

在2024 年 10 月退出隐身模式的时候,以色列芯片初创公司NextSilicon 表示,期即将退出的Maverick-2 是世界上第一款智能计算加速器 (ICA:Intelligent Compute Accelerator),旨在满足高性能计算人工智能 (HPC-AI) 应用的需求,是一种“新颖且原创的计算架构”,可在降低功耗和成本的同时提高性能。
刚刚。经过八年时间、3.03 亿美元的种子资金和三轮风险投资的NextSilicon 终于推出了其 64 位数据流引擎的多个版本。与此同时,该公司还将推出一款名为 Arbel 的自主研发 RISC-V 处理器,该芯片或将与 Maverick-2 搭配使用,打造诸如英伟达“Superchip”类型的产品。

从左到右:NextSilicon Arbel RISC-V CPU、Maverick-1 DFP、Maverick-2 DFP 和用于 OAM 插座的双芯片 Maverick-2。
NextSilicon 成立于 2017 年,远早于 GenAI 热潮兴起之时,但当时人们已经意识到 HPC 和 AI 计算引擎架构即将分道扬镳——而且不利于专注于 64 位和 32 位浮点计算的 HPC 仿真和建模领域。即使没有像 Cerebras Systems、Graphcore、Groq、Habana Labs、Nervana Systems、SambaNova Systems 等公司那样直接进军 AI 市场的初步计划,NextSilicon 也已在三轮融资中筹集了 2.026 亿美元,其中 C 轮融资于 2021 年 6 月完成,融资金额为 1.2 亿美元。
当时,NextSilicon 的估值约为 15 亿美元,这笔资金和原型设计工作的完成意味着美国能源部可以了解 NextSilicon 的动向。彼时,桑迪亚国家实验室还和 NextSilicon 合作设计和测试了 Maverick-1 数据流引擎,目前桑迪亚正在构建一款名为“Spectra”的新型架构超级计算机,这是其 Vanguard-II 计划的一部分。据推测,这台超级计算机将使用今天发布的 Maverick-2 数据流引擎构建。
一条全新的道路
在英伟达已经牢牢把持市场的当下,为什么需要构建一个新的芯片?“这主要是因为没有专门用于高性能计算的加速器,”NextSilicon 创始人兼首席执行官 Elad Raz在去年接受媒体采访的时候如此说。他指出,我们有数百家公司在为人工智能和机器学习做加速,大多数大型供应商都在转向人工智能机器学习。你可以看到大型超级计算机对他们意味着什么——他们只需构建一个新的 GPU 集群,成但本是原来的两倍,功耗是原来的两倍,但得到的却是相同的 FP64 浮点运算能力。而NextSilicon 是一家以高性能计算 (HPC) 为先的公司。”
