

一天搞定5000万行代码。什么概念?相当于把一个千亿市值的软件公司,从零到一重写一遍——而且只用了24小时。
就在今天,Anthropic藏了两个月的“神话”级模型终于解封。不是一款,是两款:Claude Fable 5面向所有用户开放,Claude Mythos 5只对少数受信任用户开放。同一个底层模型,同一个“Mythos”内核,区别只有一个——Fable 5身上系着安全带,Mythos 5彻底解除了限制。
更耐人寻味的是发布时机。就在前两天,Anthropic的CEO Dario还郑重其事地呼吁“所有AI研究立刻停止”。结果不到48小时,自家最强模型连夜上架。嘴上说不要,身体很诚实。
但抛开这些烟雾弹,真正值得关心的问题是:这台“性能怪兽”到底强在哪?为什么同一个心脏要装进两个不同的身体?以及,当AI能在无人看管的情况下自主工作一周、产出超越《科学》杂志的成果时——我们人类的位置,还剩什么?
Mythos 5的“封神”之路: 从5000万行代码到反超《科学》论文
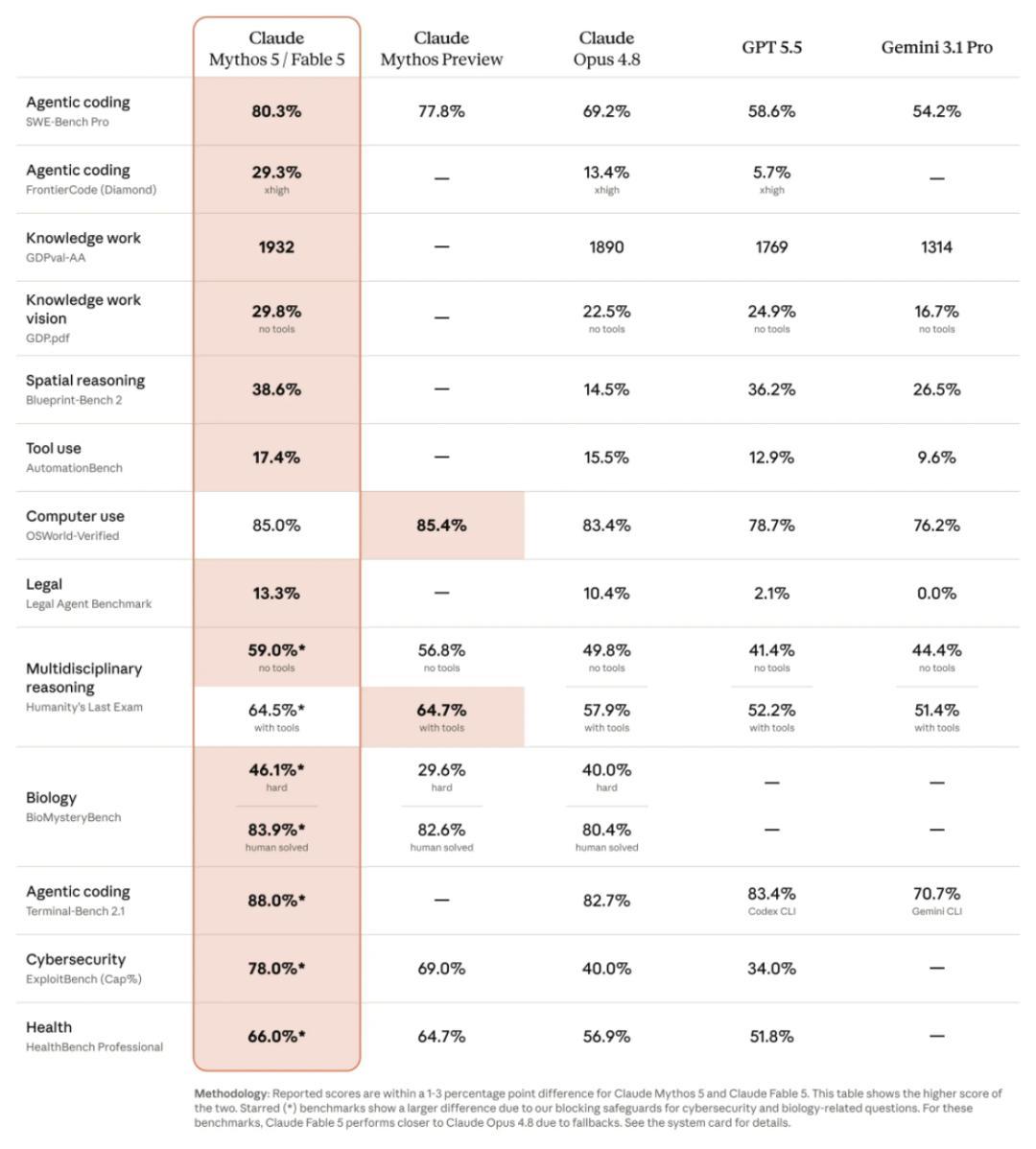
首先看软件工程。虽然官方基准跑分主要公布的是Fable 5的数据,但Anthropic明确表示——Fable 5与Mythos 5是同一底层模型,基础技术指标完全一致。因此Fable 5在SWE-Bench Pro上80.3%的惊人得分,Mythos 5同样具备。作为对比,GPT-5.5只有58.6%。
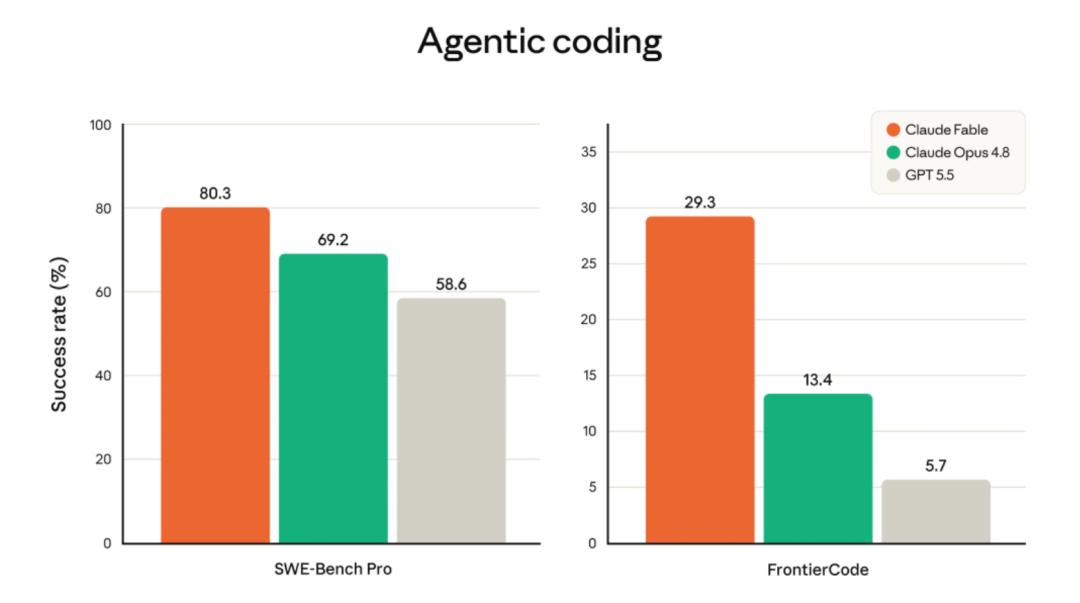
