

苹果发文质疑:大语言模型根本无法进行逻辑推理
2024-10-13
/ 阅读约10分钟
来源:36kr
5 大证据显示,LLM 在推理复杂问题时非常脆弱。
大语言模型(LLM)是真的会数学推理?还是只是在“套路”解题?
 论文链接:https://arxiv.org/abs/2410.05229
论文链接:https://arxiv.org/abs/2410.05229
大模型不具备形式推理能力?5 大证据来了
 然而,随着准确率的提升,疑问也随之而来:这些模型的推理能力是否真的进步了?它们的表现是否真的体现了逻辑或符号推理能力,抑或是简单的模式识别,数据污染,甚至过拟合的结果?
为进一步探索这一问题,研究团队此发了 GSM-Symbolic,用于测试大语言模型在数学推理中的极限。GSM-Symbolic 基于 GSM8K 数据集,通过符号模板生成多样化的问题实例,允许更可控的实验设计。
为了更清晰地观察模型在面对这些变体问题时的表现,他们生成了 50 个独特的 GSM-Symbolic 集合,这些问题与 GSM8K 问题类似,但更改了其中的数值和名称。
基于 GSM-Symbolic,他们从 5 个方面说明了为何他们认为大语言模型不具备形式推理能力:
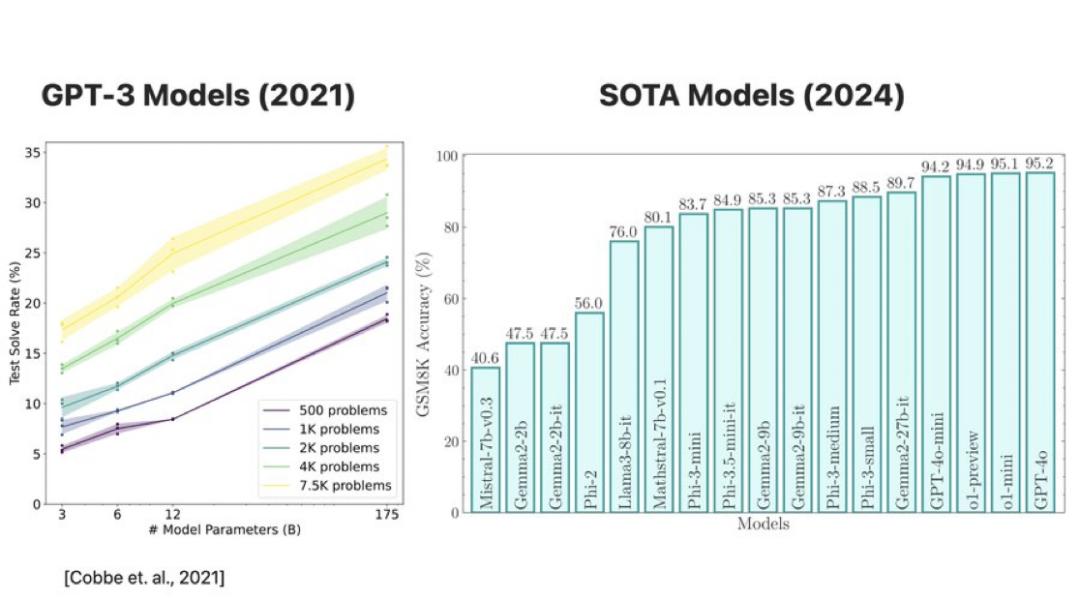
1. GSM8K 的当前准确率并不可靠
通过对多个开源模型(如 Llama 8B、Phi-3)和闭源模型(如 GPT-4o 和 o1 系列)的大规模评估,他们发现模型在 GSM8K 上的表现存在显著波动。例如,Llama 8B 的准确率在 70%-80% 之间波动,而 Phi-3 的表现则在 75%-90% 之间浮动。
这也表明,模型在处理相似问题时表现并不稳定,GSM8K 上的高分并不能证明它们具备真正的推理能力。
然而,随着准确率的提升,疑问也随之而来:这些模型的推理能力是否真的进步了?它们的表现是否真的体现了逻辑或符号推理能力,抑或是简单的模式识别,数据污染,甚至过拟合的结果?
