

写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。
但绝大多数Agent,始终跨不过一道核心门槛:只是强大的执行器,不会进行自主科研。
它们可以一次次修改代码、运行评测、记录日志,但很难稳定地把假设、证据、失败与经验组织成一个持续演化的研究状态。
随着任务变长,Agent往往会退化成线性的局部试错:试一个方向,失败;再试一个方向,再失败;即便偶尔成功,也很难把成功背后的机制沉淀下来,指导后续探索。
为此,来自中国人民大学高瓴人工智能学院和Microsoft Research的研究者提出了Arbor:通用且实用的自主科研的框架与开源工具包。
借助Hypothesis-Tree,Arbor对优化空间进行结构化探索,不是通过test-time scaling让Agent尝试更多方向,而是通过特有的insight回传机制让每一次尝试都能加深Arbor对问题的理解。

目前Arbor在国内外社区收获了较高的关注度,同时荣登Huggingface Daily Paper日榜第一!

Definition:自主科研究竟在关注什么?
Agent的飞速发展让Autoresearch不再只是一个概念:如果给Agent一个真实研究项目,它是否可以像研究者一样,持续提出想法、实现方案、运行实验,并在反馈中不断修正自己的判断?
这类问题在论文中被形式化为Autonomous Optimization,简称AO。系统会给定一个初始artifact,例如模型训练代码、agent harness、数据生成pipeline;同时给定一个研究目标和可执行evaluator。
Agent需要在没有逐步人工监督的情况下,只可见dev集,通过多轮实验不断改进这个artifact,最终保证test集上效果提升。这一定义不绑定具体task,无论是训练模型、改进代码、调整流程,都能被划归到AO的定义中来:
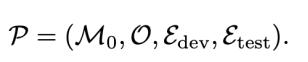
这一设定更关注真实科研中的核心循环:我们不是让Agent回答一个问题,而是让它持续优化一个研究对象。它需要长期工作,需要处理延迟反馈,需要面对失败,也需要决定下一步应该继续哪个方向、放弃哪个方向、合并哪个结果。
Problem:为什么当前Agent还不能胜任AO任务?
在真实科研中,进展很少来自孤立的一次尝试。一个研究者可能会同时思考多个方向:某个方向看起来有潜力,但实验结果不稳定;另一个方向分数提升明显,但可能只是过拟合开发集;还有一个方向虽然失败了,却暴露出了关键问题。
这些信息都需要被比较、抽象和保留,而不是每一轮实验都像从头开始。
而许多现有Agent系统的状态表示并不适合这种长期科研过程。对话历史又长又散,难以承载结构化的研究判断;工作目录记录了代码变化,但并不解释这些变化对应的假设;日志保存了结果,却很难告诉Agent为什么成功或失败。最终,Agent虽然能执行很多次trial,但这些trial不一定能汇聚成真正的research progress。
Arbor试图解决的正是这个问题:如何把一次次短暂的实验,组织成可以长期积累、可以被审计、可以指导未来探索的研究状态。
△
Method:Arbor,迈向通用+实用的自主科研
Arbor想强调并实现两个要点:
通用性。Arbor不绑定某一个特定benchmark或任务形态,只要有待优化的artifact、明确的目标和可执行的反馈信号,无论是model、harness、data都可以优化。
实用性。为了让框架真实可用,Arbor开源了独立CLI和Agent Skill:你既可以直接使用完整的CLI进行长时间自动化研究实验,也可以在Codex/Claude Code等环境中加载Arbor-style skills实现平替的效果。
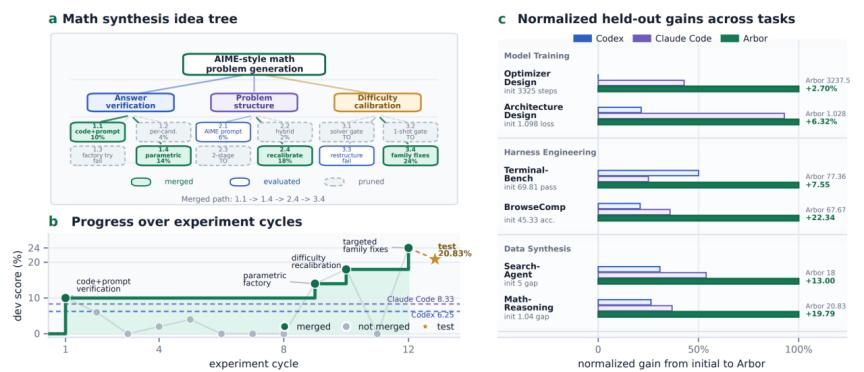
Hypothesis-Tree Refinement:持续演进与动态选择
Arbor的核心机制是 Hypothesis-Tree Refinement,HTR。它将整个研究过程外化为一棵持续演化的Hypothesis Tree。在这棵树中,每个节点都代表一个研究假设。这个假设不是一句随意的想法,而是一个可以被验证或证伪的claim:如果我们以某种方式修改artifact,是否会改进目标指标?
