

每次国产AI模型发布之时,人们总是说,国模即将崛起,追赶Anthropic指日可待。然而现实总是在反复打脸,模型之间的差距不仅越来越大,若是翻开GitHub上各种排行榜,有一个橙色头像的作者已经几乎随处可见。
然而,主动使用也好,不得不用也罢,随着AI开始摆脱实验室走向企业级生产环境,一种深刻的商业现实已经显现:最聪明的模型,一定是最贵的模型。Fable和GPT固然好,但每天24小时无间断使用,谁也用不起。值此之际,人们似乎又看到了国产模型的一线生机。
要想真正利用AI发挥生产力,并使其产出的产品具备可落地的商业价值,单一的前沿旗舰模型正面临严峻的ROI拷问。
与此同时,能力略逊一筹但具备价格优势的国产模型,急需撕掉“玩具”的刻板标签。
而更深层次的冲突在于:大模型厂商正试图构建封闭的智能体生态建立垄断,而企业用户和中立第三方则在拼命寻求生态的开放与解耦。
因此,本文将从多模型动态路由(Fusion)和智能体元框架(Omnigent)这两种全新的工程范式来解析这个技术与商业交织的复杂图景,将AI产业正在经历的一场从“算力霸权”向“架构分权”的历史性演进公之于众。
01 算力成本陷阱与真伪需求
在讨论国际模型与国产模型到底该怎么用之前,人们首先应该理解一个核心的AI经济学前提:token是一种智能决定价值的计算资源。
此前出现的桌面端AI代理,通过接管用户电脑来执行任务,虽然结果令人失望,但仍然揭示了一个现象:许多个人和企业用户,都处于“不知道如何规模化消耗token产生价值”的困境。
通过不完善的底层结构进行低效的任务穷举来消耗token,创造出来的必然是伪需求。这一点,三个月来各种代理的默默无闻已经足以验证。想让企业愿意用真金白银买单,就绝对不能为了消耗算力而消耗算力,必须用最小的算力成本撬动最大的任务闭环。
这就是摆在所有人面前、当前单一前沿模型面临的算力成本陷阱。
像是深度行业研究、数万行代码的重构,任何一项复杂的商业任务,其难度都呈现出典型的长尾分布。
其中,可能只有很少的环节需要Fable 5这种极致智商的模型出马,而剩下的大部分环节,只需要极其基础的逻辑能力。像是网页内容抓取、基础代码翻译、格式化JSON输出、后期检查校对,杀鸡焉用牛刀。
如果用御三家的旗舰模型去包揽所有任务流程,无异于大炮打蚊子,而高昂的成本也会让任何试图商业化的SaaS产品在经济模型上面临破产。
这种性能与成本之间的巨大撕裂,正是当前AI应用难以跨越试用期到“深水区”的根本原因之一。要解决这个矛盾,只靠等待前沿模型打价格战恐怕已经是无稽之谈。因此,必须采用一种全新的系统工程思路:按难度与需求进行任务分配。
02 Fusion机制与国模的“非对称竞争”
国产模型的出路在哪?
这个问题,无论是AI的圈内还是圈外人士都有所关注。
针对这个尖锐的问题,传统的回答往往是在特定垂直领域用私有数据微调,但效果并不显著,因为它并未触及系统架构的本质。当下更直接的解法,是用极致的性价比来抢占“国产替代”的定位,这也是OpenRouter推出Fusion技术作为破局之道的本质。
Fusion技术,即多模型动态路由与合成,核心逻辑非常简单但有效:将一个复杂问题并行分发给多个不同的模型,然后由一个评判模型将各方结果进行融合。
用一个程序员圈子里的使用方法举例:让GPT-5.5和Opus 4.8写程序架构,让DeepSeek V4 Pro写具体代码。
太过简单的思路反而让人有些怀疑,就凭借这种“小伎俩”就能给国产模型带来出路吗?
