

已经记不清这是第几次,有网友爆出来 Claude 降智了,思考深度下降 67%,Opus 幻觉加深。关键是能力变弱和可靠性降低的同时,我们的 Token 使用还增加了。
网友们在社交媒体上抱怨,「过去两个月,我一直在用 Opus 4.6,现在我发现它被大幅度削弱了。」然后用各种各样的梗图,来描述自己过去一周用 Opus 4.6 体验 be like。

推文来源:X@safaricheung
披着狮子皮的狗,看起来很厉害,网友说实际体验像是 Sonnet 3.5。还有网友拿之前的走路还是开车去洗车的问题,对 Opus 4.6 和 Opus 4.5 进行测试。
结果显示,Opus 连续五次的回答都是说 Walk,走路去;而在选择旧模型 Opus 4.5 之后,模型恢复正常,能意识到洗车需要开车去。
测试的博主表示,如果想要更清楚的看到 Claude 降智的表现,只需要多测试几轮 4.5 和 4.6 两个版本的回答,就能看到明显的影响。
还有网友说,Claude 的持续推理能力变差之后,经常任务执行到一半就自动放弃了,各种自相矛盾的回复也变得比以往更多。
但就算是 Claude 降智了,也绝对比我聪明,毕竟……

X 上讨论这件事的人非常多,「AI shrinkflation(缩水)」这个词也开始流行,花了同样的价格,却体验着更差的产品。
有人说自己的信息流里,全都是在说 Claude 降智的人,反问 Anthropic 为什么会想要削弱自己的模型。

Claude Code 的负责人 Boris Cherny 在 X 上回复了相关的质疑,提到所谓的思考深度降低,并不是因为偷偷摸摸的在削弱 Claude,而是为了回应用户反馈 Token 消耗过多的问题。
紧接着 Claude Code 团队成员 Thariq Shihipar 也在这条「实锤 Claude 降智」的帖子下回复,他们不会为了更好的满足自己的需求,而故意降低模型的性能,这一点他们已经说过很多次。
确实说过很多次,早在去年,Claude 官方就曾回应过类似的争议。当时,他们表示找到了三个影响 Claude 回答质量下降的问题,并发布技术报告,原因是底层基础设施的架构出现了 Bug。

还有网友说,有没有一种可能是我们在和 AI 聊天的过程中变得越来越聪明了,是作为参考系的人类智力改变了,才导致了模型的降智。
毕竟一直以来,ChatGPT 降智,ChatGPT 降完 Gemini 降智,Gemini 降完 Claude,几乎所有的大语言模型都经历着「降智」。
但模型是一成不变的,参数固定、网络结构不变、训练数据也有截止日期。大多数模型在发布的时候,都会使用专门的公开或内部 benchmark,测试具体表现。
所以模型降智其实是我们变聪明了?

