

IT之家 6 月 25 日消息,百度于 6 月 22 日开源推出 Unlimited OCR 模型,总参数量 30 亿,推理时仅激活 5 亿参数,目标解决在解析长文档时,端到端 OCR 模型越生成越慢的问题。
IT之家注:端到端 OCR 模型是统一神经网络架构系统,融合检测图像中的文本和字符识别,摒弃了传统“先检测文字框、再单独识别”的繁琐流程,直接从输入图像映射到文本序列输出,从而减少信息丢失和计算冗余。
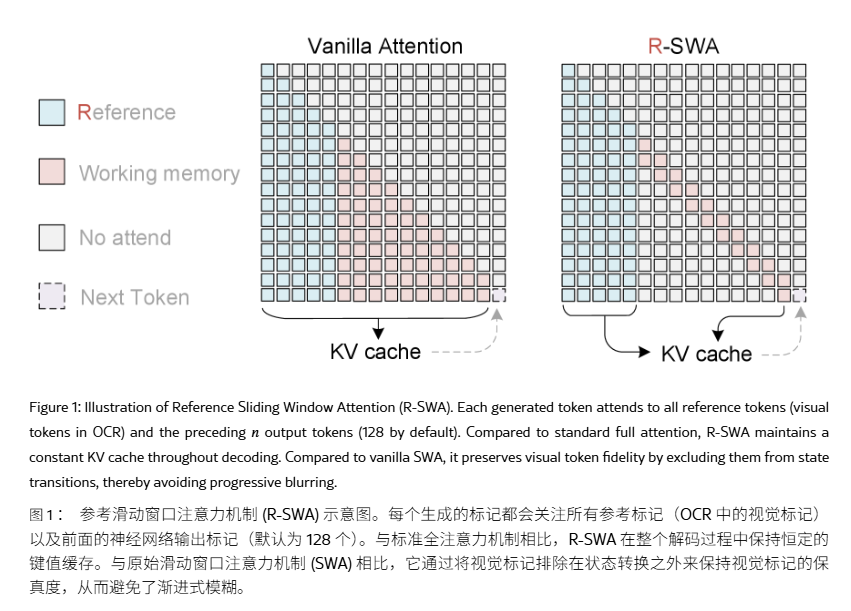
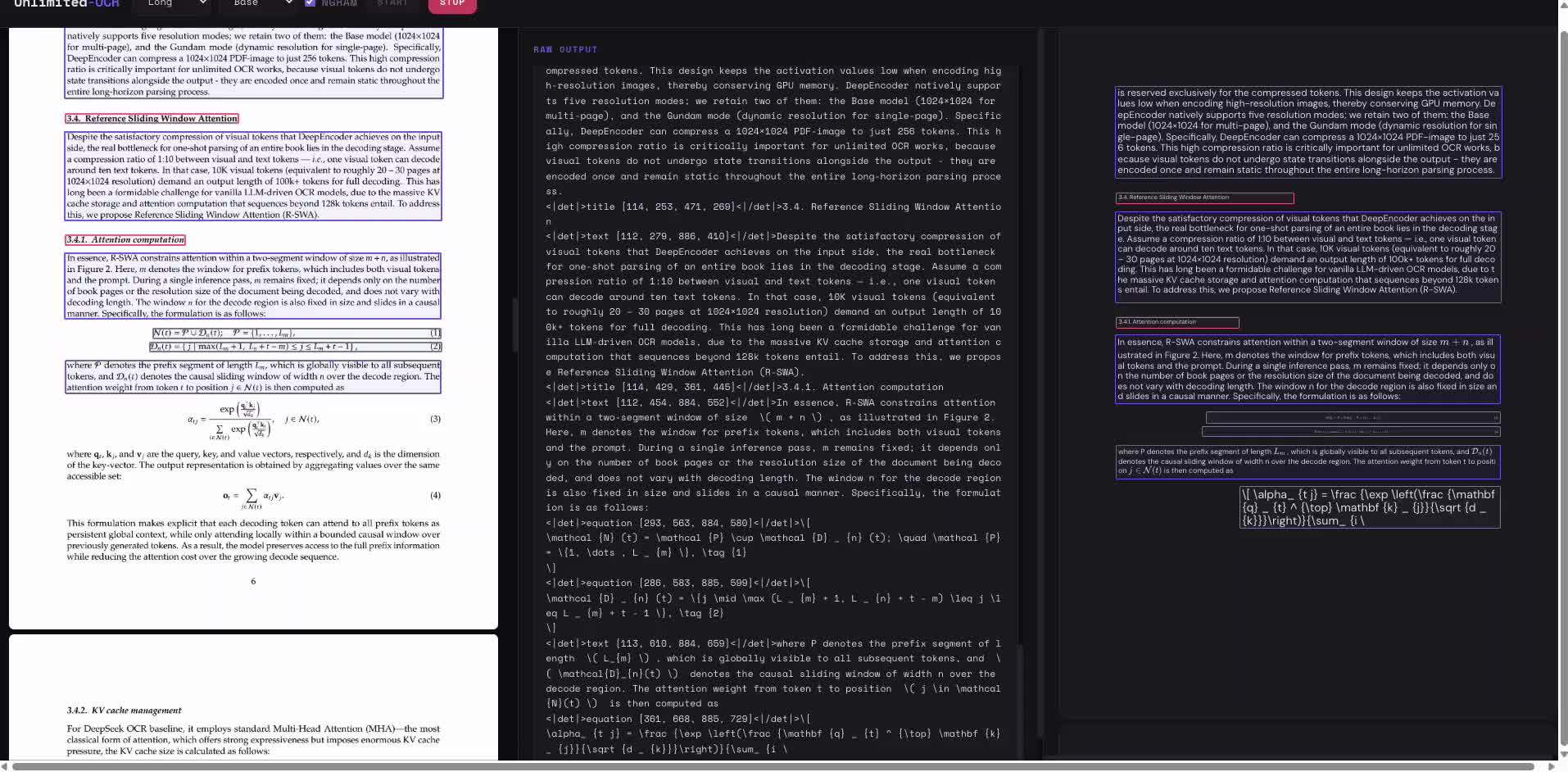
主流端到端 OCR 模型每生成 1 个 token,都会扩大 KV cache(键值缓存),显存占用和延迟随之上升,导致在用户的感知中,AI 解析多页文档后越生成越慢。
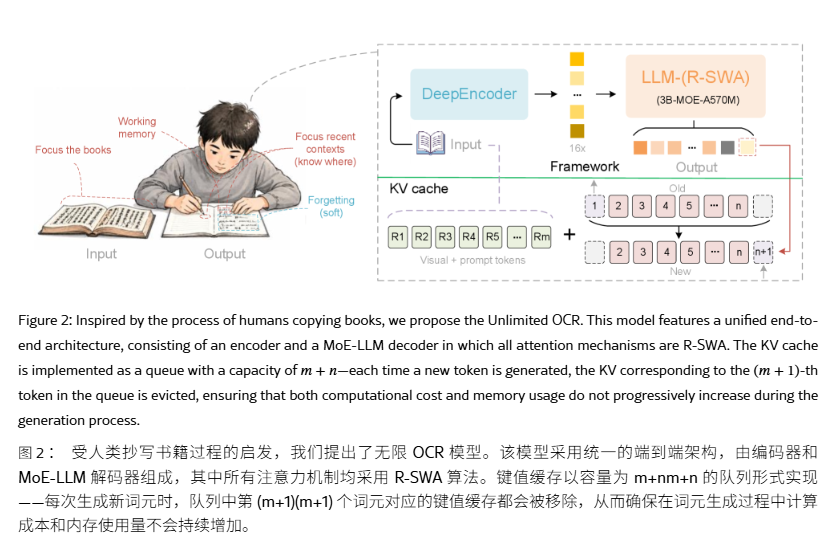
Unlimited OCR 延续 DeepSeek OCR 架构,保留 DeepEncoder 与 Mixture-of-Experts(混合专家,MoE)解码器。模型总参数量为 30 亿,但推理时只激活 5 亿参数。
Unlimited OCR 编码端采用两级视觉编码,并在连接阶段执行 16 倍 token 压缩,让 1024×1024 的 PDF 图像压缩为 256 个视觉 token,从源头减轻预填充负担。
训练方面,Unlimited OCR 基于 DeepSeek OCR 检查点继续训练 4000 步,冻结 DeepEncoder,只训练解码器。训练数据约 200 万份文档样本,运行在 8×16 A800 GPU 上。数据配比为单页与多页约 9:1,多页样本通过拼接构造。
基准测试显示,Unlimited OCR 在 OmniDocBench v1.5 上整体得分 93.23,高于 DeepSeek OCR 的 87.01,也高于 DeepSeek OCR 2 的 89.17。

其文本编辑距离为 0.038,公式 CDM 为 92.61,表格 TEDS 为 90.93,读序编辑距离为 0.045。在 OmniDocBench v1.6 上,模型整体得分进一步达到 93.92。
参考
Unlimited OCR Works Welcome the Era of One-shot Long-horizon Parsing
Unlimited OCR Works 的 GitHub 页面(已获 6.8K Star)
