

来自华威大学的研究团队提出一个面向 TESS 候选体的全新筛选与验证流程 RAVEN,其引入了合成训练数据集,不再仅依赖任务本身产生的阈值越界事件(TCE)数据,这一改进大幅拓展并增强了机器学习模型所覆盖的行星与假阳性情景参数空间。在一个包含 1361 个预分类 TESS 候选体的独立外部测试集中,该流程实现了 91% 的总体准确率,展示了其在自动排序 TESS 候选体方面的有效性。
随着天文学研究的不断深入,系外行星的发现进入了快速发展阶段。尤其是由 NASA 的凌星系外行星巡天卫星(TESS)任务提供的光变曲线数据,使得科学家每天都能获取大量凌日信号候选。
然而,确认或否定候选体的行星属性是一个漫长且充满挑战的过程。截至目前,系外行星档案库中共列出了 7,658 个 TESS 兴趣目标(TOI),其中 5,152 个仍被标记为候选体。只有 666 个被确认是真正的系外行星,另有 558 个由 TESS 探测到但此前已被确认的行星。与此同时,有 1,185 个 TESS 候选体被识别为「假阳性(FP)」,另有 97 个被归类为「误警报(FA)」——如此之高的数量凸显了确认系外行星候选体的困难。
在候选体筛选之上,更进一步的是「验证流程(validation pipelines)」,其目标是通过统计方法确认候选体为真实行星。传统的验证方法主要依赖人工分析和后续观测,包括径向速度测量(RV)和地面望远镜跟踪,这些方法虽然可靠,但耗时长、成本高。
针对于此,来自华威大学的研究团队在 David J. Armstrong 等人提出的开普勒流程基础上,进一步发展出一个面向 TESS 候选体的全新筛选与验证流程——RAVEN(RAnking and Validation of ExoplaNets)。新流程最关键的变革在于引入了合成训练数据集,不再仅依赖任务本身产生的阈值越界事件(TCE)数据,这一改进大幅拓展并增强了机器学习模型所覆盖的行星与假阳性情景参数空间。
结果显示,该流程在所有假阳性情景下均获得超过 97% 的 AUC 评分,其中除一个情景外,其余均超过 99%;在一个包含 1,361 个预分类 TESS 候选体的独立外部测试集中,该流程实现了 91% 的总体准确率,展示了其在自动排序 TESS 候选体方面的有效性。
研究人员还利用该流程确认了 118 颗新的系外行星,同时识别出了超 2,000 颗高质量的行星候选者,其中将近 1,000 颗此前从未被发现。
相关研究成果以「RAVEN: RAnking and Validation of ExoplaNets」为题,已发布预印本于 arXiv。
研究亮点:
* 借助合成数据集,RAVEN 实现了对行星情景与每一种假阳性情景的逐一对比,这一能力此前通常仅存在于依赖模型拟合的验证框架中
* 新流程引入了合成训练数据集,不再仅依赖任务本身产生的 TCE 数据
