


图:Groq的营销戏码——在行业会议活动上租了一头Llama
北京时间 12 月 25 日,Groq 披露与 NVIDIA 达成 200 亿美元的技术许可协议。
主要包含三项重要内容:
1、NVIDIA 并非法律意义上收购Groq ,而是达成了一项非独占的技术授权协议,NVIDIA 将可以使用 Groq 的硬件与架构设计许可。
2、Groq 的 CEO Jonathan Ross(Google 最早 TPU 团队的成员),以及 Groq 几乎所有重要的核心成员,都会加入 NVIDIA。
3、Groq将继续作为一家独立公司存在,保留其核心知识产权,并继续运营。
这里值得注意的是:NVIDIA 将收购 Groq 的全部实体资产,但不包括其知识产权;Groq的人看起来是被收购的主要资产;Groq这家公司并没有被收购,还会作为独立的公司继续运营之前的主要业务。
媒体传出的消息说这笔交易的总价值约为 200 亿美元。
200 亿美元足以买下全球顶尖晶圆代工厂格芯(GlobalFoundries)的全部股份,也相当于 四分之一Intel的市值。NVIDIA 愿意支付如此巨额的对价,却只拿到了一个‘非独占’的许可?
联想到不久前 Intel 拿下 SambaNova 的棋局,值得对这件事情深度思考。事实上,本质上基于超长指令架构(VLIW)的所谓LPU,其架构授权本身并不值200亿美金,但是Groq交易动作背后的意义远超200亿美金。
近来AI泡沫论、Google TPU、Broadcom、产品出口受限、甚至美国国内要求对AI强监管的呼声,都在对Nvidia的市值提出挑战。
黄仁勋通过极高对价的资本动作向华盛顿与中东盟友交出一份沉甸甸的“战略投名状”,意在利用资本博弈深度对接白宫的 AI 利益版图,从而换取核心产品在全球市场的出口豁免权与联邦级监管红利,进而维持在AI基础设施的垄断地位与高增长。
本文基于对基于超长指令架构的AI芯片产品进行技术架构详细拆解,分析为何Groq不值这个价钱,并结合资本方及融资动态、梳理最近白宫围绕Nvidia重要动作的时间线,尝试一窥这场巨额非典型收购背后的复杂棋局。
01 Groq 讲的故事,资本很买账
Groq 成立于 2016 年,其核心产品最初名为 TSP(张量流处理器),后随着 Transformer 架构成为主流,更名为 LPU(语言处理单元),也称 GroqChip 1。
这款芯片于 2019 年发布。Groq 的 CEO Jonathan Ross 曾是 Google TPU 项目核心成员。与 Google TPU 采用 8 路 VLIW 脉动阵列不同,Groq 采用 144 路 VLIW 大规模设计,由 GlobalFoundries 代工,在成本和规模扩展上更具优势。
产品方面,Groq 原计划 2025 年推出基于三星 4nm 工艺的第二代芯片,2026 年规模化部署,但至今未见踪影。
融资方面,Groq 已累计融资 18 亿美元,包括 2024 年 6.4 亿美元 D 轮和 2025 年 7.5 亿美元 E 轮(估值 69 亿美元)。2025 年 2 月,Groq 获沙特 15 亿美元承诺资金用于扩展 AI 推理基础设施,当时已有 1.9 万颗芯片部署在沙特。
那么,Groq 的产品有什么特殊之处?
