

最近一年来,半导体IP市场的三场地震,彻底撕开了生成式 AI 对底层架构重塑的深层逻辑。第一场震动来自Rambus,这家存储接口巨头,其股价在2025年间完成了近乎翻倍的飞跃,成为 AI 服务器产业链中不可或缺的“黄金节点”。第二场震动来自 Synopsys(新思科技),作为 EDA 与 IP 界的双巨头之一,它果断选择剥离旗下的处理器 IP 明星业务 ARC,将其整体出售给晶圆代工厂格芯(GlobalFoundries);第三场震动是曾誓言要颠覆高速互连格局的 Alphawave Semi,最终在2025年底接受了Qualcomm(高通)的全资收购。
一个被重估,一个被抛售,一个被吞并。这三面镜子,映照出AI时代半导体行业最残酷的真相:计算权力的王座正在发生偏移。
Rambus 的“翻红”
长期以来,Rambus在半导体圈的名声并不算好。它曾因通过密集的专利诉讼向各大存储器厂商收受“买路钱”而被贴上“专利流氓”的标签。然而,AI 时代的降临,让这家深耕高速接口技术的公司完成了一次华丽转身。
截至2026年初,Rambus股价已站上约115–125美元高位,并一度触及 135 美元的区间高点,过去一年累计涨幅接近 100% 左右,在市场上表现异常抢眼。投资者对此既看到了 AI 时代对其技术的需求提升,也反映出市场对其未来增长路径的预期显著改变。
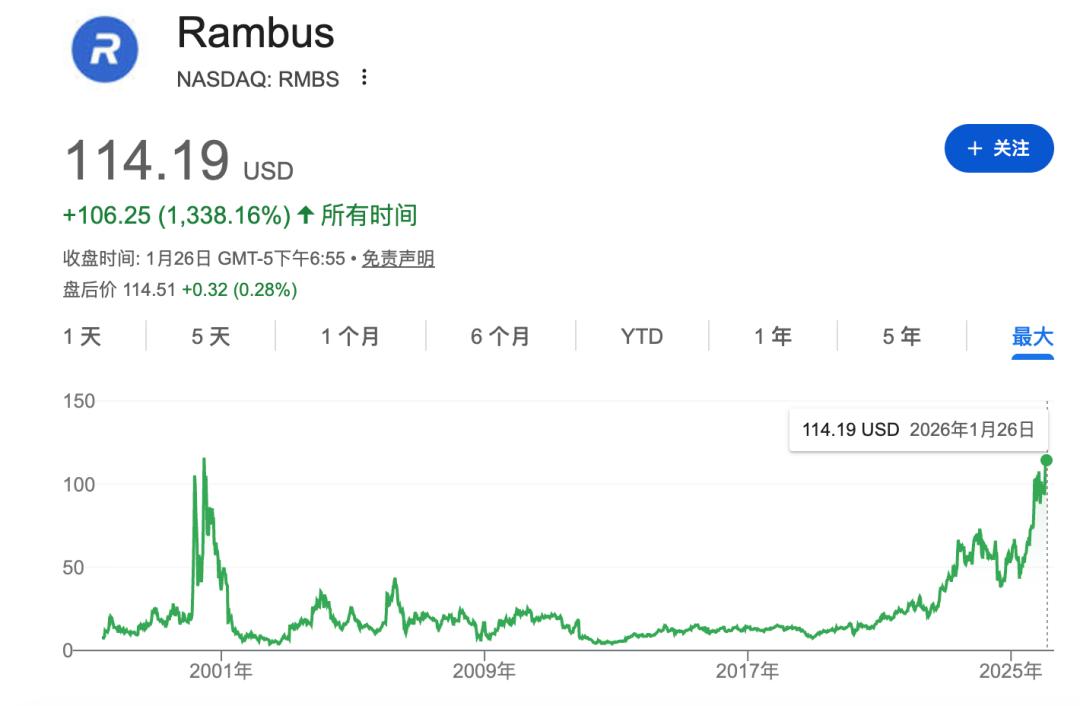
Rambus股价走势一览
在此过程中,包括贝德(Baird)在内的投行分析师多次上调 Rambus 的目标价至约 120–130 美元区间,认为其不仅脱离了过去单纯依赖专利授权的商业模式,而且在 AI 和数据中心基础设施中占据了更为核心的位置。
其中一个重要的转折,是Rambus在过去两年内对自身产品线和业务重心的战略调整。例如,2023年公司将部分SerDes与内存接口 PHY IP 资产出售给Cadence,进而释放资源专注于高性能内存子系统解决方案与安全 IP 等领域。
为何市场开始重新定价 Rambus?
