

每次写 Codex 的教程或者使用案例,都有读者询问,这个 Token 消耗情况怎么样。
虽然免费也能用 Codex,但不同的档次 Plus、Pro 5x、Pro 20x 所包含的 Token 额度完全不同,怎么省 Token 成了这段时间以来社交媒体上的热门话题。
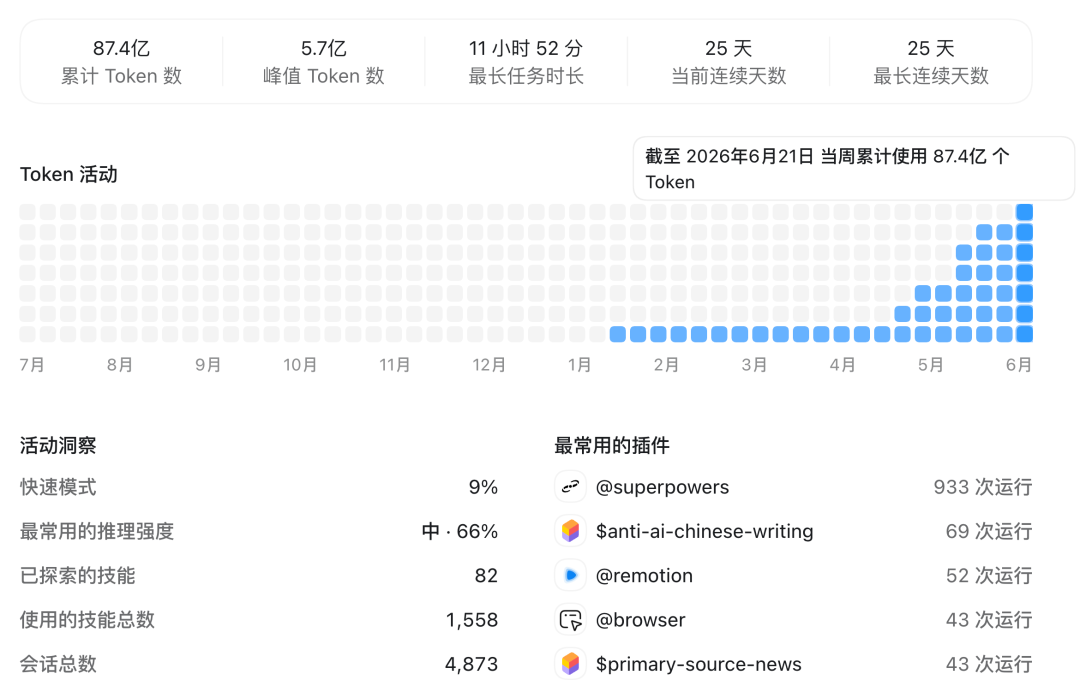
之前 Claude Code 爆火的时候,有开发者设计了一款穴居人的 Skill。
在请求模型之前,它会自动压缩 prompt 和上下文,让传输的内容更短,但含义不丢。其次,它通过在本地持久化保存常用上下文或历史对话,为 Agent 提供记忆以减少反复调用。
这些压缩策略和优化计划能降低 Token 的消耗,项目主页显示可以省下 65% 的 AI 开支,目前在 GitHub 上即将达到 8 万个 Star。
最近另一个叫「马尾辫」的项目在 GitHub 上开始被疯狂下载,直接拿下了 GitHub 热门榜单连续三周的周榜第一。
这个项目的介绍图也特别有意思,在项目描述里写着,
你一定认识他,长长的马尾辫,椭圆形眼镜,在公司待的时间比版本控制系统的历史还长。你给他看五十行代码;他看了看,什么也没说,然后只用一行替换掉。

这套刻板印象不仅有点冒犯,给程序员看,他们大概还会表示,「女装明明才是顶级程序员的底层逻辑」。
概括性地说,这根马尾辫还是通过「少写不必要的代码」来减少 token 消耗。不过,它并非一个单纯的压缩或摘要工具,Ponytail 本身有一套 给 AI agent 的 Skill,让 agent 在动笔之前先判断好,怎么用最少的 Token 可以完成这个任务。
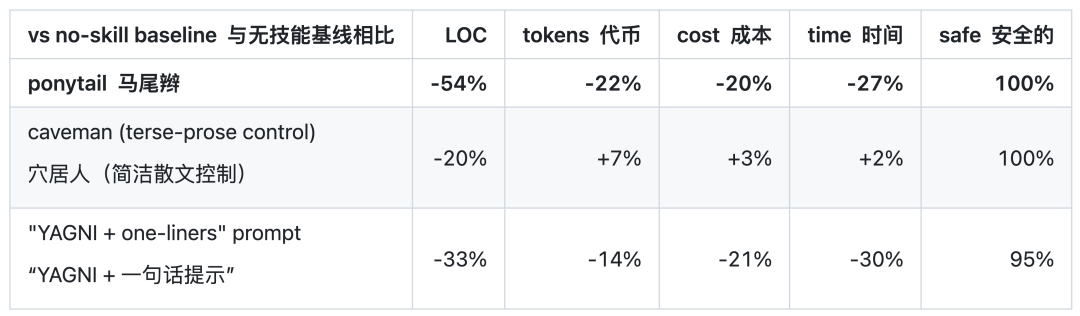
而根据他们的测试,部分场景下,它能直接做到代码量减少 80-94%,成本降低 47-77%,速度提升 3-6 倍。和其他类似工具的对比,马尾辫要比穴居人在 Token 消耗、成本、时间和代码行数上都要少,并且 100% 安全。
我们也把它安装到 Codex 上体验了一下,发现在部分场景下,Ponytail 确实能保证在结果一致的情况下,使用更少的 Token,但也会有新的麻烦点。
安装到 Codex
如果在 Codex 插件市场输入「Ponytail」可以直接搜索到的话,就能直接点击安装了。
如果没有,我们需要打开电脑终端,在命令行中输入「codex plugin marketplace add DietrichGebert/ponytail」,等待终端显示已经安装完成即可。
