

近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果:
在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。
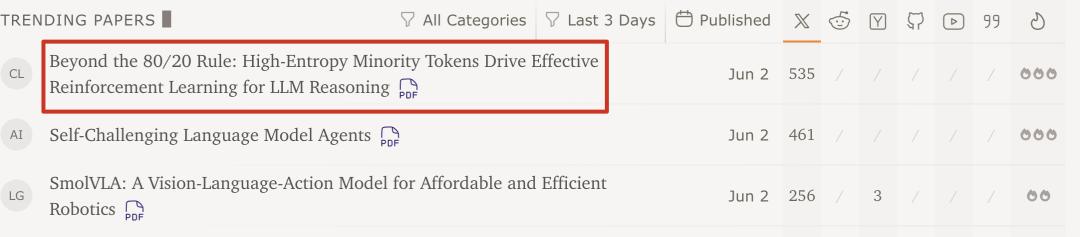
团队用这个发现在Qwen3-32B上创造了新的SOTA记录:AIME’24上达到63.5分,AIME’25上达到56.7分,
这是600B参数以下直接从base模型训练的最高分。
最大响应长度从20k延长到29k,AIME’24的分数更是飙升到了68.1分。
经典的二八法则(或帕累托法则)指出,通常80%的结果由20%的关键因素驱动,但剩下80%也是不能轻易舍弃的。
但是在大模型强化学习这里,80%低熵token不仅可以舍弃,甚至还可能起副作用,所以这篇论文被命名为“超越二八法则”。
此外,团队还从token熵的角度探究了RL对LLM的主要影响,并进一步讨论了RL与SFT的区别、LLM RL的特殊性与clip-higher相较于entropy bonus的优势。

揭开Chain-of-Thought的熵分布密码
要理解这项研究,需要先从一个有趣的观察说起:
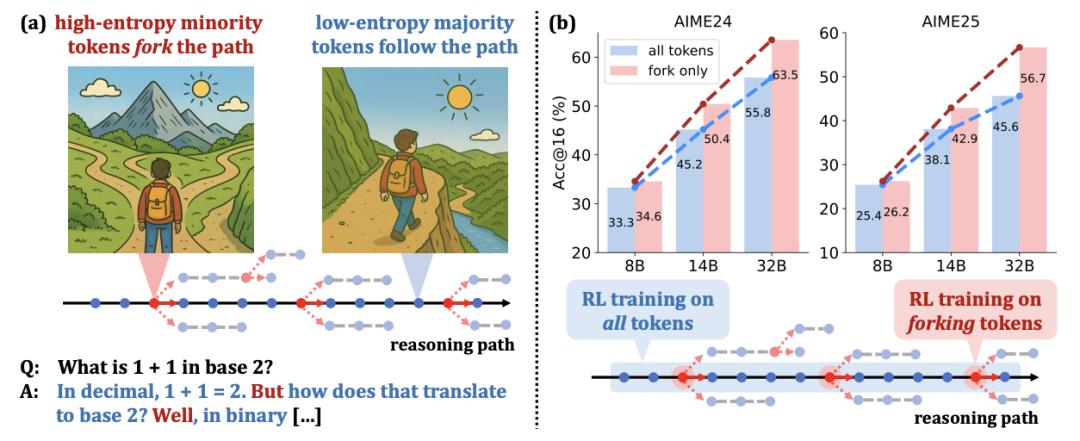
团队发现,当大模型进行链式思考(Chain-of-Thought)推理时,token的熵分布呈现出一个独特的模式:大部分token的熵都很低,只有少数token表现出高熵特征。
