

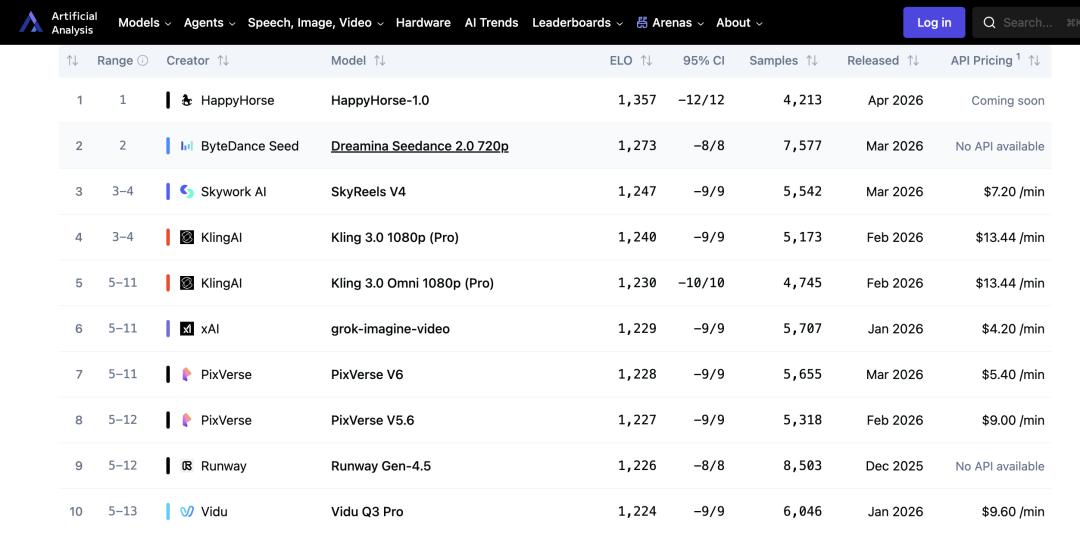
没有发布会,没有技术博客,没有任何公司背书——一款名为HappyHorse-1.0 的文本转视频模型,悄然登顶权威AI评测平台Artificial Analysis的AI Video Arena排行榜,以更高的Elo分数压过了Seedance 2.0,更将可灵、天工等一众主流玩家甩在身后,一时之间引发了技术圈的“解密竞赛”。
Artificial Analysis的排名不是技术参数评测,而是真实用户盲测结果汇总出来的 Elo 积分,反映的是普通人看过之后的真实感知。这让这个排名比通常的跑分榜更难被轻易质疑,也让“这东西到底是谁做的”变成了一个无法忽视的问题。
“快乐马”悄然登顶,引发科技圈猜谜竞赛
X上的猜测来得很快。最先被人注意到的,是官网的语言排序:普通话和粤语排在英语前面。对于一个面向全球用户的产品,这个顺序有点反常——如果是美国团队主导,英语几乎不可能不是第一位。背后团队来自中国,基本可以确认。
名字本身也是线索。2026年是农历马年,“HappyHorse”这个命名藏着不太含蓄的马年梗,今年早些时候“Pony Alpha”也玩过类似套路。于是嫌疑名单迅速拉长:腾讯和阿里的创始人都姓马,天然在列;有人押注小米,觉得雷军一贯低调,喜欢突然亮牌;也有人觉得气质更像DeepSeek,毕竟DS此前曾悄悄上线过视觉模型,后来又悄悄下线了。各路猜测热闹非凡,但没一个拿得出实锤。
真正锁定目标的,是技术层面的逐条比对。X用户Vigo Zhao把HappyHorse-1.0 的公开基准数据拿去和已知模型一一核对,结果找到了一个高度吻合的对象:daVinci-MagiHuman,也就是3月上线Github的开源模型“达芬奇魔法人类”。
