

年初至今,中国AI原生企业估值膨胀的速度,像极了2023年美国的镜像。时至今日,OpenAI和Anthropic的万亿美元IPO的前景,让新一轮市场兴奋传递过来。真正的赢家未必已经出现,但大家开始知道,赢家应该长什么样。
本周,正在谋划上市的月之暗面(Kimi)与阶跃星辰(Stepfun),前后脚融资20亿美元与25亿美元,比智谱(Z.ai)与稀宇科技(MiniMax)年初港股IPO融得还多几倍,后两者当前市值分别为525亿美元与300亿美元。这几家主要在2023年前后组建公司,估值都已在百亿美元之上。
而最沉得住气的DeepSeek,却在掀动中国风投市场最戏剧性的情绪。
4月,在发布新模型前夕,市场传言DeepSeek松口融资,估值100亿美元起。此后,在不到1个月的时间里,这个数字在外界的口中,就不断从200亿美元、450亿美元,跳涨至最新约515亿美元(即3500亿元人民币)。传言中的最新融资金额约75亿美元(即500亿元人民币),差不多快赶上上个月整个公司估值了。而它此前还是一家不以市场为重的AI实验室。
这一幕让人回想起2023年的美国。2023年年初,微软向OpenAI追加投资,当时公司估值略低于300亿美元;发布ChatGPT没多久的它,刚开始实现显著的营收增长,但仍然尚未抛弃“利润上限”架构。到了10月,OpenAI估值已经来到了800亿至900亿美元,当时,OpenAI的年化收入(ARR)达到13亿美元。
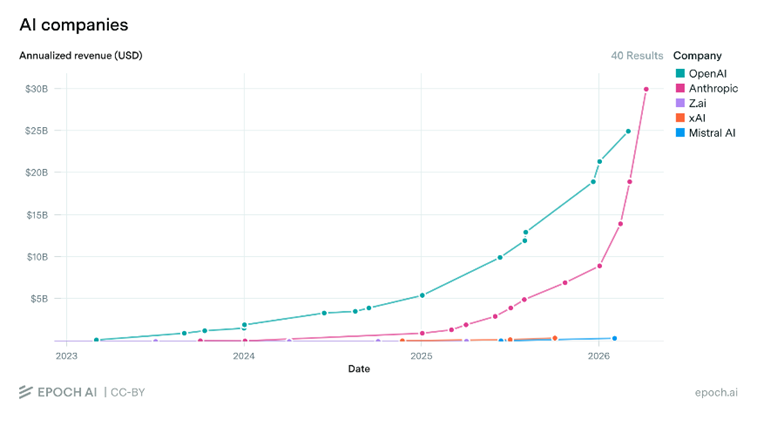
国内资金正在慷慨地给本土企业以当年美国市场的估值。它们并非无视这些短期内无法赶上的短板:从模型上看,中国仍然距离美国前沿模型存在半年左右的差距;从硬件上看,中国国产芯片无论是能效还是性价比,才刚刚勉强赶上英伟达的H200;从财务上看,它们也没有摆脱收入与亏损同步高速增长的早期阶段。那么,市场的锚点究竟是什么?