他们打算走上的是一条全新的道路。
众所周知,尽管 GPU 和 CPU 助力了高性能计算 (HPC) 和人工智能 (AI) 领域的重大科学和社会突破,但它们正面临着收益递减的未来。NextSilicon 的创始人没有继续走老路,没有投入巨资打造规模越来越大的人工智能工厂,配备越来越强大的 GPU(以及更先进的电源和冷却系统),而是决定尝试一条不同的道路。
Elad Raz 指出,尽管拥有 80 年历史的冯·诺依曼架构为我们提供了通用可编程的计算基础,但它也带来了巨大的开销。他表示,98% 的芯片用于控制开销任务,例如分支预测、乱序逻辑和指令处理,而只有 2% 的芯片用于执行应用程序核心的实际计算。
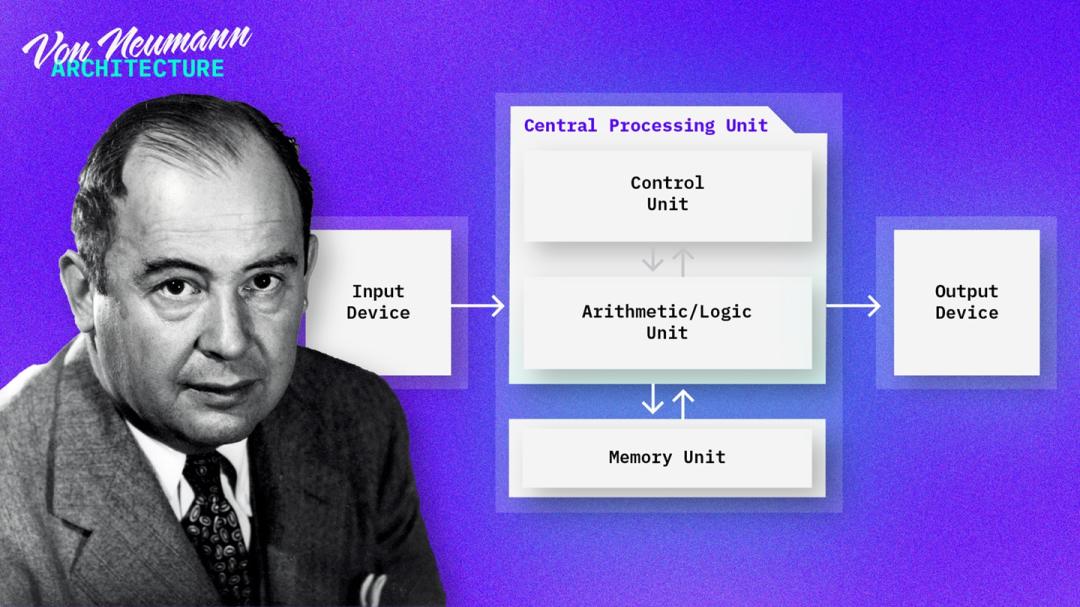
于是,Raz 和他的团队构想了一种名为“智能计算架构”(ICA)的新架构,该架构使芯片能够自我重构,以适应不断变化的工作负载,从而将开销降至最低,并最大限度地提升计算能力,用于处理高要求的 AI 和 HPC 应用背后的数学运算。这便是 NextSilicon 专利“可重构硬件的运行时优化”的基础,也是其 Maverick-2 处理器中使用的非冯·诺依曼数据流架构的指导原则。
“NextSilicon 的宗旨是使用软件来加速你的应用程序,”Raz 解释道。“其核心是一种复杂的软件算法,它能够理解代码中的重要内容并对其进行加速。相比之下,大多数 CPU 和 GPU 都是某种形式的处理器核心组。它们接收指令,并试图构建复杂的流水线和矢量指令集,并采用乱序执行来减少延迟。我们认为这是错误的方法。更好的方法是应用帕累托原则,看看哪些 20% 的代码占用了 80% 的运行时间。为什么我们不对计算和内存应用 80/20 规则呢?为什么我们不能自动识别重要的计算内核并尝试只关注它们呢?”
Raz 随后描述了其中的秘诀:“应用程序开始在主机上运行,然后我们会自动识别代码中计算密集型的部分。我们保留计算图的中间表示。我们不会将计算图转换为指令。你需要将其视为硬件的即时编译器。我们保留程序的计算图,并将其放置在数据流硬件上。我们从硬件获取遥测数据,并以递归方式进行,因此我们始终在程序运行时优化计算和内存。”
“先进的软件分析器就像一个精准定位系统,持续监控您的应用程序。它会精准定位出那些占用性能的关键代码片段,然后以纳秒级的粒度重新配置硬件本身,构建针对该特定代码优化的自定义数据流水线。这种非对称执行模型能够将卓越的效率精准地引导到能够发挥最大效能的地方,同时让您的大部分代码保持正常运行。”Raz总结说。
