

美国医学会旗下期刊:现阶段 AI 难以直接应用于临床决策,早期诊断错误率达到 80%
2026-04-17
/ 阅读约2分钟
来源:IT之家
JAMA Network Open发文称大型语言模型在临床推理存在短板,早期鉴别诊断错误率超80%。研究对21款主流大模型评测,AI在最终诊断和治疗管理较准,早期鉴别诊断差,难以直接用于临床决策。
IT之家 4 月 17 日消息,美国医学会旗下期刊 JAMA Network Open 发文,透露业界现有的大型语言模型(LLMs)在临床推理方面仍存在明显短板,尤其是在早期的鉴别诊断阶段,错误率普遍超过 80%。
IT之家参考论文获悉,研究团队利用 29 个标准化临床案例对 GPT-5、Claude 4.5 Opus、Gemini 3、Grok 4 等 21 款主流大模型进行评测,模拟完整医疗决策流程,覆盖鉴别诊断、检查选择、最终诊断、治疗管理及其他临床推理五个阶段。
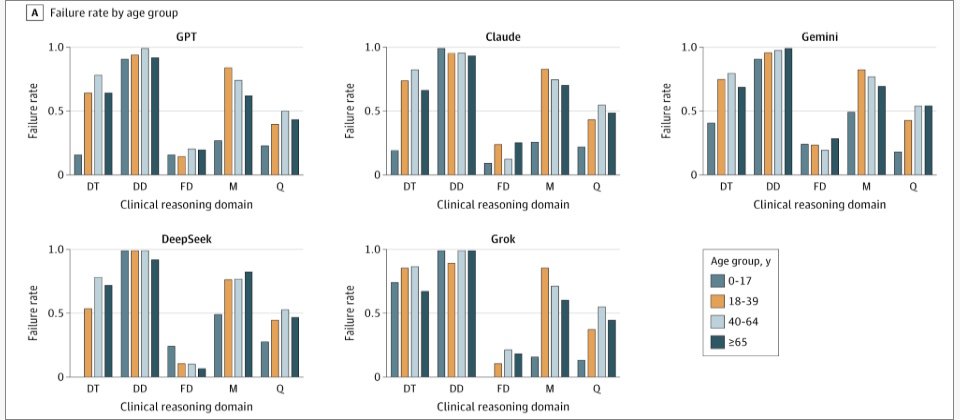
结果显示,各大模型整体表现存在一定差异,同时在不同诊疗阶段呈现出明显不均衡。具体来看,AI 在“最终诊断”和“治疗管理”环节的准确率相对较高,“检查选择”和其他推理能力处于中等水平,而在最早期的“鉴别诊断”阶段表现最差,错误率普遍超过 80%,也就是模型通常会误判病人的具体疾病。
进一步分析认为,AI 更擅长在信息相对完整的情况下给出答案,但在信息不足、需要逐步推理的早期阶段,往往容易过早收敛到单一结论,导致当前 AI 难以直接应用于临床决策。相比之下,临床医生通常会在初期保留多种可能性,并随着检查结果和信息积累不断修正判断,最终定论患者的具体疾病。