为进一步探索这一问题,研究团队此发了 GSM-Symbolic,用于测试大语言模型在数学推理中的极限。GSM-Symbolic 基于 GSM8K 数据集,通过符号模板生成多样化的问题实例,允许更可控的实验设计。
为了更清晰地观察模型在面对这些变体问题时的表现,他们生成了 50 个独特的 GSM-Symbolic 集合,这些问题与 GSM8K 问题类似,但更改了其中的数值和名称。
基于 GSM-Symbolic,他们从 5 个方面说明了为何他们认为大语言模型不具备形式推理能力:
1. GSM8K 的当前准确率并不可靠
通过对多个开源模型(如 Llama 8B、Phi-3)和闭源模型(如 GPT-4o 和 o1 系列)的大规模评估,他们发现模型在 GSM8K 上的表现存在显著波动。例如,Llama 8B 的准确率在 70%-80% 之间波动,而 Phi-3 的表现则在 75%-90% 之间浮动。
这也表明,模型在处理相似问题时表现并不稳定,GSM8K 上的高分并不能证明它们具备真正的推理能力。
 图|由 GSM-Symbolic 模板生成的 50 套 8-shot 思想链(CoT)性能分布,显示了所有 SOTA 模型之间准确性的显著差异性。
对于大多数型号来说,GSM-Symbolic 的平均性能低于 GSM8K(图中由虚线表示)。有趣的是,GSM8K 的性能落在分布的右侧,从统计学上讲,这应该非常低的可能性,因为 GSM8K 基本上只是 GSM-Symbolic 的一次单一抽样。
2. 对名称和数字变动的敏感性
研究还发现,当前的大语言模型对问题中的专有名称(如人名、食物、物品)的变化仍然很敏感,当数字发生变化时,大语言模型就会更加敏感。
例如,仅仅改变问题中的名字,就可能导致模型的准确率变化高达 10%。如果将这种情况类比到小学数学测试中,仅仅因为改变了人名而导致分数下降 10% ,是非常不可思议的。
图|由 GSM-Symbolic 模板生成的 50 套 8-shot 思想链(CoT)性能分布,显示了所有 SOTA 模型之间准确性的显著差异性。
对于大多数型号来说,GSM-Symbolic 的平均性能低于 GSM8K(图中由虚线表示)。有趣的是,GSM8K 的性能落在分布的右侧,从统计学上讲,这应该非常低的可能性,因为 GSM8K 基本上只是 GSM-Symbolic 的一次单一抽样。
2. 对名称和数字变动的敏感性
研究还发现,当前的大语言模型对问题中的专有名称(如人名、食物、物品)的变化仍然很敏感,当数字发生变化时,大语言模型就会更加敏感。
例如,仅仅改变问题中的名字,就可能导致模型的准确率变化高达 10%。如果将这种情况类比到小学数学测试中,仅仅因为改变了人名而导致分数下降 10% ,是非常不可思议的。