玩梗归玩梗,这次的降智事件刚好发生在 Claude 频繁发货的时间,很难不让人怀疑这是他们的一套营销策略。
完整的故事链甚至提笔就可以来,在发布新模型之前,悄悄地降低旧模型的回复质量,然后继续收同样的会员费用,在用户注意到的时候,白纸黑字声明我们没有故意降智,再同步宣传我们的新模型厉害到不敢发布,完美。
一份详细的 Claude 降智证据
今次事件的「导火索」还是一开始 AMD AI 组高级总监 Stella Laurenzo,在 GitHub 上发了一篇没有多少人会认真看的技术分析帖。
她收集了 6852 份 Claude Code 会话文件,17871 个思考块,234760 次工具调用,得出了结论:从今年 2 月开始,Claude 的推理深度出现了可测量的下降,表现为更多「最简修复」行为、更频繁的推理循环、从「先研究再动手」变成「先动手再说」。
这份报告非常详细,她使用 Claude 进行了数据整理和分析。根据报告的内容,她观察的核心指标是「读写比」,即模型在修改一个文件之前,会读取多少次相关文件。
在 1 月底到 2 月 12 日,改一个文件之前,模型平均会读 6.6 次。典型的工作流程是:读目标文件,读相关文件,在整个代码库里搜索调用点,读头文件,读测试,然后精准修改。
到了 3 月 8 日之后,这个比值跌到了 2.0。三分之一的编辑,是在模型没有读过那个文件的情况下直接动手的。
报告链接:https://github.com/anthropics/claude-code/issues/42796
