

近期和一些AI开发者、企业智能化项目负责人交流,我们明显感受到,业内正在累积一种对AI的疲惫感。
开发者最经常说的一句话是,要学的太多了,模型太难选了。
以前市面上哪款模型综合能力遥遥领先,直接订阅就行了。一个有短板,订阅好几个,也完全够用了。但现在不是的,没有一款模型具备绝对碾压的垄断优势,token还不断涨价,开发者需要不停更换模型,吃透每款模型的特性,精打细算,反复在具体的业务场景中实测对比,普遍存在着巨大的学习疲劳和选择障碍。
硅谷甚至出现了一种说法,越懂AI、越会用AI的人就越焦虑,不仅没有减少工作时间,反而大大增加了工作时间。
如果懒得选型,直接上顶级的模型呢?那就是“一分钱一分货,十分钱三分货”。

成本高到微软都觉得肉疼,前不久宣布停用Claude Code,迁移到自家的GitHub Copilot CLI。而自己手里没有备胎模型的公司,比如uber,每位工程师每月的Claude Code工具开销高达500至2000美元,直接导致Uber在今年4月就提前烧完了全年的AI预算。
上述烦恼,是全球1%技术精英们专属的“甜蜜的负担”。
更多普通人所感受到的,则是AI带来的割裂与无奈。

有人说,AI不是平权工具,是导致群体两极分化的杠杆。
顶级大模型变成了精英阶层的专属工具,放大了他们原本就有的优势,而大众始终处于被淘汰的恐慌与焦虑之中。为了跟上这股浪潮,非技术的职场人被迫学AI,折腾半天发现原本半小时用Excel就能搞定的基础工作,硬生生靠AI折腾了好几天。
至此,AI的使用局面已经变得诡异了:没有人能从中轻松获益,所有人都在被动焦虑与内耗。到底是什么造成了这一切?2026已经过半,应该来聊一聊模型的中场危机了。
01 停滞的“掐尖”红利
教育行业有个说法叫“掐尖”,一个学校优先筛选整个区域的优等生,外界看起来教学水平高,其实是优质生源足够多。一旦不能掐尖,升学率就会回归均值。AI让开发者们越来越疲惫,也是一样的逻辑。
过去市面上存在绝对的模型强者,开发者直接锁定头部模型,比如2025年初用Deepseek R1做问答,2026年用seedance 2.0生成视频,用GPT做图文排版,一键get最优效果,这就是掐尖红利。能“掐尖”的时代,短暂停滞了。

