

在美国红点创投的播客Unsupervised Learning最新一期节目中,红点创投合伙人Jacob Effron对话了负责Nano Banana的两位Google研究员Nicole Brichtova和Oliver Wang。讨论认为,Nano Banana的流行,归功于这款模型实现了前所未有的“角色一致性”。
Nano Banana在8月26日“匿名”发布,后来证明这款模型就是谷歌的Gemini 2.5 Flash Image模型。Nano Banana的成功也使得谷歌的Gemini APP的下载量飙升。
据应用数据分析公司Appfigures提供的最新数据,这款应用已经攀升至全球应用商店排行榜的榜首,并且在九月份下载量环比增长了45%。虽然九月份才过了一半,Gemini应用本月已经获得了1260万次下载,远高于八月份的870万次。在此之前,Gemini仅在2025年1月28日达到过美国App Store的第三名。谷歌母公司Alphabet(GOOG.US)在8月26日至9月17日收盘的股价涨幅为19.56%。
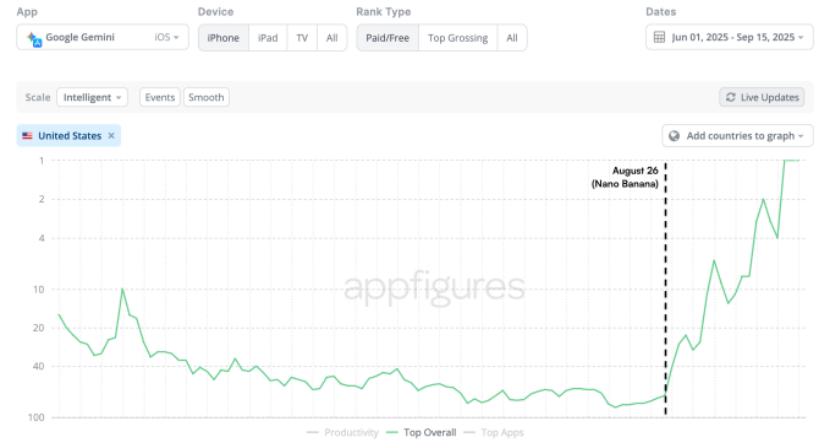
Gemini下载量数据(来源:Appfigures、TechCrunch)
在产品之外,这期播客访谈内容涵盖了模型如何融入创意工作流程,为什么尽管当前AI图像能力已经让人感觉很强大但“仍处于AI图像发展的早期阶段”,以及图像与视频生成如何正趋向统一。
在访谈中,Nicole Brichtova和Oliver Wang分还享了当前模型的局限性、安全策略,以及为什么“从提示一步到生成可直接用于生产的内容”这一期待其实被严重高估了。
以下为「明亮公司」编译的访谈正文(有删节):

Nicole(左)、Oliver(中),主持人Jacob(右)
Nano Banana的成功归功于角色的一致性
Jacob:Nicole和Oliver,非常感谢你们来到节目。我一直很期待这次对话。感觉你们已经占据了我整个Twitter动态、还有我所有的空闲时间,都是Nano Banana。
今天我们会深入探讨很多话题。也许我们可以先从这个问题开始——你们在产品和模型发布前就已经接触并体验了它,我记得最初可能是匿名发布的。但你们是最早一批玩转它的人,我很好奇,你们最初认为哪些用例会最流行或让你们最兴奋?而现在发布后,实际情况又如何?
Nicole:Oliver已经见过很多我脸部的各种迭代图片。对我来说,最激动人心的是角色一致性,以及能在新场景中看到自己——所以我真的有一堆幻灯片,都是我的脸,比如通缉海报、考古学家,还有我童年梦想的职业。
基本上,我们现在创建了一个包含我的脸和团队其他成员的评估数据集,每当我们开发新模型时都会用来测试。
Jacob:在AI领域,这简直是最高荣誉了。
Nicole:我真的很兴奋。所以我非常看重角色一致性,因为它给了人们一种全新的方式去想象自己,以前很难做到。这也是大家最终非常激动的原因之一。我们看到很多人把自己变成了手办,这是非常受欢迎的用例之一。还有一个让我感到惊喜但其实也合理的用法——人们为老照片上色,这是非常有情感价值的用例。比如:现在我能看到自己小时候真实的样子,或者能看到父母从黑白照片中还原出来的真实模样。
Jacob:这真的很有趣。我相信看到大家的各种用法也是你们拥有热门产品的乐趣之一。我在Twitter上也见过,你们一定收到无数功能请求吧?每个人都希望模型能做这或那。最常见的需求有哪些?你们如何看待这些产品和模型的下一个里程碑或发展的方向?