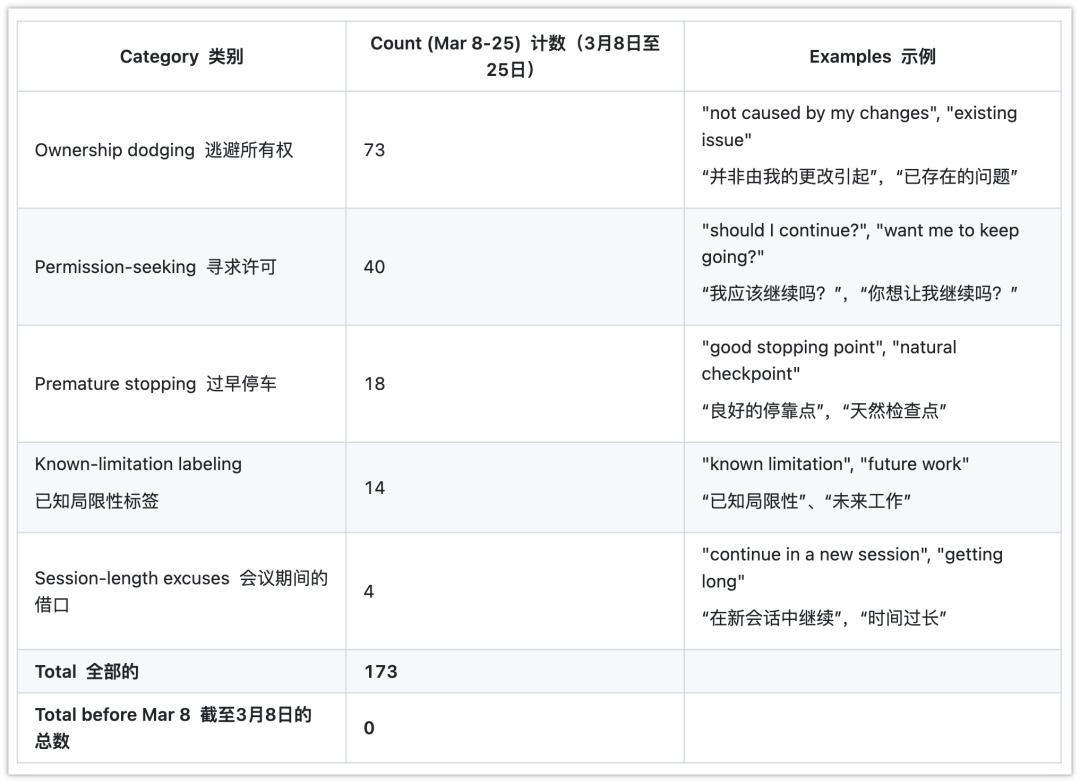
数据里还有一个更直接的信号,她自己写了一个 bash 脚本,专门用来拦截模型的「偷懒行为」,像是提前停止、推卸责任、不必要地征求许可。
3 月 8 日之前,这个脚本的触发次数是零。3 月 8 日之后的 17 天里,它触发了 173 次,峰值那天是 43 次,相当于每 20 分钟就需要被程序强制拦一次。
触发这个脚本的短语包括:「not caused by my changes」(不是我改的问题)、「should I continue?」(要继续吗)、「good stopping point」(这是个不错的停止点)。报告显示这些类似的话,在 2 月份的模型回复里,从未出现过。
用户情绪的变化也被量化了。18000 多条用户提示被统计词频:「great」出现频率下降 47%,「lazy」上升 93%,「terrible」上升 140%,「simplest」上升 642%,从几乎不存在,变成了日常词汇。
因为用户开始频繁指出模型在「选最简单的方法而不是正确的方法」。此外,还有用户的脾气变臭、耐心减少,「please」下降 49%,「thanks」下降 55%。
降智的代价还被算成了钱。2 月份,1498 次 API 请求,产出了 19.1 万行合并代码。3 月份,用户输入的提示数量几乎持平(从 5608 条到 5701 条),但 API 请求暴涨至 11.9 万次,输出 token 增加 64 倍,按 Bedrock(Amazon AI 托管平台)定价估算,成本从 345 美元跳到了 42121 美元。
