

IT之家 3 月 18 日消息,在昨日的 NVIDIA GTC 2026 上,理想汽车基座模型负责人詹锟发布了下一代自动驾驶基础模型 MindVLA-o1。
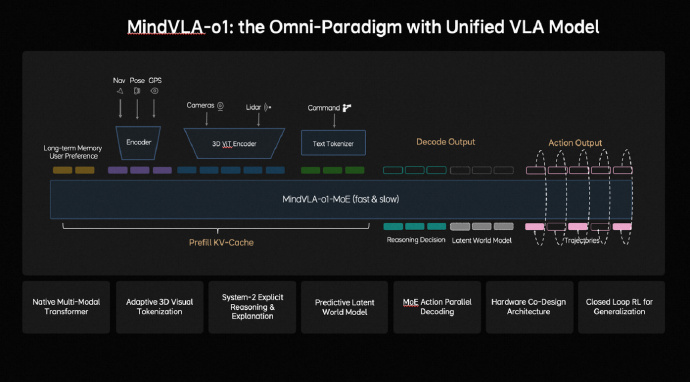
IT之家注意到,理想汽车 CEO 李想今日发布长文谈及了 MindVLA-o1。李想介绍称,理想汽车在底层实现了一个核心突破:原生 3D ViT —— 真正的三维视觉编码器。他表示,自动驾驶,只是物理 AI 的一个起点。
在昨天的 NVIDIA GTC 2026 上,詹锟代表理想发布了下一代自动驾驶基座模型 MindVLA-o1。我们在底层实现了一个核心突破:原生 3D ViT —— 真正的三维视觉编码器。
我们在尝试解答一个问题:人类开车看上去没那么难,每个普通人都能把车开得又快又稳,但全世界最顶尖的企业砸了几千亿进去,自动驾驶仍然进展缓慢。问题到底出在哪?
我们一直在教 AI 做成年人的事,但从来没让它当过小孩。
人类在 0 到 6 岁的阶段学会了走路,学会了扔球、接球。看起来只是简单的动作,但实际上已经帮助孩子建立了对三维物理空间的理解。这就是为什么我们能精准测距、稳定驾驶,因为“3D 预训练”6 岁前就完成了。
但今天所有的端到端系统本质上都是“看 2D 视频学开车”,更像是一个人坐在电脑前看了十万小时行车记录仪,然后直接上路。它有了智能,但离人类的智能程度差得远。过去我们和行业使用的 BEV 把世界从俯视角拍扁,丢失了高度信息;OCC 确实是 3D 的,但缺失了语义信息。物理 AI 缺的不是更大的模型、更多的数据,而是一个能真正理解 3D 世界的视觉基础。
3D ViT 解决了这个问题。不再是从 2D“还原”3D,而是让模型一开始就工作在真实的三维世界里。以高分辨率多视角视觉为核心,在编码阶段直接完成对 3D 空间几何和语义的统一理解 —— 空间结构、位置关系、语义信息,一次完成。模型不只是看见画面,而是理解世界,既知道它在哪,也知道它是什么。
在这个体系下,激光雷达的角色变了。它不再是感知的核心,而更像一把高精度的尺子,为视觉提供几何标定和近场空间约束。真正决定感知上限的,不是传感器的物理线数,而是模型的表征能力。在统一建模下,3D ViT 可以稳定感知并推理到 500 米以上的空间范围。
这件事以前不是没人想做,是做不到,因为 3D ViT 对车端推理算力提出了极高的要求。我们自研的马赫芯片,单颗有效算力是上一代的 3 倍,能把这套架构真正放进车里。
有了 3D ViT 打底,MindVLA-o1 把空间理解、思考推理、驾驶行为统一在一个模型里。不光看见世界,还能在隐空间里模拟未来几秒的场景变化,想清楚再开。我们把这种能力称之为多模态思考。
我们也已经进行了验证,这套基座模型不只是为自动驾驶设计的。同一套 VLA 基座模型,能开车,也能控制机器人,它正在逐渐演化成一个通用的物理世界智能体。
自动驾驶,只是物理 AI 的一个起点。

相关阅读:
《理想汽车发布下一代自动驾驶基础模型 MindVLA-o1:看得更准、想得更深》
英伟达 GTC 2026 大会专题
