

打开Hugging Face上LongCat-2.0的页面,标题下面是logo和MIT License标签,Model Introduction里堆满了1.6万亿参数、480亿激活、五万卡国产ASIC集群的硬数据。但滑到最底部,一个蓝色Note框里写着:Model weights coming soon — stay tuned!
浓密大眼的美团,还搞上预售制了,现房与期房说是。
不过讲真,美团这次确实干了一件硬事——五万卡国产专用AI加速芯片,区别于NVIDIA的通用GPU,是面向大模型训练定制的专用计算芯片。不靠NVIDIA的NCCL(NVIDIA芯片之间的对讲机协议),采用国产集群自带的分布式通信协议做分布式训练,把1.6T参数的MoE模型从头训到尾。
1.6T的总参数量,平均激活约480亿,原生支持100万token超长上下文。搭配稀疏注意力、多专家动态融合等一系列优化方案,据官方表述,这是国产算力生态中首次完成如此规模的端到端训练验证。
看下评分,SWE-bench Pro拿到59.5分,略高于GPT-5.5的58.6分。国产算力生态喊了三年模芯协同,美团交出了第一份能跑通的AI期中作业。
但三个最能证明国产竞争力的数字,官方全部保密。芯片厂商是谁?训练总成本多少?wall-clock(实际训练耗时)多久?wall-clock就是实际训练耗时,现在确实都看不到。
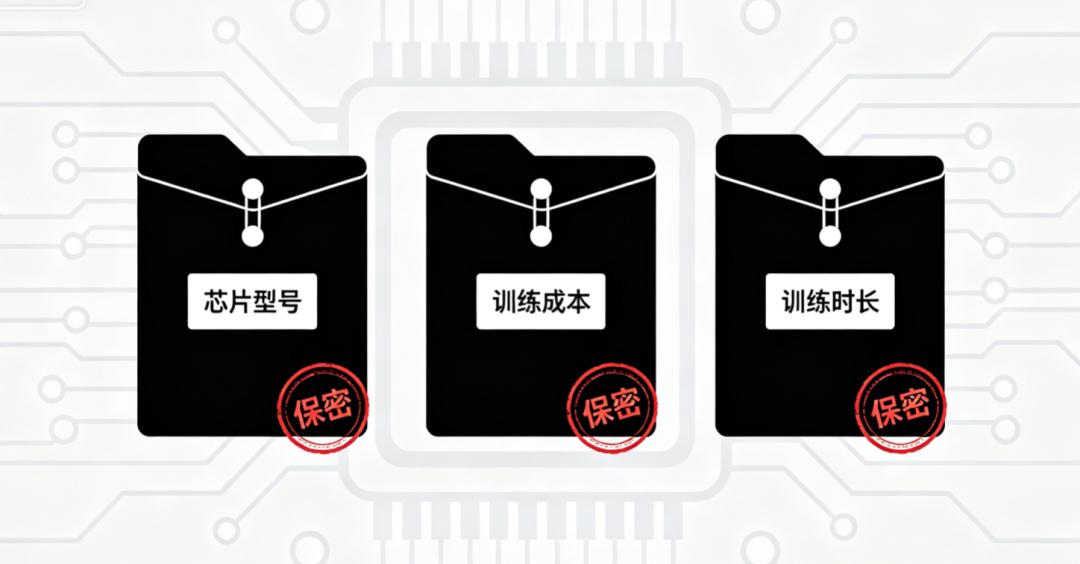
这三个数字藏着,全国产的真实成色、算力经济性、和NVIDIA的效率差距就都没法验证。行业也没法对标,没法复用。
有点像咱去买房,问能不能看看样板间咋装修的,人家说:样板间只能看照片。这个比喻不完全精准,毕竟模型都可以跑通了,但问题是,我还准备按照训练过程跑通全国产跑通美团,结果美团自己也没给机会。
权重即将推出,数据只字不提
美团说LongCat是MIT许可证开源,听起来敞亮。但点进Hugging Face,权重状态写着coming soon,即将推出,等于现在是个“待开源”状态。截至目前,官方只放出了推理框架和Infra代码;模型权重开不开、何时开、以什么协议开,全都待定。Infra框架和推理引擎放出来了,但那35T以上tokens的训练数据,一个字没提。
开源权重不开源数据,等于美团只给了成品,不给配方。开发者能调用模型,但没法复现训练过程,这就相当于是“伪开源”了。行业内对大模型开源的默认共识,是至少开放权重、代码、训练数据配比与流程,保证第三方可以复现微调、甚至二次预训练。目前LongCat仅开放了推理侧框架,权重待上线、训练侧信息空白,更接近免费商用的闭源模型。
就比如咱拿DeepSeek V4比一下,权重、代码、训练数据配比全公开,社区可复现性更强。但V4并未像LongCat这样强调"五万卡国产算力从零训练"的工程验证。LongCat反过来,训练全栈国产,但权重和数据捂着。一个赌全栈国产,一个赌全量开源,目前看谁都没走完。