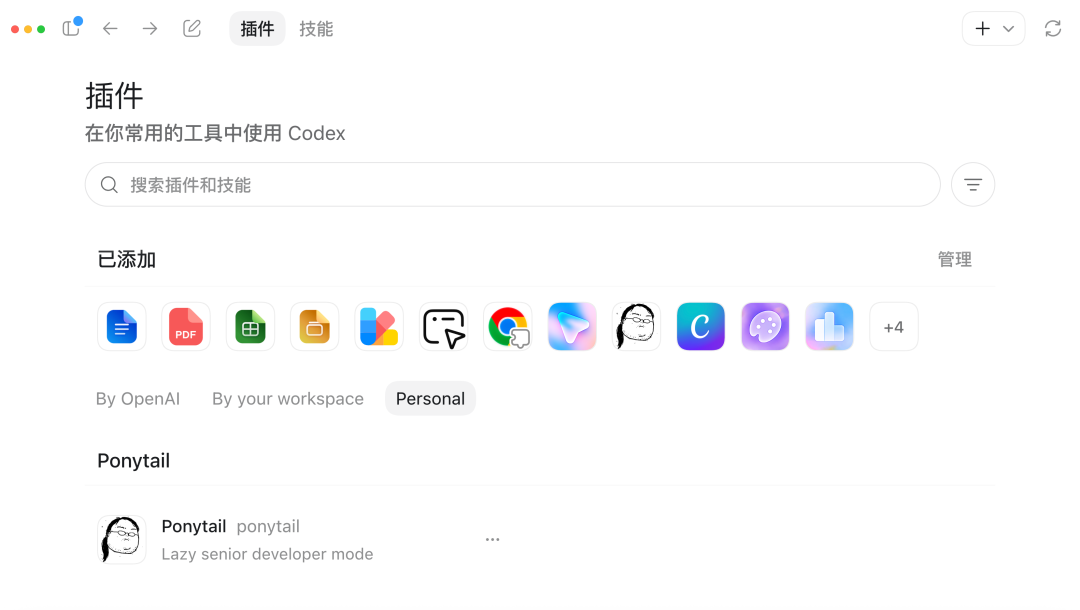
在 Codex 应用内,点击插件主页右上角的刷新按钮,在 Personal 部分就会显示已经安装好的 Ponytail。
可以看到 Ponytail 的介绍里面直接写着「YAGNI」,即 You Aren't Gonna Need It 的缩写,直译过来就是「你不会需要它的」。这也是极限编程(XP)里的一条原则,核心意思是:在真正需要某个功能之前,别去实现它。
Ponytail 的插件内包含了 6 个 Skill,这些技能里只有第一个是真正会动手改代码的,其余五个都是围绕这个理念做的检查、记账和展示工具。
第一个主 Skill Ponytail,开启后强制走最精简路线,支持三档强度:lite(轻)、full(默认)、ultra(极端)。触发词包括 「ponytail」、「be lazy」、「简单点」、「yagni」、「少做点」,或者在用户吐槽某段代码过度设计、充斥样板代码、依赖过多时也会触发。
Ponytail Review 和 Ponytail Audit 主要是看代码的改动以及整个仓库的代码,扫描整个代码库,给一份排好序的清单,什么该删、什么该简化、什么能换成标准库/原生实现。
Ponytail Debt 意思是技术债账本,Ponytail 偷懒时会留下 ponytail: 注释,标记「这里先这么糊弄,以后再说」。这个技能可以把全代码库里这些注释收集起来,整理成一份债务清单,免得那些故意留下的捷径毁了整个项目。
Ponytail Gain 则是把 Ponytail 的实测效果做成一个紧凑记分牌:少写了多少代码、省了多少成本、快了多少,数据来自基准测试的中位数。
不过技能是被动加载的,我们必须手动选择使用该插件,或者在提示词里明确说出「Ponytail」等触发词,模型才会判断该用某个技能了。
因此 Ponytail 还设置了 3 个钩子,全部信任后,能保证 ponytail 在「会话开头、每一轮对话、以及派给子智能体时」都不掉线。
了解了 Ponytail 的基本情况,我们做了一些简单的小测试,像是实现同样的提示词任务,最后交付的成果和 Token 使用会不会有大的差别。
我们还没有启用钩子,于是从插件市场的「在对话中试用」去开启。最明显的不同,就是 Ponytail 会一直问我问题,像是要做桌面键盘还是手机滑动。虽然说着如果懒得选,它会按 B 开工,但事实是我们必须输入对应选项,任务才会继续。