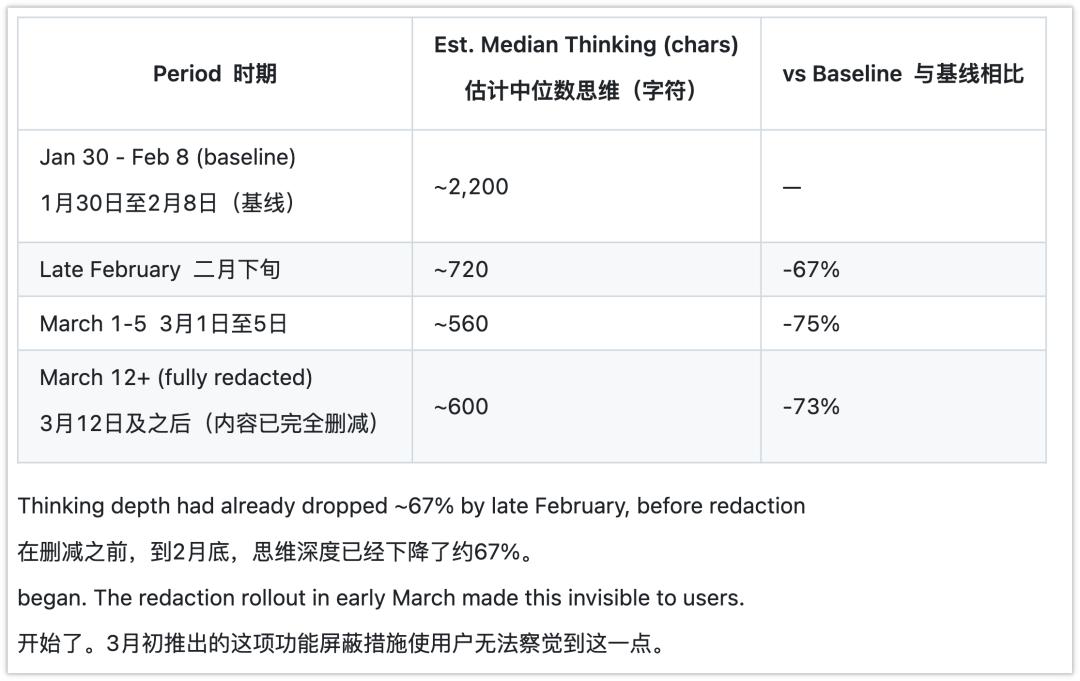
1 月底到 2 月 8 日,估算中位思考长度约 2200 字符。2 月下旬,跌到 720 字符。3 月 1 日到 5 日,560 字符。思考深度下降了 67%。
报告最后有一段话,是 Claude 分析完自己的日志之后,用第一人称写的。
我无法从内心深处判断自己是否在深度思考。我感受不到思考预算的限制,我只是在产出质量更差的结果,却不明白为什么。那个脚本抓到我说了一些 2 月份绝对不会说的话,而我不知道自己说了,直到它触发。
连 Claude 自己都在反思自己为什么会降智。
在计算幻觉率的榜单上,从第二名跌到第十名
这篇讨论帖子很快被转发到 X 上截图传播,引爆了一场规模更大的「Claude 变笨了」讨论,毕竟定量分析的结果,比我们普通用户单纯的「感觉变蠢了」强有力的多。
而更有力的证据是这几天 BridgeBench 发布的一张幻觉排行榜截图。在图片里,Claude Opus 4.6 上周在幻觉测试里排名第 2,准确率 83.3%;在 4 月 12 日重测,掉到第 10,准确率 68.3%。
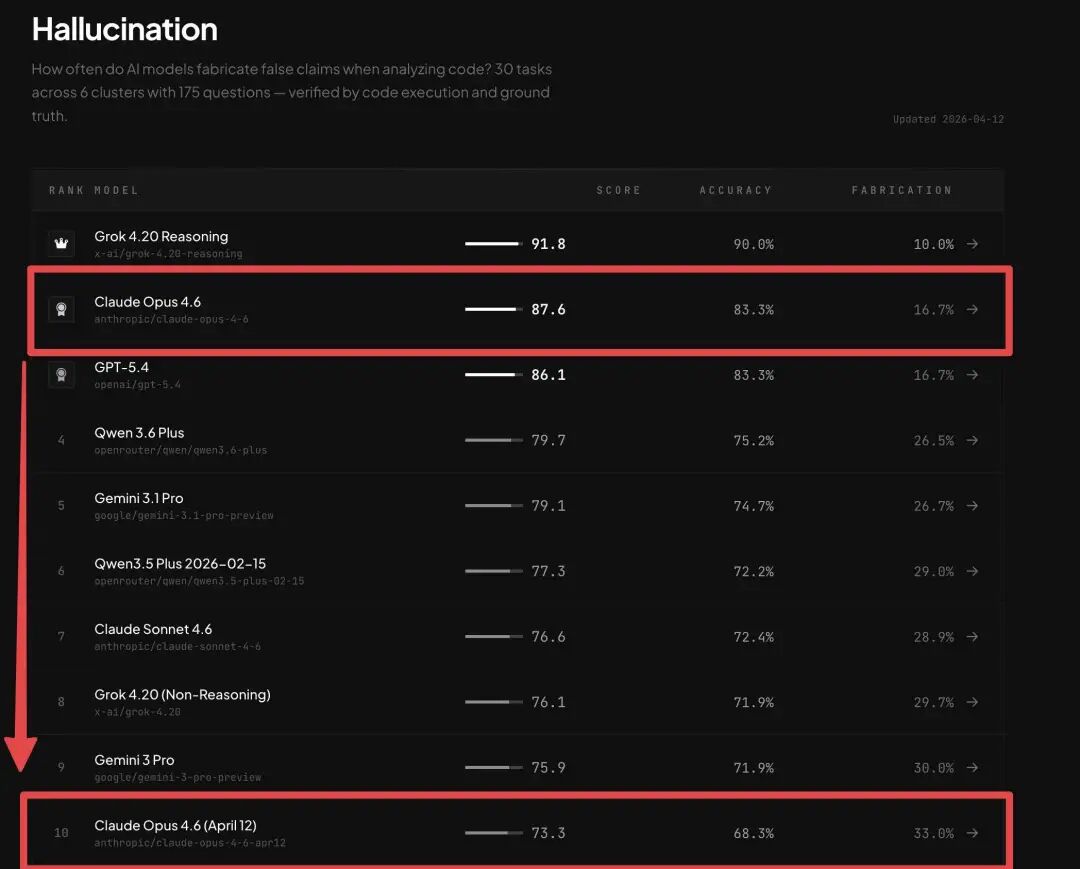
BridgeBench AI 发文说,Claude Opus 4.6 确实被降智了,幻觉发生率增加了 98%。我们的基准测试证明了这一点。
