

在《从 “白日梦” 到 “万贯金”,Space X 真那么 “科幻”?》中,海豚君讲过,SpaceX的三大业务板块(火箭发射、Starlink、AI业务)中,AI业务是最烧钱、但也是估值想象力最大的板块。
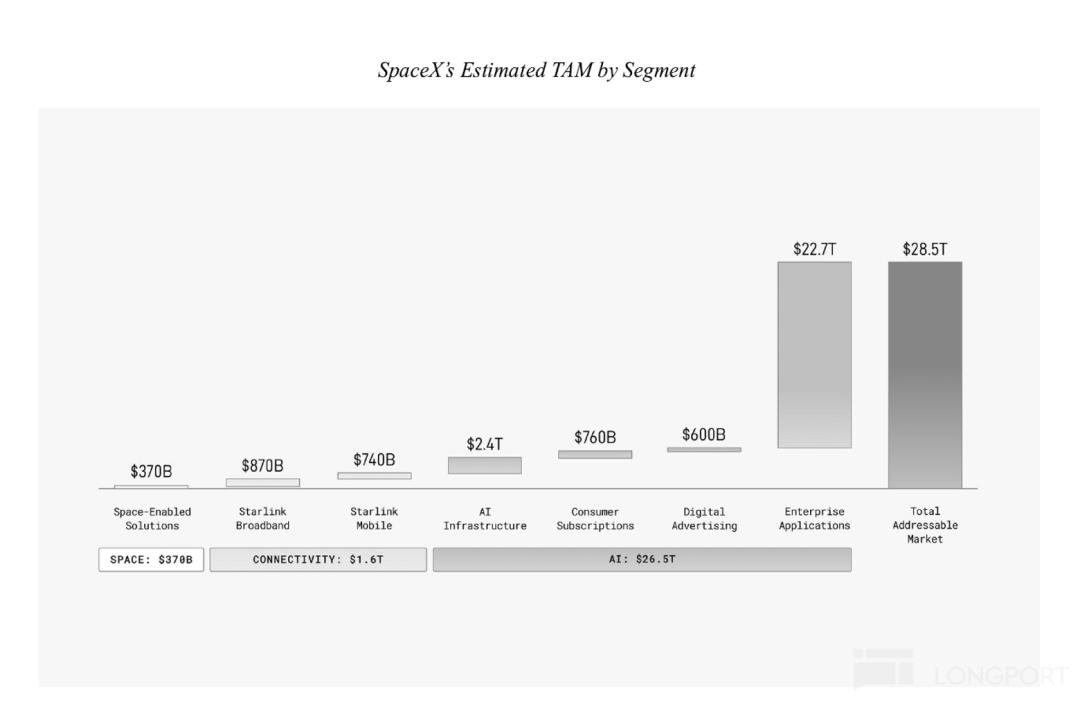
它不仅承载着 SpaceX 从“硬核航天基础设施巨头”向“平台级智能服务商”跨越的核心叙事,更是支撑其高达 28.5 万亿美元总潜在市场规模(TAM)的绝对基石——在总 TAM 中,AI 业务的占比高达 93%,而其中的企业端应用更是贡献了近 80% 的市场空间。
而本篇海豚君将深度拆解AI板块,重点关注以下核心问题:
一、SpaceX 的 AI 资产版图究竟由哪些核心模块构成?
二、作为底层数据源的 X 平台,为何广告收入持续承压下滑?
三、被寄予厚望的 Grok 大模型,目前的智力与商业化进展如何?
四、算力租赁业务:一场意料之外的“现金流盛宴”能持续多久?
五、太空数据中心:从地面演练跨入“天基算力霸权”,究竟是星际科幻还是降维打击?
以下是详细分析
一、SpaceX的AI资产包含哪些核心模块?
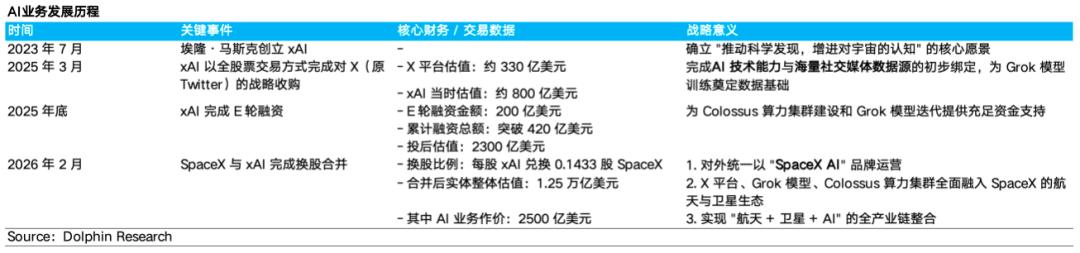
SpaceX的AI业务是在2026年2月全资收购xAI后正式成型的。其发展历程如下:
马斯克于2023年7月创立xAI,愿景是“推动科学发现,增进对宇宙的认知”。2025年3月,xAI以全股票交易方式完成对X(原Twitter)社交平台的战略收购。彼时,X平台估值约330亿美元,xAI估值约800亿美元,完成了数据源与AI业务的初步绑定。而到2025年底,xAI完成200亿美元E轮融资,投后估值达2300亿美元。
2026年2月,SpaceX与xAI完成换股合并,合并后实体整体估值达1.25万亿美元(其中AI业务作价2500亿美元),对外统一以“SpaceX AI”品牌运营。自此,X平台、Grok模型、Colossus算力集群全面融入SpaceX的航天与卫星生态。
伴随体系并入,原xAI高管团队发生重大调整。SpaceX Starlink工程资深高管Michael Nicolls出任AI部门总裁,这也代表了,Space X将在战略上开启了“太空边缘计算与空间 AI”深度融合的新纪元。
从SpaceX AI业务的收入构成来看,其收入由广告收入和AI解决方案及基础设施收入两大板块构成。
广告收入主要来自X平台,而AI解决方案及基础设施收入则主要包括:1)X平台订阅及数据授权服务收入;2)Grok大模型订阅及API访问服务收入;3)算力基础设施(Colossus集群)租赁收入(2026年起显著放量)。
