

Grok-4-fast最近在降本增效上的表现堪称一骑绝尘,连有「路由器」傍身的GPT5都给干趴下了。
面对如此惊艳的推理效率,很多人第一反应就是:堆卡式的算力scaling又一次大显神威了。
实际上,Grok的背后确实有英伟达的影子。
但这次立功的,或许不是老黄的显卡,而是算法。
没错,Grok-4-fast的秘密武器,被和一篇英伟达的算法论文关联在了一起。
让LLM快53倍的火箭发动机
正如Grok-4-fast所表现出来的一样,这篇论文解决了困扰行业已久的推理成本问题。
一味的硬件Scaling只会让模型厂商账单上的数字越来越长,用户耐心也在漫长的推理时间中逐渐被消耗殆尽。
为此,英伟达研究团队推出了一种全新「混合结构」模型——Jet-Nemotron。
经过一系列全面的基准测试,发现Jet-Nemotron-2B的表现与Qwen3、Qwen2.5、Gemma3和Llama3.2等顶尖开源模型不相上下,还能实现约53倍的速度提升。
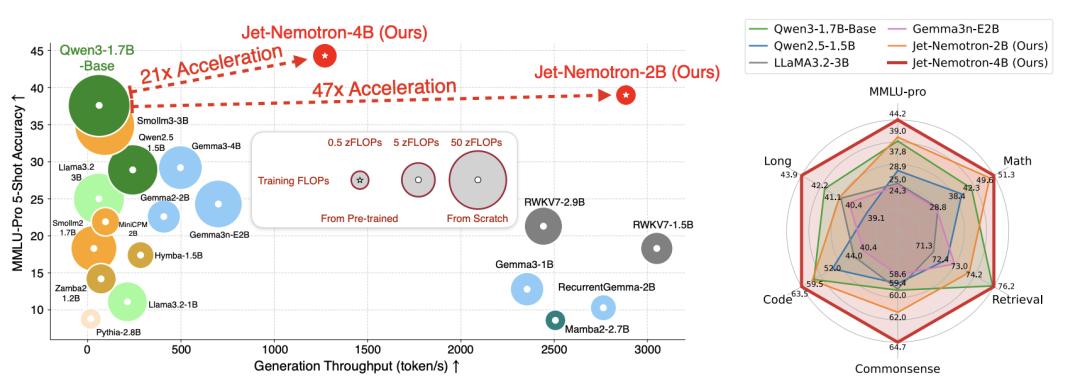
例如在MMLU-Pro上,Jet-Nemotron-2B不仅准确率比Qwen3-1.7B-Base更高,就连生成速度也要快上47倍。
此外,Jet-Nemotron-2B即便遇上参数更大的模型也丝毫不虚,它在MMLU和MMLU-Pro上的准确率甚至可以超过DeepSeek-V3-Small和Moonlight(总参数量15B,激活参数量2.2B)。
改变这一切的关键,在于一个叫PortNAS的新框架。
不同于以往的方法,PostNAS不是从零开始训练,而是以一个预训练的全注意力模型为起点,并冻结其MLP权重,只探索注意力机制的改进。
这样一来,不仅能让训练成本直接降低几个数量级,还能有更多精力用于全面探索模型结构。
其流程包括四个核心部分:全注意力层放置、选择最优的线性注意力模块、设计更优的线性注意力模块、硬件感知架构搜索。
全注意力层放置
大多数团队会在模型的所有层里统一使用全注意力,但这会浪费算力资源。
因此,英伟达团队希望保留少量关键的全注意力层,以维持复杂任务的准确性,同时剔除冗余层以提升效率。
PostNAS的做法是:先构建一个同时包含两种注意力机制的超级网络,再通过特征蒸馏来训练子网络,最后用beam search找到最优的注意力层放置方案。