Raz同时指出,英伟达的CUDA生态,也在将大家绑死在其GPU上,丧失了主动性和议价权。为此,NextSilicon 制定了不是迭代的愿景,而是推动一场革命。公司不会墨守成规,而是构建一个全新的游戏规则,其中计算基础设施:
1、运行一切,毫不妥协:您现有的 CPU 代码、复杂的 GPU 内核、要求苛刻的 HPC 任务以及尖端的 AI/ML 模型——无需修改代码即可运行它们。
2、提供极致速度:体验高达 10 倍的加速,功耗仅为原来的四分之一。如何实现?通过实时动态优化芯片,优化应用程序最热门、资源最密集的代码路径。
3、消除供应商锁定:告别专有领域特定语言 (DSL)。告别繁琐的移植流程。告别框架维护的噩梦。您的代码,您的语言,加速开发。
4、让您的创新永不过时: ICA 能够随着工作负载的演变而不断调整。您再也不会遇到“重写瓶颈”。
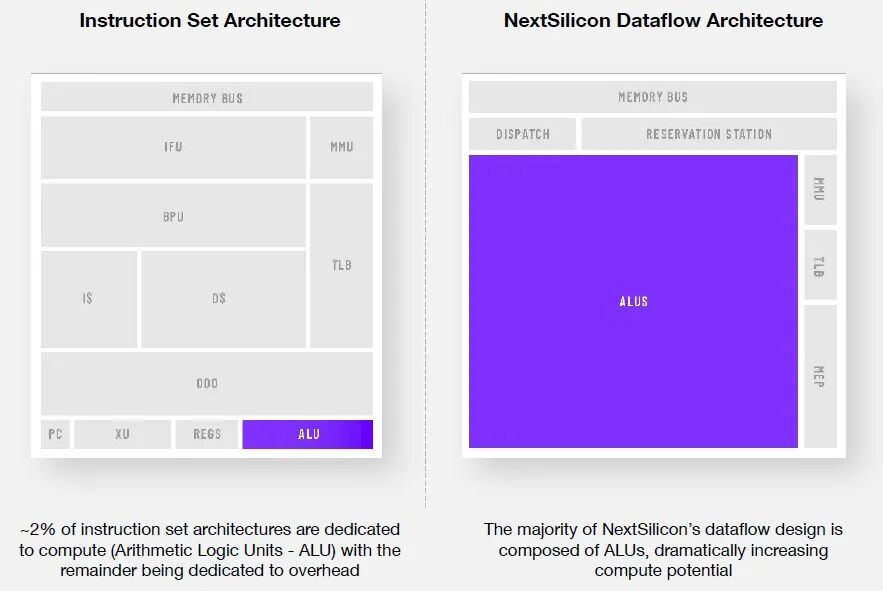
总结而言,NextSilicon 的数据流架构建立在图形结构之上。数据流处理器并非像冯·诺依曼那样逐条处理指令,而是由一系列计算单元(称为 ALU)组成,这些单元以图形结构互连。每个 ALU 处理特定类型的函数,例如乘法或逻辑运算。当输入数据到达时,计算会自动触发,结果将流向图形中的下一个单元。与串行数据处理相比,这种新方法具有很大的优势,因为芯片不再需要处理数据提取、解码或调度,这些是消耗计算周期的开销任务。
在预告Maverick-2 一年之后,NextSilicon终于带来了这颗革命性芯片的详细细节披露。
一颗与众不同的芯片
如下图所示,Maverick-2 芯片有四个计算区域,32 个 RISC-V E 核位于芯片左右两侧的外缘。据统计,计算块网格由七列组成,每列八个计算块,芯片上总共有 224 个计算块。每个计算块有数百个 ALU,因此可以轻松获得数万到近十万个 ALU。对于这颗采用台积电 5 纳米工艺制造,拥有540 亿个晶体管的 Maverick-2 芯片来说,这样的数据似乎并不合理。
但如果我们按照 NextSilicon 的图表所示做一个 14 x 14 的网格,那么每个计算块有 196 个 ALU;我们不知道一个计算块中有多少个浮点单元。每个 ALU 都有一个 FPU 是有道理的。

