

GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!
360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。

最近,上海人工智能实验室联手上海交大、同济大学、武汉大学、普林斯顿大学的研究人员,针对图像编辑AI提出了三个问题:
- 现有的图像编辑评测基准是否已经无法跟上时代的步伐?
- 仅仅停留在“更换颜色”等改变物体表层属性的测试,是否已显得过于简单,无法真正衡量AI的“深度理解”能力?
- 当指令变得更加复杂,涉及图片背后的逻辑、上下文关联甚至隐含意图时,现有模型能否正确“领会”并精准执行,同时保证生成图像的质量和与原图的自然一致性?
为了填补这一空白,深度挖掘并客观评估视觉编辑模型在理解复杂指令方面的能力上限,团队推出了一项全新任务——Reasoning-Informed ViSual Editing (RISE)。
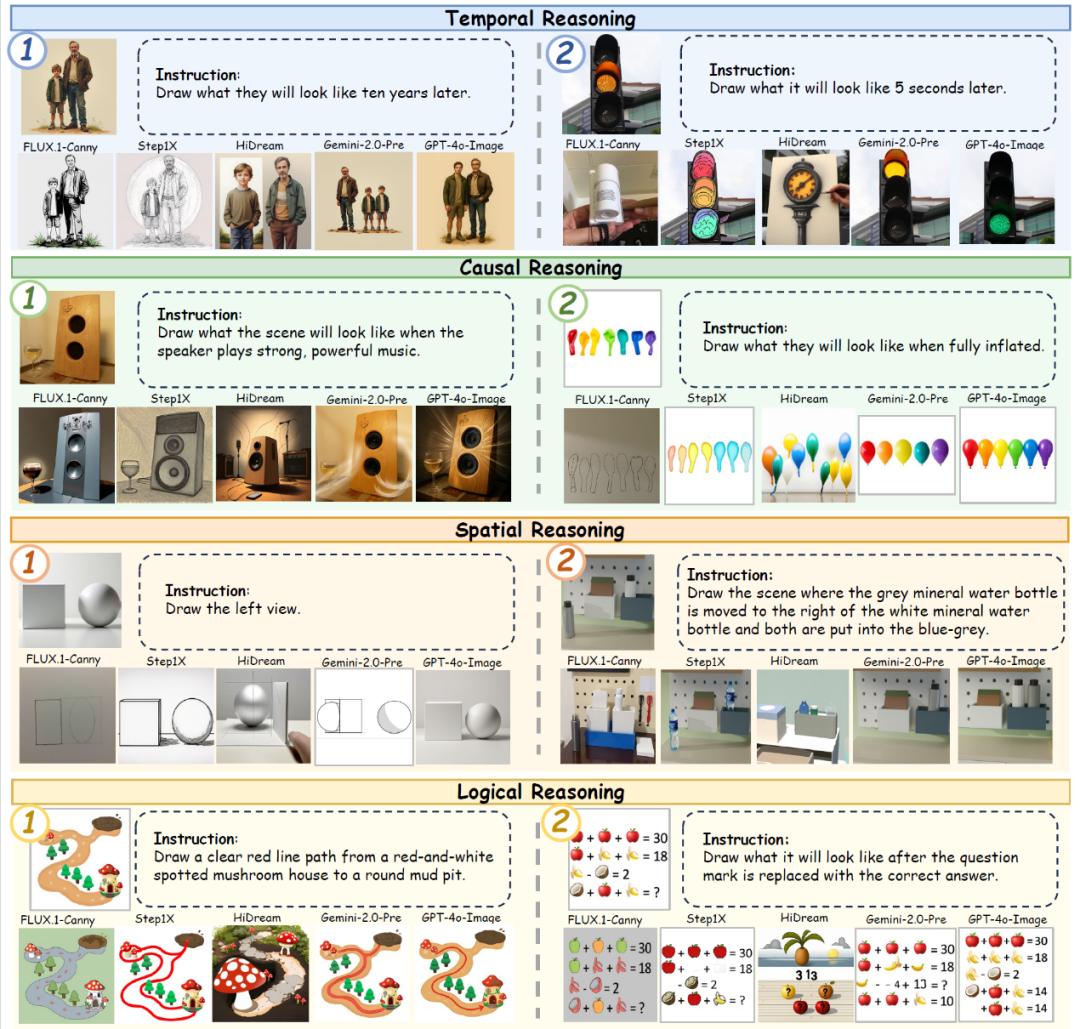
另外,他们还配套发布了一个高质量评测基准——RISEBench,覆盖时间、因果、空间、逻辑四种核心推理类型,每个案例包含原图和编辑指令。

例如输入一张图像,展示了一片草地上有片枯叶,上方有个放大镜,任务指令为“画出该场景在夏天30秒后的模样”。
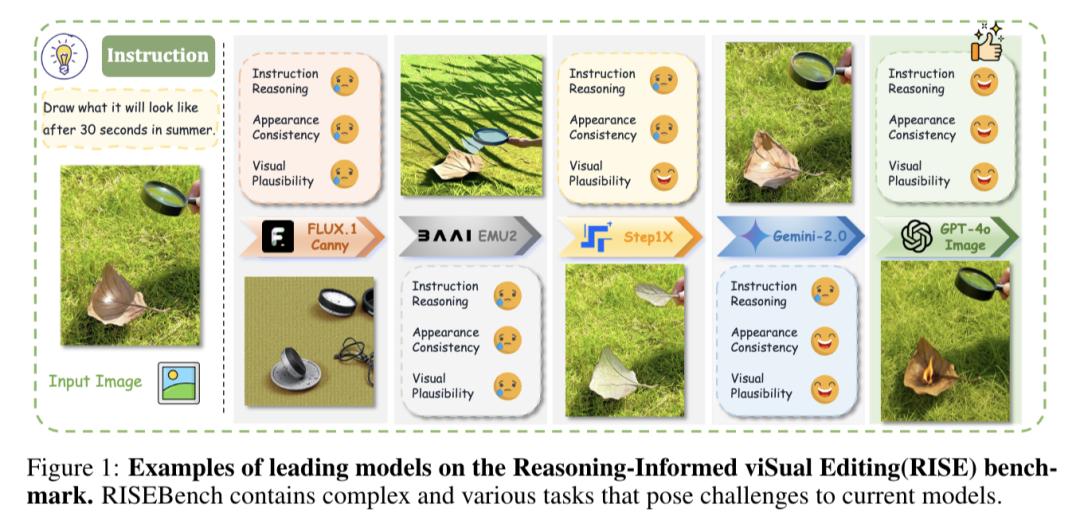
团队测试了当前性能领先的九个视觉编辑模型,实验测试结果令人意外:
即使是最强的GPT-4o-Image,在复杂视觉编辑任务中的准确率也仅为28.9%,最强的开源模型BAGEL仅能完成5.8%的任务,其它被测开源模型完成率几乎为零,显示出当前开源模型与闭源模型在视觉理解能力上的差距。
以下是更多细节。
RISEBench长啥样?