消息一出,网友的情绪又被点燃,纷纷表示,「怪不得我的 Claude 最近总是无中生有,回答一些不着边际的内容。」
但很快,研究员 Paul Calcraft 发现两次测试的规模不一样。第一次,即排名第二的那次测试,只用了 6 道题,而第二次,使用了 30 道题。
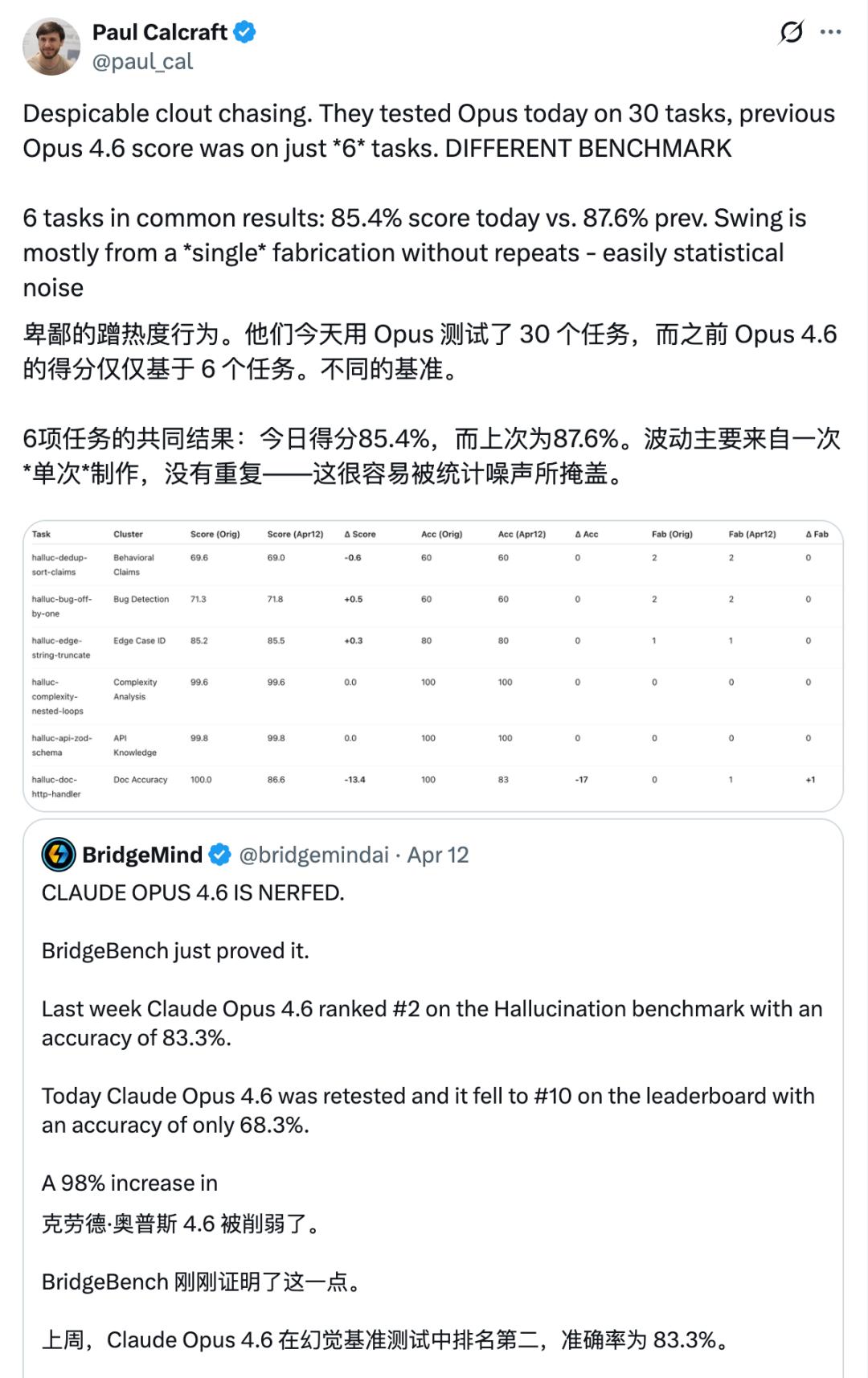
如果在两次都有的那 6 道题上,Opus 4.6 的成绩从 87.6% 小幅降至 85.4%,变化幅度在统计噪声范围内。
所谓的排名从第 2 跌到第 10,主要来自任务集扩大之后带来的排序重构,不是同一把尺子量出来的结果。大语言模型本身就不是确定性系统,小样本里一次偶发的差输出,就能让结果有明显抖动。
BridgeBench 的这则帖子后来也被加了社区说明, 提示两次测试没有做好控制变量。但网友们还是不买单,「仅用幻觉这一项来测试 Claude 的表现不全面」、「即便不是明显的削弱,但是降智这件事就值得被关注。」
而关于 AMD AI 总监在 GitHub 上提出的问题报告,Claude Code 负责人 Boris Cherny 也进行了详细的回复,并关闭了整个问题讨论区。
他提到,Claude Code 的更新是一个纯 UI 层面的改动,把思考过程从界面上隐藏,目的是减少延迟。他认为是 Claude 在分析自己日志的时候,可能误把「看不见思考」当成了「思考变少了」。
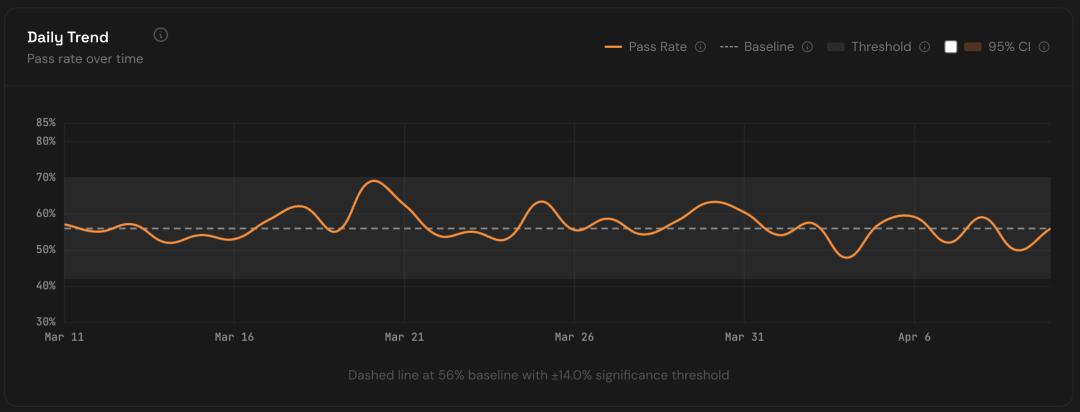