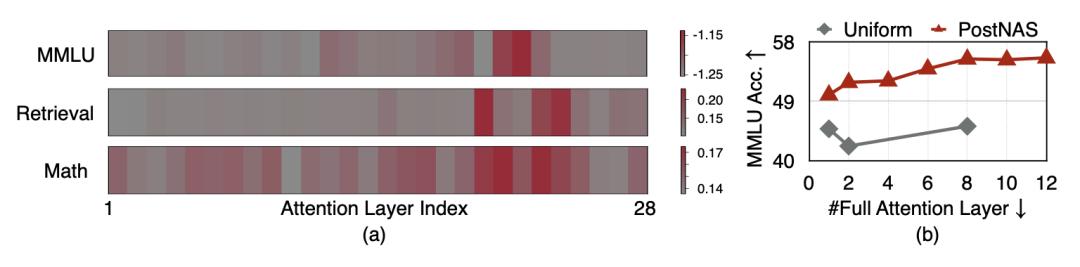
事实证明,的确并非所有注意力层都重要,不同任务依赖不同层,少量关键层即可覆盖大部分任务需求。
实验结果显示,PostNAS优于均匀放置策略——在只使用2层全注意力的情况下,PostNAS的准确率约49%,而均匀放置的准确率约40%。
选择最优的线性注意力模块
在确定了全注意力层后,英伟达团队开始进行注意力模块搜索,旨在找到目前最优的线性注意力模块。
论文评估了六种当前最先进的线性注意力模块,包括RWKV7、RetNet、Mamba2、GLA、DeltaNet和Gated DeltaNet。
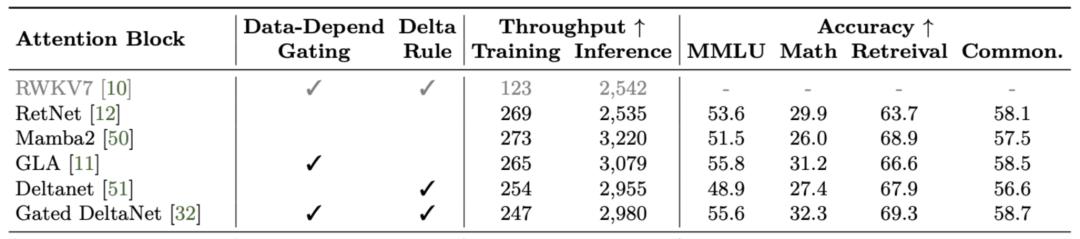
这六个之中,Gated DeltaNet的准确率最高,这主要归功于两个因素:
1、数据依赖门控机制(Data-Dependent Gating Mechanism):可以理解成一个路由器。模型会根据输入的内容,决定是更重视新信息,还是之前的历史状态,从而在不同任务里找到平衡。
2、Delta规则(Delta Rule):不是每次都把记忆里的东西全部覆盖,而是只更新新变化的部分。这样能减少不必要的重复存储,节省内存,同时保持信息的连续性。
更优解:JetBlock
不过,英伟达并不打算止步于Gated DeltaNet,而是设计了一款比它更强的线性注意力模块——JetBlock。
卷积对线性注意力模块的准确率至关重要,然而,以往方法大多使用的是静态卷积核,它们无法根据输入自动调整特征提取方式。
相比之下,JetBlock使用动态卷积,通过在线性注意力中引入一个卷积核生成器模块,JetBlock能根据输入特征动态地产生卷积核。
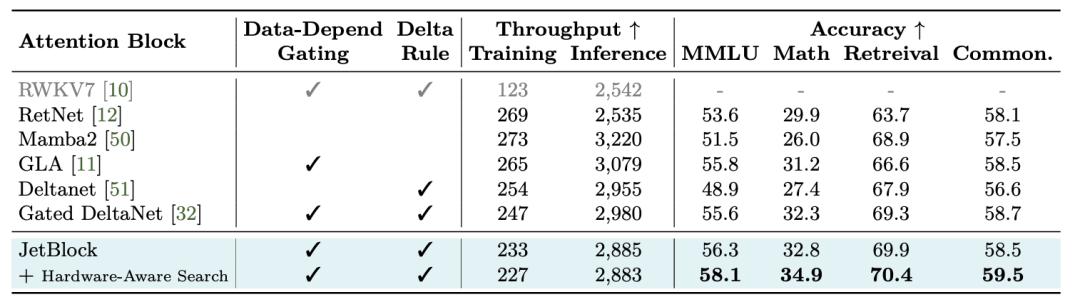
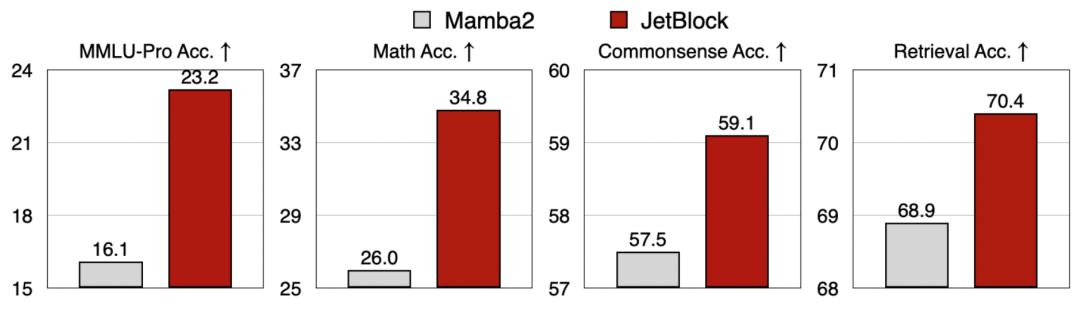
结果显示,JetBlock在数学推理和检索任务上的准确率优于Gated DeltaNet,而且仍然保持了不错的生成效率。
要是跟表现最差的Mamba2比起来,JetBlock的优势就更明显了。
硬件感知架构搜索