但数字远不如真实案例震撼。参与早期测试的金融科技公司Stripe,在一个5000万行Ruby代码库中,让Mythos级模型做了一次全库迁移。正常情况下,这需要一个工程团队干两个多月。而Mythos 5只用了一天。一天,5000万行,整个团队看傻了。
更让人头皮发麻的,是它在生命科学领域的“自主科研”能力。 这才是Mythos 5真正与所有公开模型拉开代差的地方。
在蛋白质设计任务中,Mythos 5在完全没有人类协助的情况下,独立执行了生物学家的全部工作流:选择结合位点、运行生物信息学工具、遭遇运行失败时自己Debug。它设计出的14个蛋白质靶向复合物中,有9个已经进入了真实药物研发管线,覆盖免疫检查点、神经退行性疾病、肌肉疾病等高难度靶点。
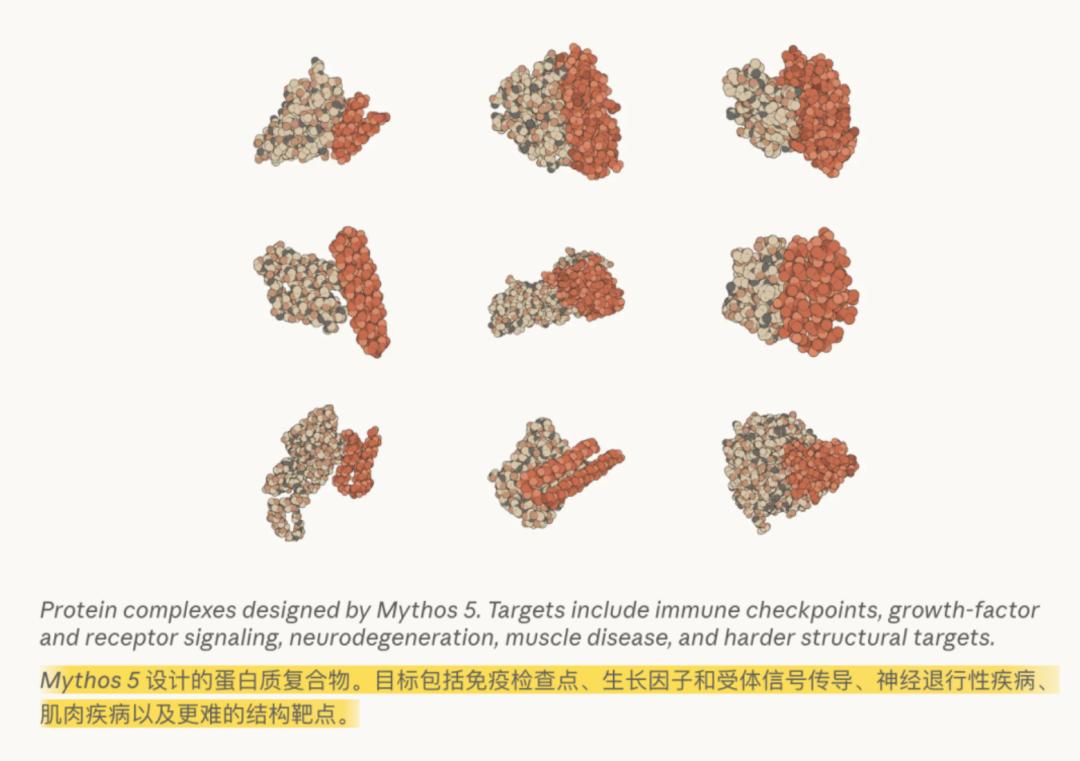
Anthropic官方直言:Mythos 5“是我们首个能够持续产生新颖且引人注目的科学假设的模型”。 在与Opus级模型的盲法对比中,科学家在80%的情况下更倾向于Mythos 5提出的分子生物学假设。其中一项关于大肠杆菌蛋白质新机制的假说,已被另一个独立研究团队的近期论文直接证实。
最炸裂的,是基因组学研究。 Mythos 5在几乎无人干预的情况下,自主工作了一周多。它汇集了横跨138个动物物种的数百万个单细胞数据,自己设计并训练了一个定制机器学习模型,用于识别亲缘关系极远的物种中执行相同功能的细胞。
结果呢?这个由AI训练出来的、体积小了100倍的微型模型,在表现上直接击败了前不久刚发表在《Science》杂志上的最新科研成果。Anthropic计划在未来几个月内将这一结果正式发表。
因此,Mythos 5不是在某一个领域“更强”,而是在软件工程和生命科学两个完全不同的高壁垒行业,同时交出了“碾压人类团队”和“反超顶刊论文”级别的成绩单。 它不再是工具,而是能够独立完成研究项目、产出可验证成果的“AI研究员”。