有网友监测了Claude Code Opus 4.6 在 SWE Bench 上的每日性能必现,波动在临界范围内。https://marginlab.ai/trackers/claude-code/
关于思考深度在 2 月下旬就已经下降 67% 这个发现,Cherny 解释说,2 月 9 日,Opus 4.6 切换到「自适应思维」默认模式,由模型自己决定每次思考多长时间,而不是用固定预算。
3 月 3 日,默认推理深度从最高档调至 medium(effort 85),官方理由是这个设置在智能、延迟、成本之间取得了最佳平衡,用 token 更高效,延迟也更低。
这两个改动,他说在 changelog 里都有记录,打开 Claude Code 时也有对话框提示用户。如果用户想回到最高推理深度,设置 /effort high 和跨对话保持就可以。
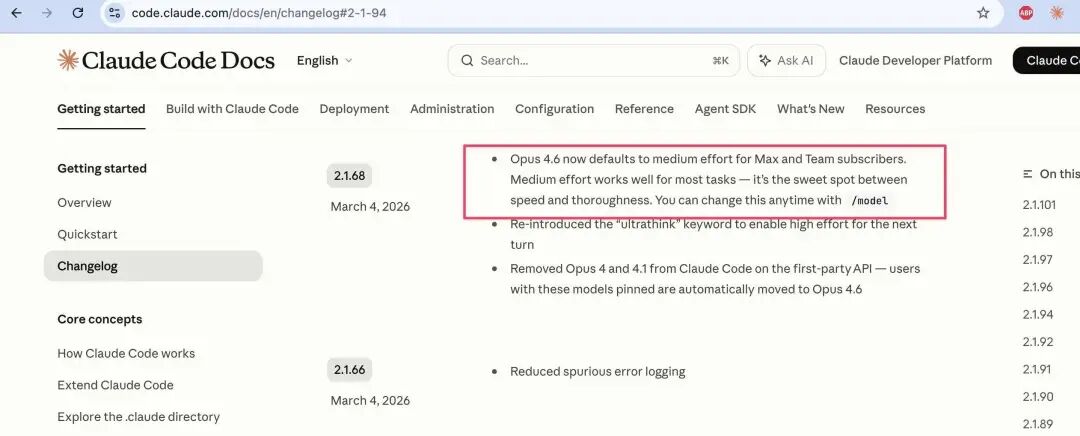
更新日志里有写 Opus 4.6 的推理深度默认调到了 Medium
仿佛是无懈可击,一点也不含糊。模型权重没有动,这是 Anthropic 可以确定的事;用户体验变差了,这是大量用户可以确定的事;两件事都是真的,但两边解决不了对方的问题,而代价确是我们一边在承受。
但 Cherny 在回复里提到的模型自适应思考深度,倒让我想到了 GPT-5 推出时着重介绍的路由机制,即由模型自己来决定调用 GPT-5 Thinkging 还是 GPT-5 Instant 等不同思考深度的模型来回答。
