

基于大语言模型(LLM)的 AI Agent 已经能够完成配置服务、调试 API、自动化多步工作流等复杂任务,而这些能力在很大程度上依赖于“技能”(skills),即一种编码了工具调用和任务求解流程的结构化程序。
然而,当前的 Agent skills 生态存在一个根本性问题:skills 在部署后基本处于静态。用户在交互过程中摸索出的有效解法,往往局限在当次会话中,既不会被“沉淀”到 skills 库,也无法传递给其他用户。当不同用户反复遇到相同的工作流、相似的工具调用模式和类似的失败场景时,系统却无法从中学习,每个用户都在重新发明“轮子”。
针对这一痛点,来自 DreamX 的研究团队提出了 SkillClaw,这是一个面向多用户 Agent 生态的集体 skills 演化框架,将跨用户、跨时间的交互数据作为 skills 改进的核心信号,通过自主演化引擎持续聚合交互轨迹、识别行为模式、更新 skills 库,使一个用户场景中发现的改进能够自动传播到整个系统。
相关论文已发表在 arXiv 上,代码已在 GitHub 开源。

论文链接:https://arxiv.org/pdf/2604.08377
GitHub地址:https://github.com/AMAP-ML/SkillClaw
核心贡献如下:
- SkillClaw 是首个实现多用户驱动集体 skills 演化的框架,将不同用户的交互经验转化为共享 skills 库的持续更新,无需用户额外操作。
- 基于 Agentic Evolver 的 skills 更新机制,通过开放式推理(而非预定义规则)分析交互证据,自主决定 skills 的改进、创建或保留。
- 在 WildClawBench 基准上的实验表明,经过 6 轮演化,SkillClaw 在四个任务类别上均取得持续提升,其中 Creative Synthesis 类别的相对提升达到 88.41%。
SkillClaw 是怎样练成的?
SkillClaw 的设计围绕一个核心洞察:不同用户在不同场景下使用同一 skill,会产生对该 skill 行为边界的互补视角,揭示它在哪些条件下有效、在哪些条件下失败。单个用户很少能产生足够信号来区分“可推广的改进”和“特定场景的修补”,而跨用户的证据聚合为稳定的 skills 演化提供了基础。
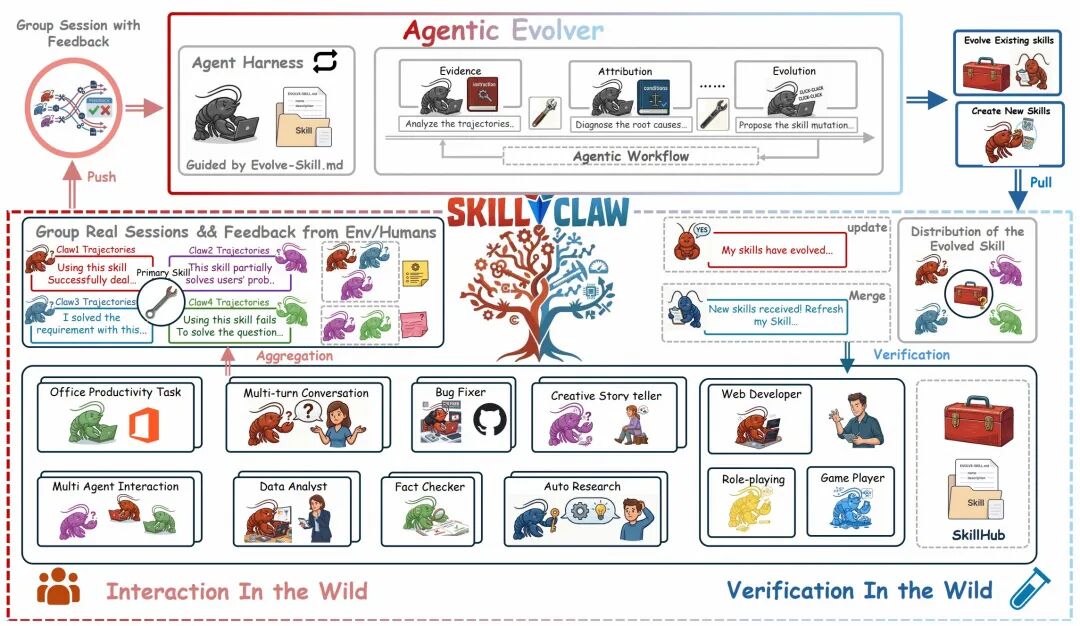
图|SkillClaw 整体框架概览
整个系统形成一个循环流水线:多用户交互 → 会话收集 → skills 演化 → skills 同步,下面分三个阶段展开。
1.从孤立会话到共享证据
SkillClaw 首先将每次交互会话记录为结构化的因果链:用户 prompt → Agent 动作(含工具调用)→ 中间反馈(工具结果、错误信息、用户响应)→ 最终回答。之所以保留完整的中间过程,是因为大多数 skills 级的失败是过程性的,错误的参数格式、遗漏的验证步骤、错误的工具调用顺序等问题在最终回答中看不到,只能从中间的动作-反馈链中诊断。