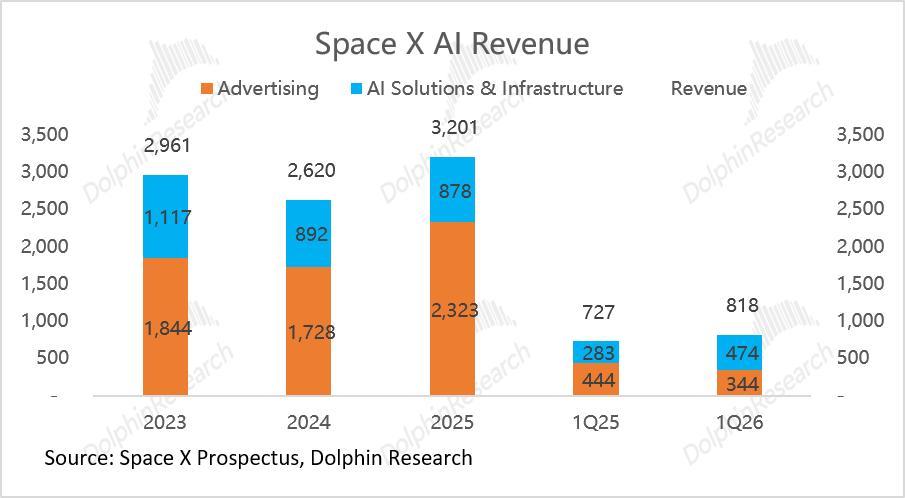
在2023-2025年三年间,SpaceX的AI业务收入增速相对缓慢,从29.6亿美元增长至32.0亿美元,2年复合增速仅4%。
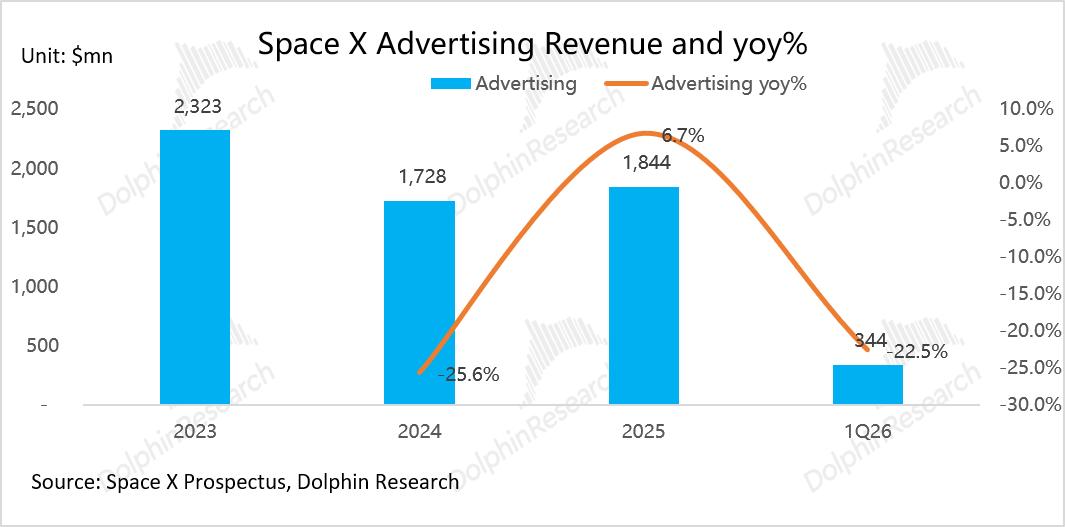
增长贡献主要来自AI解决方案和基础设施服务收入,从2023年的6.4亿美元增长至2025年的13.6亿美元,2年复合增速达46%;与之相反,来自X平台的广告收入反而在持续下滑,从2023年的23.2亿美元降至2025年的18.4亿美元,年均降幅约11%。

我们先来依次看看Space X AI业务核心的四个板块:① X平台;② Grok大模型;③ 算力租赁业务(Colossus 集群);④ 太空算力业务:
二、作为底层数据源的 X 平台,为何广告收入持续承压下滑?
X平台(原名Twitter)在2022年底被马斯克以440亿美元收购后,经历了根本性重塑。其身份从原来的社交媒体平台,转变为xAI的“数据粮仓”和“分发渠道”:
在数据端,其每日 3.5 亿条实时帖文为Grok大模型提供了独家的高时效训练语料;在分发端,坐拥 5.5 亿月活的 X 平台构筑了天然的零成本流量入口——目前已有约 1.17 亿用户触达并使用了 Grok 的 AI 功能,整体X平台付费用户达 440 万,付费渗透率约为 0.8%。
然而,X平台的广告收入自2022年达到巅峰后持续下滑,海豚君认为,这一下滑是行业结构性趋势与内部战略收缩双重因素导致的结果:
① 品牌广告基因遭遇“效果化”围剿
X平台(从Twitter时代起)的广告基因一直偏向品牌广告(Brand Awareness),侧重于品牌曝光与话题营销。然而,整体品牌广告预算正因地缘政治与宏观经济的不确定性而持续承压。在预算有限的环境下,广告主越来越追求可量化的ROI,资金加速从“曝光导向”平台流向“转化导向”平台。
相比之下,X平台的竞争对手在“转化效果”上拥有不可替代的优势:
a. TikTok:凭借统治级的用户时长构建了高粘性的广告体系。
b. Google搜索:握有最明确的“购买意图”——用户的每一个搜索词都是商业需求的直接表达。
c. 亚马逊:拥有最直接的“购买行为”数据,构建了极具成本竞争力的效果广告产品。
D. Meta:凭借AI驱动的前沿广告技术(如Advantage+、GEM推荐模型),建立了业界领先的转化追踪与归因能力。
反观X平台,其从“看广告→下单”的全链路效果上始终显著薄弱于以上四位对手。随着公司将算力与研发资源大规模倾斜至 Grok 等通用大模型的开发,广告 AI 算法的迭代进一步被滞后 (广告投放精准度不够)。