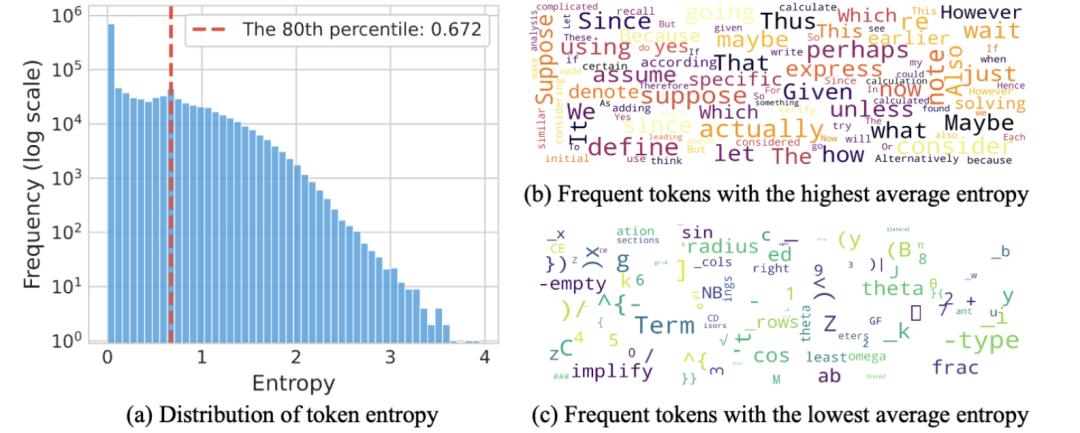
具体来说,超过50%的token熵值低于0.01,而只有20%的token熵值大于0.672。

更有意思的是,这些高熵token和低熵token在功能上有着本质区别。高熵token通常扮演着“逻辑连接器”的角色,比如“wait”、“however”、“thus”这些词,它们在推理过程中起到转折、递进或因果连接的作用。
在数学推导中,“suppose”、“assume”、“given”这些引入假设或条件的词也属于高熵token。而低熵token则往往是词缀、代码片段或数学表达式的组成部分,这些内容具有很高的确定性。
团队形象地把这些高熵token称为分叉token(forking tokens),如果将思维链比做走山路,高熵token就像分叉路口(fork),决定了接下来的方向;低熵token就像一面是山一面是悬崖的小路,只能沿着既定方向走下去。
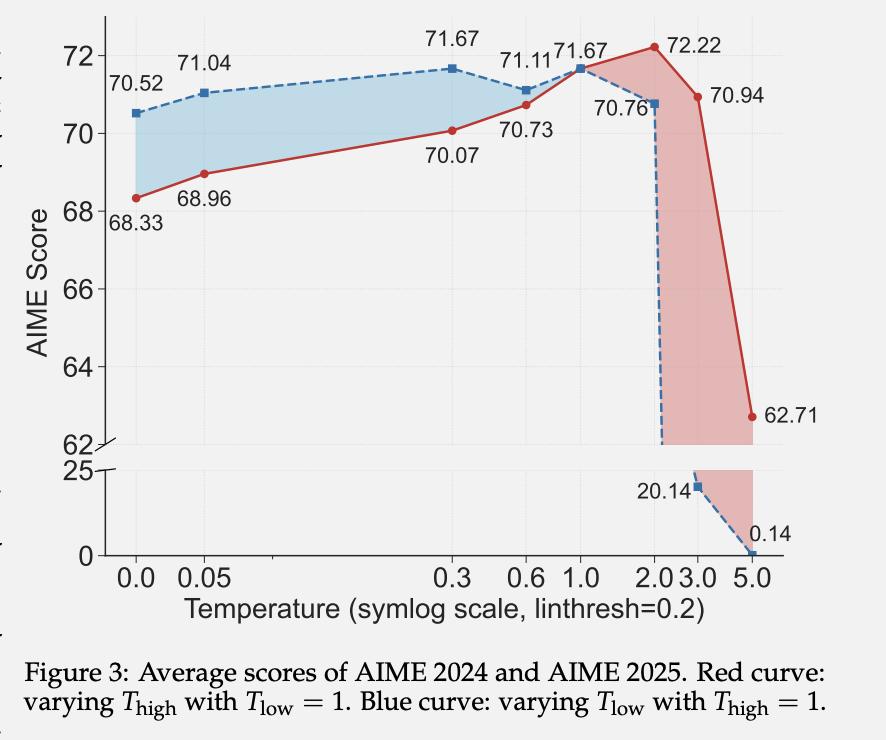
为了验证这些分叉token的重要性,团队还设计了这样的实验:给不同的token设置不同的解码温度。
结果发现,适度提高高熵token的温度能改善推理性能,而降低它们的温度则会导致性能下降。这进一步证实了保持这些关键位置的高熵对推理的重要性。
只用20%的token,效果反而更好
既然发现了这些分叉token的特殊性,那么如果在强化学习训练时只关注这些关键的少数token会怎样?
