

今年英伟达 GTC 主题演讲,应该是史上悬念最少的一届。
2022 年说元宇宙,2023-2024 年说生成式 AI,2025 年说物理 AI。但今年不一样,即便台上英伟达创始人黄仁勋的演讲还没有开始,但台下所有人已经知道答案了——Agent。

包括英伟达也悄悄在 GTC 园区里开设了「Build-a-Claw」互动专区,让与会者现场搭建自己的AI Agent。 从芯片到模型,从英伟达版龙虾到数据中心,今年主题演讲的潜台词只有一句话:
一切都要为 Agent 让路。

专为 Agentic AI 打造的 Vera Rubin 正式发布
如果说 Hopper 架构开启了生成式 AI(Generative AI)的时代,让机器学会了「说话」;那么 Vera Rubin 的使命,就是开启智能体(Agentic AI)时代,让机器学会「干活」。

英伟达 Vera Rubin 架构包含七款芯片、五套机架系统,以及一台用于 AI Agent 的超级计算机
七款芯片分别是 NVIDIA Vera CPU、NVIDIA Rubin GPU、NVIDIA NVLink™ 6 交换机、NVIDIA ConnectX-9 超级网卡、NVIDIA BlueField-4 DPU 和 NVIDIA Spectrum™-6 以太网交换机,以及新集成的 NVIDIA Groq 3 LPU
五个机架分别是 NVIDIA Vera Rubin NVL72 机架、NVIDIA Vera CPU 机架、NVIDIA Groq 3 LPX 机架、NVIDIA BlueField-4 STX 存储机架,以及 NVIDIA Spectrum-6 SPX 以太网机架。
过去的 AI 像是一个极其聪明的图书馆管理员,我们问一个问题,它慢条斯理地翻书,然后把答案整理出来。我们对这种速度是宽容的,因为我们自己打字看书也慢。
但 Agent 完全不同。它不仅要用大模型思考,还要疯狂地调用工具——比如打开浏览器、控制云端的虚拟 PC、在无数个数据库里来回比对。更要命的是,AI 对工具的容忍度极低,它要求一切操作都在毫秒级完成。
「它会狠狠地捶打内存。」黄仁勋在台上这样形容。

当模型越来越大,上下文长度从十万 Token 飙升到数百万,还要同时处理结构化和非结构化的数据,传统的算力架构开始喘不过气了。为了应对这种「捶打」,英伟达交出了第一份答卷,全新的 Vera CPU。
这颗芯片特立独行,它是世界上首款专为智能体 AI 和强化学习时代打造的处理器,其效率是传统机架式 CPU 的两倍,速度提升 50%,采用 LPDDR5X 内存,能实现极高的单线程性能、大型的数据吞吐量和极致的能效。
黄仁勋甚至毫不掩饰他的骄傲:「我们从没想过会单独卖 CPU,但现在,这绝对是一个价值数十亿美元的业务。」

紧随其后的是 Rubin GPU,单片芯片直接塞进了高达 288 GB 的海量内存。它就像是一个拥有无限脑容量的思考者,专门用来装载那些体积越来越庞大的超大语言模型,以及处理成百上千万的上下文 KV 缓存。
除了堆叠 CPU 和 GPU,英伟达这次发布的 Vera Rubin 架构,直接把 NVLink 的带宽翻了一倍——260 TB/s 的全互联带宽。
十年前,DGX-1 用第一代 NVLink 把 8 张卡连在一起,那是专为 AI 研究员打造的奇迹;到了 Hopper 时代,是 NVLink 4;而前不久的 Blackwell 架构,用 NVLink 72 实现了 72 张 GPU 的全互联,带宽达到 130 TB/s。
为了配合 Vera Rubin,黄仁勋甚至掏出了被称为 Kyber 的全新机架。在这个机架里,计算节点垂直插入,背后是第六代 NVLink 交换机。完全抛弃了传统的以太网或 InfiniBand 限制,在一个 NVLink 域内直接打通 144 张 GPU。