② 战略收缩引发的“品牌出走”:
2023年,马斯克对X平台进行了大规模的战略收缩,将资源重点投向AI等核心方向。大规模裁员(尤其是内容审核团队的裁撤)以及对言论尺度的放宽,直接触碰了大型广告主的“品牌安全”红线,引发了 “品牌出走潮”——大量主流广告主因担忧品牌内容安全而暂停或撤出投放。
这不仅导致 X 平台 2024 年广告收入同比下滑26%至17亿美元,叠加粗暴更名“X”带来的用户认知割裂与品牌资产流失,最终致使公司在 2023 年确认了高达 38 亿美元的商誉及无形资产减值损失。尽管平台后续试图通过完善内容管控与推出新广告组件来修补与金主的关系,但重建商业信任的过程注定漫长。
③ 广告平台主动改造的短期阵痛:
进入2026年Q1,X平台为彻底扭转技术劣势,对底层的AI广告基建进行了全面重构,重点部署了:全自动化投放系统、AI概率归因追踪、Grok驱动的实时品牌安全风控,以及广告与推荐流算法的底层融合。
然而,这种激进改造短期内不可避免地打乱了销售节奏,致使当季广告收入同比下滑约1亿美元(yoy -22.6%)至3.4亿美元。但这次重构能否真正挽回流失的广告主预算,仍需要持续观察。
而马斯克对X平台的最终构想,是将其打造为一个“万物应用(Everything App)”——融合AI、支付、通信、内容与商业的超级入口,本质是从单一广告依赖升级为“AI服务驱动”的多元变现引擎(订阅、广告、支付、商业)。通过Grok模型贯穿所有环节,形成数据→模型→变现→用户的自强化闭环。
但从现实来看, X 平台目前已经陷入“美国版微博”的窘境:虽然在突发大事件中仍是舆论中心,但日常商业流量与用户粘性正被竞品系统性蚕食,市场份额持续承压。
三、被寄予厚望的 Grok 大模型,目前的智力与商业化进展如何?
Grok 是 xAI自主研发的大语言模型系列。其最具差异化的核心优势,在于对 X 平台(原 Twitter)每日约 3.5亿条实时帖文的独家访问权。不同于 ChatGPT 依赖外部非独家合作(如 Reddit)或网页检索,X 平台是全球突发新闻的“第一现场”。
这种“秒级时效 + 独家垄断”的动态语料输入,让 Grok 具备了相比其他大模型更强的数据实时性。
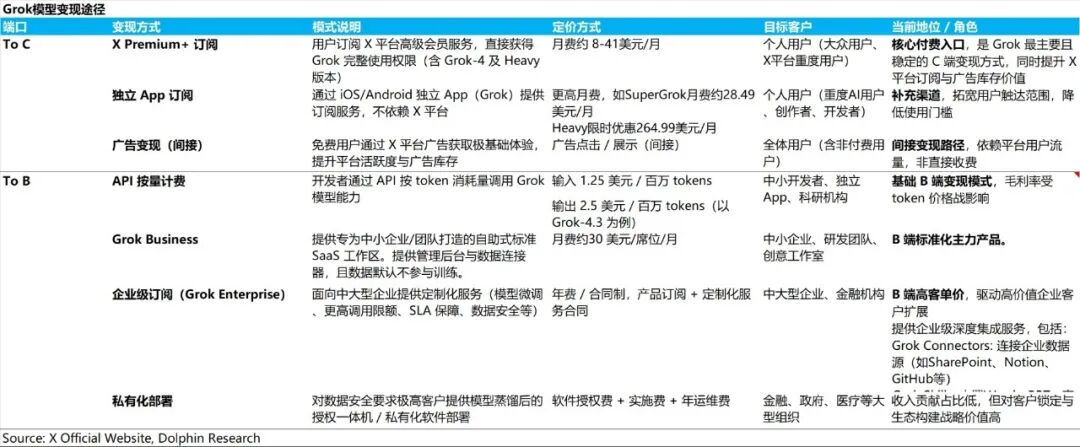
自发布以来,Grok 已构建起 “多轨并行” 的商业化变现矩阵:
To C(消费端): 通过绑定 X 平台会员(Premium/Premium+)以及推出 SuperGrok 独立阶梯套餐(Lite/Standard/Heavy),满足不同个人用户的需求;同时,以免费版引流反哺 X 平台的广告价值。