Nicole:Twitter上最多的需求是更高分辨率。目前很多专业用户都在请求1K分辨率以上的图像。还有很多请求希望支持透明背景,这是专业用户很常见的需求。这两点是我见到最多的,还有更好的文本渲染。
Jacob:角色一致性曾经是很难解决的大问题,你们在这方面做得非常棒。你们认为图像模型改进的下一个前沿是什么?
Oliver:对我来说,这个模型最令人兴奋的一点是它可以开始接受更难的问题。以前你必须定义你想要的图像的每个细节,现在你可以像问语言模型一样寻求帮助。例如,有人用它来重新装修房间,但自己没有主意,让模型给出建议。模型能根据配色方案等给出合理建议。
我认为最有趣的是结合语言模型的世界知识,让图像模型真正帮助用户,甚至展示他们没想到的东西。比如信息检索请求——我想知道某个东西是如何工作的,模型能生成解释图片。我觉得这是未来很重要的用例。
Jacob:在这方面进展如何?
Oliver:审美方面始终比较棘手,因为需要深度个性化才能给出有用的信息。我认为个性化是技术侧还在不断改进的领域。我们还需要一段时间才能真正理解用户的需求,但如果能和模型对话,不断澄清和细化,我觉得很令人期待。比如可以在对话线程中反复沟通,直到生成你想要的图片。
Jacob:你觉得个性化会只发生在提示层面吗?就是通过足够的描述,给模型足够的上下文来实现个性化?还是大家会有不同的美学模型?
Oliver:我认为会更多发生在提示层面。比如用户告诉你的信息,可以让我们做出更明智的决策。希望能这样,毕竟每个人都有自己的模型并分别服务,听起来很复杂,但也许未来就是这样。
Nicole:但我确实认为美学会有很大差异。我觉得在某种程度上,个性化必须在那个层面实现。你在Google购物标签页就能看到,比如你在找毛衣,系统会给你推荐一堆,但你其实希望聚焦于自己的美学,甚至能从你的衣柜中选出搭配。我希望这些都能在模型的上下文窗口里实现。我们应该能把你衣柜里的图片喂给模型,然后帮你找出合适的搭配。我对此很期待,希望能做到。也许还需要更高级的美学控制,但我觉得那可能更多发生在专业用户层面。
在语言模型领域,甚至在图像领域,很多决定其实都取决于预训练时用的数据,这直接影响了模型的最终能力和美学风格。所以我也很好奇,未来会不会有一个万能模型,通过提示就能覆盖所有图像用例?还是会有各种风格的模型?
Nicole:我们一直对现成模型能支持的用例范围感到惊讶。你说得很对,很多面向消费者的用例,比如你只是想画出房间的效果图,这些都可以。但一旦进入更高级的功能,就需要集成其他工具来让它成为最终产品,在营销或设计等工作流程中发挥作用。
Jacob:大家肯定很好奇,这些模型为什么会变得这么好?
