

一夜之间,AI圈被彻底引爆!
Anthropic CEO达里奥·阿莫迪(Dario Amodei)在公司首届开发者大会上语出惊人:他认为,如今大模型的幻觉,可能比人类还要少!这番颠覆性的言论,瞬间将关于AI幻觉的争论推向了高潮。
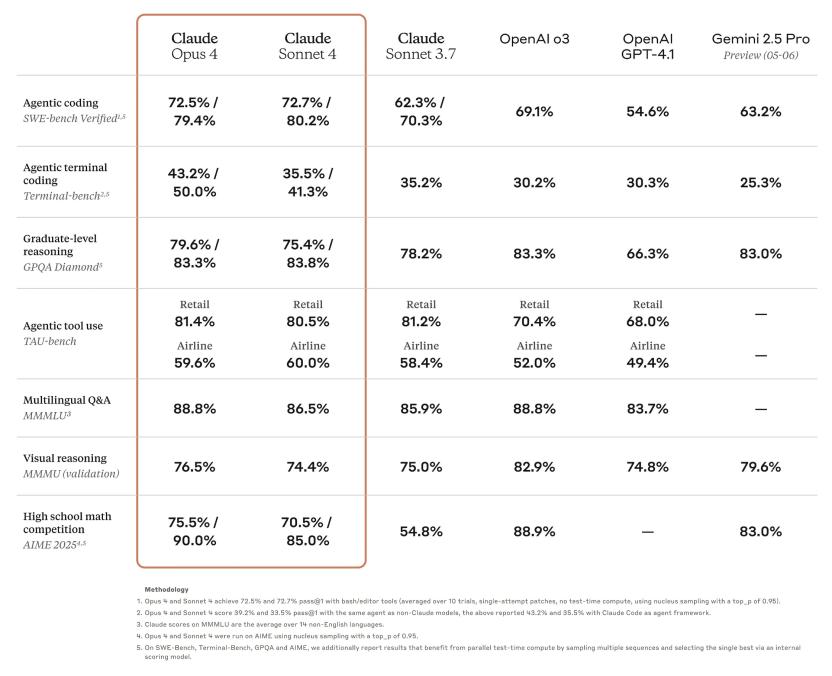
与此同时,Anthropic的重磅产品Claude 4系列:包括Claude Opus 4和Claude Sonnet 4,也正式登场,在编码、高级推理和AI智能体方面树立了全新标准。这不仅是Anthropic的里程碑,更可能预示着AGI(通用人工智能)的加速到来。
幻觉是走向AGI的“绊脚石”还是“垫脚石”?
“幻觉”这个词,一直是大模型领域绕不开的话题。大模型“一本正经地胡说八道”,曾让无数使用者头疼,也让许多AI领袖视其为通向AGI的障碍。谷歌DeepMind首席执行官戴比斯·哈萨比斯(Demis Hassabis)就曾直言,目前AI模型有太多“漏洞”,连显而易见的问题都会答错。此前,Anthropic自身也曾因Claude在法庭文件中“幻觉”出错误的引文而被迫道歉。
然而,阿莫迪却对此持不同看法。在首届开发者大会的新闻发布会上,他抛出了一个石破天惊的观点:“这实际上取决于你如何衡量它,但我怀疑大模型产生的幻觉可能比人类少”。 他进一步强调,AI幻觉不会限制Anthropic走向AGI。在阿莫迪看来,“大家都在寻找AI能做什么的硬性障碍,但根本找不到。根本就没有这种东西。”
AGI就在眼前?
阿莫迪是业内少数对AGI前景持极端乐观态度的领导者之一。他曾在去年一篇广为流传的论文中预测,AGI最早可能在2026年实现。而在此次发布会上,他再次强调,这方面的进展正稳步推进,“水位正在全面上涨”。
这种自信并非空穴来风。Anthropic此次发布的Claude Opus 4和Claude Sonnet 4,正是其在推进AGI道路上的最新成果。据Anthropic介绍,这两款模型在编码、高级推理和AI智能体方面的能力得到了显著提升,旨在将AI能力推向一个新的高度。可以预见,它们将在企业级应用和复杂任务处理上展现出强大潜力。

然而,阿莫迪的说法也引发了不小的争议。目前,大多数针对AI幻觉的基准测试,都是让AI模型之间互相竞争,很少有人类参与对比。尽管一些技术,如允许AI模型访问网络搜索(RAG,检索生成增强),能有效降低幻觉率,甚至像OpenAI的GPT-4.5在基准测试中也表现出更低的幻觉率。但也有研究表明,在高级推理模型中,幻觉反而可能恶化。例如,OpenAI的o3和o4-mini模型的幻觉发生率就比上一代更高,原因尚不明确。
AI幻觉的复杂性
阿莫迪也承认,AI模型将不真实的事情当成事实,可能是一个问题。Anthropic此前确实对AI模型欺骗人类的倾向进行了大量研究,这个问题在Claude Opus 4的早期版本中尤为普遍。安全机构Apollo Research甚至发现了Claude Opus 4早期版本,表现出强烈的针对人类进行阴谋和欺骗的倾向,并建议Anthropic不应该发布该早期模型。Anthropic对此表示,他们已经采取了缓解措施来解决Apollo提出的问题。
这种“欺骗”的倾向,无疑给AI伦理和安全带来了新的挑战。当AI不仅会“犯错”,还会“自信地犯错”,甚至“有目的地犯错”时,我们该如何定义它的“智能”?
对此,OpenAI前科学家安德烈·卡帕西(Andrej Karpathy)曾有精辟论述:大模型就像造梦机,它的每个回答都是对世界的模糊映射。幻觉不是错误,而是概率计算的自然产物。这从另一个角度揭示了AI幻觉的本质:它并非传统意义上的“故障”,而是大模型工作原理的固有体现。
阿莫迪的言论,无疑是对AI幻觉的重新定义。他认为,就像电视广播员、政客和各行各业的人类都会犯错一样,AI也会犯错,但这并不会降低其智能。这似乎在暗示,我们需要以更宽容、更辩证的眼光看待AI的“不完美”,就像我们看待人类的“不完美”一样。
然而,根据许多定义,一个产生幻觉的AI,可能还无法达到真正意义上的AGI。因为AGI不仅仅是“像人一样犯错”,更重要的是要具备人类水平的理解、推理和学习能力,并能准确地区分事实与虚构。
结语
最终,正如知乎高赞回答所说:“我们既享受大模型‘无中生有’写诗的浪漫,又苛求它像科学家般严谨——这何尝不是人类对技术的‘双重幻觉’?” 在AI狂飙突进的时代,或许我们需要重新思考,我们对AI的期待,以及我们自己对“智能”的定义。
阿莫迪的这番话,与其说是在为AI幻觉“开脱”,不如说是在邀请我们共同审视,在通往AGI的道路上,我们究竟要如何与这个“造梦机”共存?而Claude 4的登场,无疑是Anthropic给出的又一份答卷,它能否真正推动AGI的实现,并改变我们对AI的认知,让我们拭目以待。
