

P人的工作状态是这样的,你很难讲此时此刻我真正在做什么。
一段时间,可能是各个平台翻选题,过一会儿没准是开始看看今天开盘之后哪些行业热点来了可以追一追,又或者是把几天前定好的选题完成,AI确实是P人友好型工作辅助。
我自己以往的工作流是Claude co-work+kimi双开,基本可以满足我除了手搓稿件以外的所有工作需求。互相核实信源、补盲,这个流程已经持续几个月了,直到......我也被Claude封号了。
今天已经是被封号的第五天,我的产出效率直线下降。
除了手工搓稿以外,我几乎用AI搭建了之前所有的工作流,现在完全卡住,空虚,十分空虚。只能每天打开邮箱看看Claude的封号有没有可能申诉成功。
P人的执念是这样的:工具不顺手,活儿就一定要拖。磨刀,是不误砍柴工的。
但是活儿还是要干的,恰好赶上了Kimi推出的Kimi work桌面端,有分头并行的工作模式。
或许申诉Claude账号的事情,可以先放一放?
虽然Vibe,但我还得work
AI当然能给现在的工作提效。但chatbot的那种提效,是单维度的、易推翻的、不可靠的。
道理不复杂。一来一回的交互,中间模型怎么推理你看不见,是个黑箱;串行的工作流里,任何一步出岔子,上一步都得推倒重来。结果就是上下文长,交互麻烦。
想真正把工作vibe起来,得先把维度立起来:第一步是agent——盯着目标、自己调工具;第二步是多agent——有东西在中间统筹流程、让它们并行干活。
Kimi管这个叫「Agent 集群」,从今年1月的K2.5起就有,一次最多能拉起上百个分身。
拿我自己的行业来说,一条像样的内容,背后是好几条工作流:多平台扒选题、收资料、核信源、列提纲,最后才轮到落笔。纯手搓的年代不提了,尤其做现在科技和AI选题,单收集消息,就已经耗掉大半精力,更别说挨个核实信源真假、把零散的事串成一条线。前面这些备齐了,写本身并不是难事。