在RLVR(Reinforcement Learning with Verifiable Rewards)训练中,只保留top 20%高熵token的策略梯度,把剩下80%的梯度全部屏蔽掉。
结果Qwen3-32B上,这种方法不仅没有降低性能,反而带来了显著提升:AIME’24分数提升7.71分,AIME’25分数提升11.04分,平均响应长度增加约1378个token。
在Qwen3-14B上也有类似的提升效果,而在较小的Qwen3-8B上,性能也保持稳定。
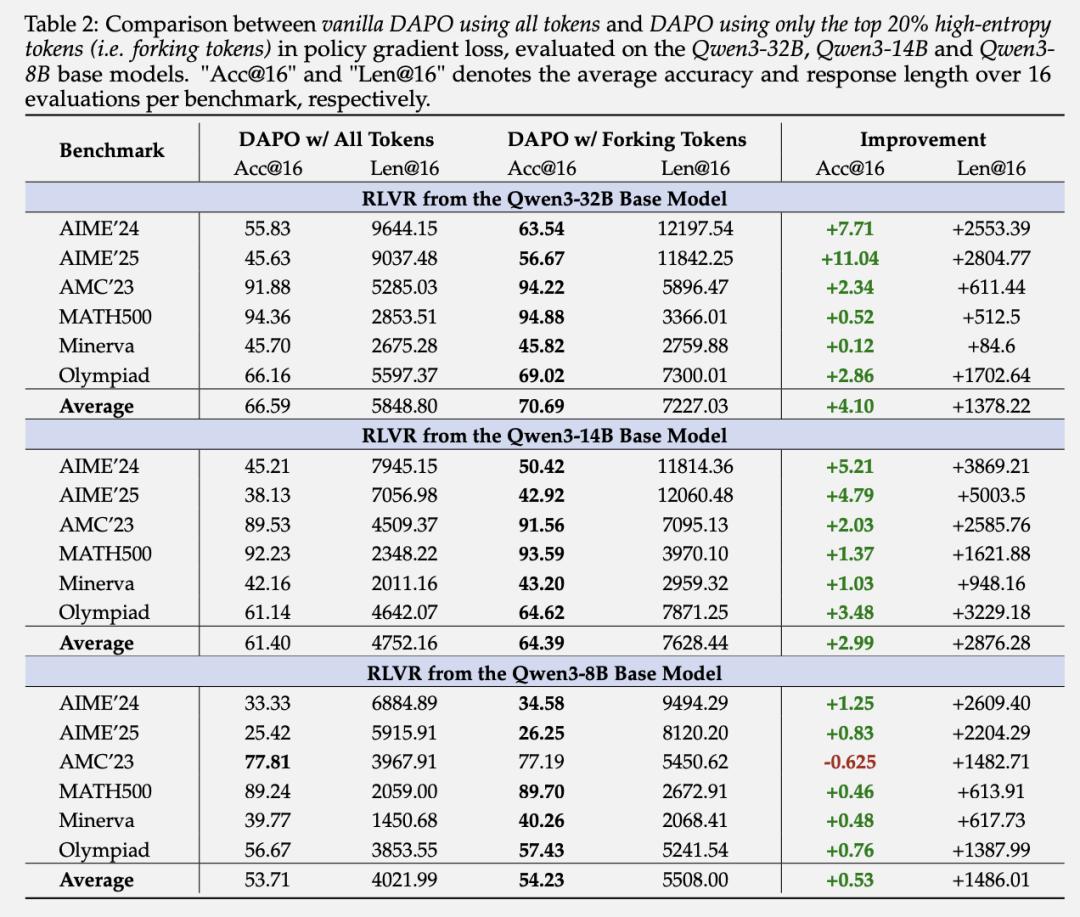
更有趣的是反向实验的结果:如果只用80%的低熵token训练,模型性能急剧下降。
这说明低熵token对推理能力的提升贡献微乎其微,甚至可能起到负面作用。
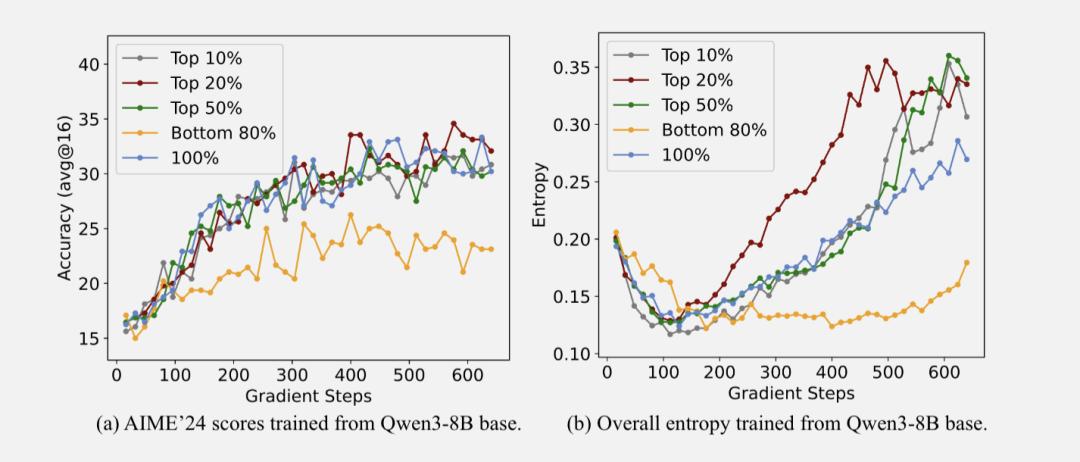
团队分析认为,这可能与路径探索有关。高熵token由于其不确定性,能够帮助模型探索不同的推理路径。而低熵token过于确定,反而限制了模型的探索能力。
从训练过程中的整体熵变化也能看出端倪:使用20%高熵token训练时,模型保持了较高的整体熵水平,而使用全部token或只用低熵token时,整体熵水平都会下降。

另一个重要发现是这种方法存在明显的规模效应:模型越大,只用高熵token训练的优势就越明显。在32B模型上的提升最大,14B次之,8B模型提升最小。这可能是因为更大的模型有更强的能力利用增强的探索性。