即便强如 Vera Rubin,在面对「无限生成 Token」的极端需求时,也会感到吃力。
在算力世界里,吞吐量(Throughput,同时处理巨量任务的能力)和延迟(Latency,单次任务的极速响应)是一对物理学上的死敌。英伟达是吞吐量的绝对霸主,但在极致低延迟的 Token 生成上,传统 GPU 架构显得过于笨重。
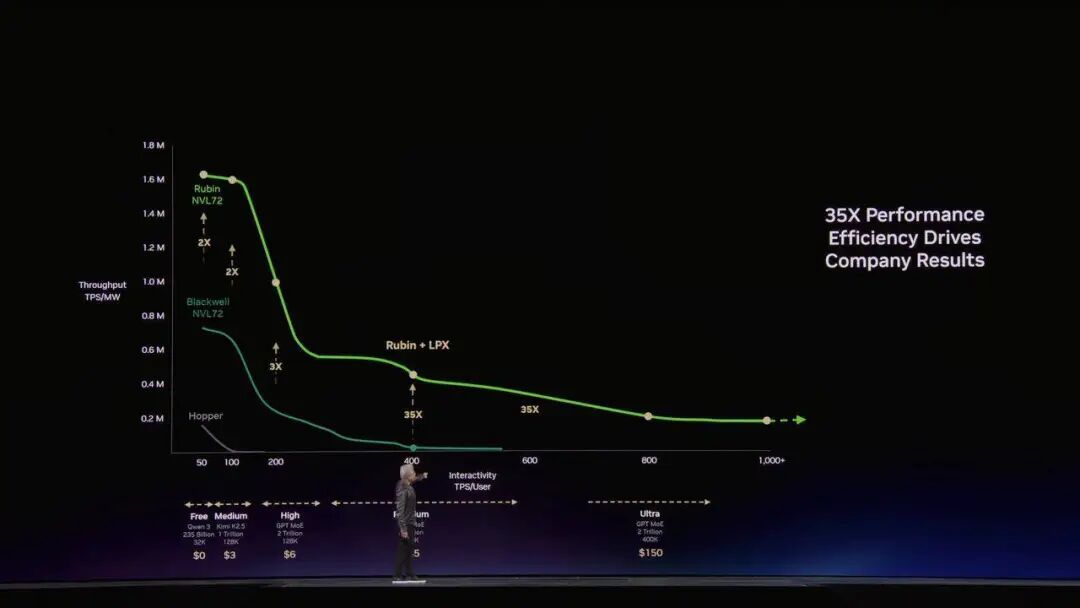
这时候,Groq 出场了。英伟达早在之前就「收购」并授权了 Groq 团队的技术,在今天正式推出了 Groq LPU(语言处理单元)。
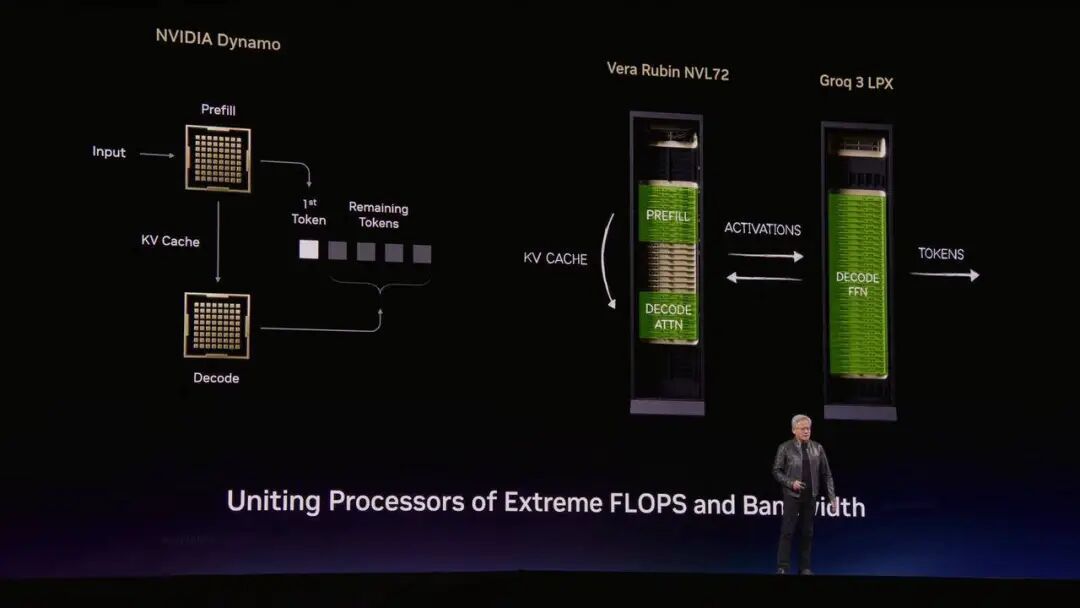
黄仁勋用一款名为 Dynamo 的软件,把这两者完美捏合,首创了「解耦推理(Disaggregated Inference)」。
AI 推理前半段的 Prefill(预填充)和极其耗费算力的 Attention(注意力机制),全部交给 Vera Rubin 这个性能王者来处理;
后半段的 Decode(解码),也就是生成 Token 的瞬间,直接卸载给 Groq LPU 来降低延迟。