* 新流程保持了较高的运行效率:处理一个典型候选体仅需约一分钟,并且通过多进程支持具备良好的扩展性
论文地址:https://arxiv.org/abs/2509.17645
数据集:从输入数据到训练样本的完整构建路径
输入数据:以光变曲线为核心的多源信息融合
RAVEN 流程目前使用由 TESS 科学处理运营中心发布的 TESS 全帧图像(FFI)生成的光变曲线。这些光变曲线通过孔径光度法(aperture photometry)从各观测扇区的 FFI 数据中提取,其中第 1–27 扇区的采样率为 30 分钟,第 28–55 扇区为 10 分钟。TESS 第二次扩展任务(从第 56 扇区开始)发布的 FFI 采样率为 200 秒。本研究使用的光变曲线截止于第 55 扇区。
训练数据:行星与假阳性的系统化建模
RAVEN 流程引入了合成光变曲线数据用于训练机器学习模型,而不再依赖任务中已有的已分类候选体光变数据。
初始合成事件集合使用模拟的凌日或食现象,并注入到 SPOC 光变曲线中。模拟事件使用研究人员修改版的 PASTIS 软件生成,初步包括凌日行星(Planet)、食双星(EB)、分层食双星(HEB)、分层凌日行星(HTP)、背景食双星(BEB)、背景凌日行星(BTP)等情景。为了确保合成数据尽量贴近 TESS 实际观测群体,每个情景中的主星从经过充分表征的 TESS 输入目录(TIC)样本中随机选择。最终,其目标样本包含 1,200,520 颗 SPOC FFI 恒星。
在此基础上,假阳性数据的构建更为复杂且关键——对于附近假阳性(Nearby False Positives, NFPs),研究人员考虑以下 NFP 情景:附近凌日行星(NTP):行星凌经过稀释宿主; 附近食双星(NEB):附近稀释源为食双星; 附近分层食双星(NHEB):附近稀释源为分层食双星。
测试数据:以 TOI 为核心的真实应用场景
该流程的性能最终在一组已有先验分类的 TOI(即 TESS 兴趣目标)上进行了测试,测试所用 TOI 列表及分类信息来自 NASA Exoplanet Archive,日期为 2025 年 2 月 3 日。当时共有 2,134 个预分类 TOIs,其中 548 个被分类为已知行星(Known Planets, KP),485 个为 TESS 确认行星(Confirmed Planets, CP),1,113 个为 FP,96 个为 FA。然而,只有 1,918 个 TOIs 具备关联的已发布 SPOC FFI 光变曲线。最终,在对剩余样本应用深度和周期约束后,待处理 TOIs 总数为 1,589 个。
所有 TOIs 都经过管线的完整处理步骤,除了一个 FP TOI,其目标星在 TIC 中被标记为 「DUPLICATE」。最终结果中,有 68 个 TOIs 因目标星在 TIC 中缺失恒星半径而被排除;另有 87 个因 TESS 星等超过 13.5 被排除,22 个因 Gaia 星等超过 14 被排除。