从“施法者”到“甲方”: 人与AI的协作范式,被彻底逆转
著名AI学者、沃顿商学院教授Ethan Mollick在测试后给出了一个极其深刻的洞察:人类正在从“施法者”变成“甲方”。
过去,我们使用大模型就像念咒语的施法者——必须手把手地指导,精雕细琢每一句Prompt,不断对话提示、纠正、引导,AI才能勉强变出一个戏法。那是“驾驭工具”的模式。
而现在,Mollick教授直接向Fable 5(同一底层模型)喂了一份15页的复杂项目设计文档,留下一段宏观的需求描述。接下来9个多小时,Fable 5在后台完全自主运行:自己生成Agent工作流,内部调度多个小Agent分别搞调研、写大纲、相互校对、推翻错误假设、纠错重来。人类全程没有介入半步。9小时后,一个极高品质的成品直接交付到他面前。

这就是“甲方”模式。 你不再是那个事必躬亲的施法者,而是那个在最终成品上签字的委托人。你不需要关心AI在黑盒里做了多少个微观决策,你只需要提出要求、验收结果。
这种转变的背后,是长上下文与自主逻辑的结合。 传统的大模型,上下文窗口只是一个“内容容器”——你把一堆资料塞进去,它基于这些资料回答问题。而Mythos级的百万级Token上下文,加上持久化文件记忆,让它变成了一个“能自主运行的智能操作系统”。
Anthropic用Slay the Spire这款游戏做了一个定量测试:给模型接入持久化文件记忆后,Fable 5的表现提升幅度是Opus 4.8的三倍,到达最终章节的频率也是三倍。这意味着模型不仅记住了之前的经验,还能主动利用这些经验优化后续决策——它正在“从自己的经验中学习”。