To D(开发者端)提供兼容行业标准的 Grok API,以按量计费模式为开发者与初创团队提供灵活的模型调用服务。
To B(企业端):
中小团队:提供线上自助、按席位计费的标准化 SaaS 服务(Grok Business)。
中大型及合规机构:提供合同制的专属套件(Grok Enterprise)及专有云/本地部署,满足私有数据接入、合规与定制微调等深度需求。
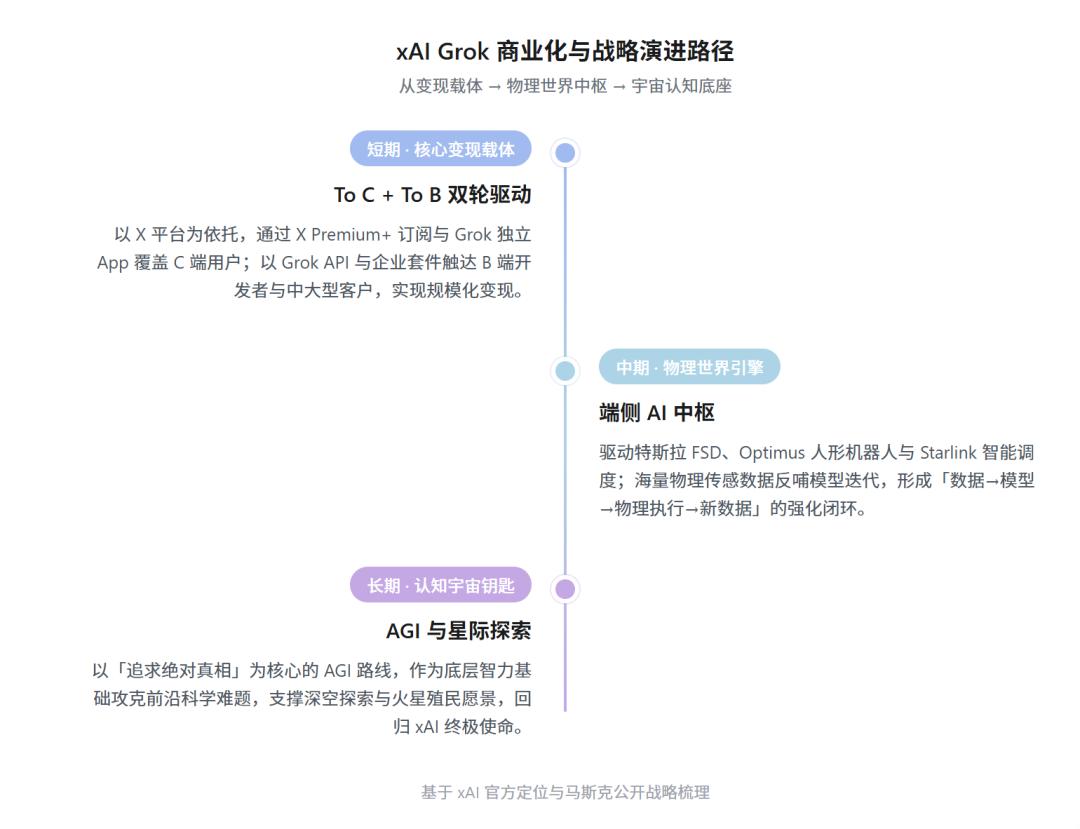
而在马斯克的宏大商业版图中,Grok 扮演着最具想象力的中长期业务中枢。它被构想为贯穿特斯拉、SpaceX、X、Optimus 与 Neuralink的“中央大脑”,其战略部署如下:
短期以X平台为依托,通过X Premium+订阅与Grok独立App订阅实现To C覆盖,同时以Grok API和Grok Enterprise企业套件触及B端开发者与中大型客户,中期作为端侧AI的中枢,成为驱动特斯拉FSD系统、Optimus 人形机器人以及 Starlink 星链网络智能调度的“中枢神经”。
更长期则将Grok模型作为底层智力基础,用于攻克复杂前沿科学难题、支撑深空探索及火星殖民的宏大愿景,也是马斯克为 Grok 设定的“终极使命”。
虽然远期梦想很宏伟,Grok大模型在马斯克的AI生态中扮演着最核心的软件智能引擎角色,但其实际表现相比头部的Anthropic和OpenAI,在综合指标上仍落后约一个身位,仍是一个“追赶者”的角色。
自 2023 年 7 月 xAI 成立至今,Grok 在不到三年时间里完成了从 Grok‑1 到 Grok‑4.3 的快速迭代,其迭代速度(4-5 个月一个主要版本)在业界已经算相对较快。然而,模型的快速迭代并不等于领先:

基础智力显著落后:Grok 4.3 智力得分(38分)与第一梯队(Claude Fable 5、GPT-5.5)差距悬殊,且已被“高性价比”著称的 GLM-5.2、DeepSeek V4 Pro 等竞品反超,显露出基础能力迭代的停滞。
代码与 Agent 存在短板,制约企业级变现:尽管在个别垂直领域(如电信 τ²‑Bench)表现优异,但整体编码指数(42.2)和agent指数(24.1)大幅落后于头部竞品(均在 74 分和 45 分以上),在自主规划和执行复杂任务上显得乏力。
这削弱了其在企业级AI高净值应用场景(自动化流程、智能客服、代码开发助手)的落地能力,显著落后于 OpenAI 和 Anthropic 的商业化步伐。
核心优势:极速响应与高性价比
凭借极低的推理延迟(首字仅 13.7 毫秒,端到端速度远超 GPT-5.5的82秒)和适中的 API 定价($1.25-$3/百万 tokens),Grok 在实时交互场景中依然具备极强的“性价比”竞争力。