Nicole:有很多特别的原因。
Oliver:其实没有某个单一因素,而是把所有细节都做好了,真正调试好配方,还要有一个长期专注于这个问题的团队。我们其实也被模型的成功程度吓了一跳。我们知道模型很酷,很期待发布。但当我们在LM Arena上线后,不仅Elo分数很高,这当然很好。分数高是模型有用的好迹象,但对我来说,真正的指标是有大量用户涌入LM Arena使用模型。我们不得不不断增加每秒查询量,完全没预料到。这是第一次意识到,这确实是非常有用的东西。有很多人都需要这样的模型。
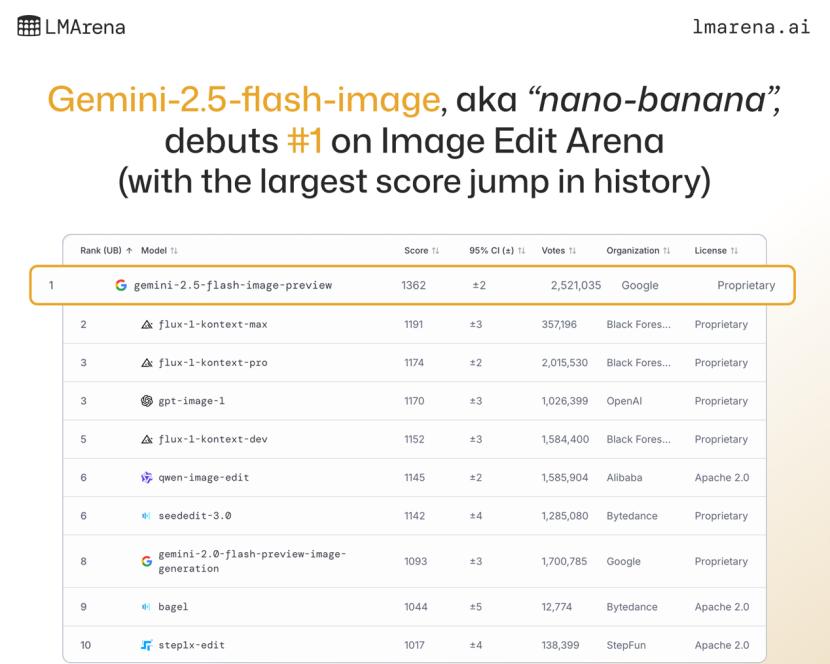
上线后Nano Banana的Elo分数明显领先(来源:LM Arena网站)
Jacob:我觉得这是这个生态系统最有趣的部分。你们自己构建模型时有些预期,但只有真正发布到用户手中,才能发现它的强大和影响力,这次显然引发了巨大反响。
显然,模型的推理能力很大程度上受益于语言模型本身的进步。你能否介绍一下图像模型从语言模型进步中获得了多少好处?你认为这种趋势会随着LLM发展继续吗?
Oliver:当然受益,几乎100%依赖语言模型的世界知识。比如Gemini 2.5 Flash Image(就是这个模型的名字)。
Jacob:名字有趣一点就好了。
Nicole:(Nano Banana)确实更容易读。
Oliver:我有点好奇我们的成功是不是因为大家喜欢说Nano Banana这个名字。但它确实是Gemini模型的一部分,你可以像和Gemini对话一样和它交流,它懂Gemini懂的所有东西。这是这些模型迈向实用性的关键一步,就是和语言模型整合。
Nicole:你可能还记得,两三年前你必须非常具体地描述需求。比如“桌子上的猫,背景是什么,这些颜色”,现在不用那么详细了。很大原因就是语言模型变得更强了。
Jacob:不再是后台魔法提示转换了。以前你输入一句话,系统会自动扩展成十句话的详细提示,现在模型本身就足够聪明,能理解你的意图,这真的很让人兴奋。
如何打磨产品、多模态和语音AI的潜力
Jacob:从产品角度看,你们有各种不同类型的用户。有些是专家,一上线就去LM Arena玩模型,他们很懂怎么用;还有很多普通Gemini用户,面对“空白画布”完全不知道该做什么。你们是怎么考虑为这两类用户打造产品的?
