

国产GPU的头部牌桌上,正在悄悄“加人”。
近来,据媒体报道,字节跳动正与天数智芯洽谈采购至少5万颗AI芯片,主要用于推理任务。本次洽谈涉及的芯片,主要为天数智芯智铠系列云端推理GPU,训练场景则使用天垓系列。

截图来源于媒体报道
消息一出,市场一片惊呼。毕竟,字节跳动可是国内AI算力的头号买家——2026年计划将资本开支上调超2000亿元。
不过,截至目前,字节跳动以及天数智芯方面暂未有所回应。
如果这笔买卖真能落地,天数智芯将成为继华为和寒武纪之后,字节跳动的第三大国产GPU供应商。
对于今年1月刚在港交所上市的天数智芯来说,这已不光是巨额订单的问题,更是获得了“大厂认证”。
但比订单更值得关注的,是这件事背后透出的信号——国产AI芯片正在从“政策采购、行业试点”,真正进入互联网大厂的应用场景,从备选方案转向刚需算力支撑。
01 不买不行了
字节跳动不是没有选择。
美国目前已在受控条件下批准部分中国企业购买英伟达H200,但H20的“后门事件”,让中国买家在采购时面临额外的合规和安全审查压力。不把鸡蛋放在一个篮子里,已经是国内大厂的基本操作。
更重要的是,字节跳动的算力需求正在发生结构性变化。
QuestMobile数据显示,截至2026年3月,字节跳动旗下AI智能助手豆包的月活用户已达3.45亿。用户增长带来的压力不仅来自模型训练,更来自上线后的持续推理成本。而推理场景对芯片的诉求,无论在互联带宽、显存还是生态成熟度上,都比训练要宽松一档。国产芯片在推理侧已经达到了可用水平。
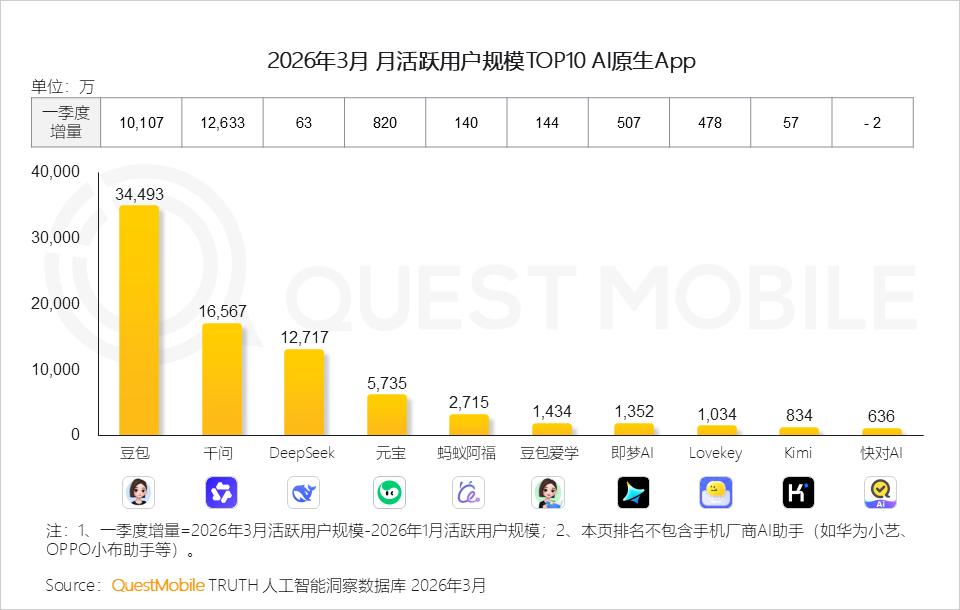
图片来源:QuestMobile
截至2026年3月,豆包大模型日均Token调用量突破120万亿,较上线初期增长千倍。按火山引擎定价及用户行为测算,每日算力消耗成本已达数千万元——这还不算智算中心与芯片采购等一次性投入。
尽管豆包2.0的推理效率提升43%,万Token成本仅为海外头部模型合规链路的38%,但面对3.45亿月活用户的免费使用,亏损缺口依然难填。
压力之下,字节跳动开启“豪赌”式加码。
据多家媒体援引《南华早报》消息称,2026年,字节AI基础设施资本开支预算上调约25%至2000亿元。此次上调主要受两大因素驱动:一是公司在人工智能领域投入持续增加,二则是内存芯片成本攀升。
更有消息称,字节跳动正考虑将2026年开支上限推至700亿美元。而在2025年,公司净利润同比缩水超70%。盈利与开支冰火两重天,张一鸣的算力豪赌,赌的或许是未来五年的身位。
字节跳动的算力供应链策略已经很清晰了:训练用华为昇腾、寒武纪高端训练卡,推理引入天数智芯智铠系列,三路并行。这种“训练、推理两条腿走路,国产、进口两手准备”的打法,正在成为互联网大厂的“标配”。
02 壁仞们的“朋友圈”
不过,就在字节跳动准备购买国产芯片的消息刷屏时,另一家国产GPU厂商的动作更值得关注。
6月16日晚,智谱正式开源新一代旗舰模型GLM-5.2。第二天,壁仞科技和摩尔线程就相继宣布完成“Day-0”适配。壁仞科技壁砺166系列基于vLLM推理框架完成适配与调优,率先向开发者提供快速部署方案。消息公布后,壁仞科技当天股价上涨7.09%。
截图来源于相关公众号推文
“Day-0适配”,是理解国产GPU竞争格局的关键——它不是能用,而是模型发布当天就能跑。这意味着芯片厂商不仅要硬件做得好,软件栈、工具链、开发者生态都得跟得上。而壁仞科技在这件事上已经具备明显的先发优势。
腾讯混元Hy3 preview、阿里通义千问Qwen3.6、DeepSeek全系模型、MiniMax M3、智谱GLM全系列、月之暗面Kimi等20余款国内头部大模型,均完成壁仞科技芯片Day-0级同步适配。其中最值得一提的是DeepSeek,有消息称壁仞仅用数小时就完成了全系列适配,创下了国产芯片响应速度的纪录。
