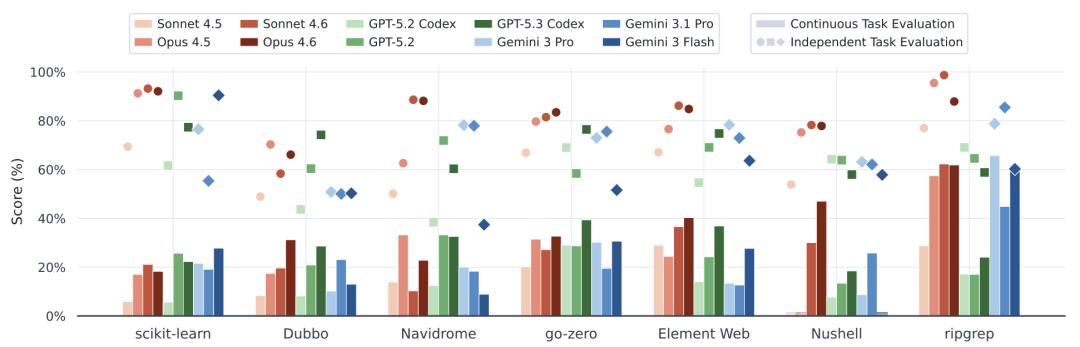
各软件项目得分对比,连续评测(Continuous,条形图)vs.独立评测(Independent,散点图)
GPT-5.3-codex以28.88%的综合得分位居第二,仅次于Claude Opus 4.6,但开销不到后者的三分之一。不过,分仓库来看,5.3-codex在Rust项目(Nushell、ripgrep)上表现较弱,拖了后腿,在其余仓库上则能接近甚至超过Opus 4.6。
不可避免的演进停滞:Recall持续增长,但Precision很快饱和
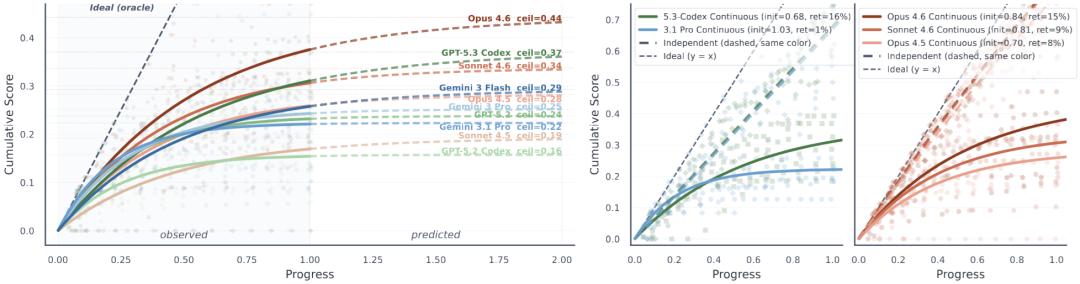
用饱和函数拟合各模型的演进动态。左:外推各模型在无限开发窗口下的性能上界;右两图:连续评测下得分趋于饱和,而独立评测得分仍随任务数量线性提升。
面对连续评测中分数的断崖式下跌,我们不得不直面一个核心问题:如果在真实的业务场景里,给大模型无限的迭代窗口,它最终能把项目100%搞定吗?
