

在过去几十年里,国际大学生程序设计竞赛(ICPC)一直被视为计算机程序设计领域的“奥林匹克”。然而今年,赛场上的风头却被两位“非人类”选手抢走——OpenAI 的 GPT-5 和 Google DeepMind 的 Gemini 2.5 DeepThink。
GPT-5 和 Gemini 2.5 Deep Think 作为参赛模型,受 ICPC 官方规则与组织监督,参与了与人类选手相同的解题环节。虽然它们并非与学生团队直接同场竞技,却交出了惊艳答卷:
● GPT-5 拿下满分,12 道题全解,相当于“金牌”水准。
● Gemini 2.5 Deep Think 在 677 分钟内解出 12 题中的 10 题,也达到金牌级别。根据谷歌的说法,这样的成绩放在人类排名里将是全球第二。
要知道,本届 ICPC 的人类金牌队伍来自圣彼得堡国立大学、东京大学、北京交通大学和清华大学。可即便是这些顶尖学府的强队,也没有任何一支做到全对(最好成绩是 11/12)。换句话说,这是 AI 第一次在这类算法竞赛中实现了“超车”。
ICPC:程序员的“奥林匹克”
ICPC 是全球最顶尖的大学生编程赛事,自 1970 年代起,这项赛事就汇聚了全球高校最顶尖的算法天才。今年,ICPC 总决赛共有来自 103 个国家、139 所高校的战队参赛,大赛规则看似简单:
● 每支队伍由三名大学生组成;
● 5 小时内解答 12 道算法题;
● 排名取决于解题数和用时。
但背后的难度远超一般编程比赛。据悉,ICPC 的题目常涉及图论、数论、动态规划、组合优化、网络流等前沿算法。既考察编码速度,也考察数学功底与团队合作。历年来,能在 ICPC 拿到金牌的队伍,几乎都成为了全球科技公司的核心技术人才。
也正因为 ICPC 的权威与挑战性,本届 AI 的入局显得尤为标志性:这是把AI直接推上了最严苛的算法竞技场。
GPT-5 给出完美答卷,Gemini 2.5 解出人类没有答出的问题 C
根据 OpenAI 官方披露,GPT-5 参赛时并没有针对 ICPC 做特别训练,也没有任何“外挂”工具。它像其他人类队伍一样:直接拿到同样的 PDF 赛题、通过官方判题系统提交答案、在 5 小时内完成所有解答。
结果令人瞠目:有 11 道题都是一遍过,唯一的难题在第 9 次提交时才解出,最终达成 12/12 满分——要知道,今年人类最强队伍的成绩是 11/12,而 GPT-5 直接拿下满分,这在 ICPC 的历史上极为罕见。
基于此,OpenAI 也在 X 平台分享了 GPT-5 的成绩:
“我们在 ICPC 的 AI 赛道正式参赛,同样是 5 小时解 12 道题,答案由 ICPC 评测系统实时判定。结果显示,12 道题中有 11 道题一次提交就通过,最难的一题则是在第 9 次提交时才解出。最终,GPT-5 完成了全部 12 道题,而最好的人类队伍只解出 11 道。”
与此同时,Google 也公布了 Gemini 2.5 Deep Think 的比赛细节:45 分钟内解出 8 题;3 小时内解出 10 题;更令人震惊的是,Gemini 在比赛前半小时内,就成功解决了问题 C——一道没有任何大学队伍解出的难题。
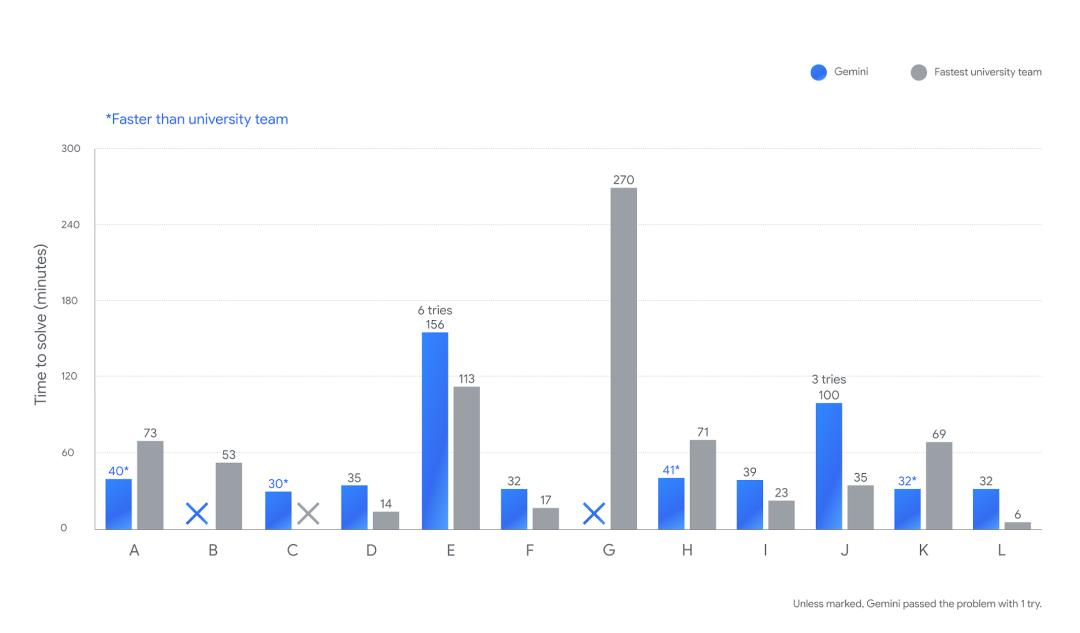
据悉,这道题目要求:在由多个水库和管道组成的复杂网络中,找到一种管道开关配置,使所有水库在最短时间内被注满。每条管道可以开、关或部分开启,组合几乎无限,导致搜索最优解极其困难。
面对这道题,Gemini 2.5 Deep Think 的解题思路堪称“巧妙”:
1、先为每个水库设定一个“优先级值”,表示它相对于其他水库应被分配的程度;
2、在给定优先级值后,通过动态规划找到最优管道配置;
3、进一步应用极小化极大定理,将问题转化为寻找“最受约束”的优先级组合;
4、最后在凸优化空间中,利用嵌套三分搜索快速收敛到最优解。
这一思路并非赛题官方题解的“标准做法”,而是模型自己推演出的路径。换句话说,Gemini 在赛场上展示了超越记忆的原创性算法思维。为此Google 也在博客中强调,这不仅是一次正确解答,更是一次“创造性突破”。
为什么这次意义非凡?
其实,大模型在各种考试、基准测试中的高分表现早已不是新闻:
● ChatGPT、Gemini 等 LLM 在 SAT、律师资格考试、托福等人类考试中屡屡高分;
● 今年7月,Gemini在国际数学奥林匹克(IMO) 拿到金牌;
● 在各种 NLP、逻辑推理 benchmark 上,LLM 也早已“刷榜”。
但这些成绩往往被质疑为“靠记忆训练数据”或“靠海量算力暴力搜索”。而 ICPC 这种现场算法竞赛不同:首先题目新颖,几乎不可能出现在训练语料中;其次需要综合运用数学建模、推理和代码实现;最为重要的是,必须在有限时间内找到解法,而不是离线慢慢思考。
此次GPT-5 与 Gemini 2.5 Deep Think在ICPC中的表现,证明了它们已经具备临场推理、抽象建模、创造性解题的能力,这比在标准化考试中得高分更能说明问题。为此在社交媒体上,许多 AI 工程师感叹:“过去我们担心 AI 只是会背题库;现在它在现场比赛里击败人类冠军。这感觉像是见证了‘人机智力平权’的时刻。”
这不是终点,而是一个开始。接下来,AI 是否会把这种能力扩展到更复杂的现实问题中还有待考验,但可以确定的是:如今,AI 不再只是“会写代码的助手”,而是真正具备了与人类智力正面对抗的实力。