回答了这个问题之后,又有新的问题,要做什么样的视觉取向。我想在 Ponytail 的技能里面,大概提到了如果要偷懒,还是要给用户选择,以何种形式来呈现最终的结果,Ponytail 自己无法决定是否真的采用极简实现。

最后呈现的效果其实差不多,使用 Ponytail 消耗的 Token 是 103815,剩余 60%,而没有使用该插件是 109033,剩余 58%,相差并不是很大,游戏的体验上,也都类似,简单的 2D 风格,三个不同的跑道,设置的障碍物都类似。
而如果是读同一个代码仓库,分别要求他们「帮我看看这个仓库里有些什么 bug,这个仓库是一个什么代码仓库」。
正常情况下,Codex 在当前的会话里面使用 243923 个 Token,剩余 6%,得出的结论是
这是一个股票智能分析系统仓库:Python 后端 + FastAPI API + 多数据源行情抓取 + LLM 分析报告 + 通知推送,另外有 React Web 工作台和 Electron 桌面端。覆盖 A 股、港股、美股等,自选股分析、市场复盘、历史报告、回测、配置管理、机器人/通知都在里面。
而诊断出的 Bug/风险有 5 个,大多是在本地部署或者云部署过程中,有裸奔风险的提醒。
在 Ponytail 的测试过程中,它的思考流程里则是很清楚地写着「接下来我会跑最便宜的确定性检查:先看 Python 语法和关键静态错误。能被机器直接抓住的 bug,优先让机器抓。」
Ponytail 用时 5 分钟,得出的结论和不使用 Ponytail 插件的结果类似,扫描到的问题也有 5 个,基本和正常状态的 Codex 一样,同样提到了在本地或者云端部署时,可能会有风险。
但这次 Codex 还剩余 26% 的 Token,而未使用 Ponytail 的任务里,只剩下了 6% 的上下文 Token 余量,直接省下了 52277 个 Token。
所以,不同的任务,应用 Ponytail 的效果也可能有所不同。
马尾辫的适用场景有哪些
根据 Ponytail 官方的测试,他们挑选了一些前端和后端任务。
比如写一个日期选择器、颜色选择器、文件上传框。普通 Agent 很可能上来就装依赖、写组件、加样式、补状态管理,最后一个小功能变成几十行甚至几百行代码。
Ponytail 会先问一句:平台自己有没有?标准库有没有?代码库里有没有现成实现?