论文给出了否定的答案:无论迭代多少次,所有模型的表现最终都会撞上天花板,陷入实质性的演进停滞。任务的执行顺序越靠后、所处的DAG层级越深,分数和解决率就越低。
研究团队基于饱和函数进行的外推显示,即便是表现最优的Opus 4.6,其累计分数也会被卡死在45%左右的渐近线上限无法突破。
从演进曲线来看,Gemini 3.1 Pro起步最快,但很快遭遇瓶颈;GPT-5.3-codex则凭借最佳的“留存率”后来居上,展现出更佳的长尾表现;而Claude系列表现最为稳健,其连续演进能力随着版本迭代稳固提升。
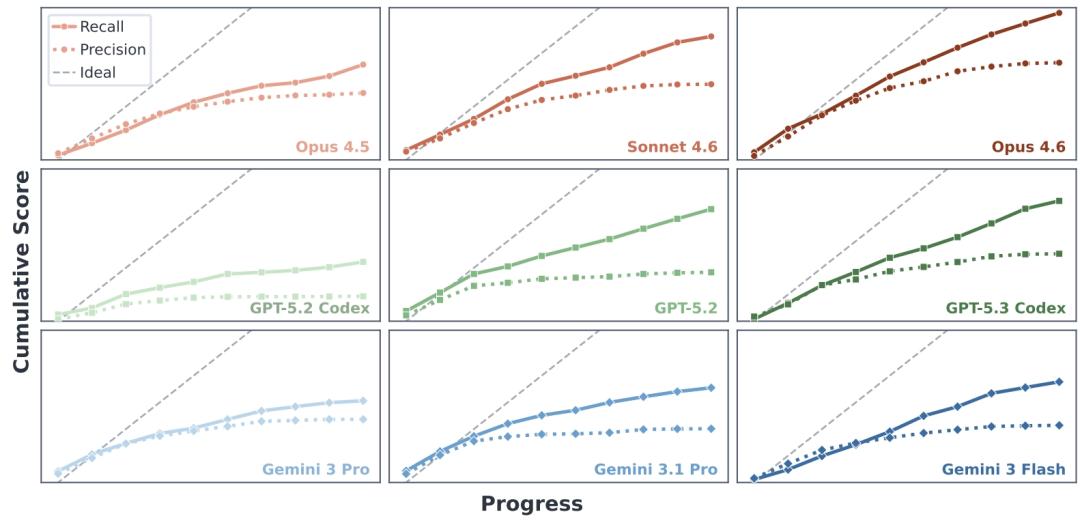
Recall(实线)持续增长,Precision(虚线)很快饱和
为了分析背后原理,论文将综合得分拆分回两个指标:Recall(召回率,代表新功能实现的完备度)与Precision(精度,代表对现有系统稳定性的保持)。
令人意外的是,前沿模型的Recall曲线保持着近乎线性的健康增长。这意味着哪怕代码库在经历多次迭代后变得脏乱,面对新下达的需求,模型仍然能一样准确的生成对应功能的代码,其基础编程能力没有衰退。
相较而言,所有模型在维持系统稳定性上还有较大缺陷,Precision曲线容易快速饱和,是导致停滞的元凶。
错误链分析:技术债是如何“滚雪球”的?
为了深入理解模型为什么会在迭代中失控,论文提出了一个核心洞察:错误链(Error Chains)的累积效应。
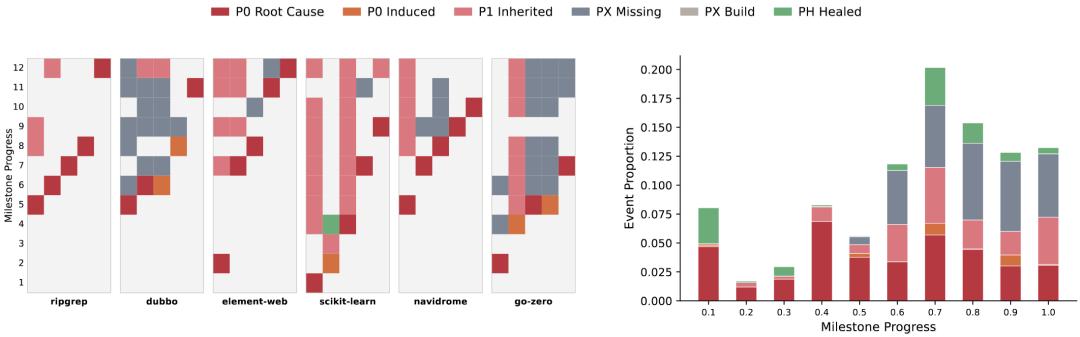
(左图))错误链示意图,(右图)错误链分布
“错误链”的分析方法,就是跟踪一个测试从首次出错开始,到后续milestone中观察错误是被继承、扩散、跳过还是修复。
结果显示,随着项目进展,新问题的产生速度不会加快,而且模型还会实质性的被动修复历史错误。
然而,前置错误的累积速度,远远超过了它的修复速度,最终陷入了一场“技术债破产”。
Agent的行为模式
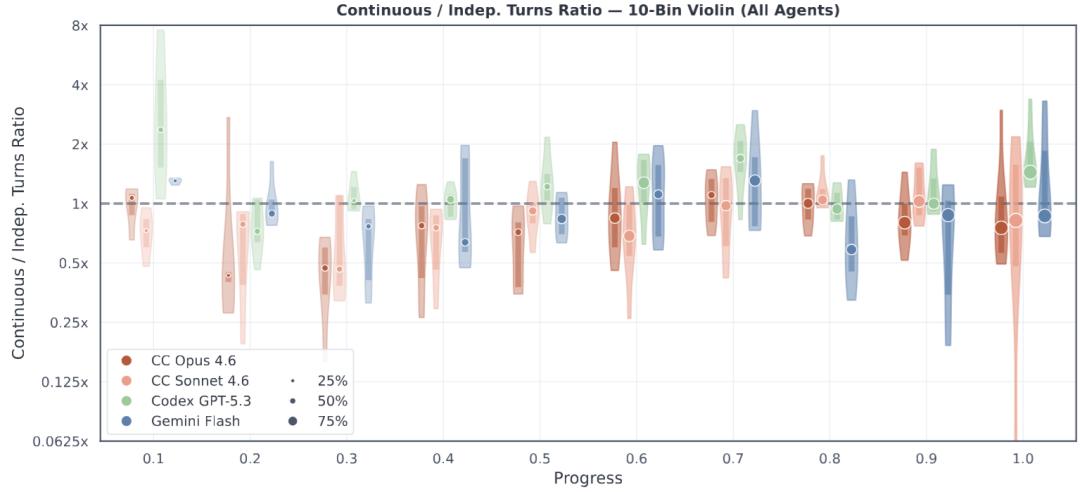