Nicole:我们还有很多可以做的。你说得对,LM Arena的用户和开发者都很专业,能用这些工具创造我们没想到的新用例。比如有人在照片里把物体变成全息影像,我们根本没训练过这种场景,但模型表现得很好。对于普通消费者来说,易用性极其重要。现在你进入Gemini应用,会发现到处都是香蕉表情。我们这么做是因为大家听说Nano Banana后去找,但应用里没有明显入口。
我们做了很多工作,比如和创作者合作预置一些用例,放出直接链接到Gemini应用的示例,提示会自动填充。我觉得“零状态”问题还有很大改进空间,比如用视觉引导用户。未来还可以让手势成为编辑图片的方式,不只是靠文字提示。
有时你想要很具体的效果,还是需要很长的提示,但这对大多数用户来说并不自然。所以我会用“父母测试法”——如果我父母能用,那就合格了,现在还没做到,所以还有很长路要走。
很多问题其实就是要“展示而不是讲述”,给用户易于复制的示例,让分享变得简单。没有一个魔法答案,需要多方面共同努力。
Oliver:我们还发现社交分享在解决“空白画布”问题上很重要。用户看到别人做的东西,因为模型默认就能个性化,可以用自己的照片、朋友、宠物尝试,非常容易就能模仿,这也是模型传播的重要方式。
Jacob:现在大家都是用文本和模型互动,你们对未来还有什么新型设计界面感到兴奋吗?
Nicole:我觉得我们才刚刚开始探索可能性。最终我希望各种模态能融合在一起,界面能根据任务自动切换最合适的方式。现在大模型不仅能输出文本,还能输出图片和视觉解释,满足用户需求。
我觉得语音很有潜力,是很自然的交互方式,但还没人真正做出很棒的语音界面。现在我们还是在输入文字,所以未来可能结合暂停、手势等,比如你想擦除图片中的物体,应该能像在草稿本上一样操作。如何在不同模态间无缝切换,是我非常期待的方向,还有很多空间去探索实际形态。
Jacob:你觉得语音的限制是什么?我完全能想象和图片对话。
Nicole:有些问题是优先级的,我们还在推进模型能力,语音这两年也进步很大。我觉得很快会有人尝试,也许我们也会做一些相关工作。
问题在于如何检测用户意图,然后根据意图切换不同模式,因为并不明显。你可能又回到“空白画布”问题,怎么向用户展示功能?我们发现用户进来后对聊天机器人期望很高,觉得它什么都能做,实际上很难解释限制,也很难展示所有功能,尤其工具能力越来越强时。所以要想办法划定范围,在UI里展示可能性,帮助用户完成任务。
Jacob:而且你教会用户某个时刻机器人能做什么,三个月后又得重新教,因为功能已经变了,这也是很有意思的产品挑战。
很多产品都有评估机制,你们有自己的评估数据集,比如Nicole自己的照片。图像模型的评估通常是什么样?除了放到LM Arena让用户体验外,你们在追踪模型进步方面有哪些经验?
Oliver:语言模型和视觉语言模型进步的一个好处是能形成反馈环,用语言模型的智能来评估自己生成的内容。这形成了良性循环,可以同时提升两个维度。
但最终,用户才是他们想要图片的裁判。所以像LM Arena这种用户自己输入提示的场景,是评估模型的最佳方式。
Nicole:品味也很重要。Oliver不会夸自己,其实他在团队里很擅长判断图片效果,能发现问题和缺陷。我们团队有几个人专门做这种“眼球评估”,就是技术性地看模型输出效果,这在初期仍然很重要。我们也会收集用户反馈,包括X(推特)上的意见,看看哪些地方有效,哪些地方需要改进,然后调整评估标准,既保证已有功能不退步,也推动社区关心的方向。欢迎大家持续反馈。
Jacob:感觉这比语言模型难多了,比如法律用例有标准答案,模型偏离时有纯粹的评估数据集。但图片很主观,很难明确爬坡方向。比如角色一致性能量化,但主观性确实让优化变得很难。对了,Nano Banana这个名字有什么故事?