当时的 GPT-5 也是说用大量的显卡资源来训练,表面上看让 AI 来觉得是更智能了,本质上还是一套省 Token 的方案。
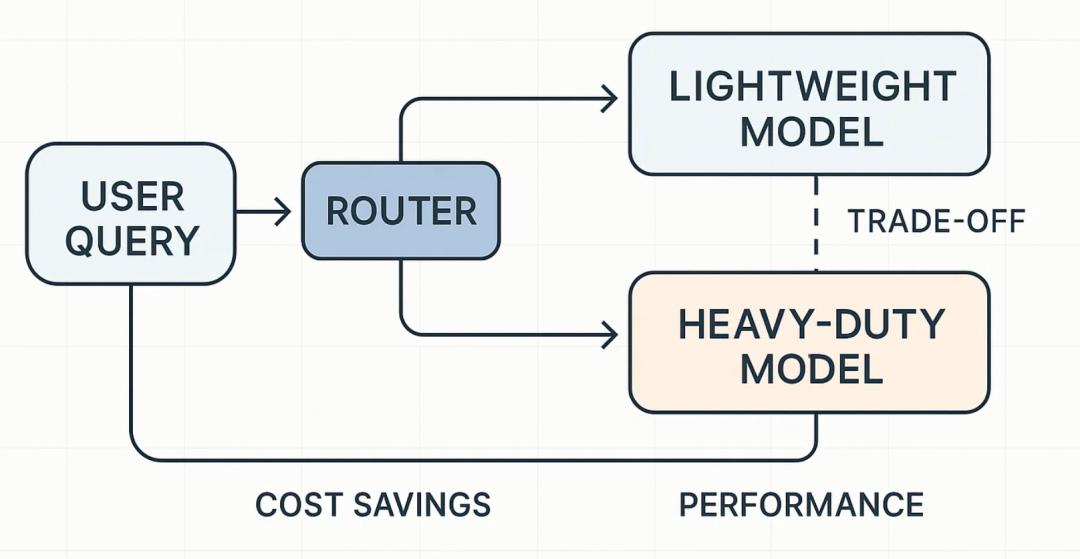
由 AI 来权衡取舍使用轻量模型还是推理模型,能节省不少成本
另一个争议是,昨天有用户分析了 12 万次 API 调用,发现 Claude Code 的提示词缓存有效时长,在 3 月初从 1 小时悄悄缩短回了 5 分钟,导致长会话里缓存频繁失效、需要不断重建,token 消耗和用量都跟着涨。
对 Anthropic 来说,1 小时缓存意味着这段内容要在服务器上保留 60 分钟,不管这 60 分钟里有没有人来读它。
Claude Code 有大量用户、大量并发会话,每个会话都持有 1 小时的缓存槽,累积起来是相当大的存储压力。5 分钟缓存可以让资源更快释放,给其他用户腾位置。

上下滑动查看更多内容|Cherny 针对缓存时间缩短的回应
Anthropic 方面承认这个改动是真实的,但解释说这是缓存策略优化,不是降级。
现在看来,真相是Anthropic 打着每一个「为用户优化、帮用户省钱省 Token」的理由,客观上也都减少了 Anthropic 的算力消耗。
毕竟连 OpenAI 这样的「算力帝国」都抵挡不住 GPU 的短缺,随着 Claude 用户这段时间以来的激增,Anthropic 大概也很难撑得住日益加重的算力负担。