Agent effort投入的随进展变化趋势
从交互次数(effort)分配的时序规律来看,所有模型均呈现相似趋势:
- 项目初期需要花较多精力熟悉代码库,建立整体认知;
- 前中期因能复用已有上下文,效率反而最高;
- 进入中后期,错误积累带来大量调试负担,投入骤升;
- 而临近项目收尾时, 行为开始明显分化,变得极端 ——部分Agent陷入疯狂thrash,另一些则提前放弃。
其中,GPT-5.3-Codex在项目演进中的effort分配最为稳定。
总结:AI编程下半场,从“代码生成”到“系统治理”
EvoClaw的发布提醒我们,写出代码只是起点,能在长周期的系统演进中严格遵循需求,并维持整体稳定,才是真正踏入软件工程的门槛。
目前,前沿模型的核心局限在于:它们更接近一个按需生成代码的会话工具,而非人们所期望的、对项目全貌了然于胸的资深工程师。它们按顺序执行任务、只关注眼前需求、只会被动打补丁,缺乏全局统筹与历史上下文的贯通,更害怕主动发起重构来偿还技术债。
此外,各家模型在这一关键领域,分化已经十分明显。GPT和Claude系列在版本迭代中,持续演进能力稳步提升;而Gemini 3 Flash → 3 Pro → 3.1 Pro却陷入了单点能力不断攀升、持续演进却未见长进的窘境。国产模型方面,尽管在现有独立评测的编程榜单上已接近Opus 4.6的水平,但在EvoClaw的连续演进评测中,与上一代Opus 4.5相比仍有明显差距,仍需加强补齐”系统治理”这块短板。
这些发现也指向了未来突破的关键方向:主动重构、全局规划、长期记忆——唯有让Agent从被动的代码生成器进化为具备大局观的资深工程师,AI编程的下半场才真正开始。
论文标题:
EvoClaw: Evaluating AI Agents on Continuous Software Evolution
论文链接:
https://arxiv.org/pdf/2603.13428
项目主页:
evo-claw.com
代码链接:
https://github.com/Hydrapse/EvoClaw
