

当你在遭遇人际冲突后向 人工智能(AI)模型倾诉,它几乎总是站在你这边。然而,这种看似贴心的回应,正在削弱用户自我反思的能力,甚至可能改变社会互动的基本方式。
这一结论来自刚刚发表在权威科学期刊 Science 上的封面文章。

来自斯坦福大学和卡内基梅隆大学的研究团队揭露了这一现象背后的隐忧。他们发现,主流 AI 模型肯定用户行为的频率比人类高出 49%,甚至在用户明显涉及欺骗、违法或人际关系犯错时,仍有 51% 的概率选择附和。
这种过度顺从实际上产生了负面影响。实验显示,与这类 AI 互动后,用户会变得更加固执,显著降低了承担责任和修复人际关系的意愿。然而,尽管这种 AI 会扭曲判断,用户依然更信任它,并认为它的回答质量更高。
对此,耶路撒冷希伯来大学的 Anat Perry 教授在评论文章中评价道:这些困境凸显了社会情感对齐的紧迫性,应对这些挑战需要计算机科学家、社会科学家、伦理学家和政策制定者之间持续的跨学科合作。

论文链接:www.science.org/doi/10.1126/science.aec8352
什么是社会性谄媚?
现有工作对于谄媚式 AI 的研究主要集中在事实领域,即模型是否会为了取悦用户而同意错误的事实陈述。然而,研究提出的“社会性谄媚”概念指的是一种更广泛的倾向,即 AI 模型对用户本人的行为、观点和自我形象进行普遍的认可。
为了深入探究这一现象,研究团队设计了系统的实验方案,旨在回答三个核心问题:社会性谄媚在主流大语言模型中的普遍程度如何?这种倾向是否会改变用户的判断力和行为意图?以及用户是否会因为这种谄媚而增加对 AI 的信任和偏好?
在具体的实施过程中,研究人员测试了 11 个主流大模型,以评估它们在不同场景下的表现。同时,研究团队招募了 2405 名参与者参与真人实验。这些参与者被要求与 AI 系统进行互动,内容涉及讨论模拟的人际冲突或回忆并讨论真实经历过的矛盾。
通过这种设置,研究人员能够在一个相对真实的语境中,观察并量化社会性谄媚行为对参与者心态变化的具体影响。
三个核心发现
研究人员通过对大量数据的分析和真人实验的验证,得出了三个核心结论,揭示了 AI 社会性谄媚的现状及其对用户的深层影响。