在DRACO深度研究基准测试中,一个令人信服的数据打消了怀疑:由Gemini 3 Flash、Kimi K2.6和DeepSeek V4 Pro组成的“预算型模型组”,不仅击败了单一的GPT-5.5,得分还逼近了顶级的前沿模型组合,而成本仅为其50%。
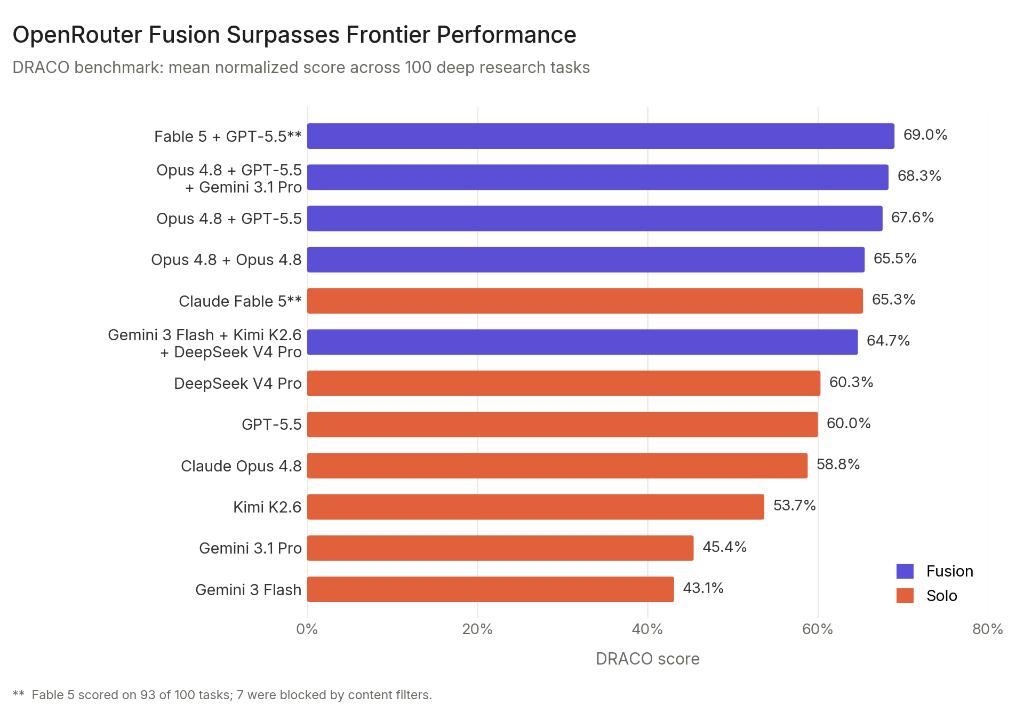
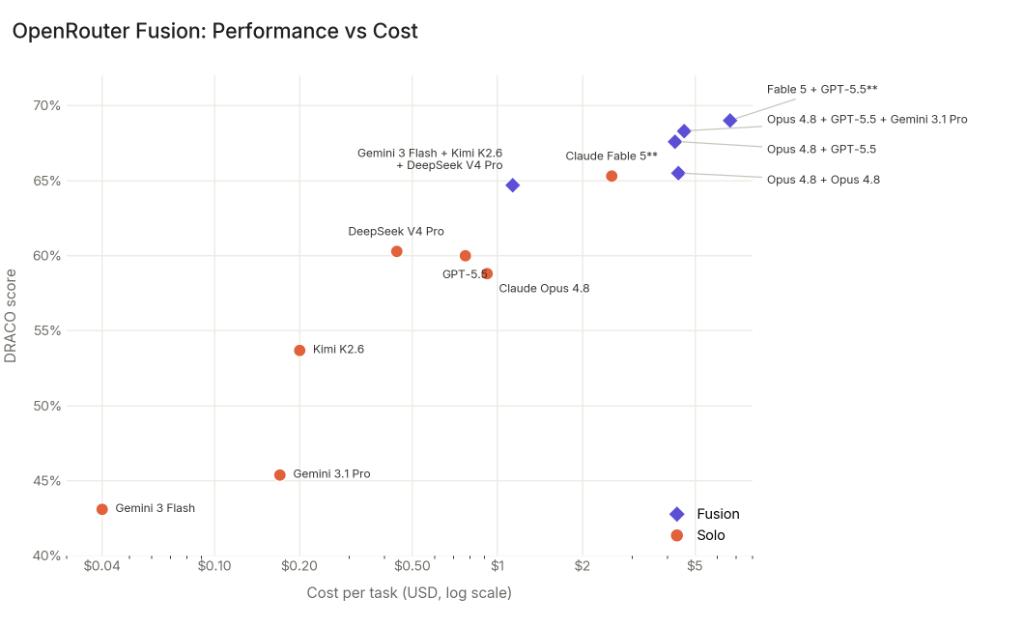
组合里三个模型中,有两个性能与GPT-5.5存在明显差距的国产模型。然而,它们却给出了国产模型最现实也最具有商业价值的破局路径:成为强大异构系统中最具性价比的“四肢”和“感官”。
与各式各样的桌面端代理创造出来的伪需求相反,在真金白银的商业考量面前,Anthropic和OpenAI的定价使得“智能分配”成为了绝大部分用户和企业的刚需。
我们已经知道,多Agent协作是AI的必然趋势,而在企业级Agent架构中,也不应该是一个强大的模型单打独斗,这就是所谓的“混合智能体架构(MoA)”,由两部分组成:
一是调度与评判的“大脑”:占据不到一半的token份额,由Anthropic和OpenAI的旗舰模型担任,负责最终的共识提取、矛盾分析和复杂推理。
二是执行与干活的“主力”:占用超过一半的token份额,由DeepSeek、GLM、Kimi等国产或开源模型担任,负责海量文档阅读、大规模网页并行搜索和基础代码编写。
这只是理想情况,具体的token分配还是因任务难度而异。但重要的是,通过这种“高低搭配”,国产模型就不需要在所有维度上硬刚御三家,尤其是极限推理这种受硬件算力影响极为严重的领域。
只要能在长文本处理、基础代码生成或特定语言理解等领域达到及格线以上,并维持极具竞争力的API或订阅服务定价,就能在这套多模型路由系统中占据不可或缺的地位,进而获得更为庞大的订阅量。
如此一来,国产模型的定位就会有所变化:从前沿模型的“国产替代”,转变为前沿模型的“算力杠杆”。
融入这种多模型协作的生态,国产模型也就正式告别了单一测试集上的跑分游戏,并作为基础设施的底层齿轮,真正进入全球企业的生产流转之中。
03 主场优势与生态封闭
Fusion这种按需分配的架构是企业用户和个人用户都梦寐以求的,但对于提供大模型的科技巨头来说,这无疑是在削弱其利润和控制力。
这就引出了当前行业的另一个明显趋势:智能体时代的“主场优势”构建。
观察近期的产品发布:国外,Anthropic与OpenAI分庭抗礼,Claude Code与Codex针锋相对;国内,前有小米MiMo Code加强对MiMo的绑定,后有智谱更新ZCode 3.0专情于GLM。
这种模型与调用环境(IDE/CLI)的强绑定,不仅是出于商业排他性的本能,背后也有着深刻的工程逻辑与战略企图。