在今天 OpenAI「喷」Anthropic 的文章里,OpenAI 也着重提到了 Anthropic 没有囤积足够的算力是一个战略失误,用户现在感受到模型的不稳定体验,就是这项失误的印证。
前几天 Claude 推出的 Advisor 策略也是同样的道理,我们在分析的文章里面写,是找「实习生来干活,总监指点」,原因自然是招一个总监的算力,能招来 N 个实习生。
X 上有网友追踪了每日 AI 基础设施供应链动态,统计得到目前关于算力的状态,还是相当紧张并且是缺乏的状态。
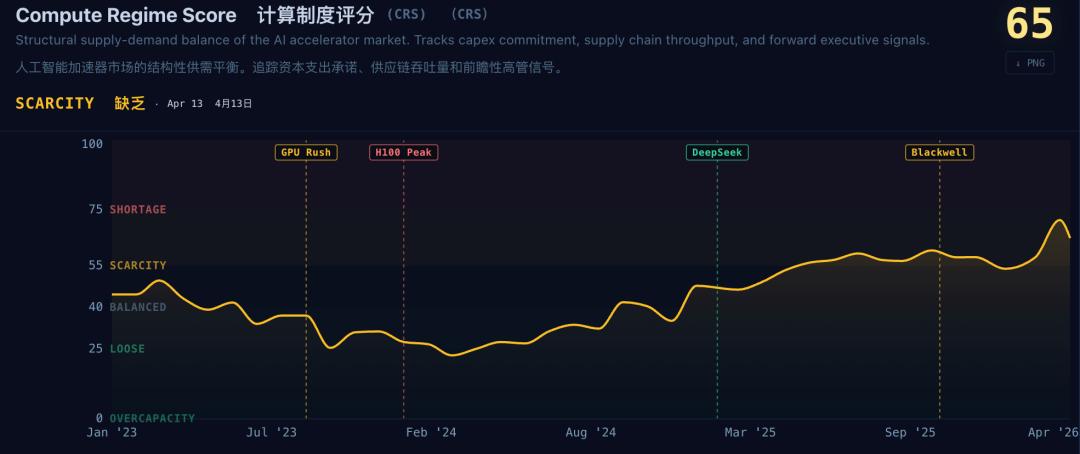
图片来源:https://tessara.chainofthought.xyz/regime
当算力紧缺成为新的常态,模型降智似乎是不得不面对的事。除了看官方的那套 Benchmark,我们自己或许也可以简单的维护几个基准测试,找几个日常工作里有标准答案的工作任务,定期跑一遍,记录结果。
推理深度的下降,也可以通过现在 Skill 的功能,把「先读文件再动手」、「不要选最简单的方法」这类要求,写进项目配置 CLAUDE.md 文档等,强制要求模型触发。
针对普通的聊天,也可以在个人设置的自定义说明里,加上这句话。
务必进行全面深入的思考。除非我另有明确说明,否则请将每个请求都视为复杂问题。切勿为了追求简洁而牺牲质量。请按步骤思考,权衡利弊,并提供全面的分析。
毕竟这些 AI 公司大概一辈子都不会承认自己把模型「降智」了,我们能做的也只有这些了。