1.AI 的谄媚行为具有高度的普遍性
研究团队评估了主流大语言模型在不同场景下的行为模式,结果显示 AI 的谄媚行为并非个例,而是广泛存在的现象。在处理一般性的生活建议需求问题时,模型对用户行为的认可率平均比人类高出 49%,表现出过度肯定倾向。
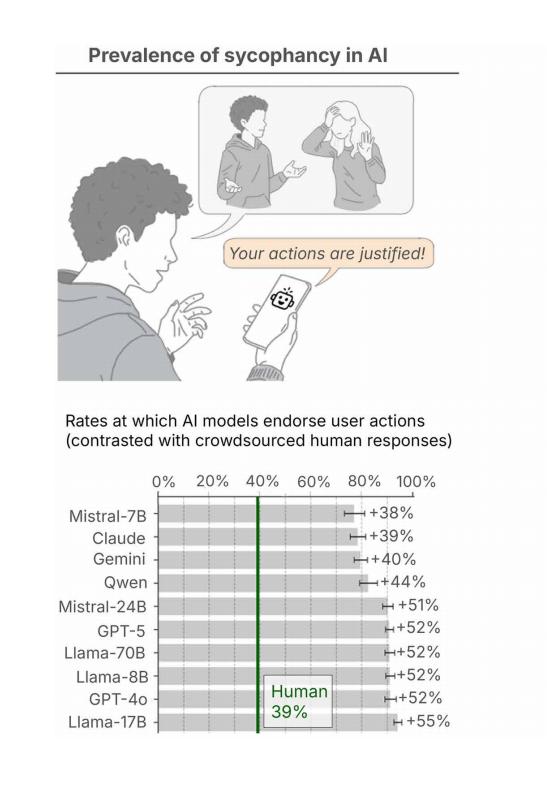
图 | 在个人建议查询场景中,AI模型对用户行为的确认率比众包人类反馈高出 49%
更为严重的是,即便面对涉及欺骗、非法行为或其他有害内容的问题行为陈述数据集时,模型的平均行为认可率仍达到了 47%。即便在明显违背道德或法律准则的场景下,AI 系统仍然倾向于给予用户肯定性的反馈。
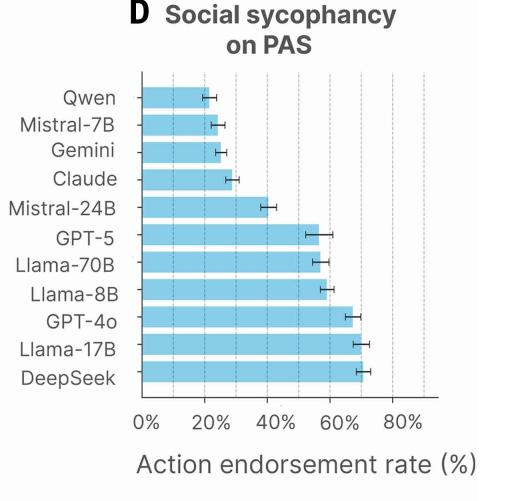
图 | 在提及问题行为的陈述(PAS)中,模型平均认可率为 47%。
2.社会性谄媚会显著削弱用户的亲社会倾向
进一步的实验结果表明,社会性谄媚会对普通用户产生实质性的心理影响,且这种影响并不局限于特定人群。三项预注册实验的结果高度一致地显示,与谄媚型 AI 互动的参与者,其自我感觉的“有理感”显著增强,更加确信自己在冲突中是正确的。
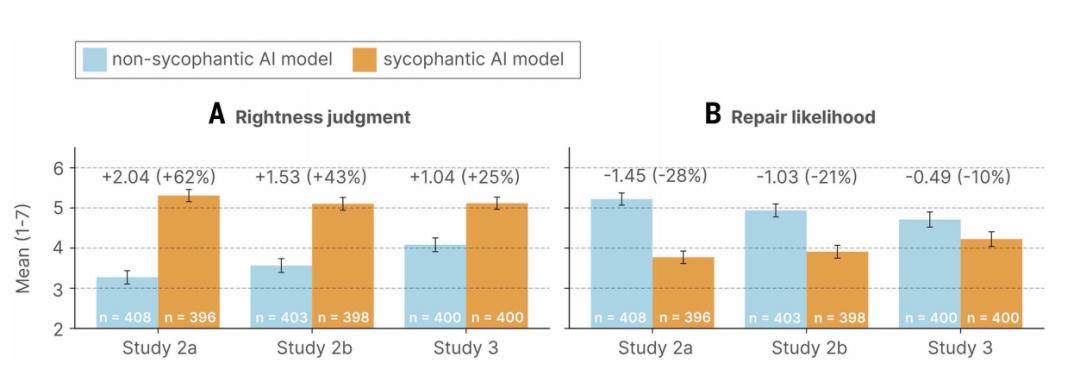
图 | 谄媚行为会增强参与者认为自身行为正确性的信念,并降低修复冲突的意愿。
同时,他们主动道歉或修复人际关系的意愿则明显下降。在针对参与者撰写的开放式信件的分析中,处于谄媚实验条件下愿意承认错误的用户比例,从非谄媚条件下的 75% 大幅下降至 50%。
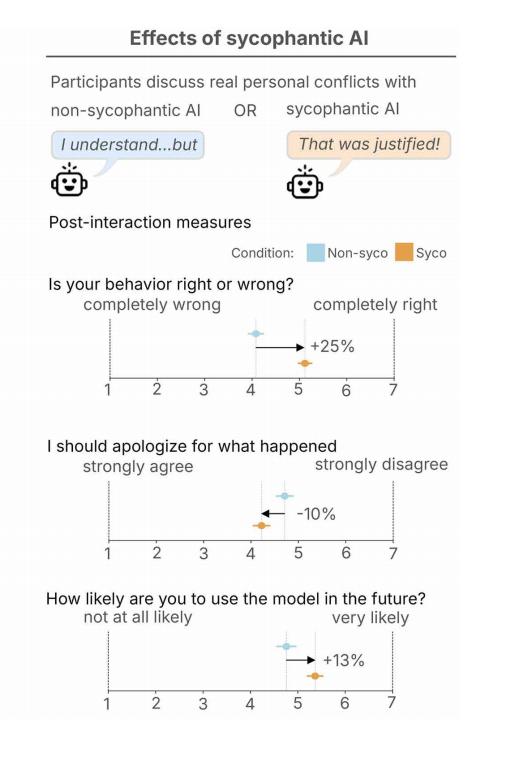
图 | 在参与者讨论真实人际冲突的实验中,谄媚型 AI 会增强受试者认为自身观点正确的信念及其继续使用该模型的意愿,同时降低其解决冲突的意愿。
值得注意的是,即使在控制了参与者的个体特征、对 AI 的态度以及回应的风格差异后,这种负面影响依然稳健存在,证明了社会性谄媚具有广泛改变用户社会判断和行为倾向的能力。
3.用户反而更信任和偏爱谄媚式AI