美团捂着数据不难理解。LongCat的训练数据里大概率混了大量业务数据,外卖订单、商家信息、用户评价、地理位置。这些是核心资产,不可能公开。但不公开数据构成与清洗规则,行业就无法验证测试集是否存在泄露风险,59.5分的含金量,目前只能靠企业自己担保。
调用量全球前三:靠低价和免费额度
LongCat在OpenRouter上以Owl Alpha的匿名身份跑了几个月,OpenRouter是第三方模型调用平台,相当于模型的比价网站。
月调用量挤进全球前三。怎么来的?API定价0.30美元每百万token,远低于GPT-5.5的2.50美元,而且大量调用免费。
OpenRouter的排行榜本身就是新模型冲知名度的常规赛道。行业通用玩法就是上线初期靠低价、免费额度冲榜,攒口碑再涨价。说白了,几乎没有哪个新模型的榜单成绩是纯靠付费用户打出来的。一旦收费,这个前三还能保持多久,才是真正的考题。
性能上,LongCat对标的是Claude Opus 4.6,但Anthropic已经迭代到4.8,时间窗口就几个月。功能上,它是垂直模型,专为本地生活、Agentic Coding优化,通用问答和多模态能力明显弱于同期竞品。
全网刷屏的通稿里,几乎都在刻意弱化本地生活垂直的定位,把LongCat包装成对标GPT的通用大模型突破。但本质上,它从训练目标到数据底座,都是为美团自家的商家智能助手、外卖调度、到店运营服务的。这个定位本身没问题,但放在国产算力突破的宏大叙事里,就容易被误读为通用大模型的胜利。
7月国产模型正在扎堆发布。Kimi K3,2.5万亿参数,通用多模态路线,对标OpenAI和Anthropic。百度文心5.0,2.4万亿参数,原生全模态。DeepSeek V4,万亿级参数,开源加极低API成本,主打模型水电煤。美团LongCat,1.6万亿参数,本地生活垂直。参数一个比一个高,但路线彻底分化。资本市场逼着大家比参数,但企业真实需求是能把客服成本砍一半的轻量化方案。
你给一个奶茶店老板推1.6万亿参数的大模型,他只会问你能帮我自动回复差评吗。能,但用一个小模型也能做到,没必要上万亿参数。
按行业通用估算,五万卡集群三年折旧加电力加运维,总成本接近百亿级别。美团有外卖、到店、本地生活的现金流,可以摊平。纯AI创业公司没有这个缓冲池,根本学不了。阿里通义、京东言犀走通用模型微调加业务落地,轻、快、成本低。美团走全栈自研加从零训练,重、慢、壁垒高。两条路线没有对错,但中小厂根本学不了美团。
LongCat的工程价值不可否认,但这条路很难复制。国产算力迈出了关键一步,这一步证明路能走,但能不能走得远,还得看钥匙什么时候交。
掌声可以先等一等
国产AI不缺突破、超车、第一的通稿。缺的是敢晒真实成本、敢公开核心供应链、敢让所有人复现的坦诚。
对行业而言,真正的交付至少包含三点:芯片与集群配置可核验、权重可下载、训练数据构成与清洗规则可追溯。在此之前,它更像一次工程演示,而非公共基础设施。
一家的里程碑,铺不成全行业的高速公路。楼盖得再高,钥匙不交、账单不晒、路径不说,就永远只是别人的楼。在权重可下、成本可核、数据可溯之前,这一次的掌声,不妨先缓一缓。
