

如果用一个词概括HBM这几年的进化,那就是:堆得越来越高。HBM本质上是一种“把 DRAM 垂直叠起来”的存储技术。层数越高,单颗 HBM 的容量越大、带宽越高,对 AI GPU 来说就越香——因为 AI 真正稀缺的从来不是算力,而是喂数据的速度。
因此,HBM 的演进路线也非常清晰:从4层到8层、12层,再逼近16 层。8 层是 HBM 真正成熟、规模化出货的主力,它是过去一段时间 AI GPU 的“最常见配置”,良率稳定、供应链也最成熟;12层则成为近两年的主力量产方向,在容量、性能与成本之间取得了更理想的平衡,也最适合大规模出货。而截至目前,HBM 已经正式迈入16层堆叠的量产前夜:在刚刚结束的 CES 2026 上,SK 海力士已经展出了全球首款16层 HBM4 样品,单堆栈容量提升至 48GB。
但层数的提升,并不只是“多堆几层”这么简单。事实上,每增加 4 层,整个系统的制造难度都会显著上一个台阶:贴装精度、焊点间距、Z 方向高度控制、翘曲、底填(MUF)可靠性……所有原本还能被工艺余量掩盖的问题,都会被 16 层这种高度放大到“生死线”级别。
面对困局,行业分化出了两种声音:一种是追求终极的革命,另一种是基于现实的改良。
混合键合:
被“标准”暂时挡住的革命
芯片的堆叠主要是考验封装的能力。这两年先进封装圈子里一个词异常火热:混合键合(Hybrid Bonding)。它是一种高级的互连技术,彻底抛弃了焊料与助焊剂,通过金属层与介质层的同步键合,实现更接近“直接连接”的互连形态。它代表了更小互连间距、更高 I/O 密度、甚至接近“原子级连接”的终极方向。
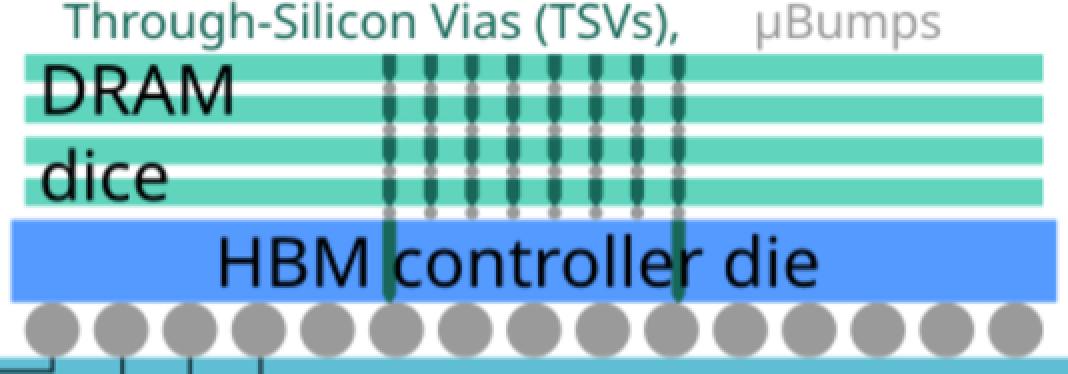
通用 HBM 结构。图中显示了微凸点。采用混合键合技术后,DRAM 芯片之间的间隙将消失。(图源:semiengineering)
原本,业界普遍预测 HBM4 将是混合键合的商业化首秀。但 JEDEC 组织的一项最新修订——将 HBM 模块高度上限从 720µm 放宽至 775µm——为 16 层 HBM 继续沿用传统微凸点(Micro-bump)技术腾出了宝贵的 55µm 空间。
这一标准红利,让原本紧绷的物理极限得到了喘息,也让一项名为Fluxless(无助焊剂) 的技术被紧急推向了台前。
Fluxless:
通往终局前的一项过渡技术
然而,即便有了高度冗余,即便暂时不用混合键合,问题依然没有消失:传统互连工艺的稳定性与成本结构,已很难从容支撑 16 层 HBM 的量产爬坡。
