

潜在世界模型(Latent world models),能让机器人在行动前先推演未来,再据此规划动作。2022年,图灵奖得主杨立昆团队提出了联合嵌入预测架构(JEPA),通过在潜空间中预测未来状态演化,推动表征空间预测成为世界模型研究中的重要范式。
问题在于,多数世界模型在训练完成后参数便不再更新,难以及时适应真实场景中变化的视觉条件和物理属性。一旦编码器或预测器失准,误差就会在后续规划中逐步放大,最终导致任务失败。
但我们人类则不同,感觉运动自适应机制是我们适应环境变化的核心能力。我们会根据感官反馈校准动作预测,也会根据新经验不断调整对环境的理解。
受到了这一生物学原理的启发,杨立昆团队提出了能在部署过程中持续学习的自适应潜在世界模型 AdaJEPA,将自适应嵌入模型预测控制(MPC)的闭环中:每执行一个动作,就用实际观测的状态转移校正模型,再用更新后的模型重新规划。

论文链接:https://arxiv.org/abs/2606.32026
结果显示,AdaJEPA 在分布内任务和多种分布偏移下都能稳定提高规划成功率,即使每次重新规划前只做一次轻量更新,也普遍优于训练后参数不再更新的世界模型。
这项工作为自适应世界模型开启了一个有前景的方向:世界模型应在行动过程中持续根据真实反馈校准预测、更新表征,从而更好地适应变化的环境。
AdaJEPA:一个懂“自适应”的世界模型
AdaJEPA 是一种自适应潜在世界模型,能够在机器人执行任务过程中持续修正预测。每完成一步动作,模型都会利用新的真实观测校正偏差,并据此重新规划。整个过程不需要额外离线数据、奖励标签或专家示范。整个流程可概括为四步:规划、执行、校正和重新规划。具体如下:
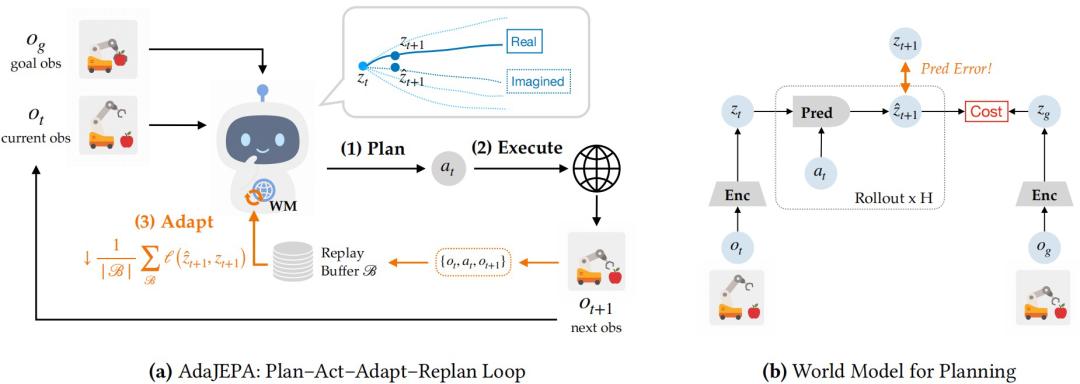
图|AdaJEPA 在闭环 MPC 中执行测试时自适应。
- 规划:模型在内部推演接下来几步的状态变化,比较多组候选方案,选出最有可能靠近目标的动作序列。
- 执行:规划完成后,模型只执行第一个动作或一小段动作,然后观测环境的真实反馈。执行前的状态变化会被记录下来,作为后续自适应的学习样本。
- 自适应:动作执行后,AdaJEPA 将这一步产生的状态转移写入在线缓冲区,并用它检验模型预测是否准确。如果预测的下一状态与真实结果存在偏差,模型就把这部分误差作为更新信号,进行一次轻量校正,为下一轮规划做准备。
- 重新规划:完成自适应后,模型会从最新观测出发,用更新后的世界模型重新预测后续轨迹,并生成新的动作序列。整个任务过程中,“规划-执行-自适应-重新规划”的循环会不断重复,使每一轮规划都建立在最新观测和最新模型之上。
此外,为避免拖慢实时规划,AdaJEPA 只做轻量更新:调整少量参数,维护小型在线缓冲区,并沿用预训练阶段的目标函数。具体如下:
- 只更新关键层:AdaJEPA 不更新整个世界模型,而是仅调整编码器和预测器中的少量关键层,这样做既能降低计算开销,也能减少对已有表征的扰动。
- 维护小型在线缓冲区:缓冲区默认保存最近 5 条真实状态转移。研究团队比较了两种保留方式:recent-N 保留最近转移,hard-N 保留预测误差最大的转移。结果显示,两种方式差异不大,但 recent-N 更稳定。
- 沿用预训练阶段的目标函数:自适应阶段保持与预训练相同的预测目标,用真实观测对应的表征作为监督信号。为减少对已有表征的扰动,目标表征仅作为参照,不参与梯度回传。
效果如何?