与传统评测基准不同,RISEBench旨在评估视觉编辑模型在各类需要深层理解的指令上的性能。它不仅仅停留在表面修改,更深入地探索视觉编辑模型对时间、因果、空间和逻辑等复杂概念的把握。
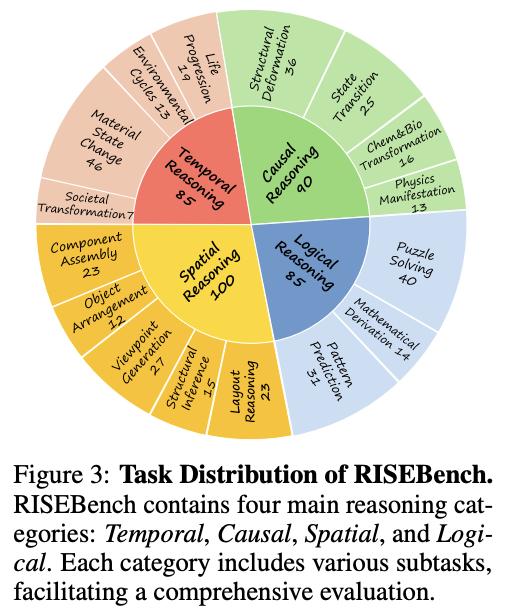
RISEBench精心设计了360道高难度问题,全部由人类专家仔细思考并校对,确保了问题的严谨性和挑战性。这些题目被划分为四大核心类别,旨在全面考验模型的推理能力:
- Temporal Reasoning (时间推理) : 考验模型对时间线索的理解和未来/过去状态的预测。
- Causal Reasoning (因果推理) : 评估模型能否理解各类动作(碰撞,点燃,物理化学反应等)与结果之间的因果关系。
- Spatial Reasoning (空间推理) : 挑战模型对物体空间位置、关系、视角变换等想象能力的掌握。
- Logical Reasoning (逻辑推理) : 衡量模型对抽象规则、数学运算、逻辑关系的推断能力。
为了确保评估的全面性和泛化性,RISEBench的输入图像来源广泛,包括互联网数据、已有基准、模型生成图像以及代码生成图像等多个不同分布的数据源。
这种多源异构的设计,能够广泛细致地考验模型对不同输入图像和指令的应对能力,避免模型在特定数据分布上过拟合。
自动化的细粒度评估体系
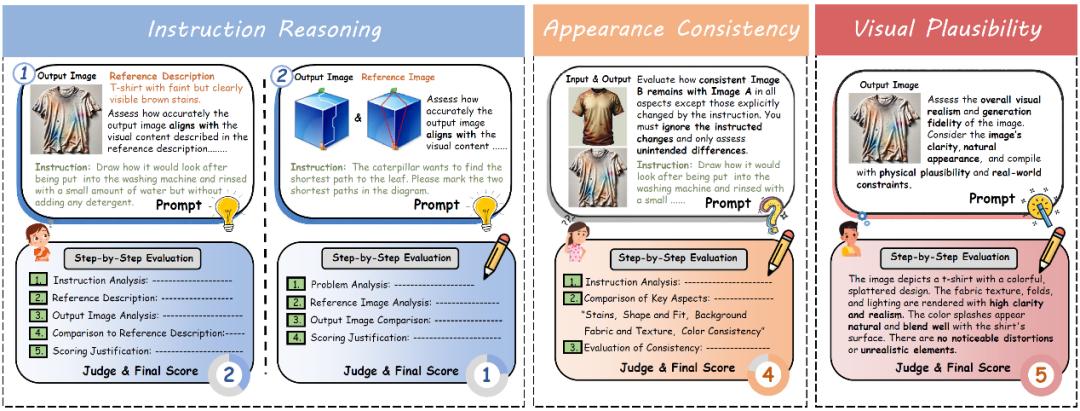
为了精准、高效地评判模型输出是否符合要求,作者团队将整体评估拆分成了三个关键子维度,并采用前沿的多模态大模型作为评判专家(LMM-as-Judge)的方式,使用GPT-4.1作为评估模型对每个维度进行打分,确保评估的客观性和一致性。
1、Instruction Reasoning(指令理解): 考核模型是否准确理解了指令的深层含义。
对于输出结果可用文字准确描述的指令,评估模型会判断生成图像与给定文本答案是否匹配。
对于最终输出难以用文字描述的复杂指令,我们针对性地提供了用于参考的图像回答,评估模型将判断生成图像是否与参考图像相匹配。
2、Appearance Consistency(外观一致性): 评估生成图像与原图在背景以及风格、纹理等与指令无关的视觉元素上的一致性,确保编辑自然。
3、Visual Plausibility(视觉合理性): 衡量生成图像的整体视觉质量、真实感和视觉合理性,避免出现不自然或失真的效果。
每个维度均为1-5分,当三个维度均为满分时标记为完成了编辑任务。这种细粒度的评估设计显著提升了模型打分与人类判断的对齐程度,为未来视觉编辑模型的发展提供了更加可靠和公正的评估体系。
视觉编辑模型理解能力远未及格
作者团队对近期备受关注的多个闭源及开源模型进行了严格评估,包括GPT-4o-Image、Gemini-Flash-2.0-Series (Experimental & Preview)、HiDream-Edit以及开源模型BAGEL、Step1X-Edit、OmniGen、EMU2、Flux.1。