结果显示,在最具商业价值的高端推理层级,这种组合让性能直接飙涨了 35 倍,且每兆瓦的吞吐量同样提升了 35 倍。
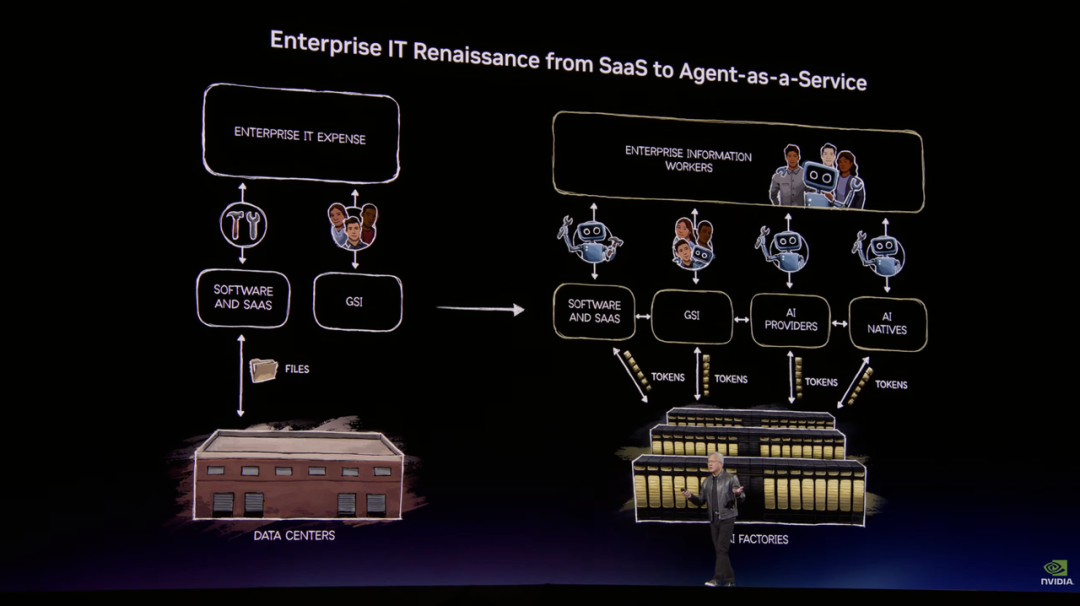
一个开源项目,让所有 CEO 都睡不着觉
主题演讲的后半部分,黄仁勋抛出了一个让全场屏息的判断:OpenClaw,将堪比这个时代的 Linux,是这个时代的 HTML。
OpenClaw 上线仅数周,下载量和影响力已经超过了 Linux 三十年的积累,其本质上是一套智能体操作系统。它能调用大模型、管理文件、拆解任务、协调子智能体,还能发邮件、发短信,以任何模态与人沟通。
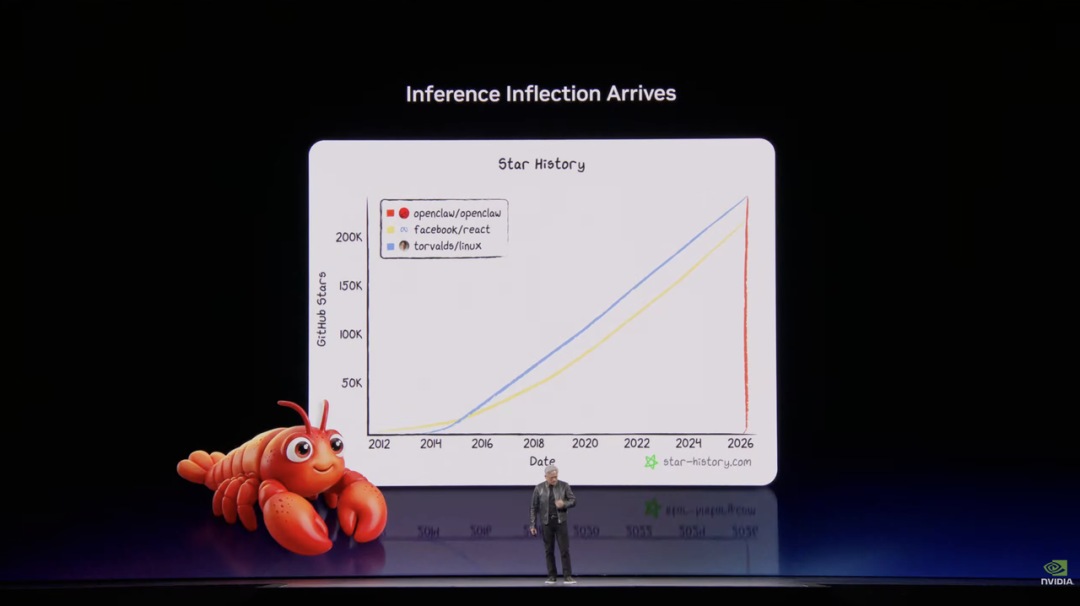
在黄仁勋看来,每一家 SaaS 公司,迟早都会变成 AgaaS 公司,也就是「Agent-as-a-Service(智能体即服务)」公司。而每一位 CEO 现在都必须回答同一个问题:你的 OpenClaw 战略是什么?
当然,开源意味着自由,但企业更需要的是安全。这也是 OpenClaw 规模化落地前最大的障碍。
为此,英伟达联合以 OpenClaw 创始人 Peter Steinberger 为代表的团队,召集了一批顶级安全与计算专家,推出 NeMoClaw 参考架构。
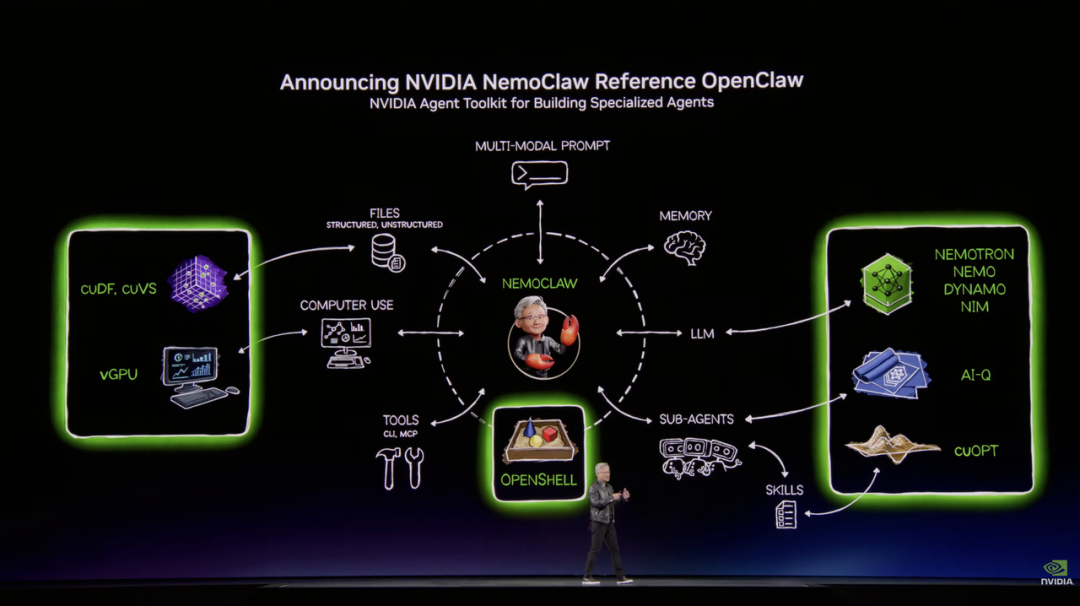
它内置 OpenShell 技术、网络防护机制和隐私路由能力,可以让企业可以在自己的私有环境中安全运行智能体系统。
而支撑这套智能体生态的,是英伟达一整条开源模型产品线。
比如 Nemotron 主攻语言推理,Cosmos 聚焦世界建模,Groot 面向通用机器人,Alpha Mayo 服务自动驾驶,BioNeMo 深耕数字生物学,Earth-2 则专注 AI 物理仿真。
黄仁勋特别强调,这些模型不只是排行榜上的名字。英伟达会持续投入推进,Nemotron 3 之后有 Nemotron 4,Cosmos 1 之后有 Cosmos 2,每一代都会更强。