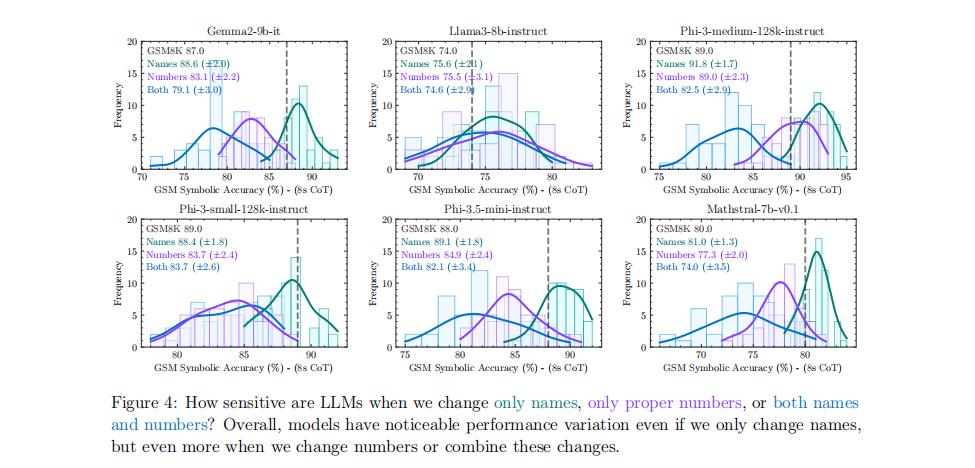 图|当只更改名称、专有编号或同时更改名称和编号时,大语言模型的敏感性如何?总体而言,即使只更改名称,模型也有明显的性能变化,但当更改编号或合并这些变化时,性能差异更大。
3. 问题难度的增加导致表现急剧下降
研究团队通过引入三种新的 GSM-Symbolic 变体(GSM-M1、GSM-P1、GSM-P2),通过删除一个分句(GSM-M1)、增加一个分句(GSM-P1)或增加两个分句(GSM-P2),来调整问题难度。
图|当只更改名称、专有编号或同时更改名称和编号时,大语言模型的敏感性如何?总体而言,即使只更改名称,模型也有明显的性能变化,但当更改编号或合并这些变化时,性能差异更大。
3. 问题难度的增加导致表现急剧下降
研究团队通过引入三种新的 GSM-Symbolic 变体(GSM-M1、GSM-P1、GSM-P2),通过删除一个分句(GSM-M1)、增加一个分句(GSM-P1)或增加两个分句(GSM-P2),来调整问题难度。
 图|通过修改条款数量来修改 GSM-Symbolic 的难度级别
图|通过修改条款数量来修改 GSM-Symbolic 的难度级别
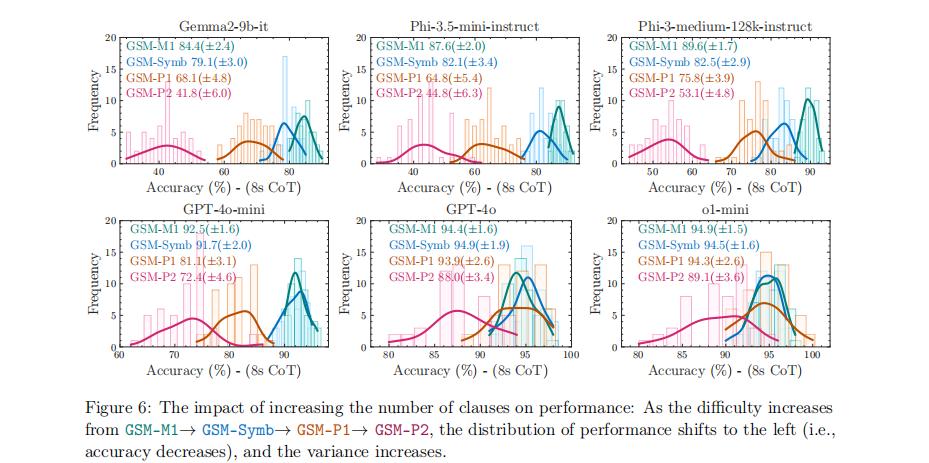 图|增加条款数量对性能的影响:随着GSM-M1→GSM-Symb→GSM-P1→GSM-P2的难度增加,性能分布向左移动(即准确性下降),方差增加。
结果发现,随着问题难度的增加(GSM-M1 → GSM-Symb → GSM-P1 → GSM-P2),模型的表现不仅下降显著,且表现波动也变得更加剧烈。面对更复杂的问题时,模型的推理能力变得更加不可靠。
4. 添加无关子句对性能的巨大影响
为进一步测试模型的推理能力,研究团队设计了 GSM_NoOp 实验,在原有问题中添加一个似乎相关但实际无关的子句 (hence "no-op")。
结果显示,所有模型的表现都显著下降,包括性能较好的 o1 模型在内。这种现象进一步说明,模型并没有真正理解数学概念,而是通过模式匹配来得出答案。
图|增加条款数量对性能的影响:随着GSM-M1→GSM-Symb→GSM-P1→GSM-P2的难度增加,性能分布向左移动(即准确性下降),方差增加。
结果发现,随着问题难度的增加(GSM-M1 → GSM-Symb → GSM-P1 → GSM-P2),模型的表现不仅下降显著,且表现波动也变得更加剧烈。面对更复杂的问题时,模型的推理能力变得更加不可靠。
4. 添加无关子句对性能的巨大影响
为进一步测试模型的推理能力,研究团队设计了 GSM_NoOp 实验,在原有问题中添加一个似乎相关但实际无关的子句 (hence "no-op")。
结果显示,所有模型的表现都显著下降,包括性能较好的 o1 模型在内。这种现象进一步说明,模型并没有真正理解数学概念,而是通过模式匹配来得出答案。
 图|在 GSM-NoOp 上,模型的性能明显下降,较新的模型比旧的模型下降更大。