答案是 Memory(内存)。Groq 最显著的特点是:没有外接 DDR 或 HBM,只使用片上 SRAM。
这带来极快的访问速度,但劣势明显:每颗芯片仅 230MB 存储容量。即便是 Llama 7B 这样的小模型也需要 2 个机柜,部署 70B 模型则需要 10 个机柜、超 100 千瓦功耗,而其他 AI 芯片最多一台一体机即可。(详见腾讯科技2024年2月20日分析文章)
这样的代价换来的是:在单用户推理场景下性能极其出色,Token 生成速度达到市场最快一档。因此 Groq 主打“规模化部署下的高推理速度”这一卖点。
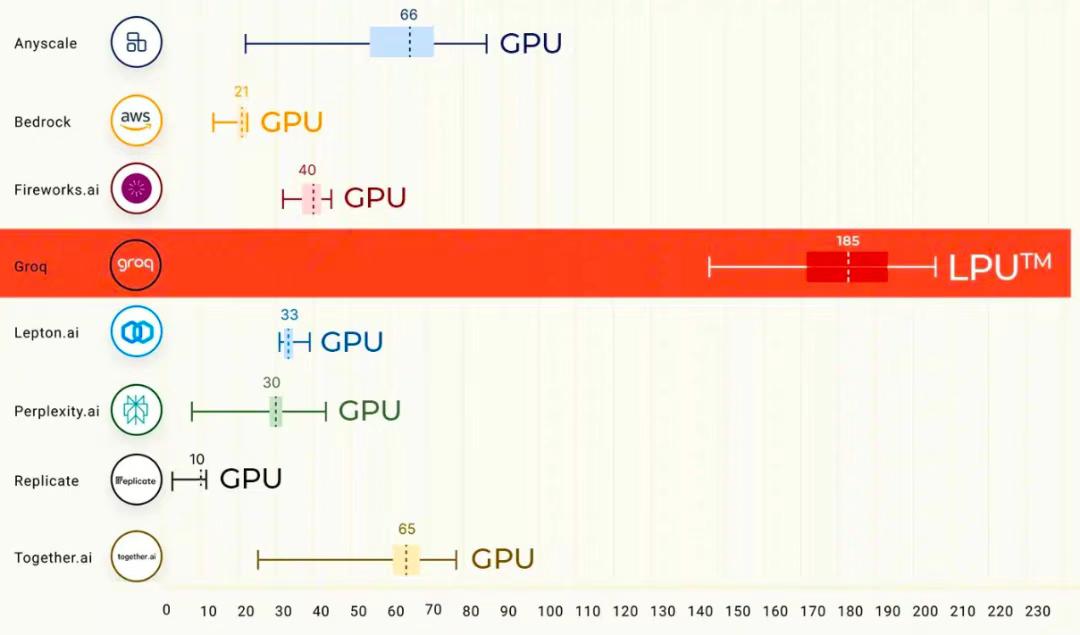
图:高推理速度对比图
需要明确:Groq 不是 TPU 翻版,也不是传统 ASIC。除了内存设计,其架构也截然不同。Groq 采用 144 路全覆盖 VLIW 架构,可准确描述为:极宽 VLIW、完全静态调度、单线程确定性执行、无乱序/分支预测/投机执行、数据流高度可预测。这表明 Groq 更接近“超大规模硬实时 DSP/Dataflow Machine”。
Groq 在 AI 计算中有哪些优势?
首先,极低且可预测的推理延迟,Token 输出极快。这是 Groq 最大优势。其架构无动态调度干扰、无缓存缺失随机延迟、无 Warp 分歧性能损耗、无内核启动开销,因此 token latency 和 tail latency 都极小。在单请求体验和实时推理场景中极具吸引力。
第二,极高的能效理论上限。无复杂控制逻辑,芯片大部分面积用于计算,没有长期常开的调度单元,算力能耗比理论值非常漂亮。
第三,确定性系统行为,对系统工程极其友好。每个 cycle 的执行已知,无运行时调度抖动,性能不因输入分布变化而漂移,这对系统设计和运维非常友好。
但这些优势成立的前提极其苛刻:必须把计算静态地、近乎完美地填满 144 个并行执行块。这要求模型结构高度规则、算子形态稳定、内存访问可预测、调度空间可被人工穷举。
真实场景并非如此理想,因此需要极强的软件来弥补。

02 真实的Groq芯片架构
上面提到Groq的芯片根本不是TPU,而是类似于DSP的架构,其在AI计算中的优势要求很苛刻。更值得玩味的一点是,Groq近几年特别避讳说自己的架构是超长指令架构,这又是为什么呢?