可能有人疑惑:明明还在不断出新模型,有的突破也十分惊艳,效果很出圈,怎么就不能掐尖了?变化在于,新模型依旧在持续发布,但每一次模型更新的突破幅度和性能增量都变小了。顶尖模型的领先保质期,也被急剧压缩。过去一款顶级模型的优势可以稳定几个月,让用户和开发者固定地用上一段时间,这期间基本不用担心被赶超,也不需要做很多功课。但现在,筛选评测更换模型的任务量大大增加,不能再无脑掐尖,比从前感觉更累了。
底座模型的能力触顶,业内其实早有预料,但2026年是真正的“狼来了”。
一方面,算力成本急剧增加。此前Scaling Law已经撞墙了,大力不再能出奇迹,而成本上升的直接影响,就是规模法则实现性能跃迁的这条路,投入产出比降到了历史最低点。谷歌、OpenAI这种仍有余粮的头部模厂,才能靠堆资源硬凹出惊艳感的突破。
同时,高质量语料接近枯竭,很多用户都感觉到AI问答已经陷入了自产自销、互相蒸馏严重的情况。“稳稳地接住你”“让我给你最直接、最客观……”之类的AI口癖,在多个模型之间彼此传染,有人调侃“GPT的话,越来越国际化”,本质是全球都缺乏新的优质语料注入,无法拉开能力差距。
不能掐尖的模型市场,极大地提高了用户的选择成本,不得不开始针对细分场景,去适配不同的模型,耗费大量时间和精力货比三家,在效果、成本、场景中寻找平衡。
02 消失的免费羊毛
一些开发者踩坑之后,得出一个简单粗暴的结论,直接选择顶级模型,最大限度减少折腾和出错。可这一套对绝大多数普通用户并不起作用。
除少量开发者群体外,几乎没有人愿意为高价模型订阅买单,一项数据显示,全球81亿人口,只有0.3%的人付费使用Al。现实中,一旦开始收费,大家就会选择更有性价比的平替或免费模型。但与掐尖红利一起消退的,还有免费的羊毛。
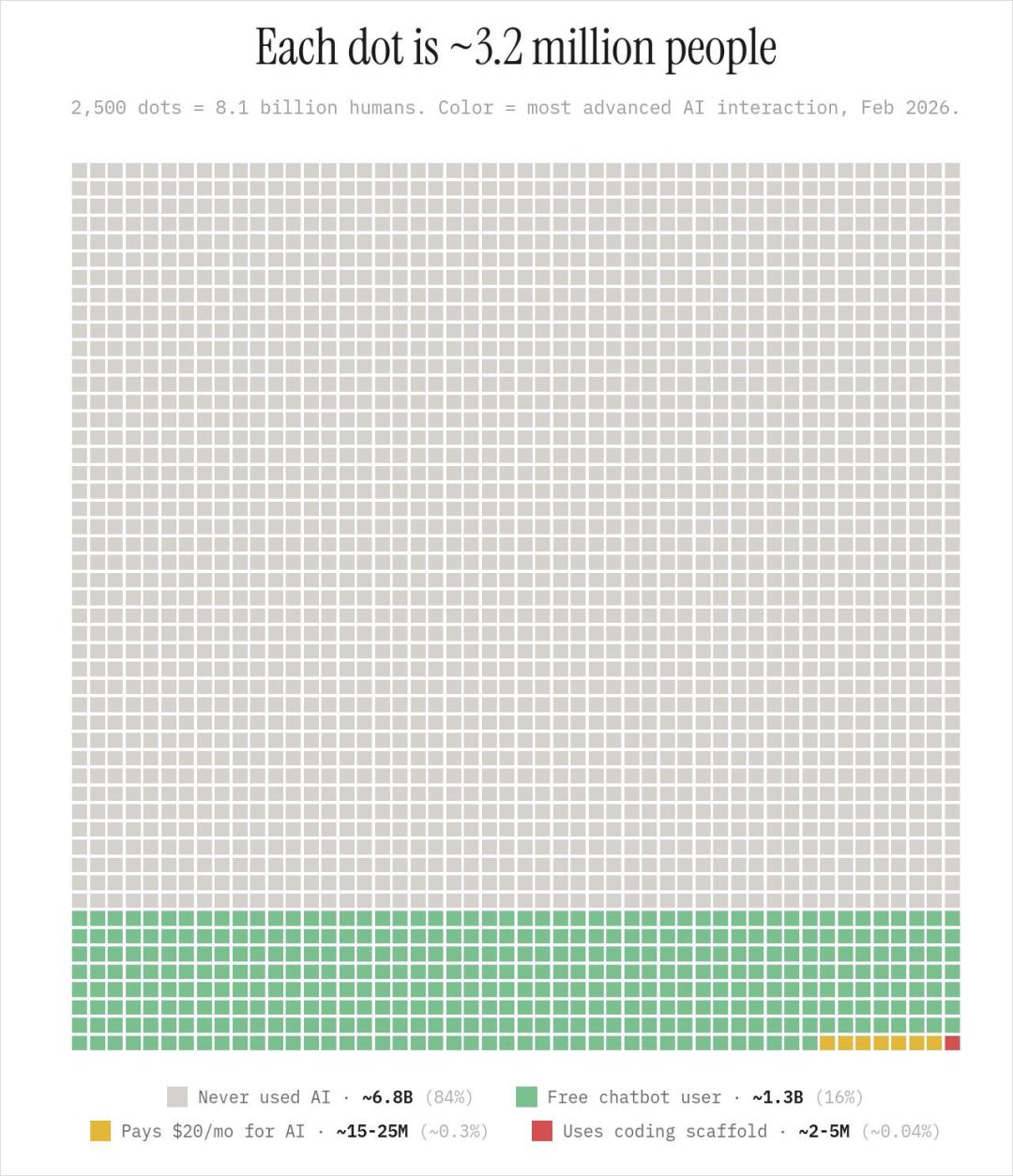
(图中黄色色块,代表全球0.3%的人每月为人工智能支付20美元)
2026年不少主流模型的免费版本,或者最低档位的订阅版本,都或多或少存在体验的倒退。
比如头部中文模型的创意写作能力退步,被用户调侃开始变得油腻了。有的开启付费模式之后,用户反馈免费版变笨了,幻觉增多。一些海外模型也被从业者发现,模型思考中位长度暴跌,在一些代码修改任务中,完全不读取原文件直接输出结果。
一句话,这些免费或者低价的模型,开始偷懒和摸鱼了。
这就导致了一系列衍生问题。很多普通用户没有及时察觉到普惠模型的降智,仍然习惯性地将法务、做题、重大决策等严肃事务,交给免费AI工具处理,导致决策翻车,甚至财务受损的事故增多。
另一个问题就是群体之间的割裂越来越大。
对顶级模型有认知、有付费实力的人群,把顶级AI当作杠杆在提效,而普通大众为平价模型投入了大量精力,带来的收益却有限。能稳定使用海外顶级模型,甚至成了某些国内高级白领的时尚单品和身份象征,还有人提出了AI造成“精品人群VS普通人”的言论,这里面有巨大的误导。