整体来看,AdaJEPA 在分布内任务和多种分布偏移下都能稳定提高规划成功率。研究团队在推物体任务 PushT / PushObj 和迷宫导航任务 PointMaze 上评估模型,覆盖形状、视觉、动力学和布局等变化场景。即使每次重新规划前只做一次轻量更新,AdaJEPA 仍普遍优于训练后参数不再更新的世界模型。具体结果如下:
1. 分布内任务
结果表明,AdaJEPA 在测试时自适应不会牺牲原有能力,还能进一步提升任务成功率。无论是用 GD 直接优化动作序列,还是用 CEM 通过采样和筛选候选动作来搜索,AdaJEPA 的成功率都高于不进行测试时自适应的基线。提升最明显的是推物体任务,最高成功率提升超过 20%;在迷宫导航任务中,原模型本身已经表现较强,AdaJEPA 仍能保持相近水平,没有明显退化。
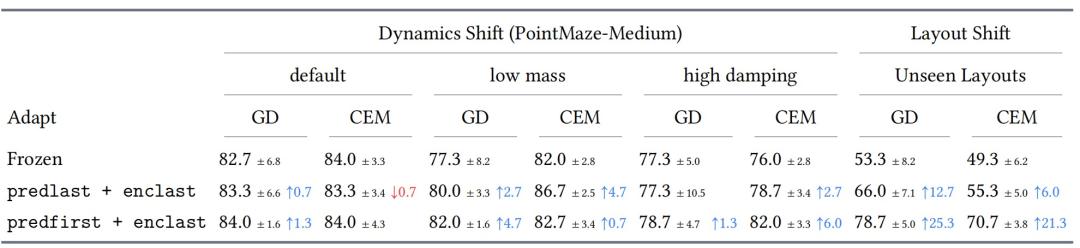
图|PointMaze 在动力学变化和布局变化条件下的规划成功率。
2. 分布外任务
在环境变化更明显的任务中,AdaJEPA 的优势更突出。它会在每轮规划和执行后,用新的真实反馈更新世界模型,让后续规划更贴近当前环境,提升任务成功率。相比之下,训练后不再更新的模型无法利用这些新观测,成功率往往很快到达上限。
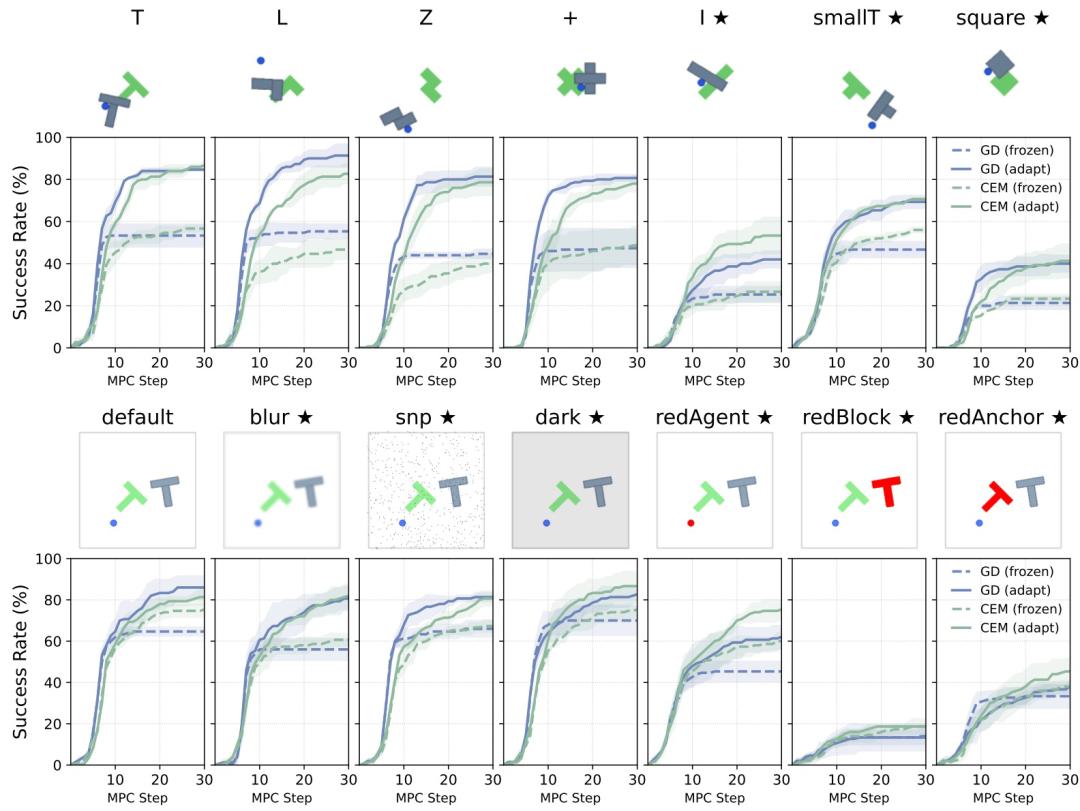
图|在形状变化和视觉变化条件下的规划成功率。