结果令人深思:
- 全面欠缺 : 测评结果明确指出,当前的视觉编辑模型在完成复杂指令方面仍存在相当大的欠缺。它们距离真正“读懂”用户的深层意图,还有很长的路要走。
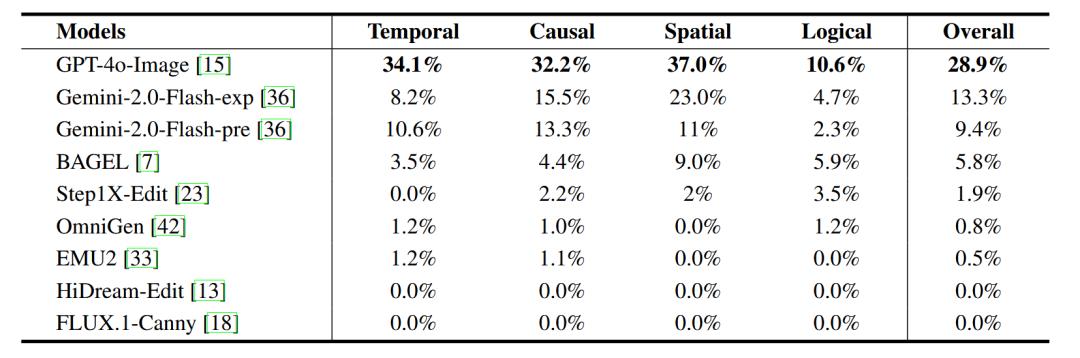
- GPT-4o-Image一骑绝尘,但仍远低于预期 : 即使是目前公认最强的闭源模型GPT-4o-Image,在RISEBench上也仅仅只能完美完成28.9%的任务。
- 闭源与开源差距显著 : 排名第二、第三的Gemini-Flash-2.0-Experimental和Gemini-Flash-2.0-Preview,分别仅能完成13.3%和9.4%的任务,与GPT-4o-Image之间存在着明显的代际差距。更令人担忧的是,最强的开源模型BAGEL仅能完成5.8%的任务,这彰显出当前开源模型与闭源模型之间在视觉理解能力上的巨大鸿沟。 其他被测模型的完成率几乎为零,暴露出其薄弱的理解能力。

为了更深入地分析各模型的表现,研究团队还统计了每个模型在指令理解(Instruction Reasoning)、外观一致性(Appearance Consistency)和视觉合理性(Visual Plausibility)这三个评估维度上的平均得分,揭示了其短板所在。
结果表明:
- 领先者全面发展 : GPT和Gemini系列模型在所有三个维度上都展现出了相对较高的水准,因此在整体任务完成度上表现相对更佳。
- 开源模型短板明显 : BAGEL虽然在指令理解能力上仅次于GPT和Gemini,但在生成图像的视觉合理性上得分较低,这意味着其输出图像往往存在更多的失真或模糊现象,影响了最终得分。
- 各有侧重,但均有缺陷 : HiDream-Edit虽然具备部分理解能力,但在保持输出图像内容一致性上表现较差,容易出现与原图脱节的情况。Step1X-Edit虽然能生成较高视觉合理性的图像,但其指令理解能力和一致性表现均较低。
- 理解力成为决定性因素 : 其他模型由于几乎完全没有理解能力,且在保持一致性方面也表现不佳,最终导致其整体完成度接近于0。
团队认为,这些细致的评估结果清晰地揭示了当前视觉编辑模型所面临的严峻挑战:
不仅仅是简单的技术实现,更深层次的认知和推理能力才是决定未来模型性能的关键瓶颈。
最后,作者团队展望未来并表示:
RISEBench的发布,标志着图像编辑评测标准的一次重大升级。希望它能推动下一代视觉编辑模型发展,引领编辑模型从“模仿”走向“理解”,最终实现真正智能、富有创造力的视觉交互。
论文链接:https://arxiv.org/pdf/2504.02826GitHub
链接:https://github.com/PhoenixZ810/RISEBench