为什么?我们把镜头拉回到 HBM 堆叠装配中的关键工艺——热压键合(TCB)。在各种先进封装架构下,热压键合(TCB)被认为是最先进的互连方法之一。尽管这项技术已经开发并应用了十余年,但由于其在引入时带来的诸多收益,仍在不断被新应用持续采用。需要说明的是,TCB 不仅仅是为了 HBM,它是为了将不同节点的 Chiplets 强行“缝合”在一起的关键手段。
热压键合(TCB)作为针对细间距(Finer Pitch)应用的解决方案而兴起。TCB 使用配备有铜柱(Cu Pillar)和焊料帽(Solder Cap)的晶圆,通过限制焊料量来缩减铜柱间距,从而实现更高的互连密度。TCB 有多种类型(如下图所示),无论哪种类型,其主要方法都是在固定芯片和基板的同时进行局部焊料回流,随后冷却使焊料固化,从而将芯片固定在基板上。通常只有在焊料部分或完全固化后,芯片才会被释放。该方法实现了更高的精度,因为它不依赖于焊料的自对中效应,同时通过在键合过程中保持芯片和基板的平整,缓解了翘曲(Warpage)问题。此外,TCB 允许主动控制键合层厚度(BLT),确保互连焊料形状均匀,并为后续的底部填充(Underfill)等工艺提供便利。
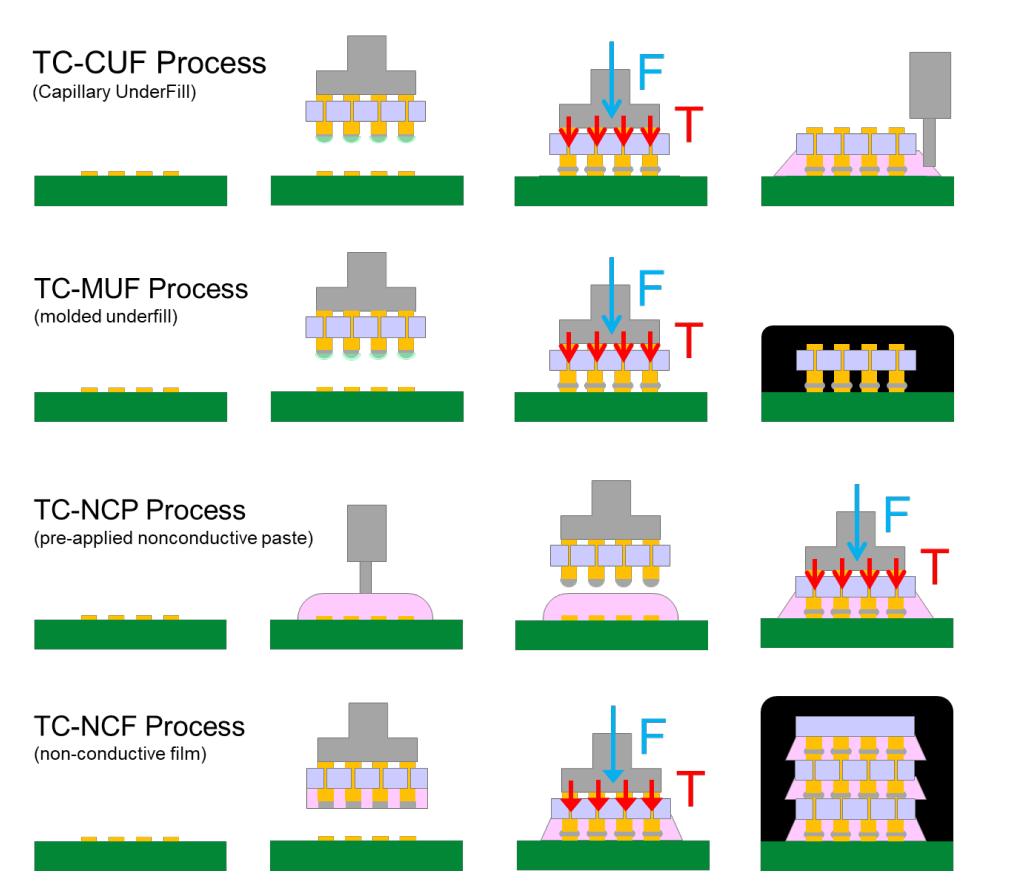
TCB 的四种主要类型包括:毛细管底部填充 TCB (TC-CUF)、模塑底部填充 TCB (TC-MUF)、非导电胶 TCB (TC-NCP) 和 非导电膜 TCB (TC-NCF)(来源:BESI)
传统TCB依赖助焊剂(flux)与回流(reflow)来促进焊料润湿和去除氧化层。但在细间距键合中,尤其是40μm以下pitch,这种方式往往导致:空洞(void)、残留污染物、可靠性下降,难以满足更高精度的要求。而 HBM4 16 层把互连间距压缩到 10µm 级,这些问题会被进一步放大:助焊剂体系的残留与清洗成本开始成为良率与可靠性的瓶颈,甚至会影响后续 MUF/底填材料的润湿与粘附。
于是,在真正迈向混合键合之前,产业迫切需要一种不推翻既有 TCB 体系,却能向更细间距(通常在 10µm 至 25µm 范围内)、更高堆叠过渡的现实路径——Fluxless(无助焊剂)TCB,便是在这样的背景下走上前台。