更重要的是,这些模型全部以基础模型形式开放,任何企业都可以在此基础上继续微调和后训练,打造专属于自己业务场景的定制化智能。英伟达还宣布将与各地区合作伙伴协作,帮助不同国家和市场孵化本土化 AI 能力。
在台上,黄仁勋还宣布了一份让人眼前一亮的合作名单。Black Forest Labs、Cursor、LangChain、Mistral、Perplexity、Sarvam,以及 Mira Murati 创立的 Thinking Machines,悉数加入,共同推进 Nemotron 4 的研发。

划重点,英伟达不甘心只做卖铲人,更要亲自下场带头挖金矿,更重要的是,英伟达也是在构建一个生态,一个围绕智能体时代的完整体系。
玩家的显卡钱,是一场长达 25 年的「众筹」
要理解英伟达今天的恐怖统治力,黄仁勋首先把时钟拨回了 25 年前。
那时候没有 ChatGPT,没有大模型,只有一群为了让游戏画面更流畅而疯狂攒机的年轻人。「GeForce 是英伟达有史以来最伟大的营销活动」,黄仁勋在台上笑着说。
黄仁勋非常直白地承认,GeForce 就是用来吸引未来客户的。他们在我们还买不起企业级产品的时候,通过游戏显卡潜伏进我们的电脑。日复一日,年复一年。

也正是依靠一代代游戏玩家的「供养」,英伟达在 20 年前做出了一个当时看来堪称疯狂、甚至差点拖垮公司利润的决定——研发 CUDA,并将它送到了全世界每一个开发者的桌面上。
这可以说是一个在黑暗中蛰伏的故事。连续 13 代架构,长达 20 年的死磕,英伟达彻底把 CUDA 变成了一个装机量过亿的庞然大物。
这也解释了为什么当深度学习的「宇宙大爆炸」来临时,Alex Krizhevsky 和 Ilya Sutskever 们环顾四周,发现除了英伟达的 GPU,他们别无他选。

Nvidia 不是碰巧站在了风口上,而是花了 20 年时间,自己造了一台造风机。
飞轮一旦转动,就再也停不下来了。因为在这个飞轮里,硬件只是载体,真正黏住开发者的是那成千上万个工具、框架和开源项目。
既然当年是 GeForce 游戏显卡把 AI 算力(CUDA)带给了这个世界,那么十年后的今天,是时候让彻底长大的 AI,反哺它最初的「老家」了。

黄仁勋在台上甩出了惊艳全场的 DLSS 5。简单来说,英伟达正在用 AI 重新发明计算机图形学。传统的 3D 渲染是「结构化数据」,它是死板的、百分百可控的;而生成式 AI 是「概率性计算」,它是天马行空、极其逼真的。
以前这两派路线完全不同,但在 DLSS 5 里,英伟达硬是把它们揉在了一起,用可控的 3D 数据打底,用生成式 AI 去脑补和渲染细节。我们看到的画面,既不会出现 AI 经常犯的幻觉错位,又拥有近乎现实的惊人质感。
「生成出来的世界,变得极其美丽,同时又完全受控。」
但这也不只是一帮极客为了高帧率打游戏搞出来的炫技。黄仁勋说,这种将「结构化数据」与「生成式 AI」融合的逻辑,将会在每一个行业里一遍遍重演。