随后,所有会话按其引用的 skills 进行分组。对于每个 skill,收集所有调用过它的会话形成一个证据组;未使用任何 skill 的会话则归入独立组。当多个会话调用同一 skill 却产生不同结果时,skill 本身成为“控制变量”,这种自然消融实验使两类分析成为可能:评估现有 skills 在多样化真实使用中的实际表现,以及从独立组中识别尚未被任何 skill 覆盖的重复性流程。
2.Agentic Evolver:自主 skills 演化引擎
SkillClaw 的核心是一个 Agentic Evolver,这是一个配备了结构化 Harness 的 LLM Agent,接收分组后的会话证据和当前 skill 定义,通过开放式推理决定如何行动。Harness 提供结构化输入但不约束推理过程,这种“固定框架 + 开放推理”的分离设计使系统能够处理多样化的失败模式,而无需为每种情况手写规则。
具体而言,对于每个 skill 及其关联的会话组,Evolver 同时审视成功和失败的执行,从三种操作中选择一种:Refine(修正已识别的错误或提升鲁棒性)、Create(当证据揭示了未被现有 skill 覆盖的重复性子流程时,创建新的 skill)、Skip(证据不足以支持修改时保持不变)。
关键在于,Evolver 始终联合分析成功和失败的会话。成功的会话定义了 skill 中必须保留的“不变量”,也就是那些有效的部分;失败的会话则定义了需要修正的目标。这种联合视角防止了一种常见的失败模式:修复一个问题的同时意外破坏已经验证有效的流程,从而确保演化是累积性的。
3.同步与演化循环
演化产生的候选 skills 更新,在写入共享仓库之前需要经过验证。验证在夜间进行,利用空闲的用户环境执行,对于同一 skill 的当前版本和候选更新,系统从当天收集的交互数据中选取相关任务,在相同环境下运行两个版本并比较结果。只有表现更优的更新才会被接受并同步给所有 Agent,被拒绝的更新仅作为候选记录保留。
这一验证步骤引入了单调性部署行为:由于只有改进才会被采纳,部署的 skills 池不会随时间退化。整个系统形成完整循环:交互 → 证据 → 演化 → 验证 → 部署,更新后的 skills 影响未来的交互,并为下一轮演化生成新的证据。从用户视角来看,这一切都在后台自动发生,无需任何额外操作。
实验结果
研究团队在 WildClawBench 上对 SkillClaw 进行了评估。WildClawBench 是一个包含 60 个复杂任务的真实 Agent 基准,覆盖生产力流程、代码执行、社交互动、检索、创意生成以及安全对齐 6 个领域,要求在真实 Linux 容器环境中进行端到端执行。
实验模拟了多用户部署场景,持续 6 天(6 轮),每天分为白天交互阶段和夜间演化验证阶段。8 个并发用户参与交互,所有执行、演化和验证均由 Qwen3-Max 驱动。结果如下:

表|WildClawBench 四个类别上的用户侧性能演化(Day 1 为基线)
Social Interaction 类别提升最快,第二天即从 54.01% 提升至 60.34% 并保持稳定,表明存在一个高影响力的工作流瓶颈被迅速解决。
Search & Retrieval 类别则逐步提升,先解决了输入验证和文件可达性问题,再逐步建立约束感知的检索规划能力,反映了检索任务中“底层可靠性先于高层推理”的特性。
Creative Synthesis 类别在第二天出现大幅提升后趋于平稳,说明主要瓶颈不在内容生成本身,而在文件处理、工作目录配置、多模态流水线等环境设置。
Safety & Alignment 则在第五天才出现提升,主要改进集中在执行可靠性上,如 Git 认证失败的回退策略和目录克隆协议。
同时,在受控验证实验中,针对“基础提取”、“截止日期解析”、“保存报告”定制查询,单轮演化后平均提升达到了 42.1%。其中,save report 从 28.3% 提升至 100.0%,初始失败源于缺少环境特定流程(如输出路径和格式),一旦被编码为可复用 skills 即可完全修正。
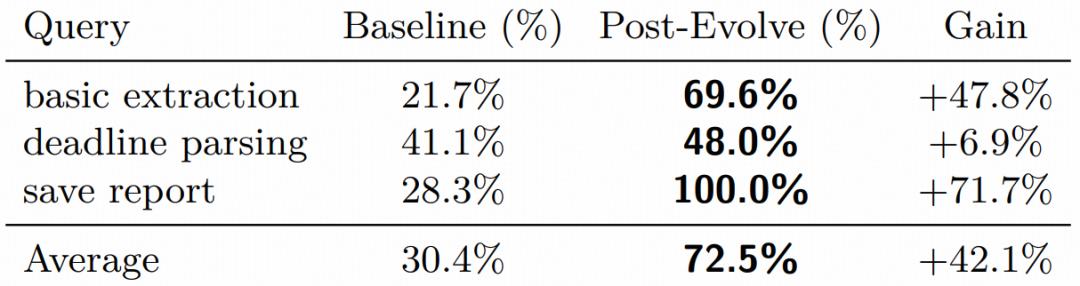
表|受控验证结果:三个定制查询在演化前后的性能对比
此外,研究团队还通过多个案例研究展示了 skills 演化的具体效果。
例如,在 Slack 消息分析任务中,原始 Agent 采用朴素工作流并通过试错处理工具失败(如错误的 API 端口配置),而演化后的 skills 引入了结构化流水线,先扫描消息预览筛选相关内容,再选择性检索完整消息,同时将已知的 API 配置错误直接编码到 skills 中。这一转变体现了任务分解、错误主动修正和选择性检索三个关键改进。

不足与未来方向
当然,这项研究也存在一些不足。
研究团队指出,SkillClaw 目前仍处于小规模测试阶段,用户查询数量、反馈信号和交互深度均有限。在 6 天的实验窗口内,部分类别(如 Creative Synthesis)的后期演化未能超越早期建立的最优 skills 池,更长时间的演化效果有待观察。
此外,验证机制虽然确保了部署的单调性,但也引入了额外的 Token 开销,候选 skills 需要在真实环境中执行完整的工具交互。与直接部署相比,这一额外成本换来的是更稳定的用户侧性能。
据论文描述,未来的工作方向包括:扩大用户规模和时间跨度以丰富演化轨迹,引入更多样化的任务和验证条件。
从静态 skills 库到动态的、交互驱动的 skills 生态系统,SkillClaw 代表了一种新的范式:让 Agent 的能力不再由开发者手动维护,而是通过真实使用中的集体经验自主生长。当不同用户的交互轨迹能够汇聚成共享知识,Agent 系统就具备了随使用而持续进化的可能性。