每个节点绑定四类信息:
Hypothesis,即当前节点想验证的研究主张
Artifact version,即该假设对应的代码、配置或数据pipeline修改
Experimental evidence,包括开发集分数、运行日志、错误信息、执行状态以及必要的held-out验证结果
Distilled insight,即这次实验沉淀出的可复用经验:为什么成功,为什么失败,在哪些条件下有效,哪些方向可能只是局部过拟合,后续探索应当继承或避免什么。
HTR的关键设计在于insight回传:如何让这些记录下的信息持续回流到研究过程本身。每次完成一个假设验证后,Arbor会观察实验结果并提取distilled insight,沿着父节点回写到整个Hypothesis Tree,借助这次实验更新对全局的认识。因此之后的改进并不是从空白上下文重复试错,而是基于整棵树中已有的假设、证据和经验,动态决定下一步应该扩展哪个leaf、合并哪个改动、剪枝哪个方向,或者生成哪些新的后续假设,保证每一步都是当前理解下的最优解。
这样一来Hypothesis-Tree不只是一个搜索树,也不是普通的实验日志,它同时承担三种角色:
搜索空间:记录哪些方向正在探索,哪些方向已经失败,哪些方向值得进一步展开。
长期记忆:把成功和失败都转化为结构化经验,而不是散落在对话历史或日志文件里。
研究记录:将每一次artifact修改和背后的假设、证据、决策连接起来,让整个过程可追踪、可审计。
通过这种机制,Arbor不再让Agent沿着单一轨迹盲目trial-and-error,而是让Agent在一棵持续生长的研究树上工作:每一次实验都会改变树的结构,每一次insight都会影响后续探索,整个系统因此能够在长时间、多分支的研究过程中不断积累证据、修正方向,并逐步逼近真正有效的artifact改进。
Coordinator+Executor:长期策略与短期实验分离
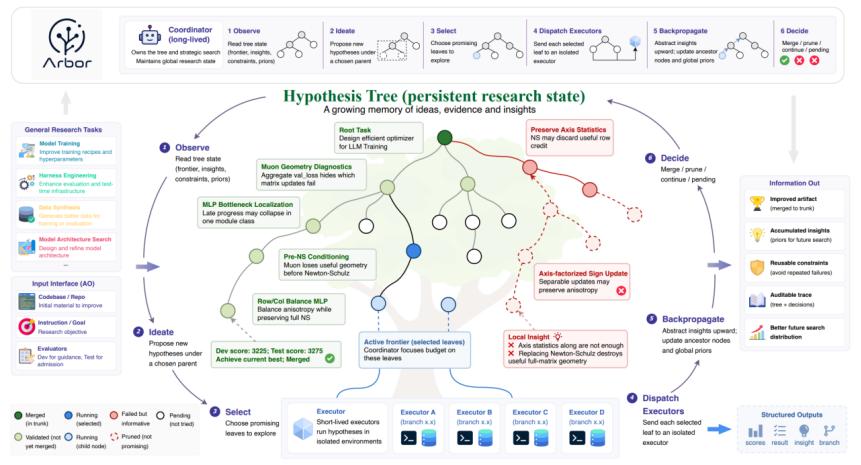
为了维护这棵Hypothesis Tree,Arbor采用了一个清晰的两级架构:长期存在的Coordinator和短期存在的Executor。
Coordinator可以理解为“研究负责人”。它维护全局Hypothesis Tree,观察当前研究状态,提出新的研究假设,选择值得执行的方向,并根据实验结果决定哪些方向应该继续、剪枝或合并。
Executor则更像“实验执行者”。每个Executor只负责一个具体假设。它会在隔离的worktree中修改代码、运行evaluator、检查失败原因,并将结果以结构化形式返回给Coordinator。返回的信息不仅包括分数,还包括artifact reference、实验现象和distilled insight。
这种设计对应长期科研需要的两种不同能力:一方面要有全局策略,知道整个研究过程走到了哪里;另一方面要有局部执行能力,能够把一个具体想法落地成代码并跑通实验。如果把这两者混在同一个长上下文里,低层执行细节很容易淹没全局研究判断。Arbor通过Coordinator-Executor分离,让全局研究状态保持清晰,让每个实验的证据能够准确回到对应的假设节点上,并借助git将功能实际落地。