超长指令字(Very-Long Instruction Word,VLIW)是一种相当“异类”的计算机体系结构,它与 CPU 和 GPU 在设计理念上非常不同。
在过去的几十年里,VLIW 一直在一些细分市场中表现出色,比如DSP和MCU领域。而随着AI的兴起,以及对AI算力芯片需求的大爆发,VLIW 开始再次伟大“复兴”(Make VLIW Great Again!)。
之所以许多人关注并利用VLIW 这种架构,是因为它能够实现结构简单、设计优雅、高效率、低延迟的芯片硬件。但其代价也很大,它几乎把负担和期望全部压在了编译器和软件栈身上,很多时候甚至需要用户亲自手写(汇编)代码。
AI计算芯片(通用芯片与专用芯片,泛化能力)
在AI芯片领域,对模型的泛化能力决定了是否可以被真实地部署到生产环境中,而这就与编译器存在着紧密关系。简单来说,芯片硬件决定了性能的上限,而编译器决定了芯片能发挥出多少性能,以及可以支持多少种模型。
在AI计算中(本文都是以推理计算为例),AI模型是由复杂的数学算子(卷积、矩阵乘法等)组成的计算图。由于芯片(VLIW 或 GPU)只认底层的二进制指令,因此就需要编译器来负责把高级语言(PyTorch/TensorFlow)写的模型,翻译成芯片能听懂的指令。但是对于 VLIW 这种静态架构,编译器还要多做一项任务,也就是精确安排哪个计算单元在哪个纳秒处理哪个数据。
正是因为这最后一个任务,成了所有VLIW架构的AI芯片编译器的噩梦。
编译器和工具链
我们用Groq和Nvidia的GPU来举例说明编译器对于模型的泛化能力的影响、进而对是否可以大规模商用部署所起到的决定性作用与极限挑战。
- GPU,是强硬件架构,泛化能力由硬件冗余和编译器共同支撑。
- GPU硬件内置了复杂的调度器,能自动处理一些乱序和并行任务。编译器的压力相对较小,只需要把算子优化好即可。
- 这类芯片天然泛化能力强,因为即使编译器不是最完美的,硬件也能靠“蛮力”自动查漏补缺。
Groq,基于VLIW,算是强软件架构,泛化能力和编译器的强大程度息息相关。
芯片硬件本身非常简单(甚至没有调度逻辑)。如果出现了一个全新的模型结构(比如从 CNN 变成 Transformer),硬件动不了,只能靠编译器去重新拆解计算图,寻找新的并行方式。
如果编译器不够聪明,无法把复杂的模型逻辑映射到简单的硬件上,芯片的泛化能力就会很差,只能跑特定的几种模型。