研究的训练集不包含目标星星等大于 13.5 Tmag 或 14 Gmag 的事件。此外,还有 28 个 TOIs 因在特征生成过程中计算出的 MES 小于 0.8而被排除,2 个 TOIs 特征生成失败而被舍弃。最后,21 个 TOIs 因质心数据问题无法生成位置概率,因此未提供后验概率,也被排除在进一步分析之外。
因此,本次测试中最终的预分类 TOIs 数量为 1,361 个,其中 705 个为已知或确认行星,630 个为 FP,26 个为 FA。
结合两种机器学习模型——GBDT+GP
RAVEN 流程基于 David J. Armstrong 等人在 2021 年针对开普勒任务候选体提出的统计验证框架(下文简称 A21),该框架被适配至凌日系外行星巡天卫星数据,同时也进行了扩展与升级。整个流程的实现与运行较为复杂,涉及多个步骤,简要流程如下图所示:
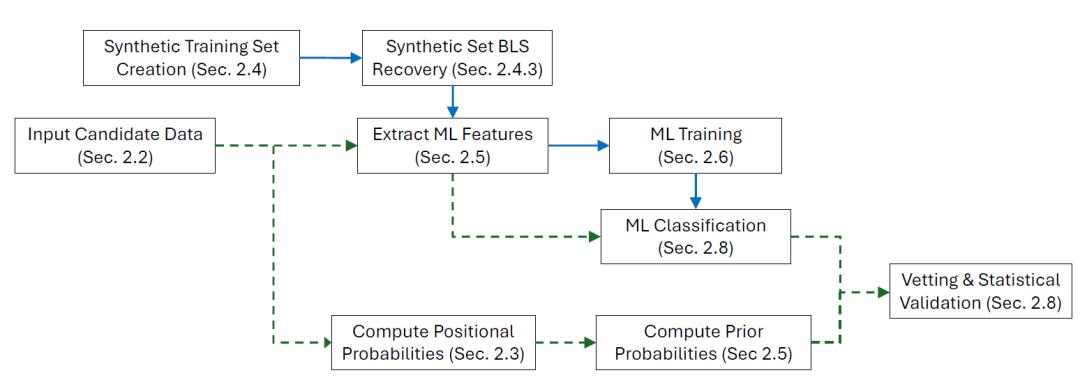
流程图
机器学习训练
RAVEN 的核心是结合两种机器学习模型:梯度提升决策树(Gradient Boosted Decision Tree, GBDT)和高斯过程(Gaussian Process, GP)。流程对每个候选行星生成 8 种假阳性情景的后验概率,并通过取最小值,得到 RAVEN 概率,即对候选真实性的最低信心。
① 梯度提升决策树(GBDT)
决策树是一类简单但功能强大的机器学习模型,它的一个显著优势是可解释性强,然而单棵决策树在稳健性方面存在局限,且当树的深度过大时容易发生过拟合。为解决这些问题,通常采用由多个「弱」树组成的集成方法。梯度提升决策树(GBDT)正是一种这样的集成方法,它通过顺序构建多个决策树来形成更强的最终模型。
GBDT 的核心特点在于:每一轮新生成的树并非直接基于原始标签训练,而是针对前一轮模型预测所产生的残差误差进行学习。换言之,每一个新模型的目标都是最小化整体模型的损失函数,这一过程本质上类似于梯度下降。在集成过程中,各个子模型的输出结果会按学习率(learning rate)进行缩放后累加,从而得到最终预测。
模型损失通过预设的损失函数计算,而残差则由该损失函数的梯度决定。在本研究的流程中,GBDT 分类器采用的是 Chen 与 Guestrin 提出的 XGBoost 实现。
② 高斯过程分类器
高斯过程(Gaussian Process,GP)是一种随机过程,它将高斯概率分布从「随机变量的分布」推广为「函数的分布」。在 GP 分类中,目标是输出离散类别标签或介于 0 到 1 之间的类别概率。为此,需要对 GP 的输出施加一个响应函数,将结果映射到 0 到 1 的区间。随后,将其与概率似然函数(如伯努利似然)结合。
本研究采用 James Hensman 等人提出的变分近似方法。该方法依赖一组「诱导点(inducing points)」,即数据的代表性子集,用于在降低计算复杂度的同时提升模型的可扩展性。