顾名思义,这种方法完全不使用任何形式的助焊剂。在无助焊剂 TCB 中,带有铜柱和焊料帽的芯片直接键合到基板上,无需任何中间介质。然而,氧化物去除成为了一个核心问题,因为氧化层会抑制焊料的润湿性,阻碍其与基体材料形成冶金结合。该工艺必须确保在芯片与基板接触之前清除所有现存氧化层,并防止在 TCB 升温过程中生成新的氧化物。
在氧化物去除方面,ASMPT 通过等离子体活化(AOR:主动氧化物去除)替代化学助焊剂。这种“干法”工艺能确保界面极度洁净,显著降低信号损耗,并改善热性能。Besi则倾向于甲酸和氢基还原。无论哪种技术路径,无助焊剂 TCB(Fluxles TCB)的发展代表了一项重大进步,解决了助焊剂和薄膜在实现稳固可靠键合工艺方面的局限性。
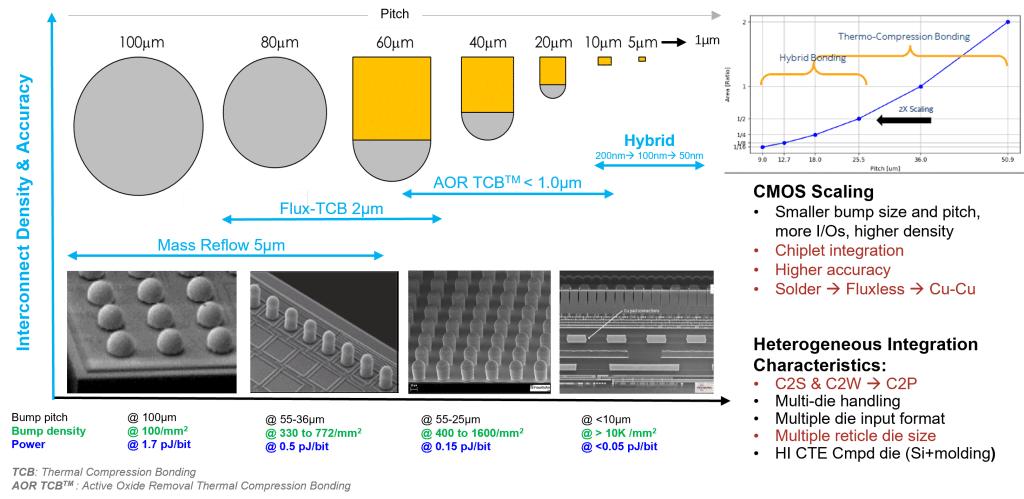
来源:ASMPT
ASMPT认为,在下一代 HBM 中(见下图),Flux-TCB 已具备 HBM 量产资格,且已用于最高 12 层的 HVM(高产量制造);而 AOR TCB 已在 12~16 层范围内展示出成功实现的能力,从而进一步支撑 HBM 路线图。这一经验证的能力确保:可在覆盖全部层数的前提下,严格控制堆叠芯片的间隙高度,从而赋能下一代HBM——这是满足最新 HPC 与 AI 器件性能需求的关键。
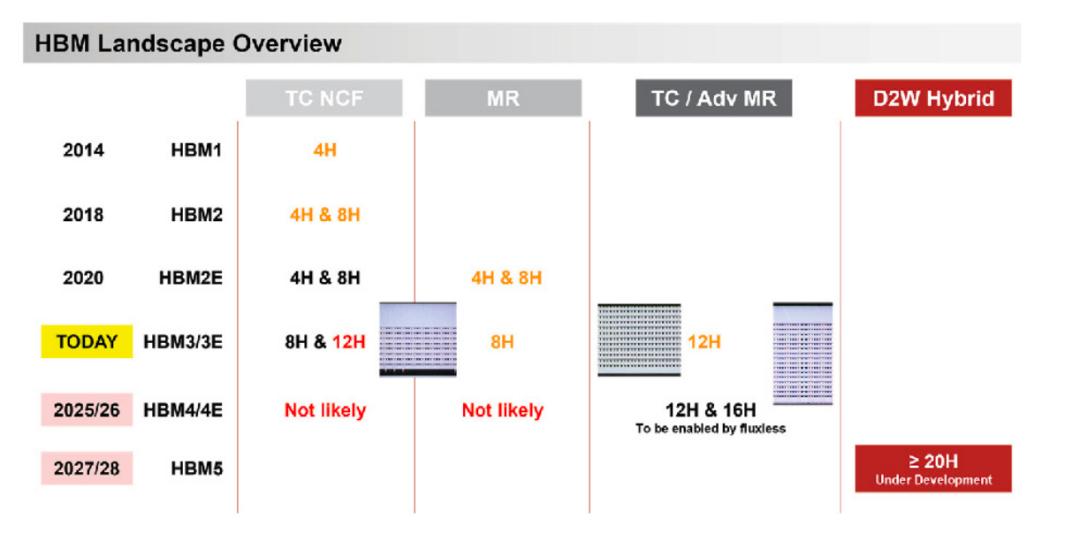
HBM路线图规划(来源:ASMPT)
可以说,Fluxless 既是对传统焊接工艺的最后一次极致压榨,也是在混合键合全面统治战场前,设备商为 AI 芯片量产平衡性能与良率的最佳“最优解”。
SK海力士:
Fluxless技术为时尚早
然而,即便作为过渡方案的Fluxless方案,在量产落地的过程中也并非一帆风顺。
作为HBM的领头羊,SK 海力士在对 Fluxless 进行了长达数月的评估后,给出了一个略显保守的结论:“现在还早”。 据悉,SK 海力士在 HBM4/4E 的 16 层产品上,将继续沿用其引以为傲的 Advanced MR-MUF 工艺。
SK海力士的MR-MUF工艺,是在芯片完成堆叠后,将液态封装保护材料注入层间空隙并固化的一种方式。公司与日本 Namics 共同开发并完善了 MUF 关键材料,并将其应用于第三代 HBM2E。SK海力士认为,相比竞争对手在每堆叠一层芯片时都需要铺设膜状材料的 TC-NCF 工艺,MR-MUF 更高效。此后 SK海力士又通过引入新型保护材料、改善散热特性,将“先进 MR-MUF”导入 HBM3,并一直沿用至 HBM4 12层产品。