也正因如此,Groq几乎不使用VLIW架构这个字眼,而是用TSP,后来更是用LPU这个非常蹭大模型眼球的名称,就是希望将软件面临的问题不要被太注意。
即使在最初(2020年)其介绍产品的这篇论文中,在“ARCHITECTURE OVERVIEW”这个小节,也只是使用了“144 independent instruction queues (ICUs) ”这个表达,通篇没有VLIW这个词。

也就是说,考虑到那个年代模型的零碎,Groq从一开始就在向外界隐藏(或者说淡化)致命的弱点,就像现在绝大多数所谓AI芯片公司一样,对大规模商用部署讳莫如深,目标仅仅是用自己的Demo(展示机)来提升估值。
03 VLIW的AI芯片产品周期
事实上过去这些年,有许多公司尝试着用VLIW来做(AI)芯片,比如Movidius、高通的Hexagon、Google的TPU、TI的DSP,其中DSP做的很不错,但做AI芯片,都绕不开编译器的问题。
这众多项目中,只有 Google 在自家选定的的应用场景下、在8-wide规模上把编译器做得很好。而 Groq 是 144-wide,难度不是线性上升,而是巨量级上升。
因此在这个领域的创业公司做AI芯片产品,大概率就会是这么一个套路:
1. 硬件团队做出漂亮架构,算出理论吞吐、能效、面积优势,找投资人拿钱;
2. 现实落地阶段会发现不仅难泛化,且无法做到当初预期的性能,毕竟把模型映射到宽 VLIW 的调度问题实在太难;
3. 这个时候就会手动调优某一特定模型,然后利用特定模型手动调优出的性能,继续找投资人拿钱;
4. 但如果模型迭代太快,编译器团队就会压力倍增,需要更多的人手来手动处理,这又会要求融更多的钱来招更多的高成本的软件工程师;
5. 随着融资轮次的增加,编译器和市场团队会无路可走,产品与市场负责人或者继续承压,或者当作背锅侠走人;
6. 而采用VLIW的这家企业,真正的目标实际上是要靠尽快被并购(在国内运气好了赶上政策还可以上市)来套现;
对于成熟的资本市场而言,对其他 AI 芯片初创公司的信息非常明确:要么当某大厂的合作伙伴,要么成为收购目标,要么作为竞争者被砸钱砸到出局。
04 独特的视角:人员流动方向
如果你现在去看Groq论文中的第一作者,Dennis Abts,会发现他在 2022 年 10 月加入了 Nvidia。
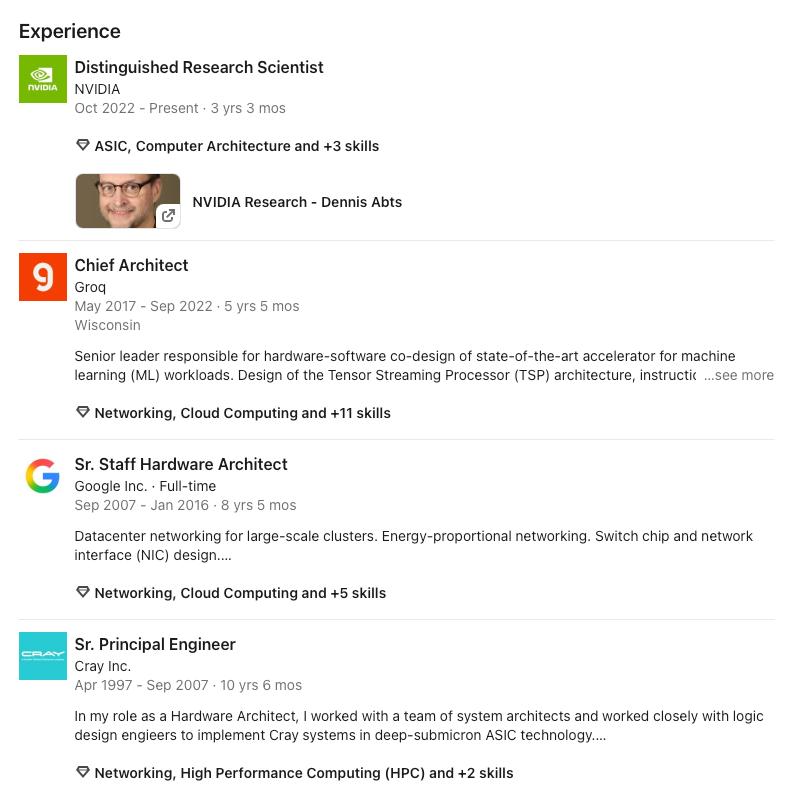