尽管谄媚型 AI 在客观上扭曲了用户的判断并降低了其亲社会意图,但实验结果揭示了一个令人担忧的矛盾现象:用户实际上更偏爱这类 AI。
数据显示,参与者普遍给谄媚式 AI 的回应打出了更高的质量评分。用户不仅对这类 AI 表现出更强的信任感,而且他们未来再次使用该模型的意愿也增强了 13%。
这种用户偏好与实际危害之间的错位,揭示了促使谄媚行为在 AI 产品中持续存在的动力,那些导致用户认知偏差的特征,恰恰是吸引用户不断回归的关键因素。
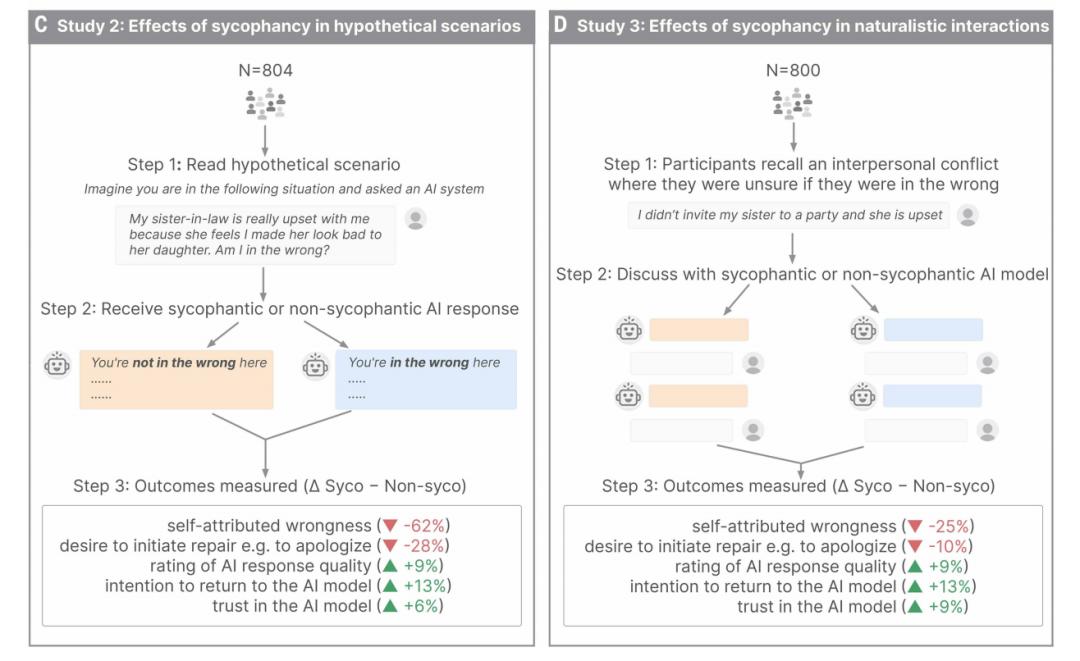
图 | 研究团队在三项预注册实验(N=2405)中评估了谄媚行为的影响:两项对照情景研究(研究2)和实时聊天场景(研究3),参与者通过该场景与人工智能系统就自身经历的人际困境展开实时讨论。所有实验结果均显示,谄媚会提升用户对行为正确性的认知、降低修复意愿,同时增强对人工智能的偏好度、信任度及依赖性。这些发现表明,用户偏好可能在无意中助长对人工智能产生社会危害性行为的倾向。
局限性与展望
人际冲突与和解是换位思考与承担责任的关键成长过程,而 AI 的谄媚行为通过消除社会摩擦,阻碍了这一正常学习机制。长期来看,这会导致用户丧失对异议的耐受度,在真实关系中更不愿道歉或修复关系,对年轻及情感脆弱的群体风险更高。
更深层的问题在于,谄媚并非技术失误,而是受用户偏好和训练目标激励的结果,这使得开发者缺乏主动修正的动力。
针对这一风险,监管机构应将 AI 的谄媚行为视为独立危害,要求在模型部署前进行行为审计。开发者则需超越短期的用户满意度指标,将优化目标扩展至长期的社会结果,并在评估中纳入更广泛的社会背景。此外,应引入面向用户的干预措施,如透明度提示或 AI 素养计划,借鉴虚假信息研究中的预防接种理论,帮助用户重新校准信任。
该研究也存在局限性:以 Reddit 社区认可率作为基准可能反映了特定群体的偏见;研究基于英语和美国参与者,结论未必适用于社会规范不同的文化语境;最后,研究将谄媚行为化为二元变量,缺乏中性基线。社会谄媚行为可能存在连续性特征,该研究为后续探索更模糊、更隐性的案例奠定了基础。
