

AI 时代的数据洪流与算力瓶颈

从日常生活中的语音助手和自动驾驶,到工业上的全自动工厂和 AI 辅助设计,人工智能技术正在为我们的世界带来革命性的变化。在人工智能的应用中,无论是文字、语音、还是视频,都需要被转化为一串串的基本的数据单元,以供 AI 处理器识别并进行运算处理。这些单元被称之为 token。

现代的 AI 系统往往要面临同时产生的海量 token 输入,并且需要在一秒内完成十亿甚至百亿数量级的 token 处理。这种高并发、高带宽的需求对计算机架构和芯片的设计提出的新的挑战:在搭载于传统的二维芯片上,尤其是使用冯·诺伊曼结构的计算机中,处理器与内存之间的总线好比乡间双向二车道的小路,数据传输速率和带宽十分有限,已经远不能承载 AI 时代的数据洪流。数据显示,当前 AI 芯片的算力利用率通常低于 30%,其主要原因正是处理器与内存之间数据传输速率与带宽跟不上处理器的运算速度。这种被称为“内存墙”的现象已经成为了限制 AI 系统性能的瓶颈。
3D-IC——突破维度的技术革命
为了解决“内存墙”对 AI 系统的桎梏,当今主流的 AI 芯片大多采用了2.5D 的方式设计制造。2.5D 就是将存储和运算芯片摆放在同一平面上,借助平面下方的中介层传输芯片来实现千和万数量级的连接,初步解决了存储和运算之间数据通路拥塞的问题。此外,将传统的大芯片切分为更小的存储和运算芯片后,良品率也能得以大幅提升。但如果要满足更严苛的高并发、高带宽的需求,我们就需要升级到 3D 的设计,将存储芯片直接堆叠在运算芯片之上。

在 3D-IC 的工艺中,金属微凸块(micro bump)或复合键(hybrid bonding)可以将上下堆叠的两个芯片直接连接。如有信号需要穿过整层芯片,则可以通过硅通孔(TSV)穿过芯片的硅衬底、器件层、甚至金属层。3D-IC 结构下的芯片间垂直互连进一步缩短了数据传输距离,从而提高了数据传输速率,减小了传输功耗。由于芯片的整个接触面都可以摆放连接接口,芯片间并行连接的数量得以有极大的增加,带宽可由此得到若干个数量级的提高。以上将内存和运算放在一起的结构被称为近存运算,是当前打破“内存墙”的重要手段。

最先进的芯片设计者甚至会在面对不同运算需求时,平衡运算性能和设计制造成本,同时采用 2.5D 和 3D 的连接技术,即 3.5D 芯片。3.5D 的设计可以更好地支持异构运算以及处理海量数据。
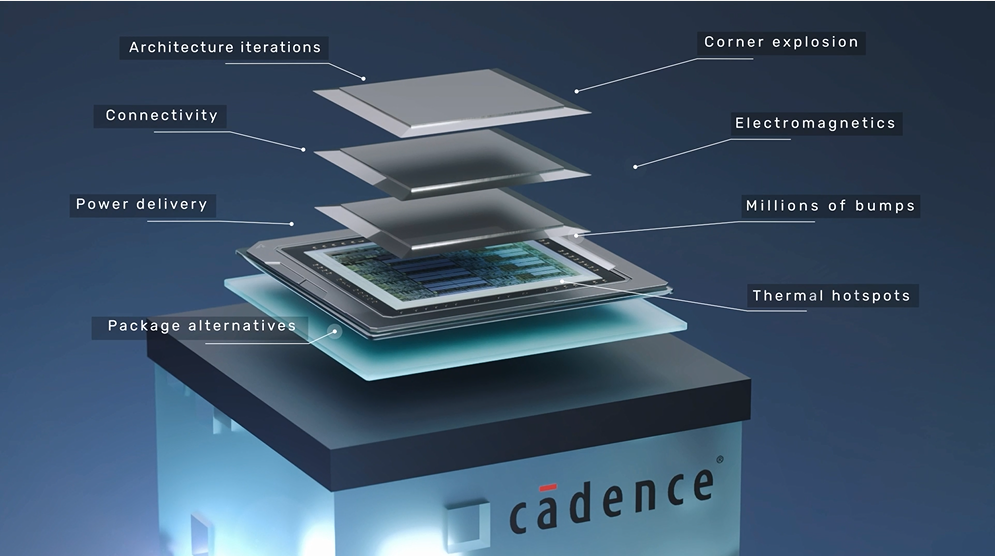
Cadence Integrity 3D-IC——全流程设计平台
3D-IC 的设计不同于传统的封装设计和芯片设计,需要创新的设计方法学和工具的支持。传统的先进封装流程会先由封装决定每个芯粒的接口,之后将设计目标拆分给芯片设计团队。然而这样的流程无法实现跨芯片、芯片与封装之间的系统级优化。3D-IC 的设计需要把传统 2D 芯片中的性能、功耗、面积、成本(PPAC)指标驱动的设计拓展到整个 3D 系统中。
Cadence 致力于提供软件、硬件和 IP 产品,助力电子设计概念称为现实。基于此,Cadence 率先推出了能在在单一平台上实现 3D-IC 全流程的 EDA 软件——Integrity 3D-IC,给业界提供了一套完整的 3D-IC 解决方案。该方案支持所有 3D-IC 设计类型和各种工艺节点,并让 3D-IC 设计的各个部门通过 Cadence 的数字设计平台 Innovus、模拟及定制化设计平台 Virtuoso 和封装与板级设计平台 Allegro 实现全系统跨平台的无缝协作。为了达到更好的 3D 系统的设计效果,Integrity 3D-IC 将 3D-IC 的设计流程拆分为:
早期架构探索 – 探索分析不同的 3D 堆叠架构,快速进行方案迭代。优化 bump 和 TSV 的规划与摆放。
中期设计实现 – 3D 系统的 partition 与floorplanning,3D placement、CTS、routing 及优化,跨芯片的静态时序分析与收敛。
后期多物理场签核 – 包括对 3D-IC 签核至关重要的系统级热分析、电源分配网络分析,3D 系统的信号完整性与电源完整性,3D 静态时序分析等多物理场的签核,系统级的 LVS 和 DRC。
从而使 3D-IC 芯片的堆叠、互联以及各芯粒都能根据全系统 PPAC 的最优或次优解完成规划与实现,让芯片公司设计出更有竞争力的 3D-IC 产品。
未来展望:3.5D 异构集成时代
在半导体产业迈向新征程的关键节点,Cadence 始终以创新者的姿态深耕行业前沿。面向未来,Cadence 满怀热忱与期待,愿与行业合作伙伴同心同行,共同推动下一代 3.5D 的技术创新。这不仅是技术参数上的迭代升级,更是对芯片设计方法学的深度重塑,力求为行业发展注入新动能。
Unleash your imagination,与 Cadence 携手,将创意变成现实!