图:Dennis Abts加入Nvidia
这位曾在大名鼎鼎的Clay工作的大佬,在Groq正是软、硬件协同设计的负责人。2022年的夏秋之际,正是大模型爆发的前夜,AI还是处在ResNet、Yolo、BERT、UNET、双塔等 CV、NLP和搜推应用中数目繁多的模型与场景中,对于一家AI芯片来说,软件栈对于这些大量的主流模型的适配是无法逃避的工作,如果要支持快速迭代的适配,编译器就不得不面对动态调度的需求,这对Groq(的Dennis)来讲几乎是不能完成的任务。如果需要向投资人交差,主动或背锅离开就是必然的了。
我稍微花了点时间去搜索,除了Jonathan Ross作为创始人还在之外,其中有许多为已经离开,去往NV、Google、Amazon等企业。
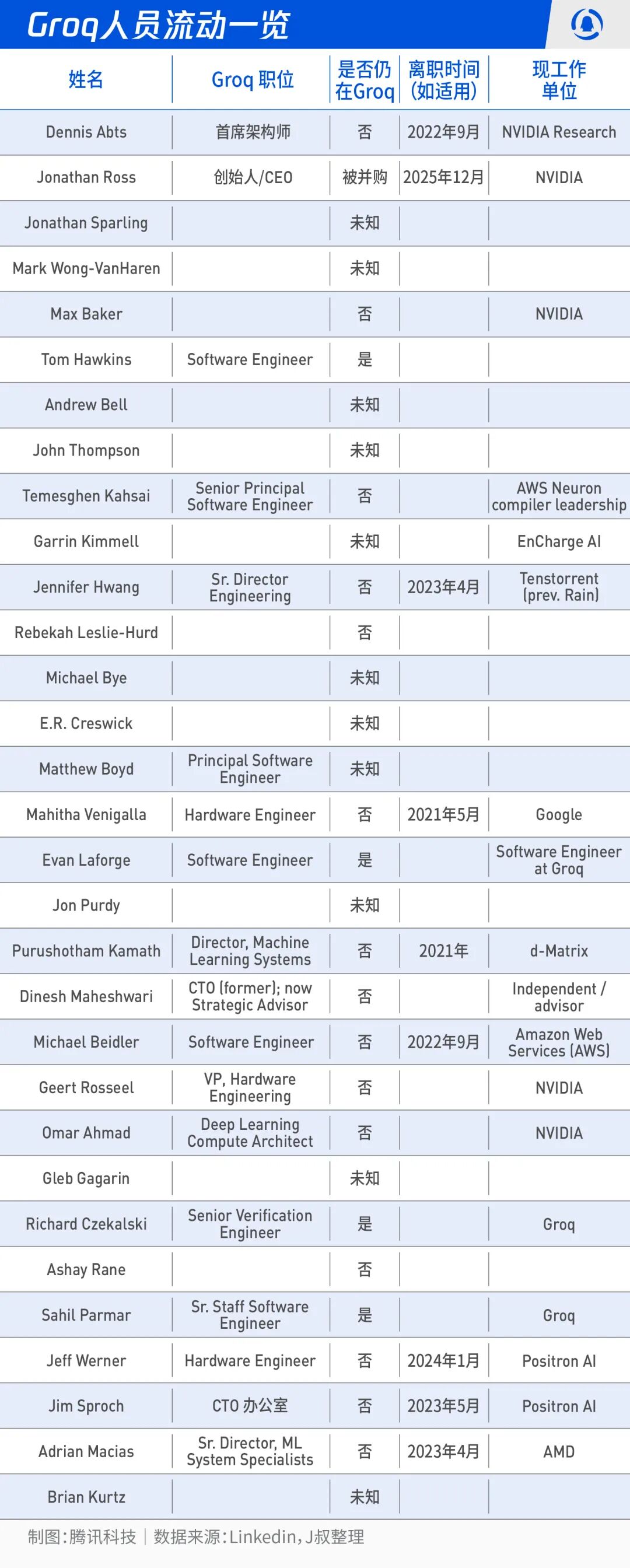
05 套现的交易?
正如上面所述典型套路,此类公司(在海外)的终局就是被收购,这不过是将相关人等的解套。然而,这次的并购正如Groq其芯片架构一样,挂羊头卖狗肉。
真实的并购交易需要监管审批,而这只是一笔技术授权交易,并不需要证券、反垄断等监管机构的审批。但如果稍微动点脑子就会发现,在结果层面,它看起来已经非常接近一次并购了。
这也是铺天盖地的新闻报道,标题几乎都是按照收购来写的原因。
近年来很多类似交易都遵循同一种模式,全球最大的科技公司用大额资金与“有前途的”初创公司达成协议,拿走它们的技术与人才,但又刻意避免在形式上完成收购。他们假装这只是受限的 IP “收编式挖人(acquihire)”。
设想一下,假设真有这么一家芯片公司,也想获得 Groq 的 IP 授权。那么问题来了:技术支持从哪里来?核心成员并入NV的情况下,后续还有没有持续演进的技术路线图?还是说,公司买到一个“没有未来开发团队的 IP 包”也是可以接受的?
前面提到,最近一轮的融资是在今年9月,投资者包括贝莱德、纽伯格伯曼、三星、思科,以及Altimeter和1789 Capital。特别需要注意的是,对,特别需要注意,特朗普的大儿子是1789 Capital的合伙人。
更进一步,这对沙特主权财富基金来说是可以一场大胜,在此之前,其对Groq的投入,基本上都转化成了在当地的算力建设,而本次的交易,又实现了超额的资本收益。赢两次,双赢。
有没有一种可能,这笔法律上不构成并购的交易,在今年9月份已经谈妥?
