

继Llama 4曝出基准刷榜丑闻、旗舰模型Behemoth项目搁置等问题之后,扎克伯格决定彻底推倒重来。
他曾砸下140亿美元挖人,亲自在帕洛阿尔托和太浩湖的豪宅里宴请顶级研究员,最终将前Scale AI首席执行官汪韬(Alexandr Wang)延揽麾下,主持成立Meta超级智能实验室(Meta Superintelligence Labs),并用九个月时间将整个AI技术栈从头重建。
美国当地时间4月8日,这场豪赌的第一张答卷正式亮相:Muse Spark。
这是Meta首款闭源大模型,告别了过去全面开源的路线,将直接为Meta AI助手提供支持,并以API私测形式向少数合作伙伴开放。
根据Meta内部基准测试,Muse Spark在多项指标上超越了谷歌Gemini,与OpenAI和Anthropic的同级模型互有胜负,并在大多数测试中大幅领先于xAI的Grok。消息公布后,Meta股价当日大涨6.5%,市值达到1.55万亿美元。
01 领跑多模态和前沿科学基准测试
成绩单是检验重建成果最直接的标尺。
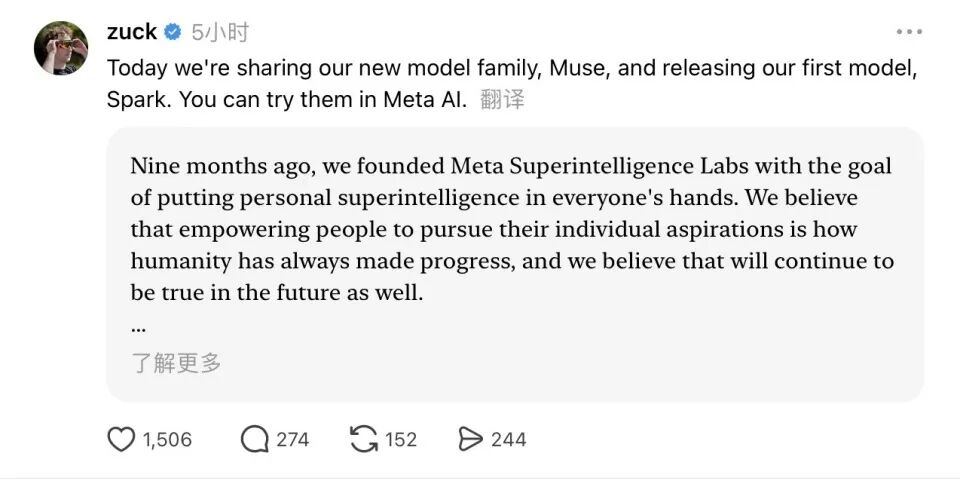
Meta提供的基准测试图呈现了一份复杂的成绩单:有亮点,也有短板,这或许才是一款“起步款”模型最真实的面貌。
在多模态理解方面,Muse Spark表现突出。图表理解测试CharXiv Reasoning中得分86.4,领先Opus 4.6(65.3)和Grok 4.2(60.9),也高于这一项表现较好的GPT 5.4(82.8)和Gemini 3.1 Pro(80.2)。
具身推理ERQA测试中得分64.7,同样优于Opus 4.6的51.6。健康领域是Muse Spark的另一个显著优势:开放式健康问答HealthBench Hard中得分42.8,远超Opus 4.6的14.8、Gemini 3.1 Pro的20.6和Grok 4.2的20.3,是几家竞争对手中的最高分。
深思模式(Contemplating)的表现同样值得关注。在“人类终极考试”(Humanity’s Last Exam)无工具版本中,Muse Spark深思模式得分50.2,超过Gemini 3.1 Deep Think的48.4和GPT 5.4 Pro的43.9;启用工具后得分58.4,超越Gemini 3.1 Deep Think的53.4,与GPT 5.4 Pro的58.7基本持平。