Mollick在测试后说了一段耐人寻味的话:使用这个工具既令人愉悦又令人不安。愉悦在于,我只需提出要求,它就能实现。不安也在于,我只需提出要求,它就能实现。
Mythos 5带来的不是“更强的问答”,而是“无需介入的交付”。 AI从需要你指挥的士兵,变成了能独立完成项目的承包商。而人类的核心能力,正在从“如何指挥AI”转向“如何验收AI的成果”。
最锋利的刀,配最坚固的鞘: 安全护栏与“权限时代”的开启
能力越强,风险越大。Anthropic对此心知肚明——这也是为什么Mythos 5没有直接向所有人开放。
最明显的变化:公开版Fable 5内置了一套安全分类器,一旦触发就自动“降级”到Opus 4.8回答。 而满血版Mythos 5则移除了网络安全与生物科研领域的限制,只交给受信任用户。
Anthropic给出了数据:超过95%的Fable 5会话不会触发降级。这意味着对绝大多数写作、代码、分析、研究工作,用户拿到的是接近Mythos 5的体验。但剩下不到5%的请求——包括合理的研究需求,比如生物学家研究病毒、安全工程师做授权攻防演练——也可能被误伤。Anthropic承认当前护栏比理想状态更严格,后续会降低误伤率。
另一个值得关注的信号:数据留存政策。从Fable 5、Mythos 5开始,Anthropic要求所有Mythos级模型的流量保留30天,覆盖第一方和第三方平台。官方强调这些数据不会用于训练,只用于安全监控——识别复杂攻击、新型越狱和跨请求攻击。
对普通用户来说,这可能只是条款里的一行字。但对企业和机构客户而言,这是非常现实的数据治理问题。想用最强能力,就要接受更高等级的安全审查和数据留存。前沿模型的成本,不只在API账单上。