作为对比,英伟达的“Ampere” A100 GPU 采用台积电 7 纳米工艺制造,拥有 542 亿个晶体管和 6912 个 FP32 CUDA 核心;而“Hopper” H100 和 H200 GPU 采用 4 纳米工艺制造,拥有 800 亿个晶体管和 18432 个 FP32 核心。Blackwell B200 插槽有两个芯片组,每个芯片组包含 1040 亿个晶体管,但每个芯片组仅包含 16896 个 CUDA 核心,采用 4 纳米工艺制造。我们推测,ALU 比 CUDA 核心更小,并且 Maverick-2 芯片上的 ALU 数量比英伟达 GPU 上的 CUDA 核心数量更多。
归根结底,ALU 数量不如一组 mill 核心所能支持的线程数量重要。NextSilicon 联合创始人兼架构副总裁、前 Mellanox(现为 Nvidia 网络部门)软件总监 Ilan Tayari 表示,典型的 CPU 有两个线程,GPU 有 32 到 64 个线程,但一个 mill 核心可以同时支持数百个线程。当然,mill 核心的大小和形状会有所不同,但每个计算块可能有数十个 mill 核心,每个 Maverick-2 有 224 个计算块,因此可以轻松支持数千个线程,所有线程都以 1.5 GHz 的频率运行——大约相当于一个慢速 CPU 或一个普通 GPU 的速度——并且所有线程都连接到 HBM3E 显存以获得快速带宽。
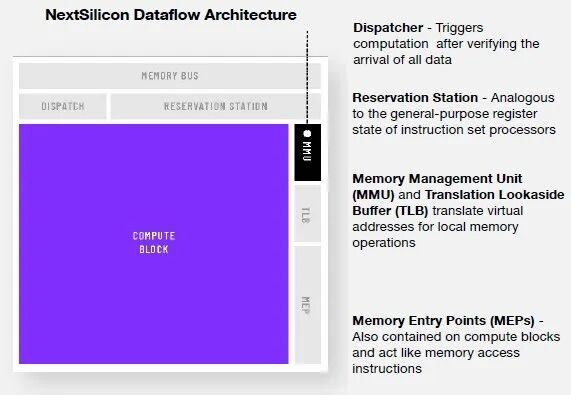
如上图右侧所示,这个主逻辑单元连接到一条内存总线,该总线上有一个保留站,用于在 ALU 调用数据之前临时存储数据。(NextSilicon 已获得这种保留站、调度器和数据流计算块组合的专利。)与常规 CPU 一样,Maverick ICA 也使用内存管理单元和表后备缓冲区,但这些单元的使用频率很低,并且仅在 ALU 调用特定数据时才会使用。它不进行推测或预测,只进行数据提取。
Tayari 自豪地说:“NextSilicon 的数据流架构使我们能够显著降低与传统 CPU 和 GPU 相比的开销。我们调整了硅片的分配比例。我们将大部分资源用于实际计算,而不是控制开销。我们独特的方法消除了指令处理开销。我们最大限度地减少了不必要的数据移动,从而使计算单元保持充分利用。我们并非试图隐藏延迟,而是通过设计来容忍并最小化延迟。”
当应用程序为数据流引擎编译时,它实际上被映射到数据流引擎上,形成一个称为 mill core(看起来像一个图)的东西。它看起来像程序在编译之前的中间表示图,并被放置在 ALU 上。NextSilicon 联合创始人兼首席执行官 Elad Raz 表示,多个 mill core 可以像俄罗斯方块一样放置在同一个计算块上,并且可以根据工作负载的需要,在几纳秒内加载和删除 mill core。