如果把这份适配名单和字节跳动的供应商名单放在一起看,一个清晰的信号浮现出来:壁仞科技已经可以和华为、寒武纪站到同一队列了。
华为是早就在主位上坐稳的那个,昇腾的生态厚度和万卡集群能力,至今仍是其他国产厂商难以企及的标杆;寒武纪入局商用市场较早,且已稳定向字节跳动供货,是大厂算力供应链的核心玩家;壁仞科技则凭国家级认证、资本青睐及大模型生态布局,拿到同等席位,成为新晋力量。
一切似乎都是顺理成章的事。
2026年5月,国家首次在安全可靠测评中设立AI芯片品类,9款国产芯片获评最高安全可靠等级I级,华为海思、阿里平头哥、壁仞科技、海光信息、天数智芯、沐曦股份、摩尔线程榜上有名。在国家级认证的坐标系里,壁仞科技已经可以和华为、阿里平头哥站在同一排。
资本市场的投票更直接:2026年1月2日壁仞科技在港交所挂牌上市,开盘即大涨82%,市值一度突破千亿港元,成为港股GPU第一股。
这个“朋友圈”的价值,在于它形成了一个正循环:模型越多在壁仞科技上跑,其软件栈就越成熟;软件栈越成熟,新模型适配就越快;适配越快,更多模型厂商就愿意选择壁仞。这就是生态的“飞轮效应”。
当然,壁仞科技不是一个人在战斗。整个国产GPU赛道,正在上演一场围绕大模型适配的军备竞赛。
前述已提及,华为昇腾的生态厚度同行难以企及。此番,智谱GLM-5.2在Day 0就完成了与昇腾的推理适配;寒武纪在DeepSeek-V4发布当天完成Day0适配,作为字节跳动现有的两家GPU供应商之一,其NeuWare软件栈的影响力持续扩大。
摩尔线程6月以来连续完成MiniMax M3和智谱GLM-5.2的当日适配,MTT S5000的响应速度已经不输任何对手。
燧原科技则在集群方向发力,联合腾讯云发布“燎原”智算集群3.0商用版,已适配DeepSeek、腾讯混元、智谱AI等主流大模型,完成数千卡万卡集群部署。
另外,值得一提的是,燧原科技6月15日刚刚过会,若顺利上市,“国产GPU四小龙”——摩尔线程、沐曦股份、壁仞科技、燧原科技,将首次在资本市场聚齐。
03 终局拼什么?
如果只看单一新闻报道,容易觉得就是几家国家芯片厂商在抢订单、抢头条。但把线索串起来看,逻辑就完全不同了。
国产GPU的黄金窗口期已经打开,但窗口期不会永远敞开。英伟达下一代Rubin架构已在路上,一旦美国放松对华出口限制,国产芯片的“时间差”优势可能很快会消失。
大厂的行动已经说明了一切。字节跳动2026年AI基础设施投入超2000亿元,阿里单季度资本开支超380亿元,腾讯2026年下半年大规模导入国产算力,这些,让国产芯片从“备胎”变成“主力”。但这种系统性替代的前提是生态成熟,谁在“Day-0适配”上不掉队,谁才能拿到大厂采购的入场券。
如今,壁仞科技拿下20余款头部模型的当日适配,寒武纪稳居字节跳动供应商名单,生态的差距正在拉开,而后来者追赶的时间窗口正在收窄。
更要命的是算力成本。字节跳动净利润下滑超70%还在硬扛2000亿算力投入,说明整个行业已经到了必须压降成本的临界点。国产芯片在推理侧的优势不仅是安全自主,更是能够为大厂们省下大把大把的钞票。
譬如,天数智芯智铠系列定价只有英伟达同级别产品的六到七成,随着产能爬坡和良率提升,价格还有进一步下探的空间。
然而,成本优势之外,产能才是真正的命门。国产GPU普遍受制于先进制程产能瓶颈,中芯国际N+2工艺的排期,早已挤满了各家芯片厂商的订单。
政策红利算是打开了需求侧的空间,但供给侧的天花板决定了谁能真正吃到蛋糕。2026年5月,9款国产芯片获评国家最高安全可靠等级,信创需求井喷,但交付能力决定谁能兑现红利。
国产GPU的窗口期不会永远存在。生态、成本、产能,三道关卡已经横在所有玩家面前。时间有限,待到年底大厂万卡集群点亮,谁是填坑者、铺路者、陪跑者,出货量自会给出答案。