来源:SK海力士
但是SK海力士的现行 MR-MUF 工艺中,为去除 micro-bump 周围的氧化膜仍需涂布助焊剂(Flux);若清洗后残留物存在,就可能影响良率——这也是 Fluxless 被研究的重要原因之一。
据Dealsite的报道,半导体业内一位相关人士表示:“SK海力士为了在 HBM4 16层上导入Flxless键合,从去年第四季度开始进行了正式评估。虽然此前曾向 ASMPT 下达过支持 Fluxless 的 TC Bonding 设备订单,但评估结果显示,在当前的良率压力与成本天平上,成熟工艺的惯性依然强大。
这句“还早”,也意味着Fluxless 在量产这关,遇到了比想象更难的现实问题。
从逻辑上看,如果连“过渡性质”的 Fluxless TCB 在 HBM4/16H 这一代都被谨慎对待乃至延期导入,那么更终极的互连技术——混合键合,在 HBM 体系内实现全面规模化的节奏,大概率也会更保守。混合键合不仅昂贵,还需要全新设备、材料与测试流程重构;首批采用它的产品单封装成本势必抬升(尽管容量提升可能摊薄每比特成本)。因此,这一趋势更像是对产业的提醒:混合键合方向不会变,但“从路线图走向大规模量产”的时间表可能被拉长。
这场互连路线的节奏变化,并不只发生在技术论文与路线图里,也正在传导到设备采购层面。
设备商的分野
随着HBM4 16层标准高度的放宽,键合设备市场不再是一场简单的“全速冲刺”,而演变成了一场关于技术节拍、量产良率与供应链博弈的深度对垒。
1. BESI:混合键合的“终局信仰者”
在全球设备链中,BESI 往往被视为混合键合产业化的“风向标”。BESI 坚信:随着 I/O 密度继续上升、microbump 的物理极限逼近,真正的 3D 集成必须走向 Hybrid Bonding at scale。也正因此,BESI 的技术与市场策略更偏向“提前卡位终局”——尽可能把混合键合的节拍、精度、平台化能力提前打磨出来,等待 HBM5 或 20 层+时代的临界点到来。这里也需要强调一点:BESI 并非只押注混合键合。在 HBM4 仍以 microbump/TCB 为主的现实中,BESI 同样拥有热压键合与高精度贴装等关键产品线。
然而,终局的正确无法抹平短期的震荡。JEDEC对HBM4模块高度的宽容,给了微凸点技术更长的生命周期,也让BESI不得不面临“领先半步是先驱,领先一步是先烈”的风险。其2025年前三季度订单总额(4.346亿欧元)同比下降6.5%,揭示了混合键合的导入节奏慢于预期。尽管第四季度收到预期中的HB订单,但BESI可能正在经历一场艰难的“黎明前守望”。