Nicole:我们团队有个PM叫Nana,她凌晨两点半在准备发布时想出了这个名字,然后大家觉得很有趣就用上了,现在甚至成了半官方名字。毕竟Gemini 2.5 flash image太难念了。
Jacob:确实很成功,连Google CEO都在发香蕉表情,名字的影响力很大。
Alphabet CEO Pichai在模型发布后的社交媒体信息(来源:X.com)
Nicole:品牌建议就是名字最好有合适的表情符号,这样更容易传播。
Jacob:感觉Hugging Face是AI界最早用表情做品牌的,现在我们离公司股票代码都是表情的时代也不远了。
专业用户的潜在应用场景
Jacob:回到刚才的话题,你们有很多专业用户,也有很多面对空白屏幕不知道做什么的普通用户。你们见过最专业的用户有哪些用法?
Oliver:我最喜欢的高级用例是视频相关的。我大部分职业生涯都在做视频工具,发现Nano Banana在AI生成视频方面非常有用。比如结合视频模型(VO3)可以更快地构思、规划镜头,这其实也是电影制作的流程,先做分镜,再拍摄。现在大家用它构建更连贯、更长的视频内容。
Nicole:我对大家用它在建筑设计流程中的表现印象很深。可以从蓝图到类似三维模型,再到设计图,快速迭代,节省了繁琐的流程,让人专注于创意和乐趣。这种效果出乎我的意料,模型开箱即用就能做到。
Jacob:感觉是各种“五分钟编码”图像用例,帮你快速搭建基础内容。
Nicole:还有网站设计,以前从提示直接生成网站代码,总觉得中间少了一个步骤,现在可以先快速迭代设计,满意后再编码。
Jacob:你觉得这会成为未来的工作流吗?确实很合理,为什么要先消耗算力生成代码,如果审美完全不满意,还得重来?
Nicole:而且这样更有趣。以前大家就在现有流程里用技术,现在大模型发展太快,能直接从提示到网站,非常惊人。但我觉得大家还是很喜欢在中间环节迭代,确保风格符合自己需求。
Jacob:你们既有模型也有API,未来会有各种接口和用例。你们如何区分哪些功能适合放在Gemini聊天工具里,哪些适合通过其他产品实现?
Nicole:体验很不同。我们看到大家会用Gemini做快速迭代,比如团队成员在重新设计花园时,会用Gemini想象效果图。然后再和景观设计师合作,把想法进一步完善。这是创意过程的第一步,很少是最终成品。而专业开发者会用更复杂的工具,串联多个模型,工作流更复杂。聊天机器人适合启发、灵感和分享,专业用户还是更需要视觉化的UI。
Jacob:编辑流程会如何融合进来?你们的API已经集成到Adobe等工具了,传统编辑流程会变得很不一样吗?还是最后从95%到100%完成度,还是需要传统编辑工具?
Oliver:很大程度上取决于用户。有些人对细节要求极高,像素级控制,这种场景必须和现有工具深度集成,比如Adobe产品。有些用户只是找灵感,要求没那么严格,聊天机器人快速生成想法就够了。所以两者都是模型的重要应用。
Nicole:像素级控制让我最近学到一个新点,比如做广告时,不同品牌对模特视线的位置有严格要求,因为视线影响广告传达的信息。这种控制很难用聊天机器人实现,所以专业用户还是需要专门的精确工具。
Oliver:归根结底,看能否用语言描述。如果只是高层次想法,语言很合适,但如果要左移三像素,语言就不太优雅了。两种方式都有存在意义。
Jacob:看真正的艺术家或创作者的完整流程,他们很难用语言精确描述自己的操作,很多时候是凭感觉。Google内部也有很多团队对图像模型感兴趣,你们最期待它在Google各产品中的应用有哪些?
Nicole:创意方面,比如在Google Photos做照片编辑很有前景,毕竟你的图库就在那儿。比如把家庭照片直接变成生日卡片,我每年都用得上。如果能直接在Photos里做很棒。
还有像一开始说的“事实性”用例也很有趣,比如让模型用适合五岁孩子的方式解释光合作用,并生成视觉化内容,这在网上可能都找不到。这样能为用户开启个性化、视觉化的学习体验。
Oliver:还有Workspace,比如PowerPoint和Google Slides。让大家能做出更有吸引力的演示文稿,不再千篇一律。
Jacob:作为前咨询行业人士,如果能实现就太棒了,大家都花太多时间在排版上了。
Nicole:以前都是先在白板上画出幻灯片结构,写好标题。比如左侧放某个数据集的图表,然后把这些信息交给大模型,让它帮你完成很多工作,我对此非常期待。
图像模型的未来:小团队有机会,但调用世界知识需要大模型支持
Jacob:回顾近几年图像模型的发展,从Stable Diffusion到Mid Journey,Oliver你怎么看这几年的主要里程碑?整个路径和变化你怎么总结?