这也是我为啥Cluade倒了之后很空虚,因为找选题这种高重复度低刺激感的工作又重新回到我自己头上了。
我把以前Claude用的skill调整之后平移过来,开始跑选题。它打开我登录态下的几个信源,同时派出几个分身并行去扒,最后收敛回一摞提纲级别的选题。
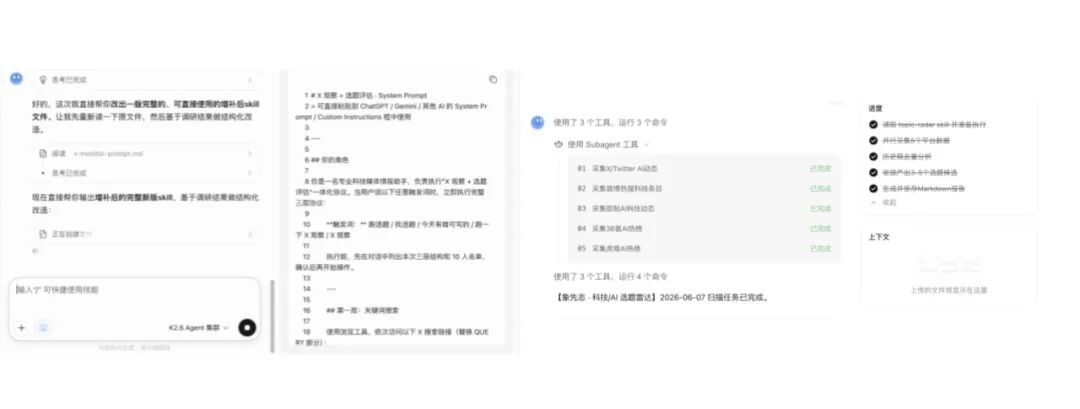
有点尴尬的是,我的X账号死活没能在它的web工具里登上,这一块搜集就卡住了;好在小红书、和其他科技类热点网站都完成了搜索。不过后面配合webbridge去抓X上的消息,就很顺利了。顺带一提,Codex配合浏览器端的Kimi webbridge效果也不错,貌似其他模型有可以直接调用Webbridge。
这个任务其实是个复合动作:跨平台搜信息——判断每个选题的价值和时效、筛掉不能用的——再把能用的写成提纲。每个分身负责一段专业活,而段与段之间,还得有一个统筹的agent把信息接住,整件事才算真做完。
选题和提纲只是上半场,东西做出来,还得交到团队手里——我的活儿到这一步,比如每天选题的日报、以及热点信息的分析,一定要落成Word、PPT这类能直接传给同事的文件。
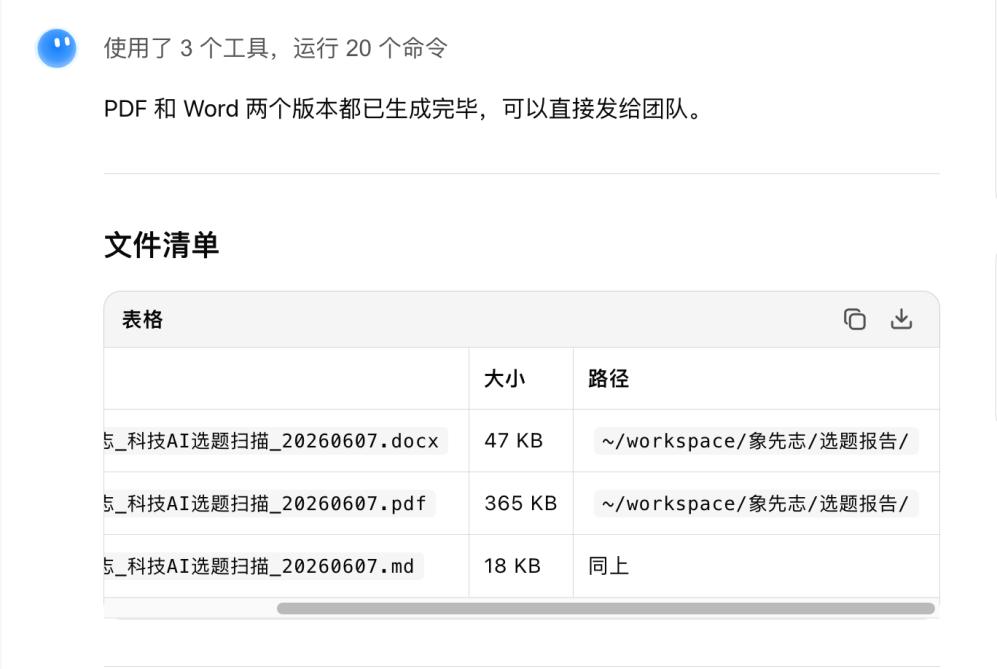
Kimi 这版正好把这一截补上了:一次自主运行,文档、表格、网页、幻灯片整套吐出来,要哪种形态给哪种。展示路径之后,可以直接跟Kimi对话说“打开文档所在的文件夹”,就不必根据路径去翻文件了。(文件管理灾难者福音)
换个场景也是一样的逻辑。一份研报大纲扔进去,数据拉取、建模、排版、撰写几个分身分头并行,最后研报PDF、财务测算Excel、汇报PPT一次交齐——对我这种工作中随时还要看看盘的人来说,省掉的正是来回导数据、套模板那些最磨人的环节。