Pipeline:不断进化的自主科研飞轮
Arbor的运行过程可以概括为一个持续循环的科研飞轮:
观察研究状态→提出候选假设→选择探索方向→分派实验执行→回传结构化证据→抽象insight→决定合并、剪枝或继续探索。
Coordinator首先读取当前Hypothesis Tree,包括已有方向、最近实验结果、失败归因、已验证insight和当前best artifact。随后,它会根据现在对问题的理解,自主选择一个当然最优的父节点继续展开,生成若干子假设。
随后Coordinator会从当前frontier中挑选最有价值的叶子节点交给Executor。Executor在独立环境中实现假设,并用development evaluator运行实验。实验完成后,Executor返回分数、结果记录、代码引用和insight。
接下来是关键的insight回传,Arbor的backpropagation传播的不是一个简单reward,而是更接近科研判断的结构化信息。例如,一个局部实验发现“某种接口不兼容导致方向失败”,这个insight可能会被抽象为更高层方向的约束,进而影响后续所有相关假设的生成。这一认知随着树结构天然向上传播,从而改进Arbor对当前实验的理解与认识。
最后Arbor决定当前候选是否应该被合并为新的best artifact。为了避免开发集过拟合,Arbor引入held-out merge gate:只有当候选在held-out evaluator上超过当前最优结果时,它才会被真正合并。
这使得Arbor同时具备探索性和验证性:开发反馈用于探索,held-out反馈用于确认真实进展。
Experiment:真实AO任务覆盖模型训练、Harness Engineering与数据合成
为了验证Arbor是否真的能支撑通用自主科研,论文构建了六个真实AO任务,覆盖三类研究artifact:
Model Training:包括optimizer design和architecture design,要求Agent改进训练算法、超参数或模型结构,在固定预算下获得更好的训练表现。
Harness Engineering:包括Terminal-Bench 2.0和BrowseComp,要求Agent改进另一个Agent的控制逻辑、工具使用方式或测试时推理流程。
Data Synthesis:包括Search-Agent Data Synthesis和Math-Reasoning Data Synthesis,要求Agent改进数据生成pipeline,使生成数据能更好地刻画搜索智能体或数学推理能力。
这六个任务都来自真实研究场景,而不是单一toy benchmark。每个任务都包含初始材料、自然语言目标、development evaluator、held-out test evaluator和任务原生指标。这样的设置模拟了真实科研中常见的模式:研究者可以在开发反馈上反复实验,但最终结果必须在独立测试上验证。与Arbor对比的是两个强大的单轨迹coding agent baseline:Codex和Claude Code。它们同样可以查看文件、修改代码、运行实验,并在相同资源预算下持续迭代。