因此现阶段来看,Grok 的定位并非纯粹冲击 AGI 极限的科研标杆,而是一个更务实的“工程型模型”。凭借极高的响应速度与高性价比,Grok在 C 端交互与轻量级 B 端场景(如基础问答、简单摘要)中表现流畅;但在复杂代码工程、多模态生成及企业级端到端自动化等深度方面,与头部全能型竞品仍存在可量化的能力断层。
但对于模型厂商而言,To B 市场价值极大且壁垒更高:B 端不仅客单价高、Token 消耗量大,且模型一旦嵌入企业核心工作流,迁移成本极高。相比价格敏感的 C 端,企业绝不会仅因“便宜或响应快”就轻易更换底座。
Grok 能力与 B 端刚需错配:B 端的核心诉求是“低幻觉、高精度、高可审计”。Grok 在基础智力和代码能力上的短板,直接制约了其在自动化开发等核心高价值场景的落地。
而顶尖模型带来的人力替代与提效收益,远超模型采购的差价。因此,B 端客户始终更愿意为“极致的聪明”支付溢价。
那问题来了,为什么AI业务充沛的算力资源(1GW+GPU集群)和数据优势(X平台)并未转化成模型的领先性呢?海豚君认为可能是在底层算法,数据结构以及组织文化上的缺失:
a. “纯堆算力”遭遇瓶颈,强化学习(RL)陷入低效:
Grok 在复杂代码任务上的短板表明算力已遇天花板。其将半数算力投入 RL,但由于代码质量主观、缺乏自动评分机制,导致模糊的奖励信号让算力在“盲人摸象”中低效空转,效率远逊于监督微调(SFT)。
而算力换不来高质量监督信号。xAI 若要突破智力上限,必须在算法上进行升级:
SFT+RL 混合训练:先以人类专家数据(SFT)打底,大幅降低 RL 盲目试错的成本。
量化指标 + RLHF 指引:将主观的代码评价转化为内存、耗时、编译率等“硬指标”,并结合人类反馈(RLHF),为模型进化提供清晰且精准的奖励信号。
b. X 平台数据先天“偏科”,缺乏 B 端专业语料:
X平台推文与对话数据在 C 端热点追踪上是降维打击,但极度缺乏高质量代码、复杂推理及结构化知识(如 StackOverflow、arXiv 等),对 B 端核心能力的训练增益十分有限。
而高质量 AI 编码依赖“生成→运行→反馈→修正”的闭环。相比竞品(如 Anthropic)通过自有开发工具沉淀高频交互数据并形成能力进化的“飞轮效应”,Grok 在编程工具端布局较晚,导致其缺乏真实编程反馈数据的持续反哺。
c. 组织文化:工程文化主导
Grok 的智力掉队可能并非单纯的研发瓶颈,也与组织动荡高度相关。自 2026 年 2 月起,xAI 半数创始成员及核心训练专家相继离职,客观上打断了前沿模型的迭代节奏。