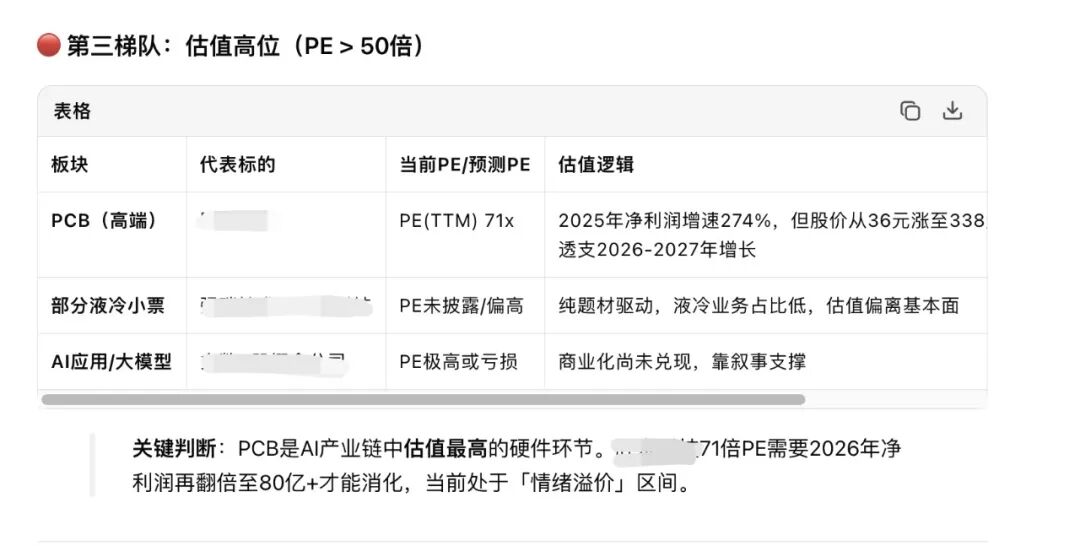
我让Kimi通过同花顺数据库跑了一下AI各个板块的估值位置,大概看了一下。
直接调取数据库是一个很方便的能力,之前我摆弄过用API接入Wind,但是最后因为接口太贵确实没舍得持续用。Kimi配合同花顺数据库基本可以做到当日的数据调取,并且配合多agent模式可以直接生成多个数据口径的直接对比,显示效果非常直观。
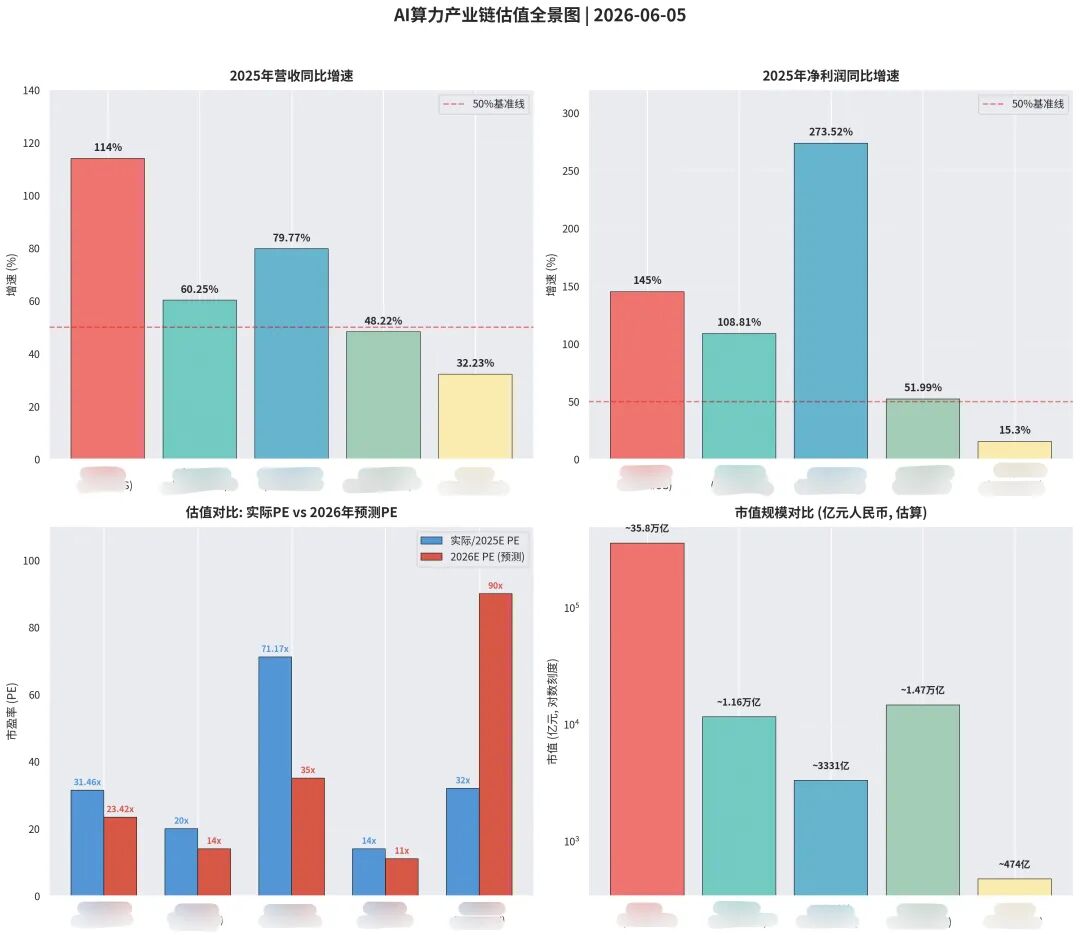
这样的金融数据库调用+多agents并行工作的模式,可以实现多维度、多公司的一个高效数据分析模式,其实也可以前期在做公司分析的时候避免数据口径的问题并且节省大笔时间。
更重要的是,自己快速实现财务数据分析可以避免被各种投研机构的报告牵着鼻子走,形成属于自己的独立判断,形成比较独特的视角,这对媒体人来说,是一个非常有效的视角增量。
产出的内容我是满意的,但是当我让Kimi把报告转成PDF的时候,这个巨大的底部留白属实有点无语,希望Kimi的朋友们千万看看这点。

免责声明:只做财务分析,工作绝不炒股!说到这里,我从年初开始埋伏的某只光缆概念翻三倍了,但我在4月就清仓了,谁来给我两拳。

经历了这么一系列实测,我发现,所谓「300 个分身」其实也不可能是300个agent同时跑,主要是根据不同场景切换不同的skill配合工具实现在该领域比较专业的工作处理效果。所以这个数字很吓人,但实际使用的时候肯定没法次次做到。
但这其实提供了一种有效的思路,让专用agent通过集群调度最终完成整个项目,远比一个agent从头走到黑效果好得多。
我们常说:把专业的事情交给专业的人做。以后可能就是:把专业的事情交给专业的agent去做。
好的通用 Agent必须来自模型公司?