AI的终极形态应该像手机、电脑一样,成为全民都可用的普惠工具,旗舰机也好,千元机也好,都能顺畅地运行所有必要功能。当下大模型,从平权工具变成差距放大器,这个阶段性的问题必须得到解决。
解决之前,我们得先了解一下,为什么普惠模型突然之间不好用了?
一个是行业告别低价Token时代后,模厂为了压缩推理成本,主动阉割模型深度思考能力,导致的AI降智。这种情况,充值就能充智。
还有一个原因,加钱也很难解决,就是普惠的国产模型的进步正在放慢。对于全球开发者和用户来说,中国开源模型一直是普惠的代名词,也是海外高昂闭源模型的平替。但进入2026年,国内开源模型与海外模型的差距确实在拉大,平均估算落后6-12个月。
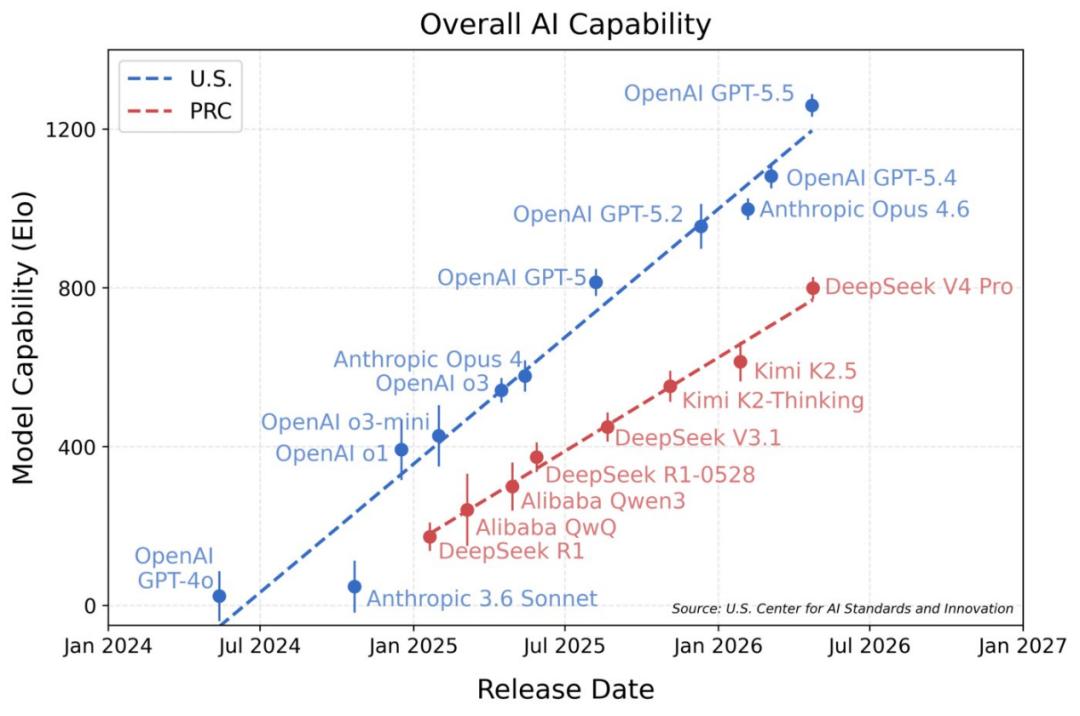
(某国产模型在非公开benchmark上能力和GPT 5相当,差距8个月)
根本原因还是算力的制约。此前靠轻量化MOE架构带来的优化是有上限的,不可能完全替代大规模高质量预训练,而后者离不开高规格的算力集群。高端AI算力体系的代差,仍然是国产模型的现实短板。
我们都不希望AI割裂社会造成阶级分化,不应该拉大不同人群的能力差距,那么针对性解决短期的成本压力与中长期的算力瓶颈,仍是整个行业的题中之义。
03 割裂的企业市场
企业智能化需求,是AI产业的首要商业化路径,也是最主要的现金池。当下的企业市场,我们听到了不同的声音,喜忧皆有:
喜的是,模型真有价值。一个做金融数智化的企业代表告诉我们,因为有免费的开源模型,国内的银行业能够低成本快速落地AI智能体与一些数智化解决方案。而美国银行只能依赖高价的闭源模型,导致做智能化的成本很高,再加上数字基础设施的老旧,就很难开展智能应用。这也使得国内金融科技成果具备更强的出海竞争力,东南亚等新兴市场的金融机构,如今更愿意主动借鉴、引入中国的金融科技方案。
忧的是,模型真难变现。也有模厂反馈,不是没有客户线索,企业也不是没有需求,是压根儿就没有预算。AI投入几乎全部汇聚在科技公司与行业龙头,这成了AI To B业务增长的最大卡点。