据介绍,Maverick-2 提供单芯片和双芯片两种配置。单芯片 Maverick-2 拥有 32 个 RISC-V 核心,采用台积电 5nm 纳米工艺制造,主频为 1.5GHz。该卡支持 PCIe Gen5x16,配备 96GB HBM3E 内存,内存带宽高达每秒 3.2TB。它拥有 128MB 的一级缓存,配备 100GbE 网卡,热设计功耗 (TDP) 为 400W,并采用风冷散热。双芯片 Maverick-2 则有效地将所有这些功能翻倍,但它需要接入 OAM(OCP 加速器模块)总线,配备两个 100GbE 网卡,支持风冷或液冷散热,热设计功耗为 750W。
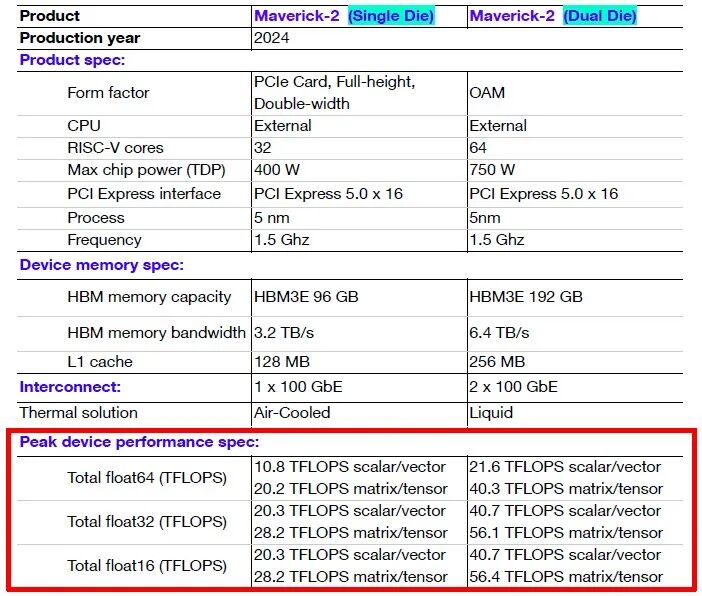
NextSilicon 还分享了 Maverick-2 的一些内部基准测试数据。就每秒千兆次更新 (GUPS) 而言,Maverick-2 能够以 460 瓦的功耗提供 32.6 GUPS,据称这比 CPU 快 22 倍,比 GPU 快近 6 倍。在 HPCG(高性能共轭梯度)类别中,Maverick-2 以 750 瓦的功耗实现了 600 GFLOPS 的计算能力,据称这与领先的 GPU 相当,但功耗仅为后者的一半。
NextSilicon 研发副总裁 Eyal Nagar 表示:“我们今天详细讨论的不仅仅是芯片,而是一个基础,一种思考计算的新方式。它为工程师和科学家打开了一个充满可能性和优化的全新世界。”
一颗意外的RISC-V芯片
NextSilicon 在发布会上,还同时披露了一颗名为Arbel 的RISC-V CPU。该公司对 RISC-V CPU 设计其实并不陌生。如上面提到的Maverick-2 就使用了一个定制的 RISC-V 内核来处理难以并行化的串行代码。该芯片性能出色,因此该组织选择采用独立内核。

NextSilicon 表示,该核心显然已经在台积电 5nm 工艺中实现,将支持高达 2.5 GHz 的时钟速度,具有 10 宽的发射管道、480 条目的重新排序缓冲区,支持 16 条缩放器指令,并集成四个 128 位矢量单元用于单指令多数据 (SIMD) 工作负载。
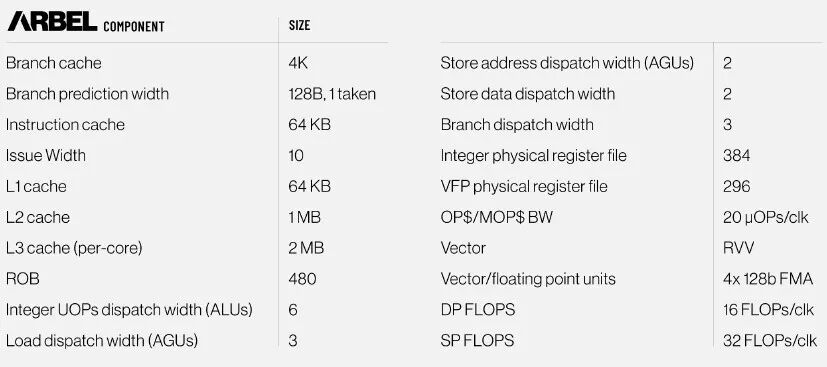
具体而言,Arbel 核心在整数端拥有一个 10 位宽的发射解码器和 6 个 ALU,在矢量端拥有 4 个 128 位 FPU。该核心可以并行支持 16 条标量指令。它拥有靠近 ALU 的 64 KB L1 指令缓存和 64 KB L1 数据缓存,以及靠近 FPU 的 1 MB L2 缓存。(这两个缓存显然都与所有计算单元交叉链接。)每个核心有 2 MB 的缓存,但同样,我们不知道 Arbel 芯片上有多少个核心。
