

Meta FAIR、剑桥大学与麻省理工学院的联合科研团队提出全原子扩散 Transformer ADiT,打破了周期性与非周期性系统的建模壁垒,通过全原子统一潜在表示与 Transformer 潜在扩散两大创新,实现了用单一模型生成分子与晶体的突破。
在当今科学研究与工业应用的前沿领域,原子系统三维结构的生成建模正展现出颠覆性潜力,有望彻底重塑新型分子和材料的逆向设计版图。从精准的结构预测到灵活的条件生成,当前最先进的扩散模型及流匹配模型已在生物分子解析、新材料研发及基于结构的药物设计等关键任务中崭露头角,成为科研人员突破技术瓶颈的核心工具。
然而,在这一蓬勃发展的领域背后,一个关键难题始终制约着技术跃迁——现有模型缺乏跨系统的通用性。尽管所有原子系统均遵循相同的物理原理决定其三维结构与相互作用,但小分子、生物分子、晶体及其复合体系的建模却长期处于「分而治之」的状态。绝大多数扩散模型高度依赖特定系统的固有特性,需在分类数据(如原子类型)与连续数据(如三维坐标)交织的复杂乘积流形上进行多模态生成,这导致不同系统间的模型难以兼容。
以具体场景为例:小分子的从头生成需拆分为原子类型(分类)与三维坐标(连续)两个独立扩散过程,去噪模型虽需学习二者的协同演化规律,却常因中间状态失真降低采样效率;生物分子建模需额外引入旋转流形,将原子组视为刚体处理;而晶体与材料的扩散过程则必须兼容周期性特征,在原子类型、分数坐标、晶格参数等多维度参数构成的联合流形上运行 —— 这些差异使得跨系统统一建模成为领域内长期未决的挑战。
在此背景下,Meta 基础人工智能研究(FAIR)、剑桥大学与麻省理工学院的联合科研团队提出了突破性解决方案——全原子扩散 Transformer(All-atom Diffusion Transformer,简称 ADiT)。
作为一种基于 Transformer 的统一潜在扩散框架,ADiT 的核心优势在于打破了周期性与非周期性系统之间的建模壁垒,通过全原子统一潜在表示与 Transformer 潜在扩散两大创新,实现了用单一模型生成分子与晶体。其设计几乎不引入归纳偏差,使得自编码器与扩散模型在训练和推理效率上远超传统等变扩散模型 —— 在相同硬件条件下,生成 10,000 个样本的时间从 2.5 小时缩短至 20 分钟以内。更值得关注的是,当模型参数扩展至 5 亿规模时,其性能呈现可预测的线性提升,这一特性为构建通用型生成化学基础模型奠定了关键基础,标志着原子系统建模向通用性与规模化应用迈出了里程碑式的一步。
相关研究成果以「All-atom Diffusion Transformers: Unified generative modelling of molecules and materials」为题,入选 ICML 2025。
研究亮点:
* ADiT 首次实现了适用于周期性材料和非周期性分子系统生成模型的统一
* ADiT 依托全原子统一潜在表示与使用 Transformer 进行潜在扩散,有效简化了生成过程,且几乎无归纳偏差
* ADiT 具有出色的可扩展性与效率,训练和推理速度远超等变扩散模型
论文地址:
https://go.hyper.ai/27d7U
数据集:从周期到非周期,覆盖多领域实验数据
在该研究中,研究团队首先选取了多类具有代表性的数据集展开实验:
* MP20 数据集,包含 45,231 个来自 Materials Project 的亚稳态晶体结构,单元格内最多有 20 个原子,涵盖 89 种不同元素,能很好地代表周期性材料系统;