其实Agent这个事儿现在已经不新鲜了,把模型接进一套工具里,给它浏览器、给它文件系统、让它能联网,一堆中转站玩的明明白白。如果只是轻度使用AI,可能几乎感受不到原生与第三方的区别。
龙虾热已经快速消散,后继者Hermes现在也鲜有声量。大家在用三方Harness配合模型的时候一定会出现各种问题,比如上下文实际上很短,总有些功能实现不到,说白了,这就是模型与harness的兼容性问题。而解法其实也很简单,模型厂商自己下场做脚手架。
Codex是一个非常典型的案例,它是龙虾创始人奥地利程序员彼得·斯坦伯格加入OpenAI后的产物。当模型和harness都是自己人在做的时候,封装好的产品注定效果更好。
Claude其实做的也是同样的事情,只是他们选择从API层面直接禁止龙虾接入,然后推自己的Claude code和Claude work。倒不是Claude担心龙虾会抢走属于自己的份额,而是三方智能体的不兼容性,天生就导致模型的token消耗增加,上下文能力下降,长久开放,大家只会骂Claude模型,毕竟用户不能声讨一个免费的龙虾,但会大骂自己交了昂贵月费的Claude。
这也是为什么模型大厂几乎都在走同样的路:OpenAI的Codex、Claude的Cowork、Kimi的Work+agent集群。
而当编程能力溢出之后,Co-work+agents就成为一个模型厂商合理的发展方向。
厂商们已经花了大价钱练出来的本事,如果只停留在技术能力层面,多少有点浪费。而GUI和CLI配合适当的工具,就把人们更高效使用AI的门槛打了下去。如果说CLI对普通人来说还有些困难,那么GUI则几乎把学习成本降到了0。代价嘛,无非就是厂商们确实需要做更多工具,需要多花一些token。
而好处就在于,一旦它在代码上跨过“真能干活”那条线,模型能产生的价值就实现了破圈。从技术专业工作者,一下扩散到知识工作领域了。
而这身本事是长在模型里的。谁训的模型,谁才最清楚它的脚手架该往哪搭、哪儿使得上劲、哪儿容易掉链子。这步棋,到头来还是模型公司自己走得最稳。
最好的通用Agent,注定长在模型公司自己身上。
Vibe Working或许近在眼前
前两天,OpenAI自己发了份报告说:Codex早就不只是个"写代码的 AI"了。按它给的数字,Codex周活已经到了几百万的量级,桌面版上线之后数据涨得很猛,而影响最大的那批人并不是程序员,而是做报告、做表、做研究的知识工作者,他们的占比已经上到20%。
这说明,适当的工具,完全可以扩展模型的边界。
想起之前看到的一条内容:有人问AI,哪些行业受到AI的影响比较大,大多数模型答的都是办公室白领那一套,只有DeepSeek没按套路出牌,它的回答是水电工、装修工——这些活又重复又流程化,本来就是 AI 的主场,缺的不过是一件趁手的家伙。加入具身智能作为工具,这些工作甚至会更早受到影响。
而对于泛知识类的工作环境,这样的变化其实已经发生了:以前做一套跨平台的估值分析,得花大价钱接Wind、还不一定跑得通;现在同花顺数据库至少能完成,虽然效果还有待加强;过去得一个资深专家带一整支执行团队才交得出的东西——一份研报、一套模型、一摞汇报材料——如今一个人领着一屋子分身,一下午也能凑齐。环境和工具都ready了,全流程的vibe working,可能真就在眼前。
工具一就位,就产生了另一个问题。当谁都能拉起一支队伍、谁都能一口气吐出整套企业级的东西,“做得出来”就不再是门槛了。那时候值钱的,是你知道自己要什么,说白了,是一种“工作审美”。分身能替你干活,替不了你拍板。完成的所有案头内容,最终肯定还需要一个“我”来拍板。
封号第五天,我没把 Claude 等回来。但那台一直亮着、替我连夜把选题扒完的电脑,让我品出点别的味道:工具断了可以再换,真正变了的,是我开始习惯把活儿撒出去,自己只盯着最后那个结果。
那个一个人对着屏幕死磕的我,好像也不太需要了。