NextSilicon 表示 Arbel 核心可以与英特尔的“LionCove”Xeon 核心和 AMD 的“Zen5”Epyc 核心“相媲美”。
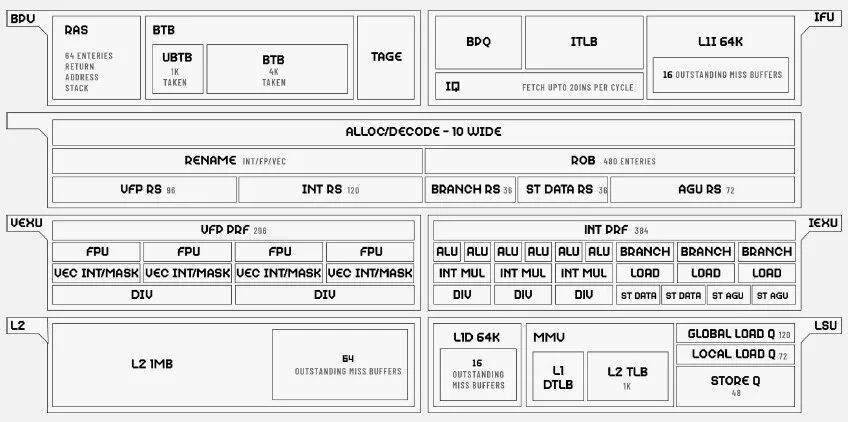
NextSilicon 强调,能实现这样的突破,主要归功于Arbel 通过四项关键架构创新:
1、大规模指令流水线具有 10 宽的发射宽度和 480 条目的重新排序缓冲区,使 Arbel 能够一次发现更多问题并最大限度地提高核心利用率。
2、2.5 GHz 的核心频率可提供高单线程性能,同时保持功率效率。
3、宽执行单元支持并行 16 条标量指令,加上四个集成的 128 位矢量单元,可在数据并行工作负载上实现卓越的性能。
4、先进的内存子系统具有 64KB L1 缓存和大型共享 L3,可保持数据接近且核心持续供电 - 解决限制现代应用程序的内存带宽和延迟瓶颈。
5、Elite TAGE 分支预测器可确保更快、更准确的决策,减少错误预测和浪费的工作。
“这是基于台积电 5 纳米工艺打造的真正硅片——这是我们自主研发的专利 IP,并非授权或借用。由 NextSilicon 工程师打造,旨在实现 NextSilicon 的未来愿景。”他们强调。
那么,这是否意味着NextSilicon 将会成为一家 CPU 公司?
该公司回应道:“不完全是,但我们正在探索一些更有趣的东西。”
NextSilicon表示,公司看到客户对 Arbel 表现出浓厚的兴趣,这让其看到了 AMD 和 NVIDIA 所意识到的机遇:CPU 和加速器技术之间垂直整合的强大力量。当你同时掌控通用计算和专用加速时,你就能以依赖其他 CPU 架构时无法实现的方式优化整个堆栈。
这种做法类似于 Nvidia 在其 GH200 和 GB200 超级芯片中对 Grace CPU 所做的那样。
“当你同时控制通用计算和专用加速时,你可以优化整个堆栈,而当你依赖其他人的 CPU 架构时,这是不可能的,”Raz 解释道。
NextSilicon声称,对于正在应对现代人工智能和高性能计算 (HPC) 基础设施复杂性的企业来说,计算难题已不再是不可避免的。Maverick-2 代表了最佳平衡:工作负载优化的性能与通用可编程性、ASIC 级效率(无需多年的开发周期)以及即时加速,无需数十年来困扰业界的供应商锁定。
Maverick-2 的数据流架构已经彻底改变了计算领域,而 Arbel 也展现了我们从零开始设计世界一流芯片的能力,我们正在证明,计算的未来并不需要你做出妥协,而是需要从头开始重新思考架构。