解锁企业AI预算的那把钥匙,是什么?投入回报比。
如果说前两年大家都是FOMO害怕错过,不管AI有没有用先上车再说,来到2026 年,要求AI做出结果,模型具有高性价比,才能说服企业立项投入。
企业市场的风向变化,直接抬高了模厂的竞争门槛,甚至可以说,新模型发布之后才是痛苦的开始。必须拿出真实的业务结果,哪怕是实验性质的案例,总之要给行业客户可验证的效果。
于是,我们能看到的明显变化,就是通用大模型的声量热度持续走低。
厂商全面转向适配垂直场景,打磨专精能力,在一些模厂的年度大会,我们不再看到基座模型的身影,取而代之的是行业版本和用户证言。而随着ISV伙伴、行业客户用例的价值凸显,模厂的生态能力正变得越来越重要。
谁能用最少的成本,撬动最大的业务价值,正拷问着所有模型。
04 危中之机
开发者的疲惫感,技术精英与普通大众的割裂,企业在投入和回报之间纠结,这些情绪组成了2026年的AI众生相,它们会持续多久呢?
答案是,取决于大模型能否走出阶段性停滞,重回持续突破的快车道。只是在当下,我们还没有看到趋势变化的拐点。

未来主义者总爱用一句话来回应公众对技术变革的疑虑,那就是:技术发展催生的问题,终将依靠技术的持续进步解决。
用时间换空间,从这个角度来看,化解当下的模型危机,并非只能一味等待技术的颠覆式突破。在模型能力平稳的平台期,减少使用过程中的种种摩擦与疲惫,也能缓冲和稀释技术本身的问题,为打破僵局争取更多的时间与空间。