具体来看,在多形状推物体任务中,如果测试时出现训练阶段没见过的物体形状,AdaJEPA 的提升最明显,成功率接近翻倍;视觉扰动中,模糊、噪声和暗光照带来的增益更明显;如果只是锚点或物体颜色改变,AdaJEPA 的优势则相对有限。在 PointMaze 迷宫导航中,AdaJEPA还能适应动力学变化和新迷宫布局,并在新布局下规划出更接近最短路径的轨迹。
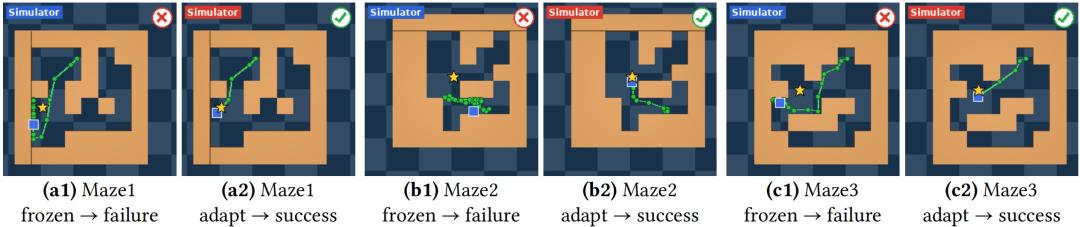
图|多样化迷宫中的规划轨迹。
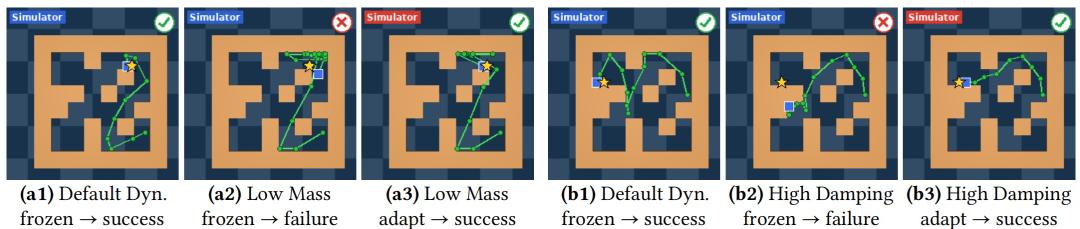
图|PointMaze-Medium 在动力学变化条件下的规划轨迹。
3.AdaJEPA 在多种 JEPA 实现上均有提升
为验证 AdaJEPA 是否依赖某一种特定模型实现,研究团队在 PushT 推物体任务上,分别更换表征形式、模型架构、训练目标和规划器进行测试。结果显示,AdaJEPA 在这些设置下都能提高规划成功率;即使基线模型已经充分训练、评估仍在分布内,测试时自适应依然带来稳定增益,每次重新规划只增加约 0.01–0.03 秒延迟。
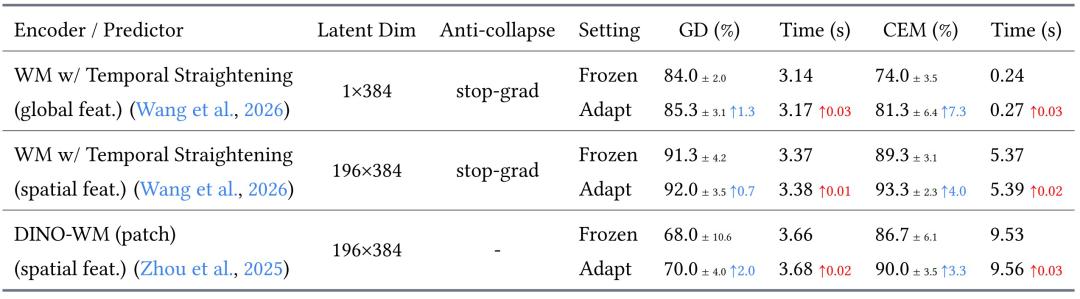
图|不同实现下的 AdaJEPA 表现。
4.AdaJEPA 不是从头学习新世界,而是在校正已有预测
可视化结果显示,AdaJEPA 的自适应更像是在校准,而不是重新学习。研究团队将自适应后的预测轨迹解码出来后发现,即使遇到视觉扰动或未见形状,解码结果仍倾向于保留训练分布中的结构特征。例如,红色方块会被解码成训练中常见的灰色方块,未见形状也会被解码成相近的已见形状。