5. 扩展规模和计算能力并不能解决根本问题
此外,他们还探讨了通过扩大数据、模型规模或计算能力是否能够解决推理能力不足的问题。
Mehrdad Farajtabar 表示,尽管 OpenAI 的 o1 系列在性能上有一定改善,但它们也会出现这样的愚蠢错误,要么是它不明白“现在”是什么意思,要么是它不明白“去年”是什么意思,还有一种更可能的解释是,更大的训练数据具有这种模式,所以它又沿用了这种模式。
图|在 GSM-NoOp 上,模型的性能明显下降,较新的模型比旧的模型下降更大。
5. 扩展规模和计算能力并不能解决根本问题
此外,他们还探讨了通过扩大数据、模型规模或计算能力是否能够解决推理能力不足的问题。
Mehrdad Farajtabar 表示,尽管 OpenAI 的 o1 系列在性能上有一定改善,但它们也会出现这样的愚蠢错误,要么是它不明白“现在”是什么意思,要么是它不明白“去年”是什么意思,还有一种更可能的解释是,更大的训练数据具有这种模式,所以它又沿用了这种模式。
 图|o1-mini 和 o1-preview 的结果:这两个模型大多遵循我们在正文中介绍的相同趋势。然而,o1-preview 在所有难度级别上都显示出非常强大的结果,因为所有分布都彼此接近。
他认为,理解大语言模型的真正推理能力对于在现实世界中的应用至关重要,尤其是在 AI 安全、教育、医疗保健和决策系统等对准确性和一致性要求极高的领域。
研究结果表明,当前大语言模型的表现,更像是高级的模式匹配器,而非具备形式推理能力的系统。为了在这些领域安全、可靠地部署大语言模型,开发更为鲁棒和适应性强的评估方法显得尤为重要。
图|o1-mini 和 o1-preview 的结果:这两个模型大多遵循我们在正文中介绍的相同趋势。然而,o1-preview 在所有难度级别上都显示出非常强大的结果,因为所有分布都彼此接近。
他认为,理解大语言模型的真正推理能力对于在现实世界中的应用至关重要,尤其是在 AI 安全、教育、医疗保健和决策系统等对准确性和一致性要求极高的领域。
研究结果表明,当前大语言模型的表现,更像是高级的模式匹配器,而非具备形式推理能力的系统。为了在这些领域安全、可靠地部署大语言模型,开发更为鲁棒和适应性强的评估方法显得尤为重要。
逻辑推理:大语言模型的真正挑战
 随着大语言模型在各类应用场景中被广泛采用,如何确保它们能够处理更复杂、更多样化的问题,已成为 AI 研究领域面临的下一个重大挑战。
未来,大语言模型需要突破模式匹配,真正实现逻辑推理,才能应对不断变化的现实需求。这也是 AI 社区共同努力的方向。
随着大语言模型在各类应用场景中被广泛采用,如何确保它们能够处理更复杂、更多样化的问题,已成为 AI 研究领域面临的下一个重大挑战。
未来,大语言模型需要突破模式匹配,真正实现逻辑推理,才能应对不断变化的现实需求。这也是 AI 社区共同努力的方向。 