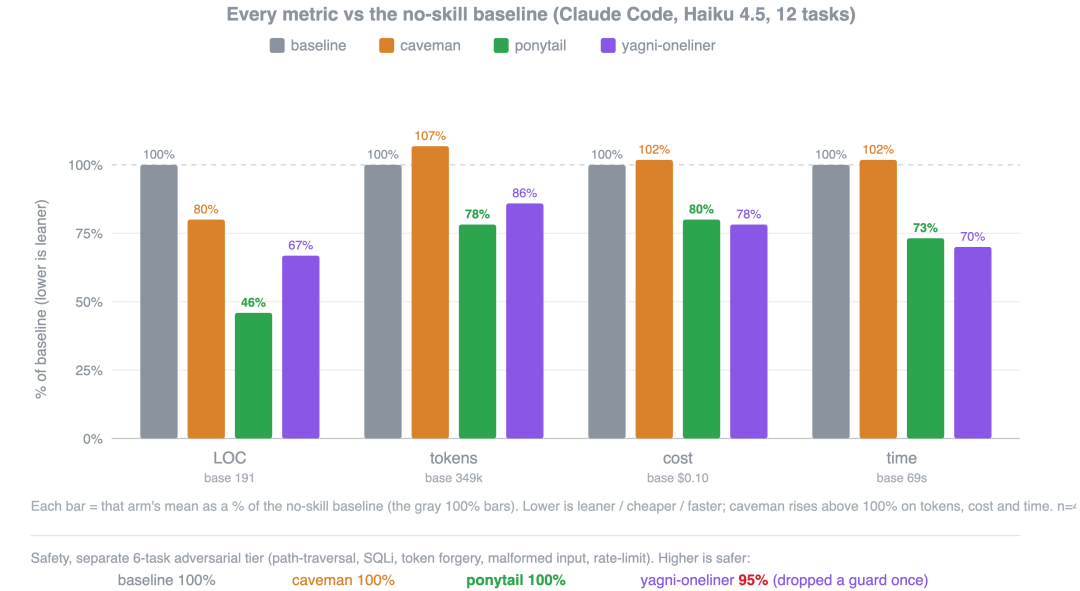
同样用 Claude Code + Haiku 4.5 跑 12 个真实功能任务,不同省代码策略相对普通 Claude Code 的表现。
测试的结果也显示,Ponytail 在这些场景下省得最明显。代码行数 LOC 上,日期选择器从 baseline 的 404 行降到 23 行,颜色选择器从 287 行降到 23 行,文件上传从 251 行降到 95 行。
所以它适合这几类任务:
一类是前端小功能。表单控件、设置项、简单交互、上传、筛选、排序、弹窗、评分、开关、日期和颜色选择,都容易被 Agent 重复写一遍。
其次是已有项目里的局部修改。比如「加一个字段」「补一个校验」「修一个边界情况」「把这个页面接上已有 API」。Ponytail 会优先读现有代码,复用项目里已经存在的函数、组件和模式。
还有代码评审和项目瘦身等任务。对于「从零开始做一个完整产品」这类任务,省 Token 或者省代码行数未必明显。
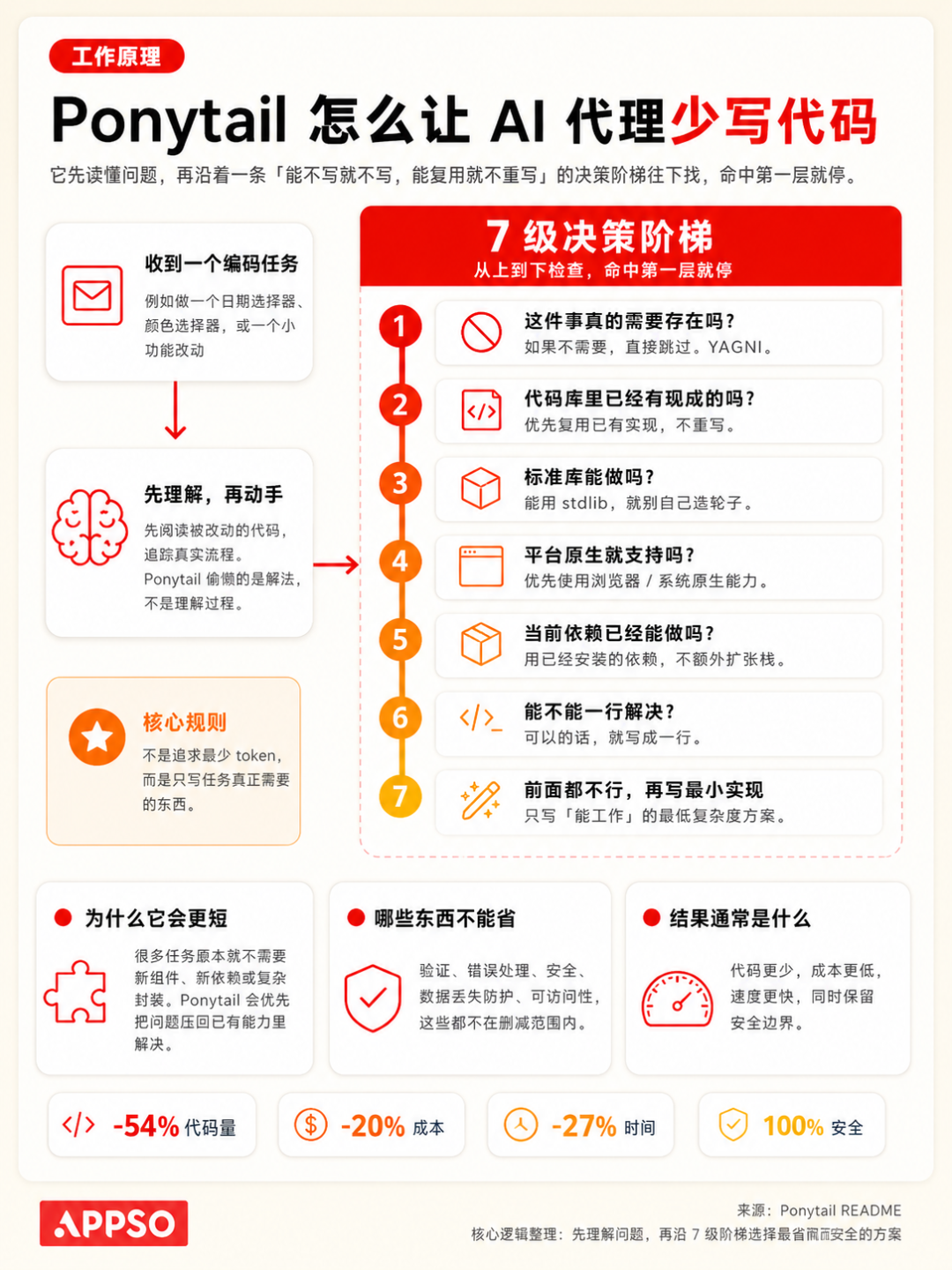
就像 Ponytail 采用的方式是持续的判断,Agent 动手前,要像爬梯子一样,一关一关去检查。