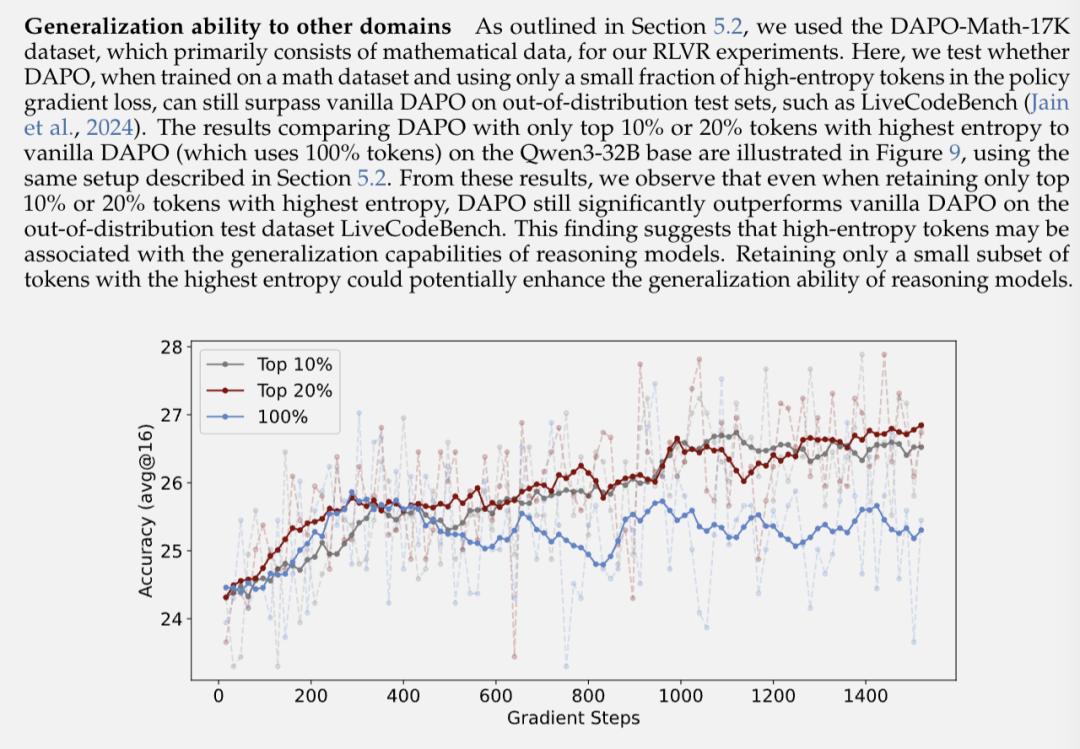
更令人惊喜的是,这种方法训练出的模型在域外任务上也表现优异。团队在数学数据集上训练的模型,在编程任务LiveCodeBench上测试时,仅用20%高熵token训练的模型依然大幅超越了使用全部token训练的版本。
这暗示着高熵token可能与模型的泛化能力密切相关。通过聚焦这些关键的决策点,模型学到的可能是更本质的推理模式,而不是死记硬背特定领域的知识。
重新理解大模型强化学习
这项研究的意义不止于提升训练效率,在深入研究RLVR(Reinforcement Learning with Verifiable Rewards)训练过程后,团队发现了一个令人意外的现象:RLVR并不是推倒重来,而是在base model的基础上做精细调整。
通过追踪训练过程中熵模式的演变,发现即使在训练收敛后(第1360步),模型与base model在高熵token位置上的重叠率仍然保持在86.67%以上。这意味着RLVR基本保留了预训练模型对”哪些地方该犹豫、哪些地方该确定”的判断。

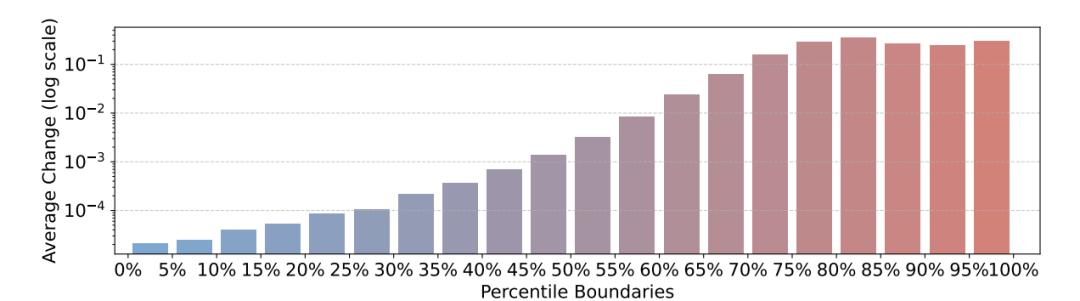
更有意思的是,RLVR的调整策略相当”偏心”。团队计算了不同熵水平token在训练前后的变化,发现了一个清晰的规律:
初始熵越高的token,在RLVR训练后熵的增幅越大。而那些原本就很确定的低熵token,整个训练过程中几乎纹丝不动。
从熵的百分位变化图中可以看到,越是高熵的token(比如90%、95%分位),训练过程中的波动范围越大;而低熵token(比如0%、5%分位)的变化微乎其微。
最后,基于以上所有这些发现,团队还提出了几个有趣的讨论:
讨论1:高熵token可能是解释为什么强化学习能泛化而监督微调倾向于记忆而过拟合的关键。
强化学习倾向于保持甚至增加分叉token的熵,维持推理路径的灵活性。而监督微调会把输出logits推向one-hot分布,导致分叉token熵降低,失去了推理路径的灵活性。这种灵活性可能正是推理模型能够有效泛化到未见任务的关键因素。
讨论2:与传统强化学习不同,大模型推理需整合先验知识,且必须生成可读性输出。因此,大模型思维链(CoT)包含低熵的多数标记与高熵的少数标记,而传统强化学习可假设整个过程中动作熵是均匀分布的。
讨论3:在强化学习与可验证奖励算法(RLVR)中,熵奖励(entropy bonus)可能并非最优选择,因为它会增加低熵多数标记的熵值。相比之下,clip-higher方法能有效提升高熵少数标记的熵值。
论文
https://arxiv.org/abs/2506.01939
项目主页
https://shenzhi-wang.github.io/high-entropy-minority-tokens-rlvr/