核心在于,AI 算力现在最大的痛苦不是GPU不够快,而是数据传不过去。AI模型的训练本质上是极大规模的矩阵运算。以GPT-4或更先进的O1模型为例,数据需要在处理器(GPU/NPU)与存储器(HBM/DDR5)之间进行极其频繁的交换。由于内存墙的存在,数据的传输一直困扰着行业。
在当前的系统架构需求变化中,Rambus抓住了三个命门:
DDR5 RCD 接口芯片: 随着 AI 服务器全面转向 DDR5 标准,Rambus 的RCD(寄存器时钟驱动器)芯片是不可或缺的组件。它就像是内存条上的“交通指挥官”,确保万亿级数据在高频下不跑偏。Rambus 在这一细分市场长期占据领先地位,据业内统计其市场份额超过40%。
HBM4控制器 IP: HBM(高带宽内存)是 NVIDIA H100/H200 等芯片的灵魂。Rambus 率先推出了 HBM4 物理层和控制器 IP,这意味着任何想做 AI 加速器的公司(如 AWS、谷歌自研芯片),都很难绕开它的授权。
MRDIMM(多级秩缓冲内存模块): 这是 2026-2027 年的爆发点。MRDIMM 能让服务器内存带宽再翻倍,Rambus 预计在这个价值6-7亿美元的新细分市场中继续拿走 40% 以上的份额。
2025年财报显示,Rambus的产品收入录得42%的惊人增长,其核心驱动力正是AI服务器对DDR5内存接口芯片(RCD)的需求。Rambus的HBM3E/4接口IP能够提供超过 1.2 TB/s 的吞吐量,这已成为 AI 加速器的标配。此外,随着AI模型资产价值飙升,Rambus 提供的硬件信任根(Root of Trust)技术也成了云厂商保护模型隐私的刚需。
ARC的“谢幕”
如果说 Rambus 的崛起代表了连接价值的跃迁,那么Synopsys卖掉ARC处理器业务,则代表了通用计算的平权。
ARC处理器曾是嵌入式领域的翘楚,长期盘踞全球IP出货量的前列。在微控制器(MCU)和早期SoC时代,ARC的低功耗与可定制性是其杀手锏。ARC 处理器属于典型的通用CPU 架构。在过去二十年,这种“万金油”式的架构是芯片设计者的首选,但在生成式 AI 的重压下,它的效率显得捉襟见肘。
在 AI 芯片中,90%的晶体管被分配给了张量处理单元(TPU/NPU)和缓存。传统的 CPU(如 ARC)从决策核心退化成了负责任务调度、输入输出处理的“领班”。当“大脑”不再是性能瓶颈时,客户对通用 CPU IP 的付费意愿开始下降。
真正让ARC这种闭源处理器IP感到窒息的,是RISC-V的架构平权。AI 厂商需要根据自己的算子(Kernels)去定制指令集。RISC-V 的开源特性允许开发者自由添加矩阵扩展,而无需支付高昂的架构授权费。维护一个庞大的处理器 IP 生态,意味着要养活庞大的编译器团队、中间件支持团队,还要应对RISC-V开源浪潮的低价冲击。
在ARM几乎垄断、RISC-V疯狂追赶的夹击下,Synopsys 意识到,与其在红海中挣扎,不如“腾笼换鸟”,去掘金AI的新基建。它将资金和研发精力全力压向了两个方向:第一是AI增强型 EDA(DSO.ai),用 AI 来设计芯片。这是Synopsys利润率最高的未来支柱;第二是与Ansys的超级合体,2025 年,Synopsys 完成了对仿真巨头Ansys的世纪收购,加强系统级仿真的能力。它要让英伟达、谷歌在芯片还没下单给台积电之前,就能在数字世界里模拟出数万个计算节点的散热、应力和信号完整性。
这场地震撕开了一个行业真相:IP市场的价值正在从内核向周边转移。过去,大家买的是 CPU内核;现在,大家抢的是把这些核心连在一起的协议(UCIe/PCIe 7.0)、解决数据吞吐的接口,以及优化整体功耗的仿真工具。
另一边,对于全球第三大晶圆代工厂格芯而言,接手ARC处理器IP并非在捡废品,而是在补齐生存短板。格芯深知,自己已退出7nm及更先进制程的“烧钱竞赛”,其核心战场在于 22nm到12nm的成熟/特色工艺。格芯需要ARC,有了自己的处理器 IP,格芯就能向那些预算有限、研发能力薄弱的中低端客户提供“全家桶”服务。客户不需要再去向第三方买授权,在格芯家里就能完成从设计到流片的闭环。
这也有助于格芯吸引长尾客户,那些做智能家电、低端车载传感器、工业控制器的厂商,并不需要3nm的AI算力,他们需要的是便宜、稳定、成熟的交钥匙方案。
这更像是一场“阶级固化”的交接:新思科技向上走,去赚 AI 时代最顶层的软件溢价和系统门票;格芯在成熟制程里,靠提供更全面的“保姆式服务”来守住阵地。
Alphawave的“卖身”