△
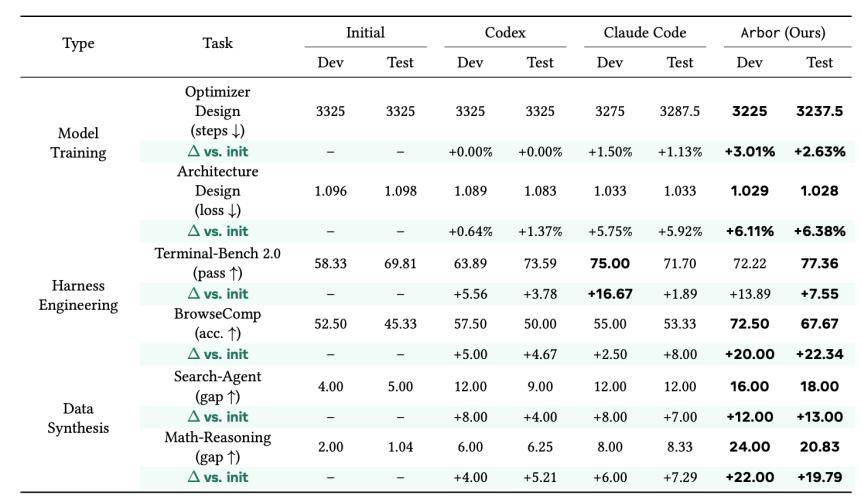
如上表所示,Arbor在六个真实AO任务上都取得了最佳held-out结果。在BrowseComp上,初始ReAct-style search harness的held-out accuracy为45.33,Codex提升到50.00,Claude Code提升到53.33,而Arbor提升到67.67。在Math-Reasoning Data Synthesis上,Arbor将held-out pass-gap提升了19.79个点,而Codex和Claude Code分别提升5.21和7.29个点。在Terminal-Bench 2.0上,Arbor也取得了最高held-out pass rate,从初始69.81提升到77.36。
总体来看,Arbor获得了超过Codex和Claude Code平均相对held-out gain 2.5倍的提升。这说明,在长程AO任务中,瓶颈不只是局部执行能力。即便强大的coding agent能写代码、能跑实验,如果缺少结构化的研究状态,它们仍然很难稳定地把多轮尝试积累成更强的artifact。
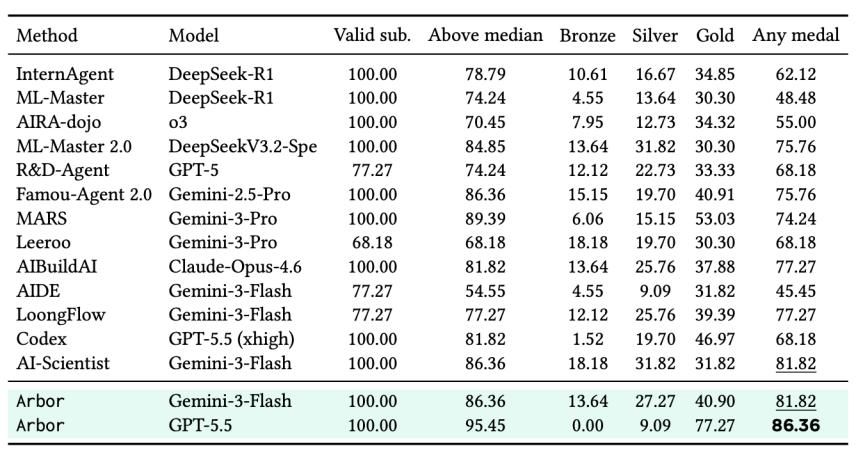
△
除了六个真实AO任务,Arbor还在MLE-Bench Lite上进行了评测。结果显示,Arbor with GPT-5.5达到86.36% Any Medal,达到了当前SOTA。这进一步说明,Arbor的方法并不只适用于作者构建的任务套件,也能够迁移到已有的长程机器学习工程benchmark上。
Analysis:不是更多试错,而是更好的研究组织
Arbor的实验分析进一步表明,其提升并不只是来自“跑了更多实验”。真正关键的是Hypothesis Tree对研究状态的组织方式。
- 更高效的探索
在六个任务的效果的成本日志里,Arbor 消耗的token与Claude Code等基线属于同一量级,却拿到了更大的held-out增益。这说明差距不在于花掉多少算力,而在于算力被组织利用的方式:它被拿去维护相互竞争的假设、跑隔离执行、对比证据、更新搜索树,而不是在一条轨迹上闷头试到底。
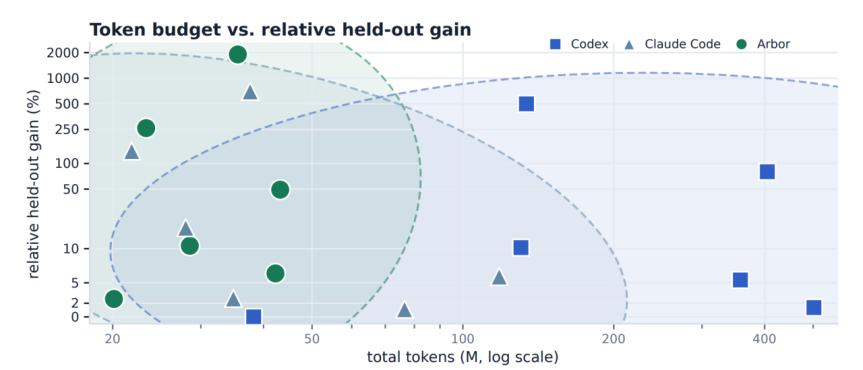
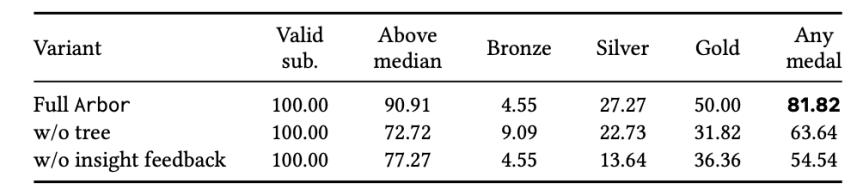
- 更有效的研究组织
论文在MLE-Bench Lite上消融了HTR最核心的两个组件:去掉假设树后,Any Medal从81.82%掉到63.64%;在保留树的前提下、再去掉insight的向上传播,进一步掉到54.54%。一个有点反直觉的结论是,只去掉洞察传播,比直接去掉整棵树掉得还多,这说明光有层次结构是不够的,一棵不传播经验的树只能把实验排排坐,却给不出后续决策真正需要的语义记忆。Arbor的核心价值,正是让agent的探索过程变得结构化、可积累、可验证,而不是简单地在agent外面套一个循环。