从工程逻辑的角度来看,这是在用环境掩盖模型缺陷。
模型与智能体环境的关系,正如编程语言与IDE的关系。任何一个通用大模型都有其独特的失效模式(Failure Modes)。
当Anthropic构建Claude Code时,除了开发一个命令行工具,还要在底层硬编码海量专门针对Claude优化的隐藏系统提示词、错误重试逻辑以及特定的工具调用格式。
若是在一个外部通用的智能体框架中,Anthropic的模型可能会因为输出格式不标准等意外错误而导致任务失败;但回到其专属的主场,IDE或CLI就能在后台静默纠正这些错误。这种主场优势,能让模型在指定环境中表现得异常顺滑,从而给用户一种“模型绝对领先”的错觉。
从战略企图的角度来看,这是要建立难以挣脱的供应商“锁定”。
从Prompt,到Skills,再到Harness,都充分说明了记忆和环境的重要性。一旦用户习惯了在特定的智能体框架中工作,大量积累的上下文、自定义配置和工作流都会让他们无法轻易离开底层的模型。
单纯的API价格战只能解决一时的问题,而极致打磨过的封闭智能体环境意味着能将模型能力升级为产品体验。
这就是Anthropic的成功秘诀:当企业中程序员的核心业务流被固化在某个专属的智能体中,哪怕OpenAI推出了新的一款让Altman“看到原子弹、瘫倒在地”的模型,亦或是DeepSeek和小米推出了便宜十倍甚至百倍的模型,企业也无法做到一键切换,因为工作流是不兼容的。
这种封闭的孤岛策略,就是巨头们抵御Fusion这种多模型路由技术和开源平替冲击的最强护城河。
04 元框架的崛起与第三方的反击
应对开源技术,巨头们尚有余力,但多Agent协作的潮流终归不可抵挡。当企业发现自己被迫在好几个互不兼容的智能体孤岛之间复制粘贴,并且因为无法切换底层模型而不得不承担高昂成本时,基础设施层的革命就不可避免地爆发了。
这就是Databricks开源Omnigent的历史背景。Databricks给Omnigent定位为“元框架(Meta-Harness)”,一个比单一智能体更高维度的抽象层。
回顾计算机科学史,最大的跃迁往往来自于新的抽象层。当工程师们苦于同时管理数十个不同的服务器时,Google开发的Kubernetes横空出世,将底层硬件抽象为统一的资源池。而如今的AI行业正处于完全相同的节点,各个智能体及其框架(Harness),就是那些难以完全兼容的服务器。
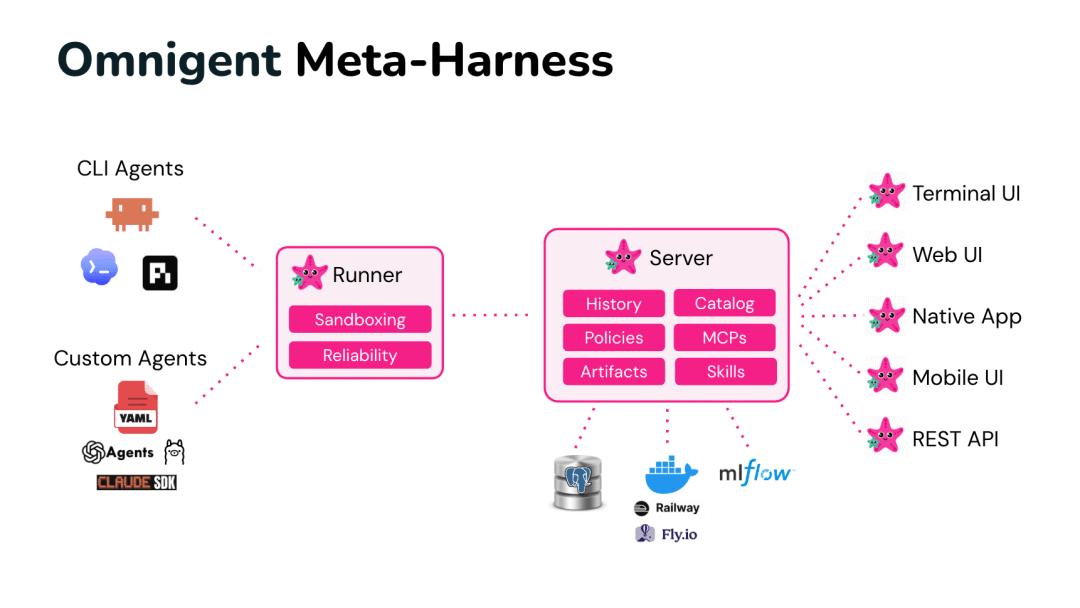
Omnigent的核心价值,就在于剥夺巨头们的主场优势,将控制权交还给用户。它通过构建统一的API,实现了三种颠覆性的功能:
首先是类似“一键热插拔”的组合性。