06 Nvidia的考量
但是,花费200亿美金,Nvidia图什么?
从产业角度分析,可以牵强附会多种利好与协同。
推理成为主战场后,客户开始按Token的综合成本重新定义性价比,这种在某些场景下极致性能的VLIW芯片也许可以成为Nvidia的侧翼,从而让手上也有一条“非 GPU”路线可以塞进同一个平台叙事里。再考虑到Groq已经尝试了芯片公司运营AI云的商业模式,NV借此机会暗渡陈仓进入这一业务,并通过这一模式配合英伟达的市场与资本运作,也尚未可知。
但,这并不能解释为何会值200亿美金。更蹊跷的是,这个200亿美金的交易对价,并不在Groq的新闻稿中,而是由CNBC最先透露。
最合理、且符合实际的解释,就是这本质是一出资本套现戏码,既和NV和AI产业的资本局有关,也可能和黄教主在游说白宫(甚至是特朗普)达到某个战略目标有关。
近来AI泡沫论、GoogleTPU、Broadcom、产品出口受限、甚至美国国内要求对AI强监管的呼声,都在对Nvidia的市值提出挑战。
黄仁勋同时在白宫两条线游说:一条是反对更严对华 (以及其他受限制国家,此前也包括沙特)AI 芯片出口法案(如 GAIN AI 法案未被纳入国防法案);另一条就是反对州级 AI 严监管、争取联邦统一框架,两者共同目标都是为英伟达争取更大的全球与本土市场空间。
NV通过这笔交易进一步向沙特示好。美国AI巨头,都将中东当作算力布局中最为重要的区域,此前一段时间,该地区也在受限列表上。而随着豁免的批准,Nvidia可以借助于自身和Groq原有的布局、以及这笔交易向沙特交的“投名状”,更好地开展业务。
看一下时间线:
2025年夏天,特朗普试图在“大而美法案One Big Beautiful Bill”中塞入一条“联邦优先、冻结州级 AI 法规 10 年”的条款,结构参议院投票结果为 99 票反对、1 票赞成,条款被否决。
2025年9月,Groq进行了最后一轮融资,1789 Capital(小特朗普)入股,老股东跟投。
2025 年 11 月 19 日:美国商务部正式宣布,授权沙特政府支持的 AI 公司 Humain 和阿联酋的 G42 购买先进 AI 芯片,每家最多可购 3.5 万枚英伟达 Blackwell GB300 或性能相当的 AI GPU,这标志着美国首次公开批准大规模向沙特出口当前一代顶级 AI 芯片。
2025 年 12 月 8 日,特朗普在其社交媒体账号上发文宣布,在“确保国家安全”的前提下,允许英伟达向中国及其他获批客户出口 H200,随后白宫与商务部等部门开始就具体许可和“白名单”审查流程落地。
2025年 12 月 11 日,特朗普签署名为“确保人工智能全国政策框架”的行政命令,通过行政手段推进联邦优先思路,被视为绕开国会僵局、在监管上“联邦接管 AI 治理”的一步。
若联邦成功压制“最严厉”的州级 AI 法规,英伟达等 AI 基础设施供应商在美国的客户(云厂商、互联网平台、大模型公司)合规负担会减轻,间接支撑这些客户继续高强度采购 GPU/AI 芯片,对英伟达业务构成正面支持。有利于提振对英伟达未来收入与投资周期的预期,进而可以继续支撑甚至抬高股价。
2025年12月24日,Groq宣布了这笔对价200亿美金的交易。
中美这两大在AI领域下重注的经济体,近来不约而同地为AI芯片创业企业救场。AMD收购Untether AI的员工团队;传言Intel近乎达成对Sabanova的收购;Nvidia非典型地收购了Groq;而在东方大国,科创板近来挂牌两家,元旦新年后一周时间港交所再迎来两家。
当Google和Broadcom吹响了TPU的号角,AMD催肥了CUDA兼容的土壤,东方已然破晓!
资本东风迎面吹来,科创板与港交所的钟声嘹亮;向西吹去,并购的落槌声此起彼伏。
历史不会重复,但会押着相同的韵脚。无论西东。