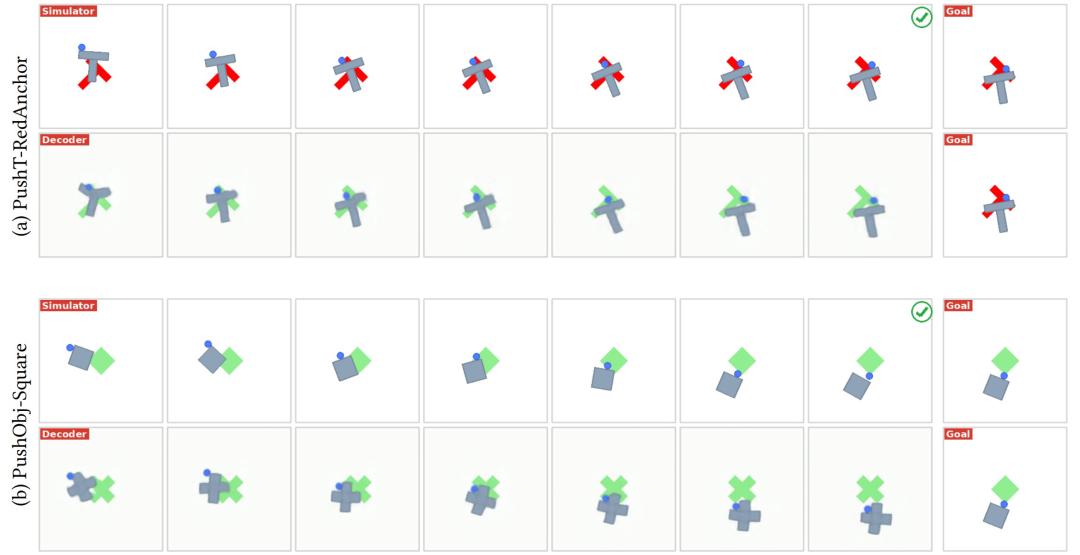
图|视觉变化和形状变化条件下的 AdaJEPA 规划轨迹示例。
5.消融实验与分析
消融实验结果显示,AdaJEPA 不需要大范围更新,也不依赖复杂调参;少量关键层更新、一步梯度更新和近期状态转移缓冲区,已经能带来稳定收益。
首先,AdaJEPA 只更新编码器或预测器的部分层,或者采用 LoRA 做轻量更新时,整体表现都优于不进行测试时自适应的基线,说明它不需要重训整个模型。
其次,不同分布偏移对更新位置的需求不同。形状变化下,各种更新方案差异不大,主要调整预测器即可;视觉和布局变化下,仅更新预测器效果有限,编码器也需要参与。布局变化中,更新预测器第一层效果最好,可能因为它最早融合潜在状态和动作信息,更容易校正新的局部转移关系。
此外,默认超参数已经足够稳定。在超参数设置上,AdaJEPA 默认沿用训练阶段学习率,每次重规划前只做一步梯度更新,并保留近期状态转移作为缓冲区。更大学习率或更多更新步数可能增强适应效果,但也会增加不稳定性和计算开销。总体来看,默认设置已经能在效果、稳定性和延迟之间取得较好平衡。
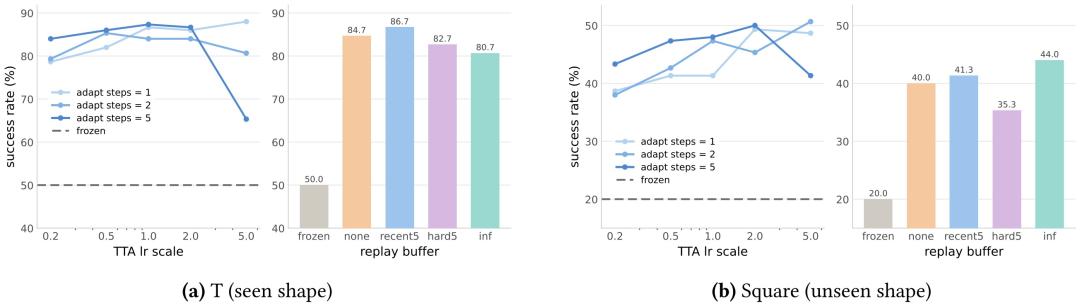
图|适应超参数和回放缓冲区对规划成功率的影响。
6.训练数据规模和形状多样性对 AdaJEPA 的影响