在OpenAI估值膨胀的2023年,不少美国AI初创企业也在加速融资,只不过,除了当时获得亚马逊AWS注资40亿美元的Anthropic,在今年成功实现了对OpenAI的逆转,其他多数已经消失在时间里。它们包括Inflection、CharacterAI、AdeptAI等等,莫不如此;马斯克的xAI也在并入SpaceX之后解散了。
活下来的关键是拥有自己的前沿模型,并持续不断地改进与迭代,确保始终站在第一梯队。而在技术上指引这条道路的,无疑是AI原生的一代人,他们要能参与一线研发。至少,要在战略上坚定支持,组织架构围绕研究生长,这也需要掌舵者真正懂技术。
创始人懂不懂AI,成为决定成败的一个重要因素。Anthropic的阿莫迪(Dario Amodei)是AI研究出身;宫斗之前的OpenAI拥有联合创始人伊莱亚(Ilya Sutskever);创立DeepMind的哈萨比斯(Demis Hassabis)从一开始就追求AGI,而谷歌联合创始人布林(Sergey Brin)选择从退休状态重启创始人模式。马斯克获得的评价则来自他当年在OpenAI的联合创始人布洛克曼:“他懂火箭,懂电动车,但他当时不懂、而且我相信现在也不懂AI。”
马斯克真的(不)懂AI吗 | 笔记
2026/05/06 完整阅读 >
谷歌再亮红灯,布林挂帅编码突击队
2026/04/21 完整阅读 >
在中国,常被外界统称为AI“六小虎”的企业中,零一万物与百川智能,离开聚光灯已久。或许是它们无法在技术上精进,或许是它们误判了产业趋势,在大模型扩展定律尚未真正放缓的情况下,早早转向了应用和行业解决方案。而仍在牌桌上的其余4家,虽然路径各异,但都跟上了Agentic时代的节奏。
美国艾伦人工智能研究所(Ai2)的Nathan,最近在中国拜访了数家大模型企业,记录下他的核心观察:这些实验室的核心贡献者中,有很大一部分是活跃的年轻人,他们快速学习,乐于谦逊地摒弃所有先入之见;而这些实验室的领导者,都在谈论如何培养更具雄心的研究文化。他们都对DeepSeek的研究品味充满敬意。
终于,商业变现确定性的信号日益明显。春节前后,Anthropic的Claude Opus 4.6、OpenAI的GPT-5.3-Codex以及谷歌的Gemini-3.1-Pro相继发布,显著提升了智能体的能力,也让大模型厂商看到了更清晰的商业化路径。就连阿莫迪也被80倍的收入增速吓到了,他的算力是为10倍速准备的。
但OpenAI与Anthropic仍在筹备上市,在这之前,MiniMax与智谱享受到了时间的红利。它们是Claude Code与OpenClaw在中国的映射。同时,月之暗面与阶跃星辰也开始启动大额融资,传出筹备上市的消息。稀缺性的窗口,不会永远敞开。
智谱与MiniMax,市场对智能体的焦虑与亢奋
2026/02/22 完整阅读 >
如今,最新的GPT-5.5与Claude-Opus-4.7领先,但DeepSeek-V4、GLM-5.1、Kimi-K2.6等模型依然能够保证在发布间隔与模型性能上跟随不掉队。它们更便宜,也有机会在高速增长的市场中,差异化地捕获属于自己的价值。而那些缺乏自研模型能力的企业,不仅要承受溢价支付的API成本,甚至可能直接被蚕食掉自身业务;AI原生的创始人,要比光靠嘴上喊着All in AI更让市场有信心。
三年前,不少互联网时代的风投资金对这些AI原生企业并不买账。当时的中国AI“六小虎”,融资金额简直就是小打小闹,远远低于美国同行。部分人更是怀疑,它们最好的结局,就是“卖给大厂”。但事实上,在相当长一段时间里,中国的互联网巨头对自研模型和投资AI初创企业都并不“亢奋”。