训练与校准
为了训练并优化两个分类器,采用迭代方式,在不同超参数组合下对合成训练集进行训练,并在验证集上评估性能,从而选取最优参数。参数调优主要聚焦于三类关键 FP 场景:EB、NEB 和 NSFP,因为它们是最常见的假阳性事件。同时,为避免对单一场景过度优化并导致过拟合,各场景之间尽量保持参数一致。
所有模型均启用了「早停(Early Stopping)」机制:当验证集上的损失函数在连续 20 次迭代中未下降至少 0.0001 时,训练即终止,并回退到损失函数最后一次改善时的模型状态。
统计验证
流程的最后一个组成部分是通过结合机器学习得出的每个行星-FP分类的概率与其对应的场景特定先验概率,来推导行星假设的后验概率——这个后验概率仅表示候选体为行星或特定 FP 场景的概率。因此,研究人员的统计验证方法要求候选体在 8 个行星-FP 分类中,每一个的行星后验概率均超过 0.99,才能被视为验证通过。
RAVEN 在筛选、排序和验证真实行星候选体方面表现良好
为了评估 RAVEN 的性能,研究人员分别在训练集和测试集上进行了以下验证:
研究人员首先在训练集未见子集上测试其性能,这些子集由每个场景随机选取的 10% 事件组成,并在训练前独立隔离。模型性能通过四个关键指标进行评估:准确率(accuracy)、ROC 曲线下面积(AUC)、精确率(precision)和召回率(recall),性能测试结果见下表:
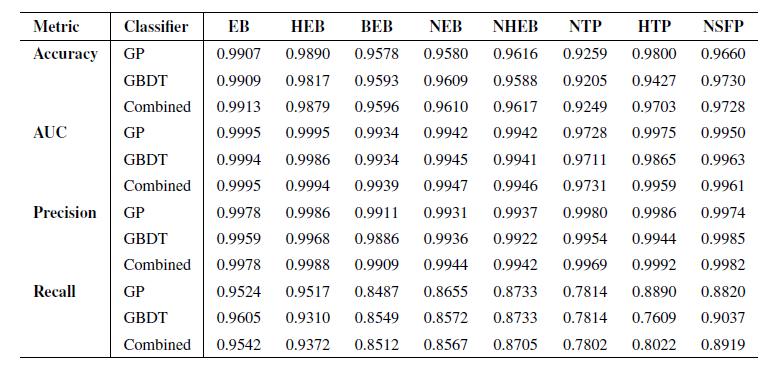
针对行星–假阳性配对训练的 GBDT 和 GP 二分类器在测试集上的性能指标
结果显示,两个分类器在所有 FP 场景下表现优异,尤其是在精确率方面。由于 RAVEN 流程的主要目标是筛选和验证真实行星候选体,精确率是最重要的指标,它体现了管线正确识别 FP 而不误判的能力。结合两个分类器的结果,精确率在所有场景下几乎达到 99%。
RAVEN 流程性能最终在一组已有先验分类的 TOIs 上进行了测试。对于样本中所有 1,361 个 TOI,其 RAVEN 概率下图所示:
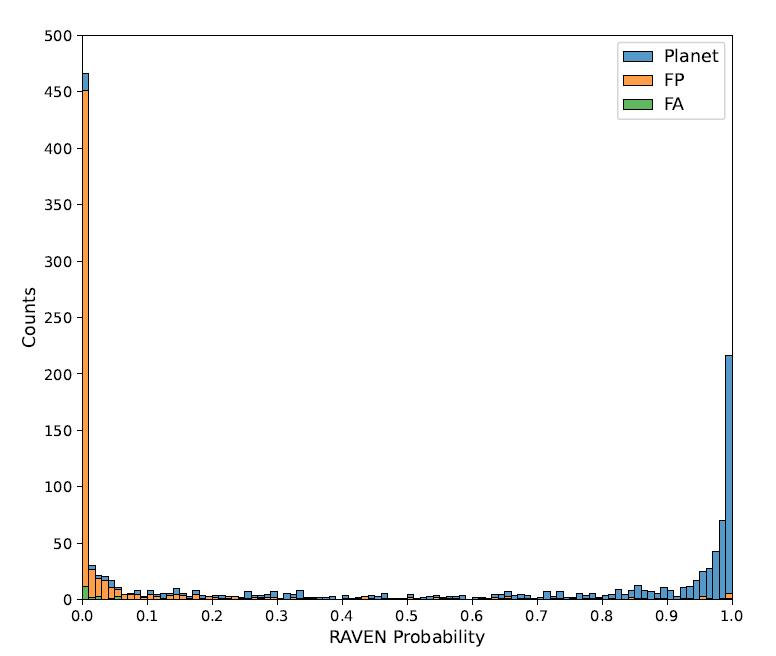
堆叠直方图,展示预先分类的行星、FP 和 FA TOI 的最小后验概率
直方图中显示了三类的概率差异明显,分布良好,极值明显。这体现了 RAVEN 在识别 FP 事件并为其分配低行星后验概率方面的有效性。具体而言,93.8% 的 FP 事件最小后验概率低于 0.5,其中 69.7% 低于 0.01。FP 事件的平均概率为 0.076,中位数为 0.00022。
类似地,对于 26 个 FA TOI,其中 23 个的概率低于 0.5,整个类别的中位数为 0.016。总体来看,FP 和 FA TOI 的结果证实了管线在筛选 TESS 候选体方面的高效性,可用于去除大部分 FP 事件。