「这是我最喜欢的一页 PPT」
在演讲的高潮,黄仁勋放出了一张极其复杂的架构图,说这是他最喜欢的一页 PPT。接着,他又半开玩笑地说,团队屡次劝他别放这张图,但他偏要放,「反正你们有些人也是免费进来的,这就是门票钱」。
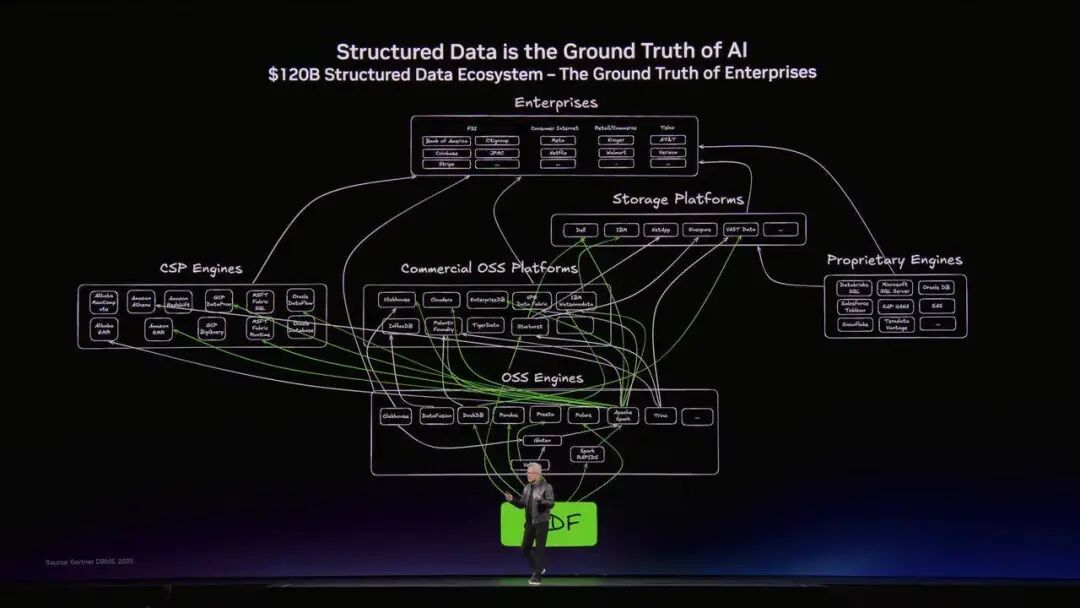
这张「最不听劝的 PPT」,真正揭示了英伟达接下来要吞噬的真正猎物,全球企业的数据中心。
过去,企业的数据分为两类。
一类是结构化数据,也就是常见的数据库 SQL、Pandas 里的那些庞大表格,它们是商业运转的地基。另一类是非结构化数据,比如海量的 PDF、视频、语音,占据了世界 90% 的信息,却因为难以检索而如同废纸。
过去几十年来,处理这些巨型 Excel 表格一直是 CPU 的绝对领地。当人类去查询这些表格时,CPU 的速度勉强够用。但黄仁勋一针见血地指出了未来的趋势,「未来,使用这些结构化数据库的,将是 AI Agents」。
当成千上万个不知疲倦的 AI Agent,以远超人类百万倍的速度同时向数据库发起查询时,传统的 CPU 计算系统连喘息的机会都没有,只会被瞬间压垮。
为了处理这个问题,英伟达掏出了第一把底层杀器:cuDF。它直接越过 CPU,用 GPU 的恐怖并行算力,把这群数据的处理速度拉爆。