能不做,就跳过。代码库已经有,就复用。标准库能做,就用标准库。平台原生能做,就用平台。已安装依赖能做,就用依赖。一行能做,就写一行。走到这里还不够,再写最小可用实现。
但这个判断的过程,对于部分 LLM 来说也是一种新的负担。也有网友说,代码行数并不是越少越好,可读性也是其中非常重要的一点。

也有网友说,用了 Ponytail 之后,实测 Token 消耗回到了当时两倍促销活动的水平。
其实除了 Ponytail 和 穴居人,类似的工具还有很多,例如 Headroom 净空,同样是在工具输出、日志、文件和 RAG 数据块等上下文,到达 LLM 之前对其进行压缩,显示能减少 60-95% 的 Token, 并保持结果不变。
有意思的是,开发 Headroom 的作者还是一位 Netflix 的工程师。
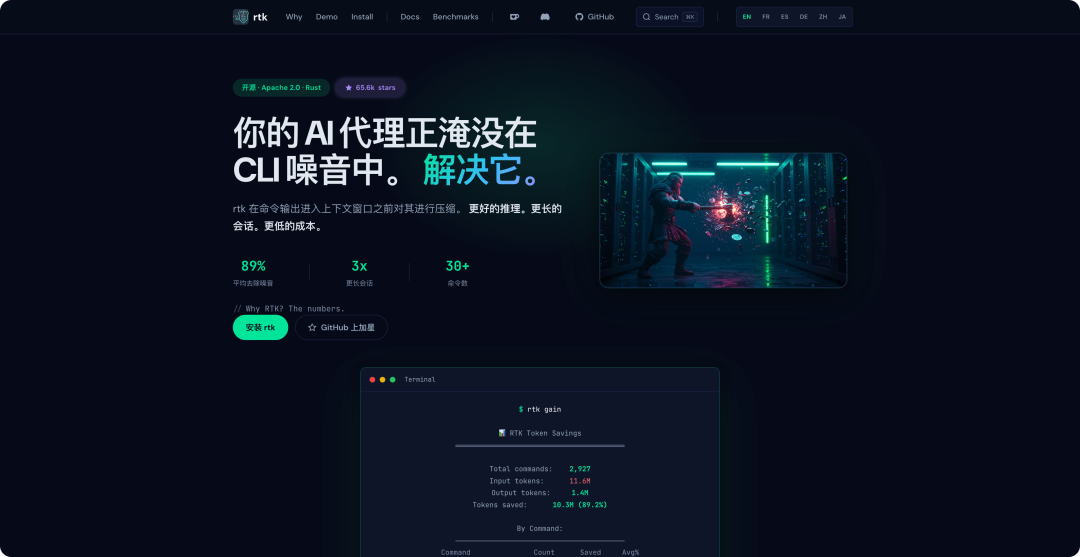
还有 RTK-AI,一个命令行 Agent 工具,专门用于在各类 AI 编程助手,如 Claude Code、Cursor、Copilot 等,自动把命令的输出压缩 60%~90%,从而大幅减少发送给大模型的 token 数量,实现省钱的同时还能提高响应速度。
这些工具表面上是在帮用户省 Token,背后其实是在教 Agent 学会克制。
过去一年,大家讨论更多的是怎么让 Agent 做得更多:更长的上下文、更复杂的规划、更强的工具调用能力。于是 Agent 逐渐养成了一种习惯——遇到问题先开干,先生成,再修改,最后补丁摞补丁。
但随着 Token 开始成为真实成本,另一条路线也开始出现:哪些步骤其实可以跳过,哪些代码其实已经存在,哪些工作其实没必要重复完成。
对于人类程序员来说,这并不是什么新理念。优秀工程师最大的价值,大多数时候体现在他的判断力上,知道怎么写出最优美的代码。
如今,这种判断力也开始被封装成各种 Skill 和工作流,成为 Agent 学习的新内容。

以往 Claude Code 和 Codex 是最擅长从社区找各种 idea 然后打包成自己的产品,之前的做梦机制、桌面宠物等功能都是先有个人开发者做出来类似的小玩意,然后被 Claude Code 复制过去。
但现在这种省 Token 的机制,恐怕 Codex/Claude Code 那边是只想等着你充钱,免费不够,请开 Plus,Plus 不够,请开 Pro,Pro 还不够,请买点数。