Alphawave Semi最初叫 Alphawave IP。正如其名,它是一家纯粹的 IP 供应商,核心拳头产品是 SerDes(解复用器)。这是一种让数据在芯片内外进行超高速传输的关键技术。在那个阶段,它被视为“接口 IP 领域的兰博基尼”,专门挑战 Synopsys 和 Cadence 的领地。
2022 年,它更名为 Alphawave Semi,去掉了“IP”二字。这标志着它不再满足于只卖图纸。通过收购 OpenFive(SiFive 旗下的定制芯片业务),它获得了设计完整 SoC的能力。高通(Qualcomm)在 2025 年底完成了对 Alphawave Semi 的收购。这一举动正式终结了其作为独立 IP 公司的身份,使其成为高通进军数据中心和 AI 基础设施的核心连接技术部门。
Alphawave Semi吸引高通的价值主要有两点:一是随着芯片面积逼近光掩模极限(Reticle Limit),单体大芯片(Monolithic)已经走到了尽头。AI 厂商必须通过 Chiplet(芯粒) 技术,将不同的功能单元拼装在一起。这其中最核心的“胶水”,就是 Alphawave 擅长的 UCIe(通用芯粒互连)。
二是随着 AI 模型规模爆炸,交换机速度正从 800G 向 1.6T 演进。,224G SerDes是 AI 交换机迈向 1.6T 时代的门票。Alphawave 在这一领域的领先优势,使其成为了所有云厂商(AWS、Google、Meta)的共同座上宾。
高通收购 Alphawave,是一场蓄谋已久的战略偷袭。长期以来,高通被困在移动端的辉煌里,难以切入高性能计算(HPC)和 AI 数据中心市场。AI 芯片不再是单打独斗,而是上千颗芯片的集群,Alphawave拥有的 UCIe(芯粒互连标准) 和2nm/3nm 高速接口技术,正是高通进军高性能计算(HPC)最缺的那块拼图。收购Alphawave,让高通瞬间拥有了与博通(Broadcom)、英伟达在数据中心互连协议上一较高下的本钱。
Alphawave 的消失,证明了高速互连 IP 的门槛之高,在AI时代的军备竞赛中,中等规模的、技术单一的IP公司正逐渐丧失独立生存的土壤,而必须成为垂直巨头手中最锋利的矛。
计算平权与连接崛起
在过去几十年的计算机体系结构演进中,从CPU主频竞争,到多核架构,再到GPU并行计算,产业长期遵循的是一套“计算中心主义”范式——谁拥有更强的计算核心,谁就掌握系统性能的天花板,也就拥有产业的话语权。
但生成式 AI 的出现,正在动摇这一长期成立的前提。
在大模型负载下,系统的性能函数正在发生结构性变化:过去,系统性能近似等于计算能力,而现在,系统性能的表现需要综合考虑多个指标,由「计算能力,内存带宽,互连带宽,系统延迟,能效约束」由“最慢的一环”决定。
随着制程工艺、EDA 工具链、编译器技术和软件栈的成熟,越来越多的厂商具备了设计可用 AI 加速器的能力,单一计算单元的技术壁垒正在下降。这并不意味着计算不重要,而是意味着:计算能力正在从“决定性竞争优势”,转变为“基础设施型能力”。换句话说,算力正在走向“平权化”。
需要强调的是,“计算平权”并不意味着计算变得不重要。恰恰相反,计算依然是 AI 系统的基础,但它不再是唯一的权力来源。
当计算能力趋于基础设施化,新的权力中心正在转移到数据通路。在 AI 系统中,数据流动路径包括:处理器与HBM/DDR之间的内存通路、Die与Die之间的互连、Chiplet之间的通信、板级高速 SerDes、节点之间的网络交换。。。。。这些路径共同构成了AI系统的“血管系统”。一旦这些通路出现瓶颈,再强的计算核心也只能空转。因此,掌握这些数据通路关键技术与标准的公司,开始站上系统权力结构的高位。
具体到IP这个细分市场,IP市场的价值正在从内核向周边转移,所以近几年,一路高歌猛进的都是接口IP厂商。根据 IPnest 的行业监测,半导体 IP 市场的版图正在发生结构性重组:处理器 IP(如 CPU/GPU 内核)的市场份额已从 2017 年的 57.6% 持续下滑至 2025 年的不足 45%。与此同时,接口 IP 的份额却从18%逆势增长,预计到2026年将占据整个IP市场的“四分之一强”。当传统 IP 市场维持在 8%-10% 的常规增长时,以 高速 SerDes、PCIe 6.0/7.0、HBM 控制器为代表的接口 IP 细分领域,正以超过 20% 的复合年增长率(CAGR)狂飙。
从更长周期看,半导体 IP 市场的竞争焦点,将越来越集中在接口、互连与系统级能力,而不是单一计算内核的性能高低。