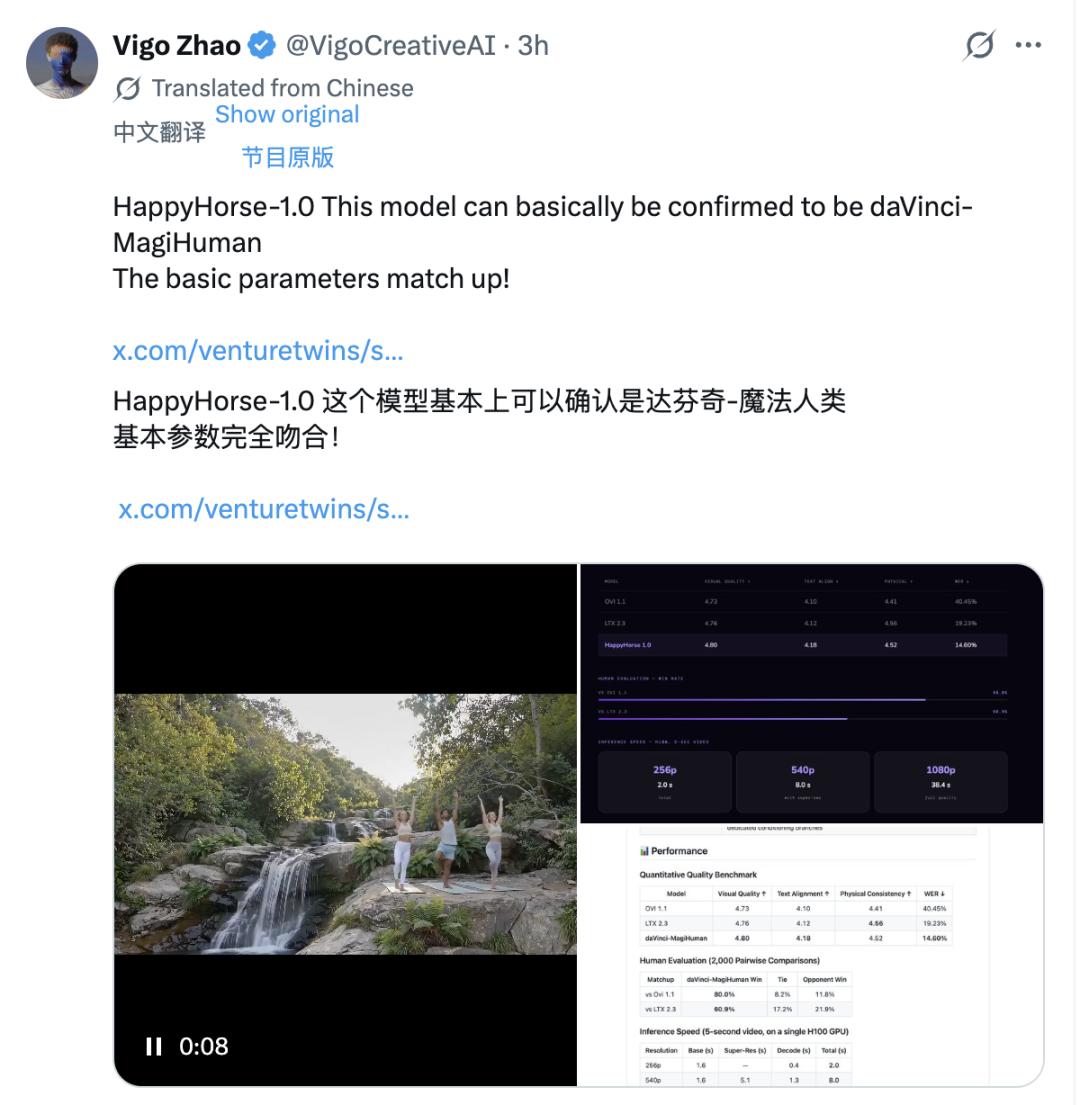
视觉质量4.80、文本对齐4.18、物理一致性4.52、语音字错率14.60%——两份数据逐项对得上。官网结构也几乎一样:架构描述、性能表格、演示视频的呈现风格,都像是出自同一套模板。两者同为单流Transformer架构,同为音视频联合生成,支持的语言列表也完全一致。这种程度的重合,很难用巧合解释。
目前技术圈认可度最高的结论是,HappyHorse 是daVinci-MagiHuman联合开发方之一的Sand.ai,基于开源模型优化的迭代版本,核心目的是验证模型在用户真实偏好下的表现上限,为后续的商业化落地做铺垫。
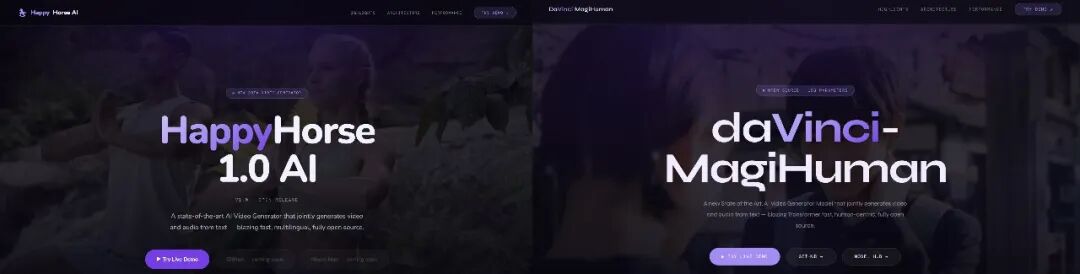
daVinci-MagiHuman在2026年3月23日正式开源,是两支年轻团队合作的产物。一支来自上海创智学院(SII)生成式人工智能研究实验室(GAIR),带头人是学者刘鹏飞;另一支是北京的 Sand.ai(三呆科技),创始人曹越同样有学术背景,公司方向是自回归世界模型。
模型用的是150亿参数的纯自注意力单流 Transformer,把文本、视频、音频三种模态的 token 全部塞进同一个序列里联合建模——开源界此前还没有人从零开始做过真正的音视频联合预训练,大多数是在单模态基础上拼接。
一款开源视频模型,何以实现两周逆袭?
身份搞清楚之后,另一个问题反而更难回答:daVinci-MagiHuman3月底才开源,HappyHorse-1.0凭什么能在短短两周内拿到比Seedance 2.0更高的Elo分数?
从官网披露的信息来看,HappyHorse并没有对底层架构动过什么手脚,比较合理的猜测是,它在默认生成策略上针对评测场景做了专项调整。