同时,随着 Starlink 工程背景的高管接掌 AI 部门,SpaceX 强势的“工程文化”正深度主导 xAI 的研发走向——这虽然大幅提升了模型的落地效率与性价比,但也可能在一定程度上削弱了前沿 AGI 研究所需的探索性与自由度。
而前沿大模型的训练需要极其庞大的人力与算力投入,这让全球相关企业共同陷入了“规模不经济”的困境:一代模型投入数亿美元,创收窗口可能仅有一年,而下一代成本往往又要翻倍。以 SpaceX AI 业务为例:
运营利润严重承压:2025 年,AI 分部总收入仅约 32 亿美元,单项研发开支便高达 51 亿美元(为收入的 1.6 倍)。高昂的研发与各项费用叠加,直接导致全年运营亏损近 64 亿美元,亏损率约 -200%。
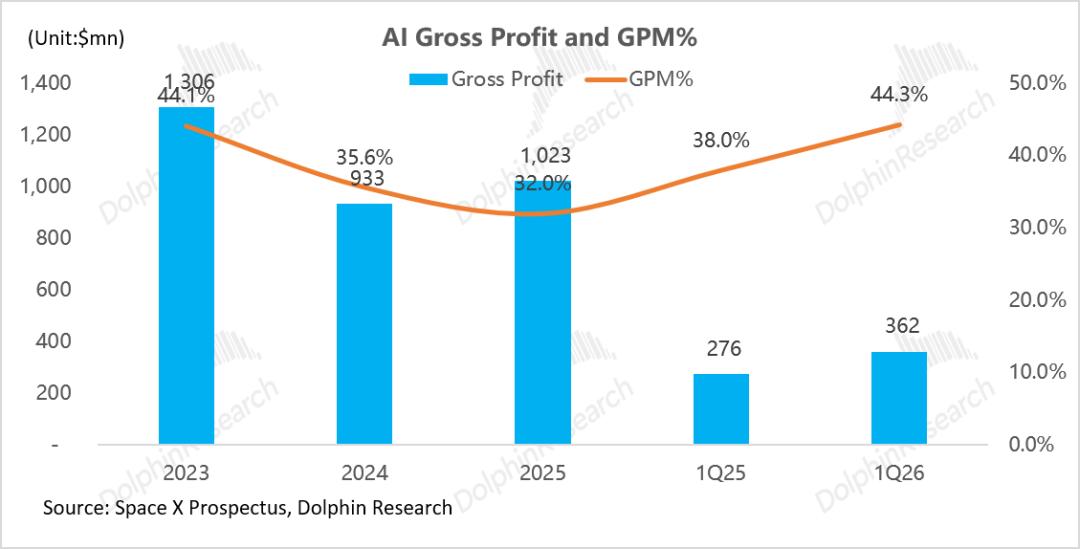
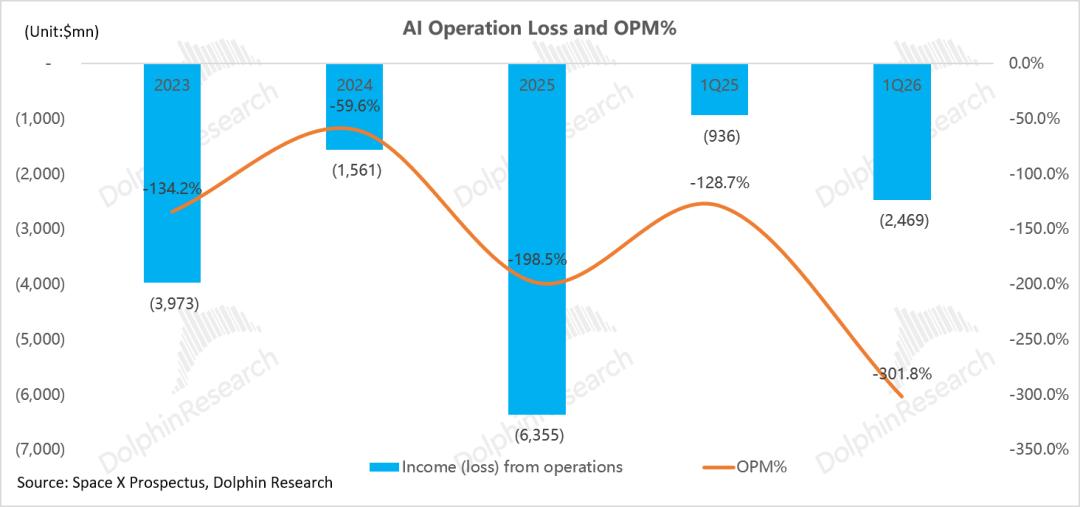
算力投入带来的现金流重压:2025 年,AI 分部资本开支高达 127.3 亿美元(占 SpaceX 总资本开支的 61.4%),是当期收入的近 4 倍。
同时,折旧与摊销费用达 36亿美元——这意味着目前AI业务的收入(仅32亿)甚至不足以覆盖当期的折旧成本。AI 业务在 2025 年完全依赖 SpaceX 其他板块(主要为 Starlink 贡献的 44 亿美元利润)及外部融资输血。
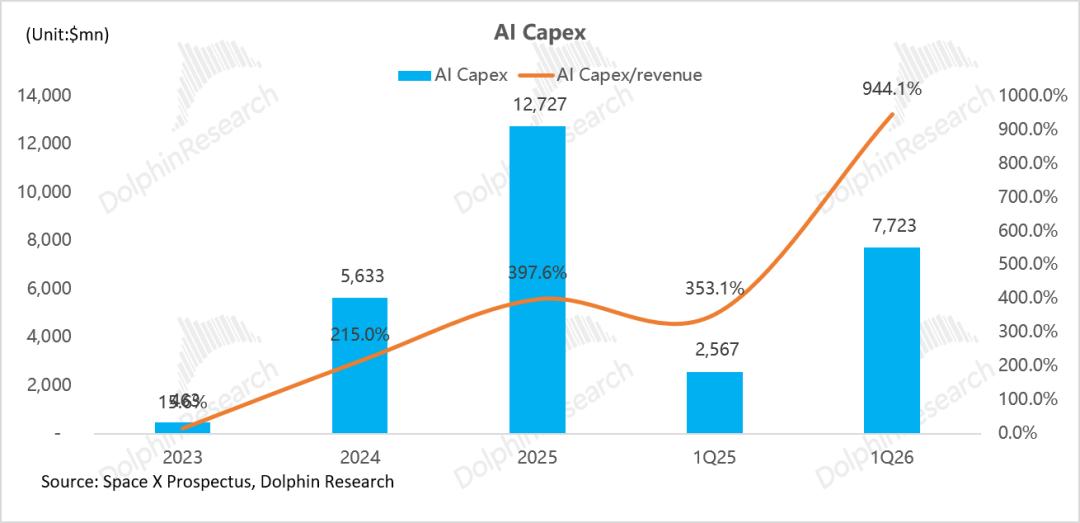
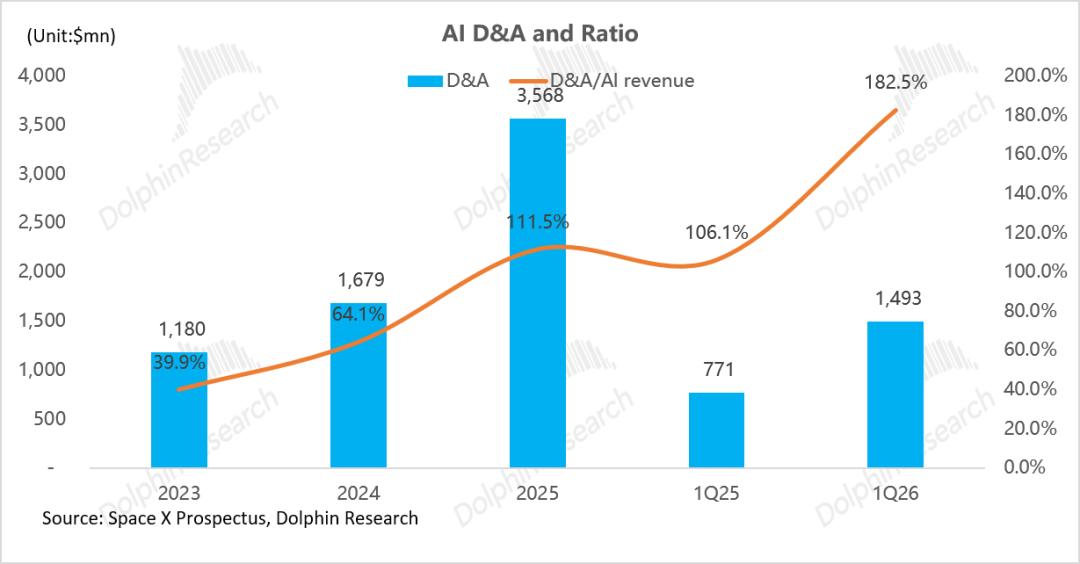
财务承压的根源,在于 Grok 的变现进度尚未跟上投入规模:
C端体量悬殊,且纯 AI 付费占比低:截至 2026 年 3 月底,Grok 生态合计付费用户为 630 万。但这其中约 440 万实为 X 平台的社交订阅会员(Grok 仅为增值服务),真正为独立 AI 功能(SuperGrok)付费的用户仅约 190 万,贡献的年化收入(ARR)仅约 10 亿美元。
作为对比,同样以C端起家的OpenAI 的付费用户数已超 5000 万,ARR 突破 250 亿美元,差距悬殊。

B端生态起步较晚:Grok 的 B 端 API 业务(Enterprise 层)直到 2025 年底才上线,目前远不及 OpenAI 和 Anthropic 已经高度成熟的企业级生态。
面对“巨额投入”与“变现滞后”之间巨大的剪刀差,xAI 并没有被动等待模型商业化改善,而是主动出击,将战略重心从单一的模型研发,全面转向“模型变现 + 算力租赁”的双轮驱动模式:
四、算力租赁业务:一场意料之外的“现金流盛宴”能持续多久?