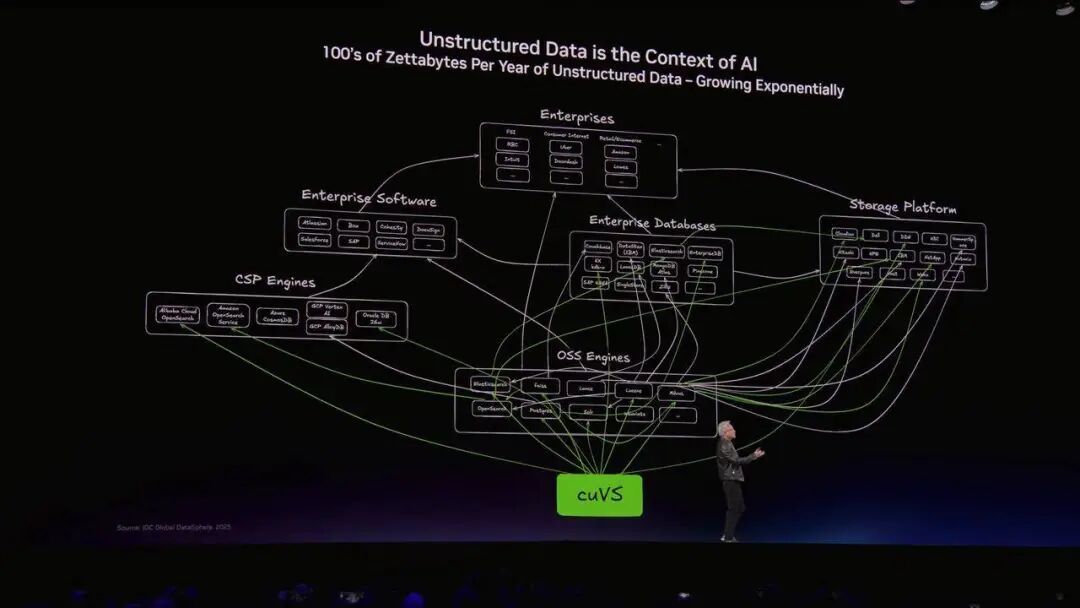
而针对非结构化数据,英伟达掏出了第二把杀器,针对向量数据库和非结构化数据的 cuVS。有了这两个底层库,英伟达实际上是捏住了全球数据处理的咽喉,它正在用 AI 的方式,重新定义企业到底该怎么处理数据。
两个工具库的效果也是相当明显。黄仁勋举了非常多合作伙伴的例子,其中提到雀巢公司每天要处理覆盖 185 个国家的庞大供应链数据,在换上英伟达加速的 IBM Watsonx.data 后,速度飙升了 5 倍,成本却骤降了 83%。
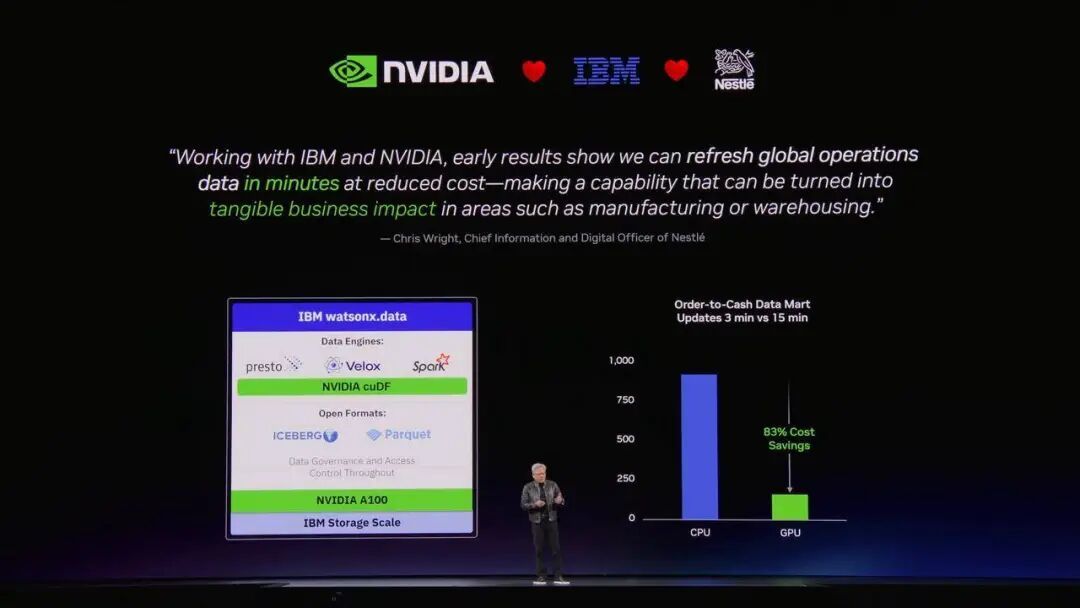
这就是「加速计算」的恐怖之处。当速度实现了几个数量级的跃升,成本就会呈断崖式下跌,新的商业模式就会在此刻涌现。
黄仁勋的演讲进行到这里,满嘴都还是「算法」、「库(Libraries)」和「数据帧」,他直言「英伟达是一家算法公司。」
英伟达将自己的算法库深度嵌入每一家云端,客户为了用 Nvidia 的算力和框架,才会去购买云服务。这也是为什么几乎世界上所有的云服务巨头——Google Cloud、AWS、微软 Azure、Oracle,都得排着队,把英伟达的服务请进自己的机房。