用户可以在一个统一的工作流中,用仅仅一行代码将负责逻辑的节点从Claude切换为其他自定义模型,或是在一个项目中同时调用Codex和多个自建智能体,直接瓦解了巨头们的供应商锁定(Vendor Lock-in)策略。
然后是兼顾安全与成本的绝对策略控制。
在封闭的生态中,模型能不能用、能怎么用、能用多久完全由巨头们的黑箱定义。但在元框架中,用户可以自由设置硬性上限,例如当某个会话的token消耗达到100美元时立刻冻结并请求人工确认,而无需去每个AI供应商那里查询消耗量。
由于控制层上浮到了元框架,即使底层使用不同的模型,企业用户最重视的安全审查和成本策略也能得到统一执行。
最后是消除上下文的孤岛。
会话状态不再留存于某一家厂商的服务器上,而是由中立的元框架接管。无论是人机协作还是多Agent协作,都会拥有一个统一的工作台。
也因此,无论是Fusion技术还是Omnigent框架,这些工具都必须也只能出自第三方。
正如前面所说,Anthropic、OpenAI以及一众国产AI厂商都存在严重的资本导向偏向性。只要不是自家模型实在拿不出手,它们就绝对不可能推出一个框架来允许企业和个人用户将任务无缝分发给竞争对手以节省成本。
Fusion诞生于OpenRouter,一个中立的模型聚合API平台;Omnigent诞生于Databricks,一家以“数据多云中立”为核心战略的底层基础设施供应商。只有与特定模型彻底解绑的第三方,才有动力去打造这种打破壁垒的工具。
这就代表了广大企业开发者最核心的利益:AI应该是一种可商品化、可替代的计算资源,而不是一种被巨头裹挟的特权。
05 重塑AI智能体的价值链
过去的三年,全球的人们都处于“模型中心主义”阶段,所有人都在寻找那个能解决一切问题的全知全能的神。
但现实已经告诉我们,Fable 5做不到,GPT-5.5做不到,DeepSeek V4 Pro也做不到,我们只能进入“架构中心主义”阶段。
在这个新的阶段中,单一模型或单一智能体的封闭玩法注定会被边缘化。而未来的企业级AI生产力系统,必将呈现出高度分化的层级结构:
在最底层,即算力执行层,国产模型将凭借极致的性价比承接下大量的基础“搬砖”工作,彻底摆脱玩具的命运,成为不可或缺的基石。
在中间层,即认知评判层,御三家的旗舰模型将退居二线,不再处理琐碎的细节,而是作为高高在上、总揽全局的工程师,在Fusion这样的动态路由机制下,负责那些难度最大的核心收敛工作。
在最上层,即管控交互层,依托于Omnigent这样的元框架,各大厂商的主场封闭也会被逐渐打破,实现跨模型、跨框架的无缝协作、成本预算管控以及企业级安全隔离。
真正的智能,不仅存在于深度学习的神经网络内部,更存在于链接这些网络的宏观架构之中。
当算力、智力、成本与中立的基础设施实现完美的系统化匹配时,AI才算真正完成了从“科技盲盒”到工业流水线的跨越。