2. ASMPT:TCB的“现实主义进化派”
与 BESI 相比,ASMPT 在 HBM 产业链里更像“现实主义工程派”:它并不否认混合键合的重要性,但更强调在当下的量产窗口期,TCB 仍是 HBM 堆叠的核心工艺平台——尤其在 12层 到 16层的过渡阶段。
ASMPT 推动的 Fluxless 方向(例如 AOR:等离子体主动去氧化)本质上是回答一个量产问题:在不推翻 microbump/TCB 体系的前提下,如何把界面做得更干净、更稳定、更可复制?这条路线比混合键合更容易向下兼容现有产线,并且更贴近客户眼前的 KPI:良率、节拍、TCO、可靠性。
在业绩方面,ASMPT 的先进封装业务在 2025 年上半年收入占比提升至约 39%(约 3.26 亿美元),明确受 AI 需求拉动。更值得注意的是其在 TCB 订单上的连续加码:2025年12月3日,ASMPT 宣布从一家领先代工厂的主要 OSAT 合作伙伴处获得 19 台芯片到基板(C2S)TCB 新订单;2025年12月22日,ASMPT 又宣布追加获得 15 台用于尖端 AI 计算芯片的 C2S TCB 设备订单。
同时,ASMPT 预计到 2027 年,TCB 总潜在市场规模(TAM)将超过 10 亿美元,并称已做好战略布局,目标占据 35%~40% 的市场份额。
3. 两家韩国公司:韩美半导体与韩华
作为SK海力士最核心的设备供应商,韩美半导体(Hanmi)是“改良路线”中最具实战经验的玩家。其核心王牌是Dual TC Bonder。不同于传统的NCF(热压非导电膜)路线,韩美通过优化的TCB设备,完美配合了SK海力士的MR-MUF(批量回流模塑底填)工艺。在16层HBM4时代,韩美正紧锣密鼓地开发下一代TC键合设备,试图将生产效率和散热稳定性推向极致。对于SK海力士而言,只要MR-MUF能走通,韩美的设备就是其守住HBM王座的最强屏障。
韩华精密机械(Hanwha)是韩系供应链中的最大变量,是志在搅局的“后起之秀”。由于不甘心韩美在海力士供应链中的垄断地位,韩华在2025年加速了针对HBM4的TC键合设备开发。韩华的策略是“多点布局”:一方面利用其精密机械制造能力追赶TCB的高产出率;另一方面,它正秘密研发适用于16层以上的无助焊剂工艺。韩华的入局,本质上是SK海力士为了分散供应风险、压低设备成本的一种战略扶持。