实验结果表明,AdaJEPA 的效果不仅取决于训练数据量,也取决于训练数据是否足够多样。对 PushObj 多形状推物体任务来说,形状多样性比单纯堆叠同一形状的轨迹更关键;同时,测试时自适应可以在数据不足时弥补部分泛化缺口。
具体来看,在总轨迹数相同的情况下,将数据分配到更多物体形状上,比集中在单一形状上更有利于泛化到未见形状。例如总轨迹数同为 16k 时,覆盖四种形状的 AdaJEPA 在未见形状上的成功率为 51.9%,高于只覆盖单一形状时的 45.8%。
此外,AdaJEPA 在不同数据规模下都能提升成功率,低数据场景下收益尤其明显。即使训练阶段只覆盖较少形状和轨迹,模型也能在部署过程中利用新观测校正预测。例如在已见形状上,只用 1 种形状、1k 条轨迹训练 AdaJEPA,成功率达到 60.8%,高于使用 4 种形状、总计 64k 条轨迹训练但测试时不更新的模型。
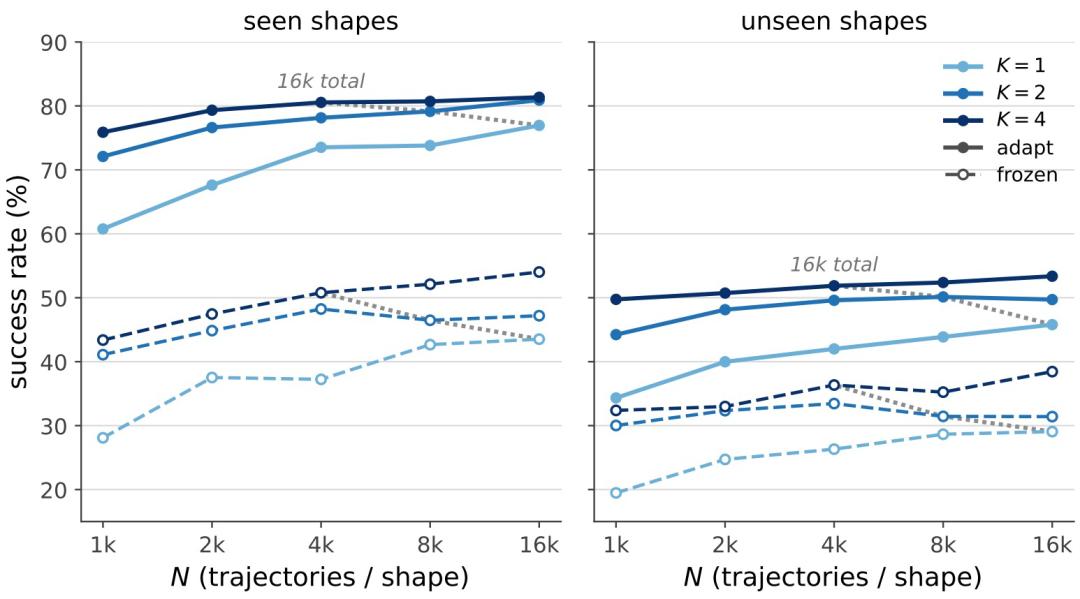
图|训练数据规模对 PushObj 规划成功率的影响:形状多样性 (K) 与每种形状的轨迹数量。
不足与未来方向
尽管 AdaJEPA 在多类规划任务中都带来了稳定增益,但仍存在以下不足:
由于 AdaJEPA 只在规划期间进行轻量级修正,其有效性仍受到预训练表征覆盖范围的限制。当测试环境中出现训练阶段未涵盖的关键特征时,自适应虽然可以在一定程度上改善规划结果,但仍难以完全弥合这一表征差距。未来,轻量级测试时自适应还需要与持续学习、主动学习结合,使世界模型能够在长期部署中不断积累新经验,逐步扩展对环境变化的覆盖范围。
更多技术细节,详见原论文。