Elo体系本质上是用户偏好的累积,人物表情稳定不稳定、音画有没有对齐、画面是否赏心悦目,这些感知敏感项上稍微做好一点,在盲测里就容易被选中。模型的能力上限没变,但“评测表现”可以被打磨出来。
事实上,Artificial Analysis的盲测样本中,人像生成、口播类内容占比超过 60%,而daVinci-MagiHuman从训练阶段就聚焦人像演绎,在该类场景中天然具备优势,这也是其盲测胜率领先的核心原因;盲测样本如果以人像特写为主,擅长人像的模型就会系统性地占便宜,跟它在多人物、复杂运镜、长时序叙事等复杂场景下的实际表现没有直接关系。
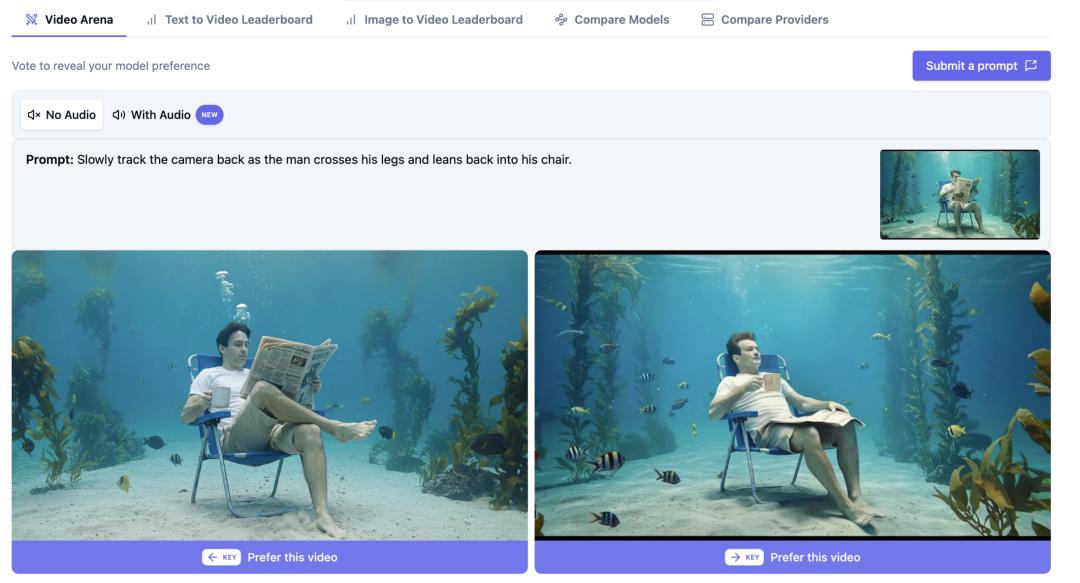
结果是,排行榜上的数字和实测体验之间出现了明显的落差,X上的讨论者也分成了两派。怀疑派在测试后认为,HappyHorse-1.0与Seedance 2.0在人物细节、动态连贯性上仍有可见差距,并由此质疑Elo评分本身的代表性。
而支持者则对HappyHorse的潜力寄予厚望,希望它能够解决“多镜头序列中的画质一致性”这一行业痛点,因为这是当前主流视频模型都没解决好的问题,如果 daVinci-MagiHuman真的在这里有所突破,可能要比一个榜单排名重要得多。
模型本身的局限也不该被数字掩盖。小红书博主@JACK的AI视界 曾第一时间部署、实测了daVinci-MagiHuman。发现它跑起来需要H100,普通消费级显卡基本没戏,虽然社区在研究量化方案,但短期内个人用户想本地部署还是有难度。
场景上,它目前主要擅长单一人物,一旦多人出镜或者场景变复杂,效果就会掉下来——这不是调参能解决的问题,和它专注人像的设计取向有直接关系。生成时长一般也就10秒上下,再长容易乱,高清输出还得靠超分插件补。