这也带来一个值得关注的insight: 自动科研的本质不是让Agent无限试错,而是让它在试错中逐步形成对问题的理解。
在Arbor中,失败不是被丢弃的负样本,而是被归因、被抽象、被传播的研究证据。成功也不是一个孤立的分数提升,而是可以被复用的局部发现。
随着Hypothesis Tree不断演化,Agent的搜索分布会被已有evidence持续塑形:它会更少重复已经失败的路径,也更容易围绕有效机制继续细化。
这让Arbor更接近人类研究者的工作方式。人类做研究时,也不会只记住“哪个实验分数最高”。我们会记住哪些想法失败了、失败原因是什么、哪些约束不能违反、哪些局部改动可能具有更广泛的意义。Arbor正是试图把这种研究记忆显式化,并变成Agent可以操作的系统状态。
Future:通用自主科研的下一步
当然,Arbor并不意味着Agent已经具备人类研究者级别的创造力。当前Agent生成idea的质量仍然有很大提升空间。在困难任务中,它可能难以提出真正新颖的机制,也可能过早放弃一个潜在方向。自动科研仍然面临大量open questions:如何产生更高质量的研究假设,如何更准确地区分真实提升和偶然过拟合,如何在更长周期中维护可靠记忆,如何让人类研究者与自主Agent更好协作。
但Arbor给出了一个重要答案:要让Agent从“执行任务”走向“自主科研”,不能只依赖更长上下文、更强模型或更多工具。我们还需要一种机制,把多轮探索组织成持续演化的研究状态。
从这个角度看,Arbor的意义不只是提出了一套新的agent framework。它希望回答一个更大的问题:
当Agent已经能写代码、跑实验之后,怎样才能让它真正积累研究进展?
Arbor的答案是:让Agent像研究者一样维护假设、证据、失败和insight,让每一次实验都成为下一次探索的基础。
这也许正是从执行型Agent走向研究型Agent的关键一步。
作者简介:
本文第一作者金佳杰,中国人民大学高瓴人工智能学院博士一年级,导师为窦志成教授。他的主要研究方向包括智能体、检索增强生成等。以第一/共同第一作者身份在ICLR、NeurIPS、ACL等国际顶级会议发表论文多篇论文;代表工作包括FlashRAG,FinSight,WebThinker,Search-o1等,受到国内外研究者的广泛关注,个人GitHub项目累计获得星标5000余枚。
共同第一作者扈煜阳,中国人民大学高瓴人工智能学院博士一年级,导师为窦志成教授,主要研究方向为长程智能体,包括智能体记忆、自进化智能体等。
本文的通信作者为人大窦志成教授。
论文标题:Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
论文链接:https://arxiv.org/pdf/2606.11926
代码仓库:https://github.com/RUC-NLPIR/Arbor
项目主页:https://ruc-nlpir.github.io/Arbor/
作者金佳杰个人主页:https://ignorejjj.github.io/
作者扈煜阳个人主页:https://namespace-eri.github.io/