在“前沿科学研究”(FrontierScience Research)测试中,Muse Spark深思模式得分38.3,不仅大幅领先Gemini 3.1 Deep Think(23.3)和GPT 5.4 Pro(36.7),更是几家中的最高分。这是衡量模型逼近真实科研边界的核心指标之一。
然而成绩单并非全面飘红。在抽象推理ARC AGI 2测试中,Muse Spark得分42.5,明显落后于Opus 4.6(63.3)、Gemini 3.1 Pro(76.5)和GPT 5.4(76.1);智能体终端编程Terminal-Bench 2.0中得分59.0,低于Opus 4.6的65.4、Gemini 3.1 Pro的68.5和GPT 5.4的75.1;竞技编程LiveCodeBench Pro中得分80.0,也落后于Gemini 3.1 Pro的82.9和GPT 5.4的87.5。办公任务综合评估GDPval-AA Elo中,Muse Spark得分1444,低于Opus 4.6的1606和GPT 5.4的1672。
MMMU-Pro多模态理解测试中,Muse Spark得分80.4,介于Opus 4.6(77.4)和Gemini 3.1 Pro(83.9)之间,与GPT 5.4(81.2)相近。博士级推理GPQA Diamond中得分89.5,低于Opus 4.6(92.7)、Gemini 3.1 Pro(94.3)和GPT 5.4(92.8),差距较为明显。
这份成绩单的背景是“Muse系列首款模型”。Meta在发布文件中反复强调,更大规模的后续模型已在研发之中,当前结果的意义更多在于证明技术栈的规模化可行性,而非宣示性能天花板。
Meta强在多模态感知与前沿科研推理,弱在抽象推理与智能体编程。这份有得有失的成绩单,或许比一份完美的跑分更能说明问题:Meta的重建尚未完成,但方向已经清晰。
02 多智能体并行
Muse Spark最引人注目的架构亮点,是多智能体并行编排机制与多模态感知能力的原生整合,二者共同构成了这款模型区别于竞争对手的核心底色。
当用户提出一个复杂问题,Meta AI不再让单个模型“想清楚再回答”,而是同时派出多个子智能体分头行动。以规划一次佛罗里达家庭旅行为例:一个智能体负责起草总行程,另一个对比奥兰多和基韦斯特各自的利弊,第三个同步搜寻亲子友好型活动,三条线并行推进,最终汇总成一份更快、更完整的答案。