@JACK的AI视界得出的结论是:daVinci-MagiHuman综合易用性不如LTX 2.3,需要得等社区把量化做好之后才适合日常使用。
视频生成赛道,等来了真正的“鲶鱼”?
当然,一次榜单领先并不能说明太多。接下来,HappyHorse还需要在稳定性、高并发访问速度、跨场景一致性、角色控制精度,以及评测集之外的泛化能力上接受更充分的检验。这些,才是决定一个模型能否真正进入创作者工作流的核心指标。
但如果把视野放到更大的行业格局,这件事传递的信号其实已经足够清晰。
开源视频模型本身并不是新鲜事。但始终横亘在开源与闭源之间的,是一道效果层面的可见差距——在需要向客户交付的场景里,开源模型的生成质量长期未能跨过“可用”到“可交付”的门槛。可灵、Seedance等闭源产品的定价权,在相当程度上正是建立在这一差距之上。
这一次的意义在于,一个基于开源模型的产品,在以真实用户感知为基准的盲测排行榜上,首次正面比肩了当前主流闭源竞争对手。不论其中有多少针对评测场景的调优成分,对于依赖这一差距构建定价权的闭源厂商而言,至少这是一个值得认真对待的信号。
对开发者而言,这个拐点的含义更为具体。在人像、数字人、虚拟主播等垂直场景中,一旦开源基座的生成质量触及“可交付”的门槛,自主部署的成本结构将发生实质性变化——不仅是API调用成本的压缩,更重要的是将数据、模型与推理链路完整地纳入自身掌控,在定制化深度与隐私合规层面获得闭源方案难以提供的灵活性。
HappyHorse-1.0短期内不会动摇 Seedance 2.0或可灵的市场地位,但开源模型效果可以媲美闭源这一认知一旦确立,后续的量化优化、垂直微调与推理加速将由社区以远超闭源产品的迭代速度持续推进。
在这个马年,真正值得关注的,或许不是哪匹马跑得最快,而是赛道本身正在变宽。