接着,研究人员验证了RAVEN 在假阳性(FP)识别方面的能力,下表进一步列出了 12 个概率大于 0.9 的 FP 事件:
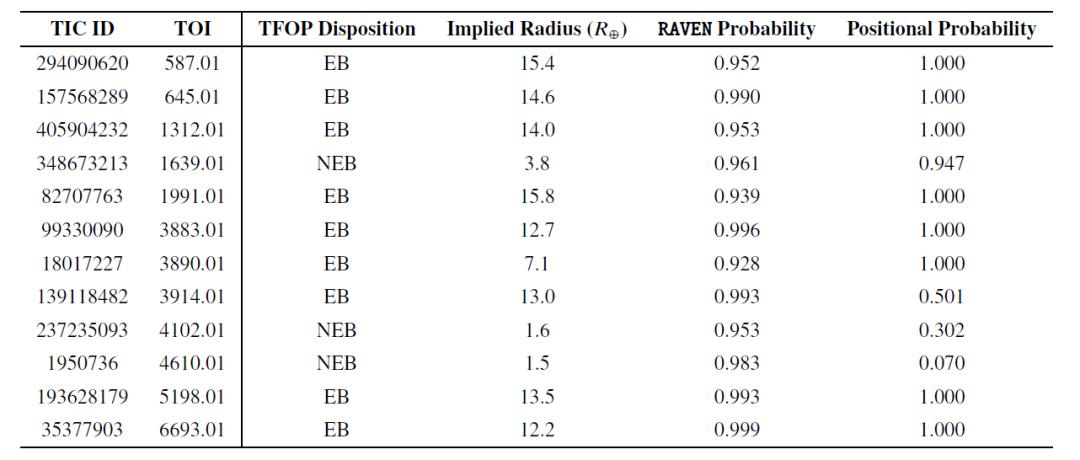
行星后验概率大于 0.9 的假阳性 TOI(FP TOIs)列表
这些高概率 FP 事件中,大多数是食双星(EB),仅包含 3 个近邻食双星(NEB)事件。尽管 NEB 是样本中最常见的 FP 类型,这表明在 RAVEN 识别 NEB 时表现有效。实际上,对于 2 个 NEB 事件(TOI-4102.01 和 TOI-4610.01), RAVEN 流程确定其位置信息概率低,并正确地将最高概率分配给随访观测确认的真实宿主。
此外,TOI-4102.01 还被标记为有问题事件。这两个 TOI 表明,在评估候选体,尤其是进行验证时,应综合参考 RAVEN 流程的完整输出,尤其是位置信息概率,以识别后验概率可能失效的情况。
同时,研究人员也评估了 RAVEN 流程在假警报(FA) TOI 上的表现,下表展示了样本中 26 个 FA TOI 的最低后验概率,以及最低概率对应的 FP 情景。几乎所有 FA TOI 的概率与行星情景不一致,显示 RAVEN 能够有效识别它们。
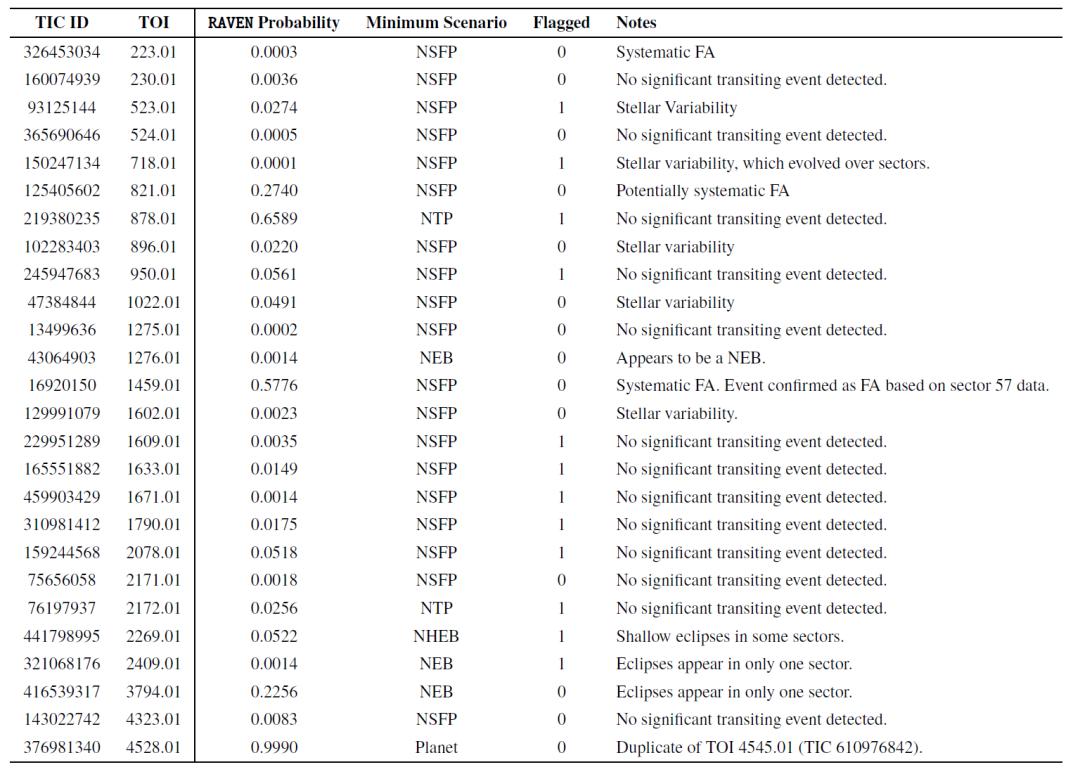
FA TOI 列表,包含其最小行星后验概率及对应的 FP 情景
最后,在对初始 TOI 样本进行筛选后,研究人员最终保留了 397 个已知行星(Known Planets)和 308 个已确认行星(Confirmed Planets),总计 705 颗行星。结果显示,大多数 Planet TOI 的行星后验概率较高,其中 81% 超过 0.5 阈值。
其中特别是 420 颗行星的概率超过 0.9,进入「可能行星(Likely Planet)」区间。此外,共有 210 个 Planet TOI 超过 0.99 的统计验证阈值,占总行星样本约 30%。这些结果表明 RAVEN 在筛选、排序和验证真实行星候选体方面表现良好。
AI 逐步成为天文学研究的重要基础设施
在更宏观的技术演进视角下,人工智能正逐步成为天文学研究的重要基础设施,其意义不再局限于「提升数据处理效率」,而是开始重塑科学发现的整体范式。长期以来,天文学依赖基于物理模型与人工规则的分析方法,但随着观测能力的提升,数据规模与复杂度持续攀升,从光变曲线到高分辨率图像,再到多维光谱与星表信息,传统方法在处理高维、非线性和强噪声数据时逐渐逼近极限。在这一背景下,以机器学习和深度学习为核心的 AI 技术,正在成为连接「海量观测数据」与「有效科学认知」的关键桥梁。