与此对应,Muse Spark推出了“深思模式”(Contemplating mode),直接与Gemini Deep Think和GPT Pro的旗舰推理模式正面竞争。多智能体并行并不意味着更长的等待,它用横向扩展取代了纵向堆叠,在可比时延下实现了更优的综合表现。
大多数AI助手的局限在于只能理解用户输入的文字,Muse Spark试图打破这一边界。拍下机场便利店货架,它能识别并筛选出蛋白质含量最高的零食,无需费力辨读食品标签;扫描一款商品,即可即时与同类产品横向比较。这种能力的本质转变,是AI从“等你解释世界”到“直接与你共同观察世界”。当这一能力搭载于Meta AI眼镜,感知的边界将进一步延伸,摄像头即是AI的眼睛。

健康是多模态能力最具现实价值的落地场景。Meta与逾1000名医师合作策划训练数据,使Muse Spark能够就常见健康问题提供更准确、更全面的回应,涵盖图像与图表的解读。用户可获得交互式健康信息展示,直观呈现不同食物的营养成分或运动动作所激活的肌肉群,将枯燥的健康数据变成可视化的个人参考。
视觉编程能力同样值得一提。用户只需一条自然语言提示,即可直接生成可交互的网页应用或小游戏,数独、复古街机、飞行模拟器,乃至一个策划盛大惊喜派对的管理看板,均可一键分享给他人。这不再是“帮你写代码”,而是“帮你造产品”。
与OpenAI和Anthropic不同,Meta手里握着一张任何外部AI公司都无法复制的牌:十亿级别的社交图谱与内容生态。Muse Spark充分利用了这一独特资产。
购物模式整合了Instagram、Facebook和Threads上已有的创作者内容与品牌叙事,为用户提供穿搭建议、家居方案或礼物推荐,灵感来源不是冷冰冰的算法匹配,而是用户已在关注的真实社群。
当用户搜索某个地点或想了解某个热门话题,Meta AI会在对话中同步呈现丰富而相关的背景信息。点击一个地点,即可看到当地居民的公开帖子;询问某件事的全貌,AI会从社区内容中汇聚真实讨论动态,来自用户自己圈子的信息,在最需要的时刻触手可及。
这是一种与通用搜索截然不同的信息整合逻辑:数据源不是泛化的互联网,而是用户自己的社交世界。Meta还透露,随着功能的持续扩展,Reels短视频、图片与动态帖子将被直接织入对话答案,并附带对原创内容创作者的归因致谢,这既是对创作者生态的承诺,也是Meta区别于所有竞争对手的核心护城河。
扎克伯格对此的定义,是“个人超级智能”:“一个不只回答问题,而是真正理解你世界的AI,因为它本就建立在你的世界之上。”
03 三条规模化轴线:下一代已在路上
发布会的另一层信号,比产品本身更值得关注。Meta首次系统性地公开了其规模化路线图的底层逻辑。