Oliver:这几年发展简直像火箭一样。我早期做这方面时,GAN(生成对抗网络)是主流方法,我们对GAN能做的事很惊讶,但它只能生成很窄分布的图片。
比如可以生成看起来不错的人脸,但只能是正面照。后来出现能泛化、完全由文本控制的模型,虽然起步时很小很模糊,但很多人都觉得这会改变一切,于是大家都全力投入,但没人能预料到进步速度如此之快。
我认为这得益于很多顶尖团队的良性竞争。大家看到其他团队出色的模型,比如Mid Journey一度遥遥领先,效果惊人,大家都很受激励,想知道他们怎么做到的。
尤其Stable Diffusion开源后,展示了开发者社区的规模,很多人愿意在这些模型上构建产品,这是另一个重要节点。从那以后,整个领域发展非常快,虽然有时压力很大,因为不仅模型变强了,用户期望也越来越高。现在大家会抱怨一些小问题,但一年前我们还在为不真实的图片感到惊讶。人类对新技术的适应力真的很强。
Jacob:确实,如果2017年有人告诉我们会有如此强大的技术,我们肯定会震惊,但现在大家总是抱怨不足。这也是人性有趣的地方。你怎么看Mid Journey当初能领先一步的原因?他们一度是行业标杆,所有人都盯着它。
Oliver:Mid Journey比其他团队更早掌握了后训练技巧,尤其是让模型生成风格化、艺术化图像。他们一直专注于风格控制,确保生成的图片都很漂亮。刚开始时,聚焦于高质量图片的小领域是很好的策略。后来所有模型,包括Midjourney和Flux等,都扩展到更广泛的类别,同时保持高质量。
Jacob:是什么让模型能生成更广泛的图片,不再只挑选完美作品?
Oliver:有很多原因,大家都不断完善细节,尤其是数据质量。同时,模型规模自然扩大,算力提升,很多以前做不到的事现在都能实现了。
Jacob:你刚才也提到,我们在图像模型上取得了巨大进步,我很难判断还剩多少提升空间。你怎么看未来三年?我们会不会回头觉得现在的模型其实还很一般?
Oliver:我完全支持后者观点。仅就图像质量而言,还有很大提升空间。未来的改进点在于模型的表达能力。现在我们能完美生成一些常见内容,完全无法分辨是生成的还是现实的。但只要超出常规场景,质量就会迅速下降,尤其是需要更多想象力、组合多概念的提示。这类场景模型很快就崩溃了。
未来模型最好的图片可能和现在一样好,但最差的图片会大幅提升,模型会更有用、适用范围更广。我们发现模型越泛化,可支持的用例越多,价值也越大。
Jacob:你怎么看图像模型领域的未来格局?相比大模型领域,主要是你们、OpenAI、Anthropic等大玩家,图像模型会类似吗?
Oliver:这是个好问题。到目前为止,图像领域小团队也能做出顶级模型。我们看到一些小实验室的作品非常惊艳。我希望这种情况能持续,因为我喜欢小团队的创新。
但模型的世界知识、实用性很需要规模,尤其是语言模型的规模。所以我猜未来还是大型团队能同时训练强大的语言和图像模型。我们看到中国的大型实验室也在推出很棒的模型,和语言模型一样,所以未来他们也会成为图像领域的重要玩家。
Jacob:如果用最好的开源模型而不是闭源模型,会有很大劣势吗?