直到这几年来,OpenAI与Anthropic的叙事,建立了另一种市场预期:传统科技巨头无法扼杀AI原生企业,它们可以跑得更快。
从ChatGPT发布至今,市场恐怕没有料到,微软、亚马逊、Meta以及苹果等巨头,在自研模型层面竟如此不堪一击。组织惯性、内部协调成本、战略优先级分散、对旧业务的路径依赖,统统成了拖累。它们并没有像互联网时代那样,牢牢掌握应用层入口,至少在企业服务层如此。
当然,它们也享受到了AI的红利,但更多集中在算力基础设施层面。美国领先的超大规模云服务提供商,积压订单已累计超过2万亿美元,其中可以明确客户的部分,大约一半以上来自OpenAI和Anthropic这两家AI原生企业。后者才是整个AI生态的发动机。
在中国,字节跳动与阿里巴巴在AI技术栈上的布局更接近美国的谷歌,涵盖了芯片、云服务、模型与应用。但同样没有给DeepSeek们,制造互联网时代那样令人胆寒的压力。或许,这也让国内投资者相信,当新的技术范式到来时,中国也能诞生自己的OpenAI或Anthropic。
当OpenAI和Anthropic证明,AI原生公司可以独立成长为万亿美元的核心节点后,中国资本终于开始用同样的逻辑,为本土前沿模型公司重新定价,而DeepSeek则成为这一轮重估中最具象征意义的公司。在新模型发布后,DeepSeek也因此迎来了自己的重估。不过,它的融资消息,仍是亦真亦假的传言。
DeepSeek-V4,需要一次重估
2026/04/26 完整阅读 >
DeepSeek需要融资。DeepSeek曾承认,训练算力约束了旗舰模型在世界知识上的覆盖广度;它的推理也常常不堪重负,难以取得用户反馈的“学习环境”。它也需要为员工对持股价值的锚定提供答案。
不过,作为一家自认“AGI属于每个人”的AI原生企业,它更需要长期主义的资金。它如今坚持与国产芯片协同,探索一条在更低单位token价格的前提下通往“AGI普惠”的目的地。这注定是一条更慢、更难、也更不容易被资本市场即时奖励的道路。
这意味着,DeepSeek及其创始人梁文锋,一方面要继续拥有绝对的话语权,另一方面也需要一个更注重通盘战略而非短期财务回报的投资方。
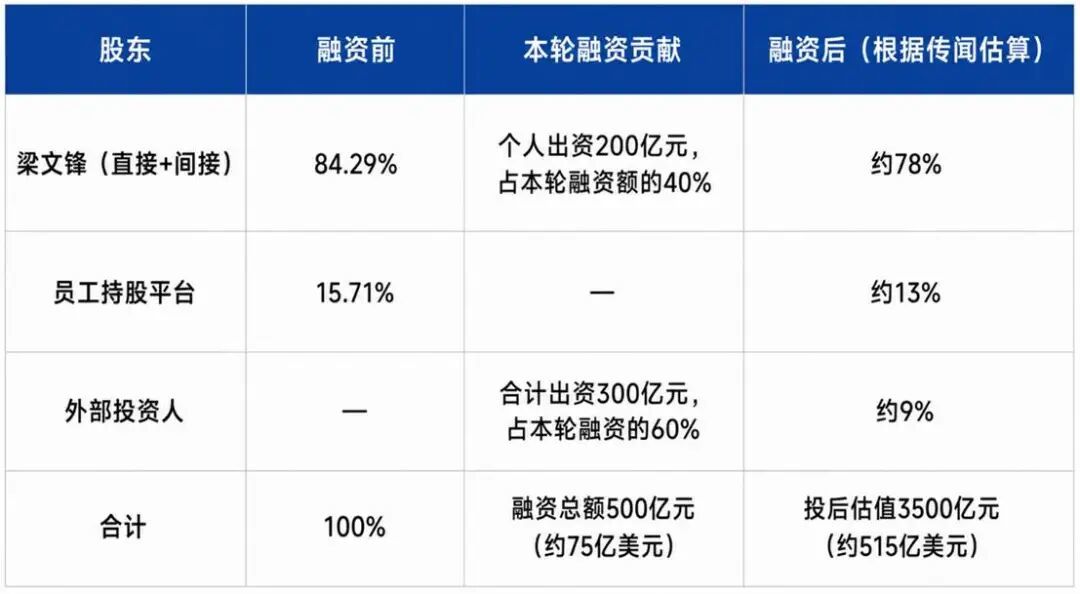
按照媒体的说法,梁文锋可能在本轮融资中以个人身份注资200亿元人民币,约占总融资额的40%。而国家人工智能产业投资基金,预计成为第二大投资方。
这恰恰是理解DeepSeek融资传闻最关键的视角之一。近期,DeepSeek(杭州深度求索人工智能基础技术研究有限公司)刚经历一次股价架构调整,梁文锋直接持股比例由1%升至34%,员工持股平台持股比例降至66%;此次变化后,梁文锋以间接、直接方式持有DeepSeek约84.29%股权。
如果市场传闻大体属实,即这轮进场的投资人,以515亿美元的投后估值,注资75美元,其中40%又来自梁文锋自己。那么,在外部融资之后,仅以金额计,综合原始股权稀释与新增认购的影响,梁文锋在外部融资后的持股比例约为78%左右,对公司的技术路线、商业模式等核心战略拥有绝对的控制权。
至于第二大投资方的选择,让人觉得传闻可信的地方在于,国家大基金既是长期主义的,又聚焦于国产算力生态的软硬件协同。这与DeepSeek当前与华为、寒武纪等伙伴的绑定,以及从“推理自由”逐步迈向“训练自由”的技术路线,是高度一致的。
关于其他科技巨头投资的种种传闻,在梁文锋下注绝对控制,以及新入资本可能体现的国家意志面前,已经不足挂齿了。