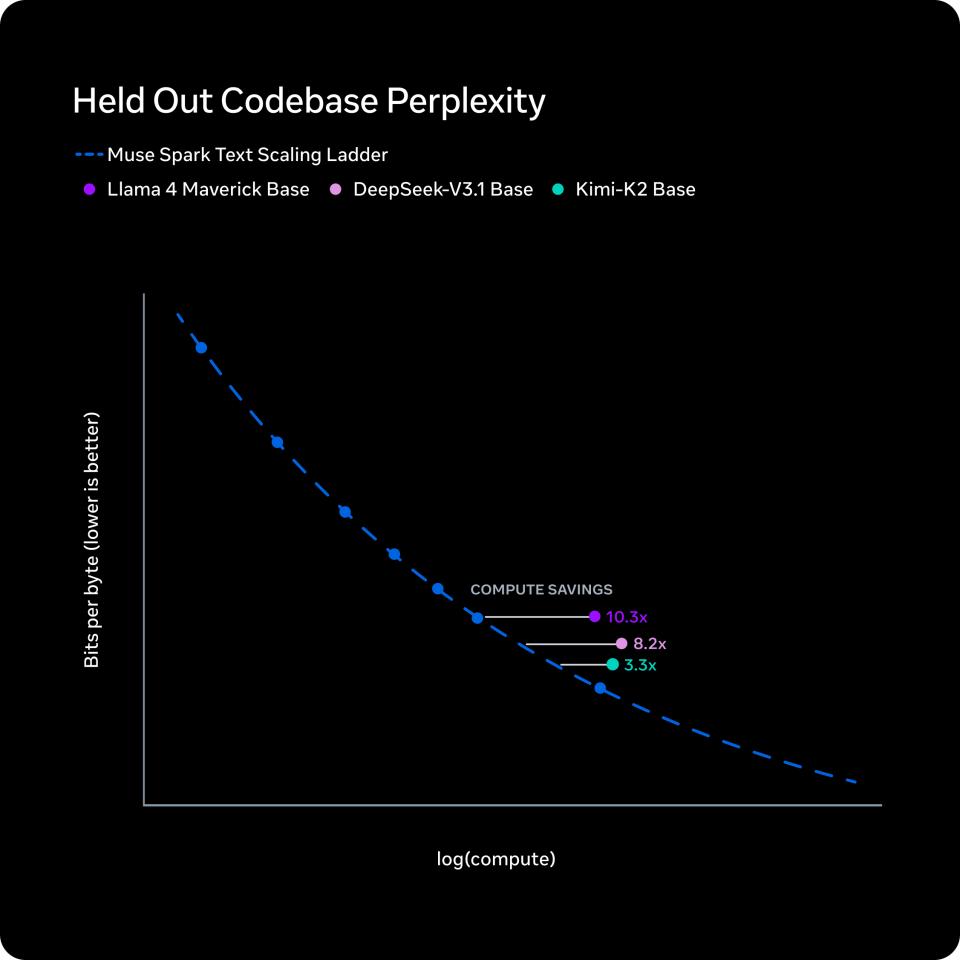
预训练:同等能力,十分之一的算力。过去九个月,Meta从模型架构、优化方法、数据策划三个维度全面重构了预训练技术栈。
通过对一系列小模型拟合规模化定律,Meta得出结论:与Llama 4 Maverick相比,Muse Spark达到相同能力水准所需的训练计算量减少了一个数量级以上。这一效率优势,也使其在主流基础模型横向比较中脱颖而出。
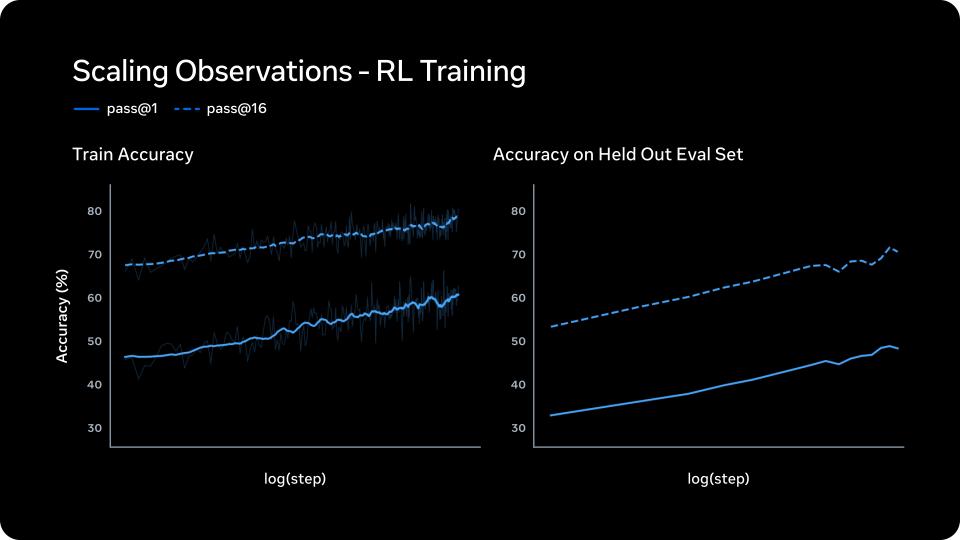
强化学习:平滑增益,可预测泛化。大规模强化学习以训练不稳定著称,但Meta的新技术栈交出了平滑、可预测的增益曲线。
训练数据上pass@1与pass@16呈对数线性增长,表明强化学习在提升模型可靠性的同时,并未损害推理多样性;留存评估集上的准确率同步稳定提升,证明训练收益能够真实泛化到未见任务上——而不是“只会考试”。
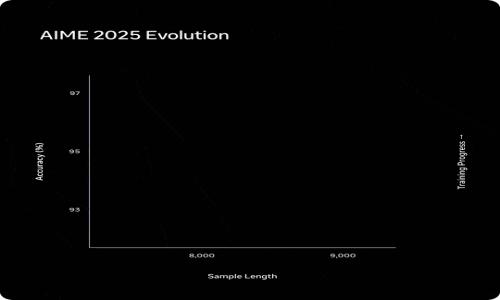
推理时计算:“思维压缩”后再提速。强化学习训练使模型在回答前学会了“思考”,但向数十亿用户提供这一能力,对token效率提出了极高要求。
Meta采用了两个关键手段:其一是思考时长惩罚项,在AIME等评测中触发了一个有趣的相变——模型先通过延长思考时间提升表现,随后长度惩罚触发“思维压缩”,以大幅减少的token数量完成同等难度的推理,之后再次延伸解题链路实现更强表现;其二是多智能体并行编排,在不显著增加响应时延的前提下,用横向扩展取代纵向堆叠。
从这三条轴线来看,Meta在这份技术报告中着墨最多的,恰恰不是当前成绩,而是规模化的可预测性。这正是资本市场和生态合作伙伴最想看到的东西。
04 起点
Muse Spark在设计上“以小巧、快速为先”,这不是能力不足的委婉说法,而是一种刻意选择的方法论。Meta将Muse系列定位为严格递进式的扩展路线:每一代在前代基础上验证、突破,再向更大规模迈进。更大参数量的后续模型已在研发之中。
回到九个月前那个艰难的起点,Meta用Muse Spark证明了两件事:技术栈在有效扩展,组织在重建之后重新凝聚了方向。
但Meta想要追赶OpenAI、Anthropic和谷歌DeepMind等主要竞争对手,仅凭一款“起步款”模型远远不够。该公司后续发布的其他系列模型,将决定扎克伯格的这场豪赌,究竟是翻盘,还是又一次代价高昂的重来。