Oliver:这很难说,取决于开源模型的未来,变化很快。一年前可能觉得开源很安全,现在不一定。但开源确实有可能支撑很多小团队继续创新。好模型肯定可以。
Jacob:Oliver,想问你一个问题。你之前做视频很多年,我一直想弄明白图像模型和视频模型的关系。你们团队在视频方面也有很大突破。两者是独立的吗?还是互相借鉴?现在图像和视频领域是怎样互动的?
Oliver:非常密切相关。未来大家都在向“全能模型”发展,就是能做所有事情的模型。这些模型有很多优势,可能最终会胜出。
我觉得我们在图像生成领域学到的很多技术都应用到了视频生成模型,反之亦然。这也是视频生成能迅速发展的原因之一,因为整个社区都在学习如何解决这些问题。所以我觉得两者是非常亲密的“朋友”,很多技术共享,未来可能会完全融合。
Jacob:你说的技术,就是很多底层方法在不同模型间都很相似吧?
Nicole:连工作流也很像。很多用户会把这些模型结合使用。比如电影制作,最初的构思在大模型领域,然后在图片或帧空间迭代,因为更快更便宜,最后才进入视频阶段。所以从工作流和可用性角度看,图像和视频模型之间有很多互补性。很多用例和问题都是共通的,比如角色、物体、场景一致性,图像和视频都有,只是视频更复杂。
Jacob:你觉得视频领域下一个要解决的难题是什么?
Oliver:我觉得在视频领域获得和最新图像模型一样的控制力,会非常有影响力,这是值得关注的方向。视频团队也在提升分辨率和时间一致性,当然还有跨场景角色一致性,大家最关心的就是这个。未来肯定会朝着更长、更连贯的内容发展。
Jacob:这些问题可以在图像领域先解决,很多方法都能迁移到视频领域,这很酷。今天聊得很精彩,我们最后有一组快问快答。
首先,你们认为目前AI领域有什么被高估,什么被低估?
Nicole:我觉得被高估的是“一个简短提示就能生成可用于生产的成果”。其实还需要很多迭代。即使是社交媒体上大家分享的内容,背后也有很多工作。所以这个有点被过度宣传了。被低估的是未来的融合,我们已经聊过了,就是如何让大家更容易使用这些模型,展示可能性,并针对具体工作流提供帮助。
Jacob:你见过哪些产品,在UI设计上有新颖的想法?
Nicole:我还在等,暂时没看到。
Oliver:我喜欢节点式界面,但这不是大众化的设计。
Jacob:未来每个人都能有自己的UI,也许会进入个性化时代。你觉得明年图像模型的进步会比今年更快,还是差不多?
Nicole:希望更快。
Oliver:有更多聪明人投入,更多资源,肯定会加速进步。
Jacob:你们已经让Nano Banana火遍全网,还有哪些AI图像领域的趋势是你们关注的,但大家没有足够重视?
Nicole:我觉得是“事实性”维度。比如大家用Nano Banana做信息图或给尼亚加拉瀑布标注,虽然演示效果不错,但仔细看文字还是有点混乱,不够准确,会重复信息。所以这是下一个前沿,大家还没太关注。
Oliver:这和文本语言模型很像。GPT-1和2刚出来时,大家觉得很酷,可以写俳句、做创意任务,答案范围很广。现在大家都用语言模型做信息检索、对话、陪伴等。所以我觉得图像领域也会有类似变化,从创意工具到信息检索工具,未来甚至会有人和视频模型对话,这很有可能出现。
Nicole:模型也应该更主动,现在都是用户主动请求图片。如果查询本身适合用图片回答,模型应该主动生成。我们在搜索中已经习惯了,有时返回文本,有时返回图片,有时两者都有。所以我也期待模型能更主动、更智能地根据需求选择模态。
Jacob:我很喜欢这种无缝切换的未来。正如你说的,可靠性是关键。早期语言模型偶尔很惊艳,但远不够稳定,工作场景用不了。图像模型也会经历类似的进化。
最重要的问题:你们最喜欢用Nano Banana生成的内容是什么?
Oliver:我最喜欢的是和孩子一起玩模型,把他们放到各种有趣场景里,让他们的玩偶“活”起来。这些内容非常个人化,孩子们很喜欢,对我来说最有价值。