* QM9 数据集,由 130,000 个稳定有机小分子构成,最多含 9 个重原子(C、N、O、F)及氢原子,是典型的非周期性分子系统代表;
* GEOM-DRUGS 数据集,包含 430,000 个最多 180 个原子的大型有机分子;
* QMOF 数据集,含有 14,000 个金属有机框架结构。
其中,MP20 与 QM9 分别对应不同类型的原子系统,为模型在周期性与非周期性系统上的联合训练提供了基础,且研究团队按先前研究的方式划分数据,保证了与其他模型比较的公平性;GEOM-DRUGS 与 QMOF 进一步拓展了模型测试的范围,能更全面地检验模型的泛化能力。
ADiT:以双核心思想构建统一原子系统生成模型
ADiT 作为一种潜在扩散模型,其核心设计围绕两个关键思想展开,以此实现对周期性和非周期性原子系统的统一生成建模。
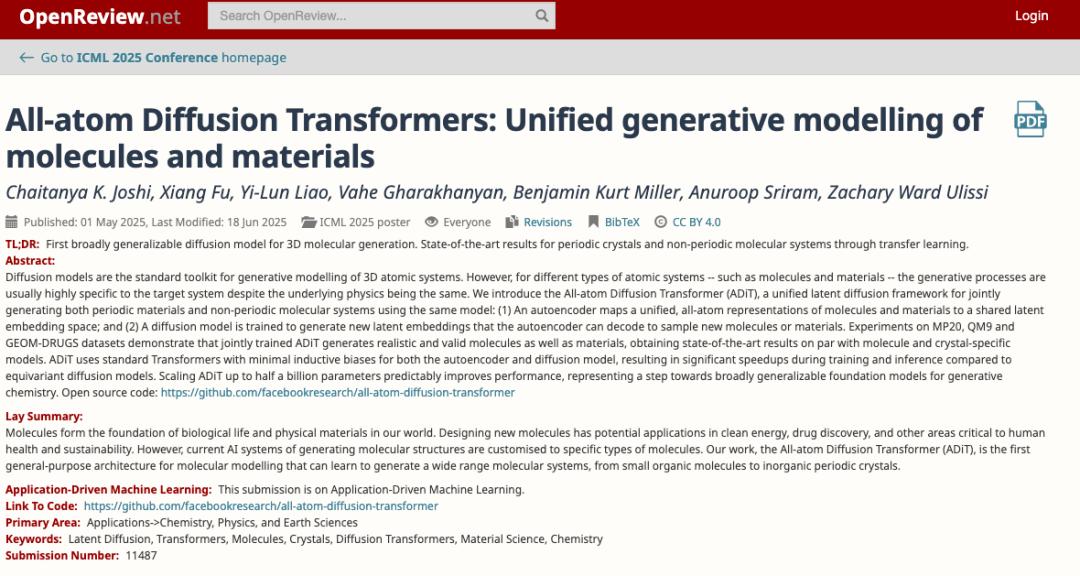
第一个关键思想是全原子统一潜在表示,研究团队将周期性与非周期性原子系统均视为三维空间中的原子集合,进而开发出一种包含每个原子分类属性(如原子类型)和连续属性(如三维坐标)的统一表示方式。通过训练变分自编码器(VAE)进行全原子重建,该编码器能够将分子和晶体嵌入到一个共享的潜在空间中,这就为不同类型原子系统的统一处理搭建了基础框架。
第二个关键思想是使用 Transformer 进行潜在扩散,在 VAE 编码器构建的潜在空间中,研究团队引入扩散 Transformer(DiT)开展生成建模工作。在推理过程中,借助无分类器引导技术,能够对新的潜在变量进行采样,而这些潜在变量又可以通过 VAE 解码器重建为有效的分子或晶体,从而完成从潜在空间到实际原子系统的转化。
基于这两个核心思想,ADiT 的实验方法分为两个阶段有序推进。
第一阶段,研究人员构建用于重建的自动编码器(Autoencoder for reconstruction),通过 VAE 对分子和材料的全原子表示进行联合重建,学习并构建共享的潜在空间——这是实现不同原子系统统一建模的前提,为后续生成过程奠定基础。
第二阶段,研究人员构建潜在扩散生成模型(Latent diffusion generative model),利用 DiT 从潜在空间生成新样本,这些样本经无分类器引导解码为有效的分子或晶体。这种潜在扩散设计的显著优势在于,将处理分类与连续属性的复杂性转移至自编码器,使潜在空间中的生成过程更简化且可扩展,有效提升了模型处理不同原子系统的效率与适应性。
ADiT 分两个阶段对化学系统进行生成建模
ADiT 在晶体与分子生成中性能领先
为充分凸显 ADiT 的性能优势,研究团队选取了多类基线模型进行针对性对比。在晶体生成领域,对比对象包括 CDVAE、DiffCSP、FlowMM 等基于多模态乘积流形的等变扩散和流匹配模型,以及非等变扩散模型 UniMat、两阶段框架 FlowLLM;在分子生成领域,则与等变扩散模型、GeoLDM、Symphony 等模型展开比较。通过与这些领域内先进基线模型的系统对比,ADiT 的性能优势得到了清晰展现。
从具体实验结果来看,ADiT 在晶体和分子生成任务中均达到了 SOTA 水平。在晶体生成方面,ADiT 生成的晶体在有效性、稳定性、独特性和新颖性等关键指标上表现出色。在分子生成任务中,ADiT 在 10,000 个采样分子的有效性和独特性指标上位居前列。