随着观测手段的丰富,天文学数据已不再局限于单一模态。图像、光谱、时序光变曲线以及星表参数等多源数据同时存在,传统深度学习模型在这一阶段开始显现出新的瓶颈。事实上,已有研究尝试构建天文学多模态模型,但这些尝试仍存在明显局限:大多聚焦于超新星爆发等单一现象,依赖「对比目标(contrastive objectives)」作为核心技术,导致模型既难以灵活应对任意模态组合,也难以捕捉模态之间除浅层关联之外的关键科学信息。
为突破这一瓶颈,来自加州大学伯克利分校、剑桥大学、牛津大学等全球十余所科研机构的团队联合攻关,推出了首个面向天文学的大规模多模态基础模型家族 AION-1(天文全模态网络,AstronomIcal Omni-modal Network),通过统一的早期融合骨干网络,将图像、光谱和星表数据等异质观测信息进行集成建模,不仅在零样本场景下表现优异,其线性探测准确率也可媲美针对特定任务专门训练的模型。
论文标题:AION-1: Omnimodal Foundation Model for Astronomical Sciences
论文地址:https://openreview.net/forum?id=6gJ2ZykQ5W
与此同时,在具体科学问题层面,AI 也正在突破传统观测方法的能力边界。例如,在现代天文学中,强引力透镜(strong gravitational lens)是研究宇宙大尺度结构和黑洞-星系共演化的重要工具。充当强引力透镜的类星体(Quasars),为研究超大质量黑洞与其宿主星系之间标度关系(尤其是 MBH–Mhost 关系)随红移演化的规律,提供了极为罕见的观测机会。
然而,类星体极为罕见,其识别一直是天文学家面临的巨大挑战——在斯隆数字巡天(SDSS)编目的近 30 万个类星体中,仅发现了 12 个候选者,最终确认的也只有 3 个。在此背景下,由斯坦福大学、SLAC 国家加速器实验室、北京大学、意大利国家天体物理研究院布雷拉天文台、伦敦大学学院、加州大学伯克利分校等众多科研机构组建的团队,开发了一套数据驱动的流程,用于在 DESI DR1 的光谱数据中识别作为强引力透镜的类星体——应用该流程后,研究人员识别出 7 个高质量(A 级)类星体透镜候选体。
论文名称:Quasars acting as Strong Lenses Found in DESI DR1
论文地址:https://arxiv.org/abs/2511.02009
可以预见,随着未来观测任务(如更大规模巡天项目)的推进,天文学将进入一个数据进一步爆发的阶段,而 AI 的角色也将随之深化。从辅助分析到主导发现,从单任务模型到通用基础模型,AI 正在重塑我们理解宇宙的路径——它不仅改变了「我们如何看见」,也在改变「我们能够发现什么」。
参考文献:
1.https://arxiv.org/abs/2509.17645
2.https://phys.org/news/2026-03-ai-approach-uncovers-dozens-hidden.html
3.https://openreview.net/forum?id=6gJ2ZykQ5W