曾经呼风唤雨的云厂商,在加速计算时代,似乎都正悄然沦为英伟达庞大生态的「底层基础设施」和「分销渠道」。
英伟达为什么能做到这一切?黄仁勋给出了一个极度反常识的定义,英伟达是世界上第一家「垂直整合,却又水平开放」的公司。
向下,它自己造芯片、造系统;向上,它懂每一个行业的应用场景。
金融界的量化交易员在用它,医疗行业的医药研发在用它,连电信行业那个只会发射信号的基站,在未来也会变成运行 AI 算法的边缘计算节点。
英伟达甚至还推出了机密计算(Confidential Computing),让极其敏感的企业数据和模型可以在完全隔离的环境下运行,连操作员都看不到。这直接打消了巨头们拥抱 AI 的最后一点顾虑。

它把自己封装成一个个底层算法库,然后像水和电一样,悄无声息地接入了所有人的基础设施;看似把所有的利润都分给了生态伙伴,但实际上,英伟达已经牢牢掌握了整个 AI 时代的命脉。
1 万亿美元,而且还会供不应求
根据黄仁勋的判断,到 2027 年底,其 Blackwell 和 Rubin 芯片将至少创造 1 万亿美元收入。,而且这还是保守估计,实际计算需求会远超这个数字。
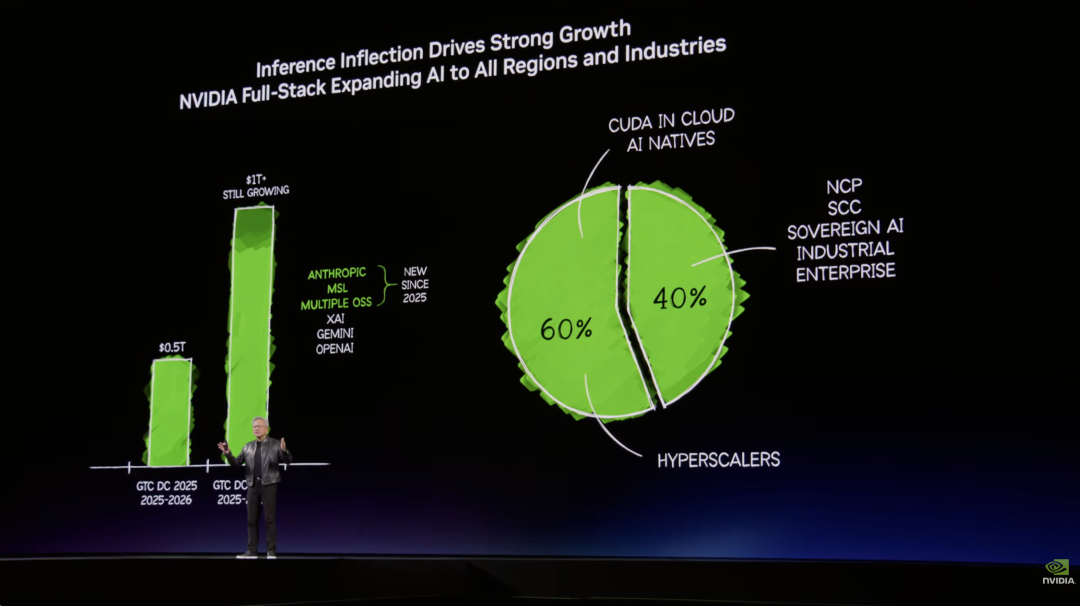
这个数字从何而来?答案藏在过去一年英伟达做的那件最重要的事里——AI 推理。
黄仁勋直言,很多人觉得推理很容易,但事实恰恰相反。
高难度推理是 AI 领域最难的事,也是最重要的事,因为它直接带来收入的增长。为此,英伟达在 Hopper 架构巅峰期做出大胆决定,彻底改变架构,打造出 NVLink 72,引入 NVFP4 精度格式,配合 Dynamo、TensorRT-LLM 及全套新算法,还专门建造了超级计算机来优化整套技术栈。
英伟达押注的结果,远超所有人的预期。
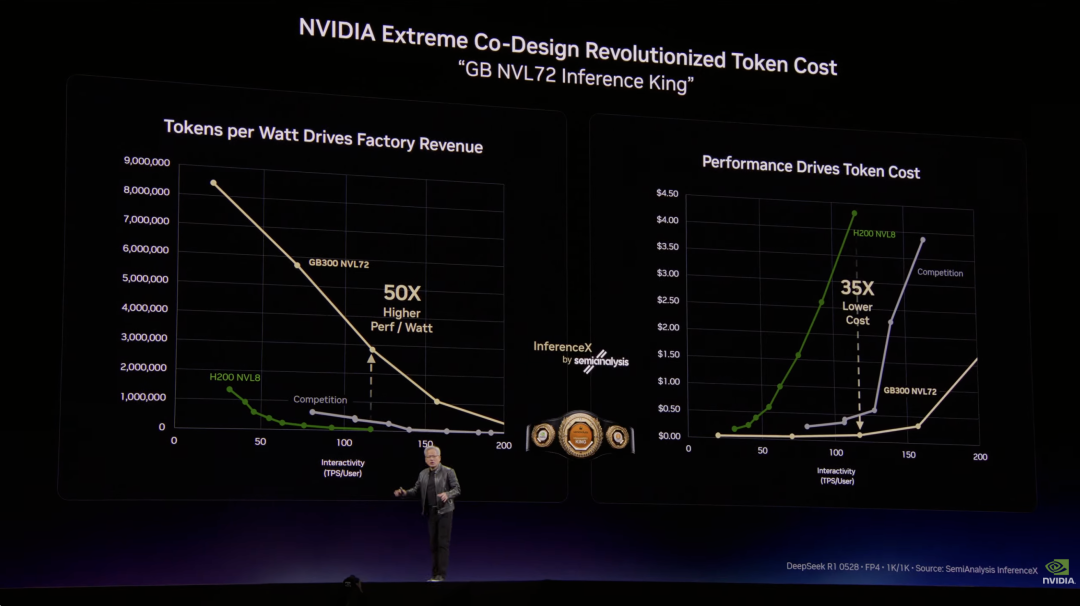
黄仁勋曾宣称 Grace Blackwell NVLink 72 每瓦性能提升 35 倍,当时没人相信他。后来 SemiAnalysis 发布评测报告,分析师 Dylan Patel 说黄仁勋说得太保守了,实际提升是 50 倍。