不过近期,这两家公司正在打专利战。据朝 鲜日报英文站报道:韩美在 2024 年 12 月提起诉讼,争议聚焦 HBM TCB/TC bonder 关键技术。据TrendForce 和 DIGITIMES等的报道,部分观点认为ASMPT拿到SK海力士的订单与韩美韩华纠纷有关。但同时,DealSite提到另一种解释:ASMPT在 fluxless bonding TCB 设备方面有优势,且这批设备可能属于既定供应计划。
4. Kulicke & Soffa (K&S):工艺延续下的“基石守护者”
当Fluxless成为中场休息的避风港,K&S这种拥有高稳定性、大规模制造经验的老牌巨头,便成了产线不可缺的“基础设施”。2025财年第四季度,K&S以1.776亿美元营收和45.7%的毛利证明了其经营韧性。
据semiengineering的报道,Brewer Science 的 Hamed Gholami Derami 指出:“并不是 HBM 中所有互连都会变成混合键合。企业正在探索方案:DRAM die 之间采用面对面混合键合形成配对,再将这些配对结构用微凸点背靠背堆叠。”这是一种折中路线,意味着 TCB 与 MR 设备在相当长一段时间里仍将留在牌桌上。
总的来看,在键合设备领域,BESI握住了通往未来的钥匙,ASMPT和韩美半导体掌控着当下的钱袋子,而韩华正在试图定义新的平衡。在16层HBM4这一战中,谁能把现有的Microbump工艺做到极致,谁才是真正的盈利之王。
结语
Fluxless 的延期,不是技术的失败,而是工业的现实。它提醒我们:当互连间距进入 10µm 级别,封装不再是“把芯片粘在一起”那么简单,它变成了一个集洁净度、材料学、热管理、计量检测、工艺窗口于一体的系统工程。任何一条链路不够成熟,都可能让先进工艺从“看起来很美”变成“算不过账”。
SK 海力士选择继续 Advanced MR-MUF,不是因为 Fluxless 没价值,而是因为在 HBM4 这一代,“更稳的方案”比“更先进的方案”更重要——它必须先确保 16 层能稳定出货,让 GPU 有足够的 HBM 能喂饱算力。
但这并不意味着终局远去。混合键合依然是那座绕不开的高山,只是它不会以革命的方式突然降临,而更可能以渐进、混合、折中的方式悄然渗透:先在局部关键互连上落地,再逐步扩展到更大范围。
先进封装这场战争,最残酷的一点就在于:技术进化永远不会停,但每一步进化,都必须通过量产的审判。