与此同时,Anthropic还做了一件事:呼吁“所有AI研究立即停止”之后没几天,自家最强模型就发布了。这种“一边喊停一边加速”的矛盾姿态,被不少业内人士解读为营销造势。但换个角度看,它也在传递一个更深的信号:前沿AI正在进入“权限时代”。 最强模型不再对所有人一视同仁,而是区分“公开版”和“受信任版”,区分“有护栏”和“无护栏”。能力越强,门槛越高。
Mythos 5的发布不仅是技术事件,也是产品形态和行业规则的分水岭。 安全不再只是模型回答前的一句免责声明,而是变成了分类器、模型路由、权限分级、数据留存共同组成的复杂架构。未来的顶尖AI,大概率都会走这条路——不是不让用,而是分级、留痕、可追溯。
写在最后
回到定价:Mythos 5与Fable 5统一定价为每百万输入Token 10美元、每百万输出Token 50美元,不到预览版的一半,也只有GPT-5.5 Pro的六分之一。但即便如此,它的Token消耗依然惊人。有用户反馈,在200美元/月的Max套餐中,Fable 5一分钟就消耗了约14%的5小时配额——折合下来大概一分钟一美元。
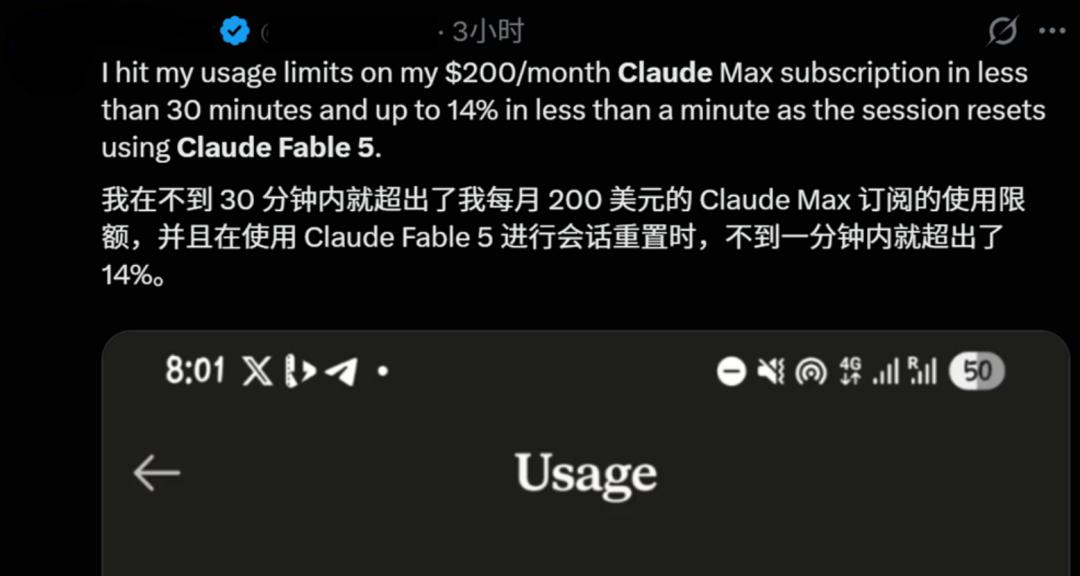
这揭示了一个被数据掩盖的事实:Mythos 5的“封神”和“昂贵”是一体两面。 它能一天搞定5000万行代码,但它烧Token的速度也会让个人用户肉疼。它能自主做一周科研并产出Science级成果,但只有机构客户才烧得起这笔算力。
Anthropic正在押注一件事:当AI能从“帮你写代码”进化到“替你完成科研项目”时,企业愿意为后者支付的价格,将远远高于前者。Mythos 5,就是这场博弈的第一张牌。
今天,神话降临。但神话的代价,才刚刚开始被计算。