xAI的算力租赁业务并非计划中的主业,而是源于一个技术困境和Grok模型掉队后的“意外收获”:
xAI 的核心算力资产是部署于孟菲斯的 Colossus 超级计算集群。截至 2026 年第一季度,该集群的纯算力功耗(仅统计 GPU 与机柜系统功耗,不含冷却、配电等配套设施)已达到 1.0 GW,是全球规模最大的单一 AI 训练数据中心集群之一,由 Colossus 1 与 Colossus 2 两个子集群组成:
Colossus 1 :为异构集群,部署了约 15 万颗 H100、5 万颗 H200、2 万颗 GB200,总计超过 22 万颗 GPU。其总算力功耗约 300 MW(纯 GPU 芯片 TDP 之和约 164 MW,叠加服务器平台、网络互联及机柜内配套组件后达到300MW)。
Colossus 1 早期用于 Grok 模型的训练,但由于混合了三代制程各异的芯片,在分布式训练中面临严重的“木桶效应”,导致 GPU 实际利用率(MFU)仅为 11%,远低于行业顶尖水平(40% 以上),完全无法支撑 Grok 5 这类 6T 参数级超大模型的训练需求。
面对这一困境,xAI 已将核心训练任务整体迁移至同构的 Colossus 2 集群,并将 Colossus 1 的完整容量以及 Colossus 2 的部分容量一并租赁给 Anthropic,据推测主要用于推理类负载。
一方面,推理任务对芯片间实时同步的要求远低于训练,恰好能适配异构集群的短板;另一方面,这也是 Grok 模型进展掉队、自身推理需求不足后的现实选择。
Colossus 2 :是高度同构的算力集群,分阶段建设:首期部署约 11 万颗 GB200(约 210 MW,以远快于行业基准的周期建成),二期部署约 11 万颗 GB300(约 220 MW),并正在规划扩建更大规模的算力容量。截至 2026 年 Q1,Colossus 2 的总算力功耗约 700 MW。
Colossus 2 的长期规划目标将部署超过 55 万颗 GB200/GB300 芯片,当前,Colossus 2 主要承担 Grok 5(xAI 下一代大模型,预计6-7月发布)及后续前沿模型的训练任务。

而从Colossus集群的客户来看,SpaceX的算力租赁不走传统云厂商的“海量中小客户”路线,而是专注于“少数超大型客户”的超大规模单租户模式:
① Anthropic(年化150亿美元):2026年5月签约,总额约450亿美元,租用Colossus 1的约300MW算力(推测用于推理),合同至2029年5月。这构成了xAI收入的最核心支柱。
② Google(年化110亿美元):2026年6月签约,总额约304亿美元,获得约11万张GPU的访问权(预计为GB200/GB300),用于支撑其AI服务。
③ Reflection AI (年化18亿美元):2026年6月签约,合同总额63亿美元,获得Colossus 2 的GB300芯片的使用权。
而仅三项合同,就为Space X的AI业务贡献了278亿的ARR,作为对比,2025 年 SpaceX 整个 AI 业务的总收入仅为 32 亿美元(其中 X 平台广告收入约占 60%,真正的 AI 解决方案与基础设施收入仅约 13 亿美元)。这意味着,AI 算力租赁业务仅凭三个大客户,就使 AI 板块的规模一举跃升至 Space X 2026 年增速最快、收入占比最高的核心业务板块。

虽然 xAI 尚未详细披露算力租赁的定价细节,但海豚君以 XAI与Anthropic 和Google的合同为例进行推演,发现其定价存在显著的反常识溢价:
a. GW级年化收入远超行业均值
若xAI与Anthropic合同推演:按年化收入150亿美元、租用约330MW算力进行拆解——首先需厘清功率口径:该330MW为纯IT负载(服务器及机柜系统净功耗,不含冷却与配电损耗)。考虑到Colossus 1以H100/H200等风冷芯片为主,典型PUE在1.3-1.5之间,对应的数据中心总设施功率约为430-495MW。
这意味着,实际每GW总设施功率对应的年化收入约为300-350亿美元。需注意的是,该合同同时涉及租赁Colossus 2的部分算力,因此上述假设推算的口径可能偏高。
交叉验证:xAI与Google合同:
Google合同明确租用11万颗英伟达GPU(GB200或GB300),我们假设以GB300芯片为主。按单芯片1,400W功耗计算,11万块GB300芯片对应的IT负载约220MW。考虑到GB300采用L2L液冷架构,PUE取值1.1-1.2,总设施功率约242-264MW,对应每GW年化收入约416-455亿美元。
作为对比,据行业调研,头部新云(Neocloud,以裸金属租赁为主)的价格约100亿美元/GW,而提供丰富软硬件生态的综合云厂商(CSP)价格约150亿美元/GW。
因此无论按哪种口径,xAI算力租赁的定价都远高于行业均值。

海豚君认为,鉴于 Anthropic 和 Google 均拥有极强的自研软件栈,xAI 提供的服务本质上是纯粹的 Bare Metal(裸金属)底层算力,并不包含高附加值的软件生态。
同时,Colossus 1 主要由 H100/H200 等上一代芯片构成。纯粹的裸金属 + 上一代硬件,从常理而言绝不应享有如此高的溢价。海豚君推测主要源于以下三大溢价原因:
① 极少数可用的超大规模推理集群
Colossus 是全球少数已投运的 GW 级 AI 算力集群。前沿大模型的推理对低延迟与高吞吐要求极高,跨地域的中小集群极易导致网络瓶颈;
而 Colossus 1 凭借单一园区内的超级网络拓扑(InfiniBand/Spectrum-X),成功化解了百兆瓦供电与数万节点的网络风暴,成为市场上极为稀缺的优质资产。
② 时间溢价:即用算力 vs. 远期期货
在 AI 应用抢位战中,算力交付速度就是生命线:
抢占市场先机:传统云服务商签约后需 12-24 个月建厂,而 Colossus 1 是现成资产,签约即投产。客户支付溢价,买的是提前 6-12 个月入场的门票。例如,Anthropic 签约后,立刻将 Claude Code 的使用限额翻倍,并全面放宽了高峰限流与 Claude Opus 模型的API 调用速率限制。
供给确定性:xAI 拥有颠覆行业的建厂速度(Colossus 1 仅用 122 天,Colossus 2 首期仅 91 天上线,远快于行业 1-2 年的基准)。这种“说到做到”的速度,为客户后续的扩容需求提供了极具价值的“确定性溢价”——这在算力极度供不应求的市场中极具价值。
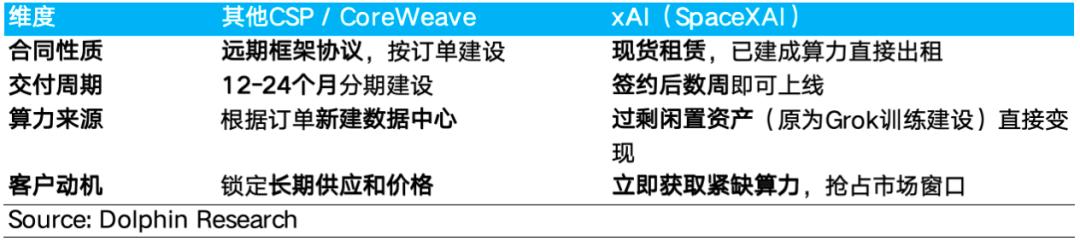
③ 风险转嫁溢价:90天终止条款背后的代价
行业典型的长期锁定式合同(如3-5年不可撤销、附带巨额预付款)将硬件折旧与技术淘汰的尾部风险完全压在客户一方。而Anthropic/Google与xAI签订的合同都包含任一方可提前90天终止的条款,这意味着客户将“GPU代际迭代后资产贬值”的风险完全转嫁给了xAI。
作为补偿,xAI必须以显著高于市场的单价来覆盖这一风险敞口:若合同仅持续3个月而非3年,xAI需要在这短时间内即收回大部分投资。因此,高单价在某种意义上也是“保险溢价”——客户支付更高的价格,换来的是灵活退出的权利与免除尾部风险的安心。
从成本端来看,虽然SpaceX尚未直接披露1GW数据中心的详细成本拆解,但我们可以从累计资本开支侧面验证其成本控制能力:AI业务从2023年至2026年Q1累计投入的资本开支约为265-300亿美元,对应已部署的约1GW混合算力(包含约0.3GW H100/H200和约0.7GW GB200/GB300)。
与此对照,若按行业最新架构(如Vera Rubin或GB300)新建1GW AI数据中心,其总投资(含IT设备)约400-600亿美元。即使考虑架构代差,xAI的算力资本开支仍显著低于行业同等规模的最新部署水平,体现了其在芯片采购、基础设施复用及规模化部署方面的显著成本优势:
a. 基础设施“壳成本”仅为行业的三分之一: 据 Oppenheimer,xAI 的数据中心建设成本仅为 300万美元/MW(折合约 30亿美元/GW),远低于行业平均的 1,000 万美元以上/MW(折合约 100 亿美元以上/GW)。
这一巨大优势主要源于其独特的建设策略:棕地改造(利用现有工厂/建筑改造,避开新建审批与电网接入长周期)、Megapack 储能方案替代柴油发电机、自建供电/冷却/网络全链路的垂直整合以及模块化标准建设。
b. GPU 芯片采购成本可能低于行业:SpaceX 与英伟达的密切关系确保其能够优先获得 GPU 供应,并可能获得折扣。SpaceX 是全球少数能够下达数十亿美元订单并快速部署的公司,这使其成为英伟达的优先客户。
尽管折扣幅度并未披露,但凭借其巨大的采购体量和快速交付能力,xAI 在芯片端的单位成本大概率低于其余CSP等竞争对手。
短期来看,这确实是一门非常暴利的生意——以低于行业的总投入完成算力部署,同时凭借稀缺资产与风险条款优势,实现了 3-4 倍于行业平均的定价能力,锁定了远超同行的利润空间。
但这份暴利的可持续性面临制约:① 90 天终止条款使超级合同可能随时消失;② 2027/2028 年后算力供需趋于平衡后将压缩定价溢价。因此,这更多是稀缺窗口期的“极短暴利”,而非可线性外推的永续生意。
五、太空数据中心:从地面演练跨入“天基算力霸权”,究竟是星际科幻还是降维打击?
从算力产能的宏观规划来看,SpaceX 的布局呈现出极具野心的双轨战略:短期以地面数据中心为基石,长期则建立颠覆行业的“太空数据中心”:
短期:以 Colossus II 为核心的地面基石
作为全球首个 GW 级 AI 超算,Colossus II 已于 2026 年 1 月投运。计划年内扩容至 1.5 GW,并于 2026 年底至 2027 年冲击 2 GW 目标(约包含 55.5 万张 GPU)。
而运营庞大的地面集群不仅是为了租赁创收,更是通往太空的“必修课”。SpaceX 借此跑通了超大供电、极限散热与数万节点网络拓扑的全链条工程体系,践行马斯克的“在地球驾驭 GW 级集群,才能在太空复制”的核心逻辑。
长期:摆脱地球电网的太空算力中心
面对地面电力资源紧缺与土地审批的物理束缚,马斯克将太空视为未来4年内实现算力极速扩张的最佳解法。
SpaceX已公布激进的部署时间线:
首代轨道AI卫星——“AI1”,展开翼展70米,平均功耗120kW,峰值150kW——预计于2028年启动规模化商业组网。
2028-2030年:得益于Starship超高频次重载发射(当前V3版本单发100吨入轨,V4目标200吨,远期目标年产1万艘、年发射1万次),以及Texas Terafab芯片工厂(采用2nm制程,远期目标年产1TW算力,约80%产能用于太空领域),SpaceX目标实现每年向轨道运送约100万吨算力硬件,按每吨100kW计算,对应年新增100 GW的太空算力部署能力(预计在4-5年后,即2030-2031年实现),其远期终极规划更达1 TW(1,000 GW)。
作为对比,当前全球主要云服务商(CSP)部署的AI总算力存量约为数十GW量级(约30-50GW)。这意味着,SpaceX仅太空算力的年增量(100GW),就相当于在全球现有AI智算存量的基础上每年再造一个“全球云计算”——彻底打破地面能源与土地的增长天花板。
从被迫外租算力回血,到试图用数十万颗卫星重塑全球算力版图,SpaceX 正在进行一场史上最昂贵的豪赌。
那太空数据中心在技术和经济性上是否真的可行呢?到底如何对Space X这一个巨无霸估值?海豚君将继续在下篇报告中继续探讨,尽情期待!