ADiT 的联合训练机制也为其带来了显著的性能增益。实验数据显示,同时在 QM9 和 MP20数据集上训练的 ADiT,在材料和分子生成任务中全面优于仅在单一数据集上训练的版本。
模型规模的扩展对 ADiT 的性能提升具有可预测性。如下图所示,随着 DiT 去噪器参数量从 3,200 万(ADiT-S,蓝色)增至1.3 亿(ADiT-B,橙色),再到 4.5 亿(ADiT-L,绿色),即使在约 13 万个样本的中等规模数据集上,扩散训练损失持续降低,有效性比率稳步提升,呈现出显著的规模效应。这种模型规模与性能的强相关性表明,通过扩大模型参数和数据量,有望推动 ADiT 实现进一步突破。

ADiT 去噪参数数量增加对训练损失和生成有效性的影响
在效率方面,ADiT 相比等变扩散模型展现出显著的速度优势。如下图所示,在英伟达 V100 GPU 上生成 10,000 个样本时,基于标准 Transformer 的 ADiT 在积分步数上的扩展性远超使用计算密集型等变网络的 FlowMM 和 GeoLDM。即便 ADiT-B 的参数规模比等变基线大 100 倍,其推理速度仍更快,这凸显了 Transformer 架构在扩展实用性上的优势。
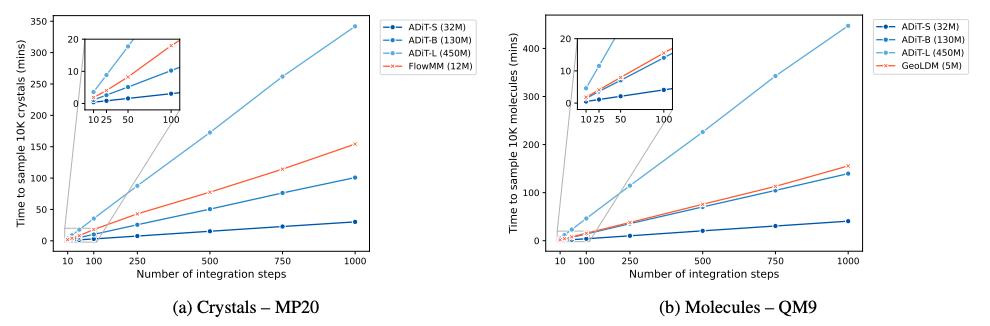
ADiTs 和等变扩散模型生成 10,000 个样本的时间关系图
此外,ADiT 在更大系统上的扩展性也得到了验证。在包含 43 万个最多 180 个原子的 GEOM-DRUGS 分子数据集上,ADiT 与最先进的等变扩散和流匹配模型相比,在有效性和 PoseBusters 指标上表现相当。值得注意的是,ADiT 基于标准 Transformer 架构,几乎不引入分子归纳偏差,且无需显式预测原子键,却能达到与等变模型相当的性能,进一步体现了其设计的通用性和广泛适用性。
产研共同推进原子系统三维结构生成的突破创新
事实上,在原子系统三维结构生成建模这一前沿研究领域,学术界与企业界历经不懈探索,已有诸多成果备受瞩目。
在学术界,加州大学伯克利分校、微软研究院携手 Genentech 公司的研究团队推出多模态蛋白质生成方法 PLAID,该方法巧妙借助预训练权重中的结构信息,以 DiT 执行去噪任务,于不同蛋白质长度的结构质量与多样性分析中,较其他基准方法彰显出更为卓越的性能。
企业界在这一领域同样踊跃投身探索,创新驱动发展。中国生成式 AI 蛋白质设计创新企业百奥几何重磅发布的全球首款全能蛋白质基础模型 GeoFlow V2,构建起统一的原子扩散模型架构,一举攻克蛋白质结构预测与设计任务。在抗体及抗原 - 抗体复合物结构预测方面,GeoFlow V2 凭借其超凡的精度与速度,全面领先同类产品。字节跳动推出的 Seedance 1.0 则另辟蹊径,采用变分自编码器与扩散 Transformer 相结合的技术方案,实现了快速高效的 AI 视频生成,其速度优势为实时创作和交互式应用打开了全新局面,预示着在商业应用领域拥有广阔前景。
这些学术界的科研突破与企业界的创新实践,共同推动着原子系统三维结构生成建模领域的发展。随着技术的持续进步,这一领域必将在新型材料研发、药物设计等诸多方面发挥更大作用,为解决全球性的科学难题和产业挑战提供强有力的支撑。
参考文章:
1.https://mp.weixin.qq.com/s/oF3-y7z8u1XpEtjd4q1u4w
2.https://mp.weixin.qq.com/s/tK0-1Qna6p7TnMrWENwZ7A