黄仁勋打趣道「Monkey King」「Token King」。
按摩尔定律,一代产品通常只能带来约 1.5 倍提升,没人预料到这次会是 50 倍。
性能提升之后,摆在面前的是另一个问题。一座 1 吉瓦数据中心,按 15 年摊销,建造成本就高达 400 亿美元,设备还没放进去。在这样的投入规模下,放进工厂里的计算系统必须是全球最好的,否则每一瓦浪费的电力都是真实流失的收入。
黄仁勋坦言,全球 AI 工厂里正有大量电力被白白浪费。
为此,英伟达发布了 NVIDIA DSX 平台,基于 Omniverse 数字孪生技术,让工程师在真正动工之前,先在虚拟空间里把整座 AI 工厂仿真一遍,从散热到电网,全部模拟清楚。
配合 Max-Q 技术,系统可以在功耗与算力之间实时动态调节。
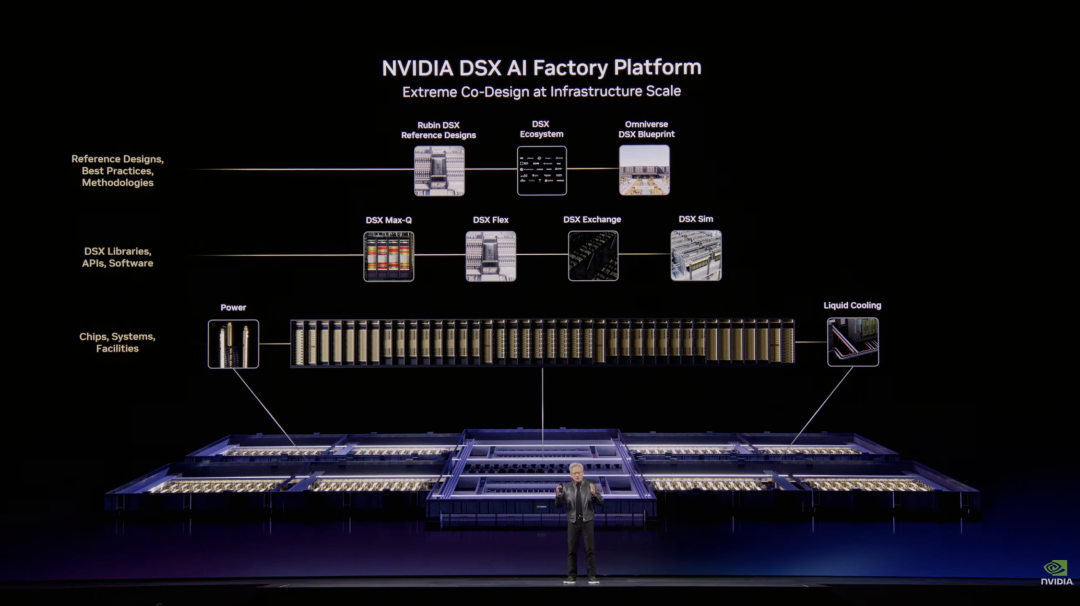
黄仁勋说,这里面至少还藏着两倍的优化空间。同一套硬件,英伟达更新算法与软件后,Fireworks 等服务商的 token 生成速度从每秒 700 个跃升至接近 5000 个,提升 7 倍。这就是「极致协同设计」的真实含义。
过去数据中心存放文件,现在它生产 token。土地、电力、机房空间决定了工厂上限,而架构优劣决定了产出多少。黄仁勋说,未来每一家公司都会认真思考自己 token 工厂的效率问题,因为算力,就是收入本身。
更重要的是,地球上的 AI 工厂还没建完,英伟达已经把目光投向了太空。
英伟达 Thor 芯片已通过抗辐射认证,率先应用于卫星之上。英伟达正与合作伙伴联合研发名为 NVIDIA Space-1 Vera Rubin 的新型计算机,目标是直接在太空中建设数据中心。

太空没有空气,无法对流散热,散热是一道极其棘手的工程难题。黄仁勋坦承这件事非常复杂,但他相信英伟达有足够优秀的工程师来攻克它。从地面到轨道,英伟达算力扩张的路线,仍在持续。
自动驾驶的 ChatGPT 时刻,已经到来
物理 AI 是未来十年最重要的课题,而黄仁勋用一句话宣告,自动驾驶的 ChatGPT 时刻,已经到来。
英伟达 RoboTaxi Ready 平台此次新增四位重量级伙伴:比亚迪、吉利、五十铃、日产,携手打造 L4 级自动驾驶汽车。
这四家车企每年合计生产约 1800 万辆汽车,体量惊人。加上此前已加入的梅赛德斯、丰田和通用,英伟达的自动驾驶版图已覆盖全球最重要的一批整车制造商。

英伟达还与 Uber 签署合作协议,计划将具备 RoboTaxi Ready(无人出租车就绪)能力的车辆部署至多个城市,并直接接入 Uber 的全球出行网络。
在工业机器人领域,英伟达与 ABB、Universal Robots、库卡等头部企业展开合作,将物理 AI 模型集成至仿真系统,推动机器人大规模进入制造产线。卡特彼勒的加入,意味着重型工程机械也开始走向智能化。

主题演讲的最后,依旧是经典的机器人环节。
近期,《冰雪奇缘》的雪宝机器人已经现身迪士尼海外游乐园,而这一次,它也迈着憨态可掬的步伐登上 GTC 2026 的舞台,和黄仁勋有来有往地对话,动作自然,反应流畅。

它的肚子里装着英伟达 Jetson 计算机,这是整套系统的大脑。它的步态和动作,全部在 Omniverse 虚拟环境中完成训练,靠的是由英伟达、迪士尼和 Google DeepMind 三方联合研发的 Newton 物理引擎,运行于英伟达 Warp 之上。
正是这套物理仿真系统,让雪宝在进入真实世界之前,就已经充分适应了现实物理规律。黄仁勋说,未来的迪士尼乐园所有角色都将拥有真正的智能,在园区里自由走动,与每一位游客展开真实的互动。

演讲开始的时候,黄仁勋说,我要提醒你们,这是一个技术大会。我们将要谈论技术,谈论平台,最重要的是,我们要谈论生态系统。
生态系统?他实在太谦虚了,用生态帝国也不为过,黄仁勋曾经用一块五层蛋糕来描述 AI 产业的结构:最底层是能源和芯片,往上是基础设施、模型,最顶层是应用。
每一层都不可或缺。这个比喻听起来像是在描述一个分工清晰、各司其职的产业格局。但当你把这块蛋糕从底看到顶,会发现每一层里都有英伟达的手笔。
从最早「潜伏」在玩家机箱里的显卡,到主宰全球云厂商的底层框架;从太空里的抗辐射数据中心,到迪士尼乐园里和我们谈笑风生的机器玩偶。
英伟达用 20 年时间造了一台造风机,如今这台机器已经化身为一台永不停歇的 Token 生产厂。在这个工厂里,算力即权力,生态即壁垒。
当所有的企业、用户都在为如何落地 AI 焦虑时,黄仁勋已经悄悄把通往 Agent 时代的门票,塞进了世界上每一台服务器的咽喉。
这场关于未来 AI 的赌局,英伟达不仅既做庄家又做玩家,它甚至要把牌桌都买下来了。