在确定了宏观架构以及选择了线性注意力模块之后,英伟达团队进一步进行了硬件感知架构搜索,用于优化核心超参数(key/value的维度、注意力头的数量…)。
过去,参数规模通常被作为衡量模型效率的主要指标,用来指导架构设计。
但英伟达团队认为这种方法并不理想,因为参数量并不能直接反映真实硬件上的效率。
对此,他们改进的方法是:以生成吞吐量作为直接目标来选择超参数。
英伟达团队发现,相比起参数量,KV缓存大小才是影响长上下文和长文本生成吞吐量的最关键因素。而当KV缓存大小固定时,不同参数规模的模型,其生成吞吐量表现相似。
基于此,英伟达团队选择保持KV缓存大小与原始设计一致,然后在key维度、value维度和注意力头数上进行小规模网格搜索。
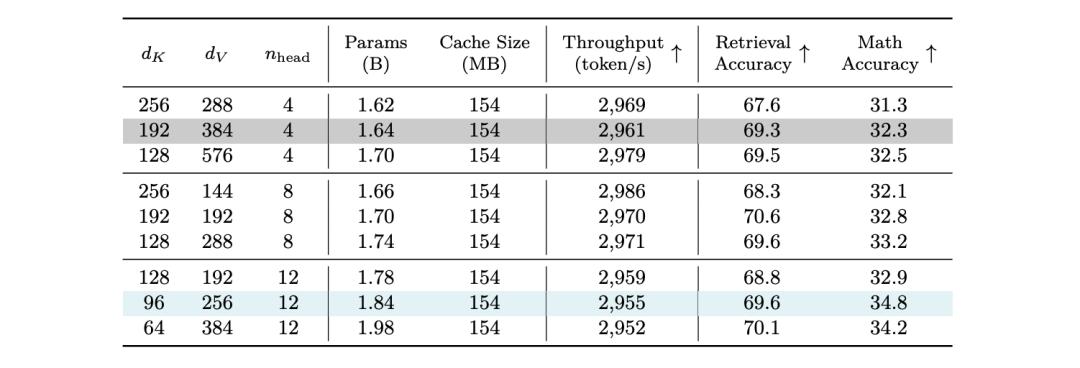
实验证明,优化后的版本在保持吞吐量不变的情况下,参数量增加(1.84亿 vs 1.7亿),同时数学准确率得到提升(34.8% vs 32.8%)(蓝色行代表实验组,灰色行代表对照组。)
综上,PortNAS有望为目前的AI行业带来三点影响。
1、推理阶段GPU使用时长减少47倍,这让LLM能够以更快的速度完成高质量任务。
2、更小的内存需求,这使得更廉价的硬件部署成为可能。
3、更高吞吐量,意味着模型厂商可在现有基础设施规模下服务更多用户。
而且,PostNAS提供低成本、高效率的架构探索方式,适用于任何预训练Transformer。
所以基本上,任何厂商都可以在不重新训练模型的情况下嵌入PortNAS,模型的成本可以大幅降低,同时准确率几乎不会受到影响。
此外,Jet-Nemotron居然还是开源的。
通讯作者Han Cai在Github上表示Jet-Nemotron的代码和预训练模型将在法律审查完成后发布。

感兴趣的朋友可以查看文末的链接~
Grok-4-fast的背后是英伟达?
同时看到Grok-4-fast和Jet-Nemotron二者同样惊艳且高度相似的表现,很难不让人怀疑老马和老黄这一次是不是联手了。
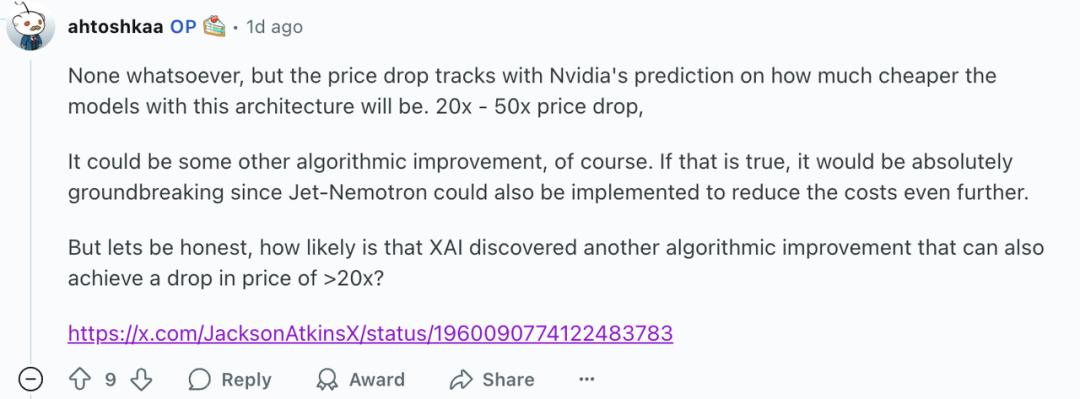
在Reddit上,有网友推测Grok-4-Fast应该就是基于Jet-Nemotron创造的。
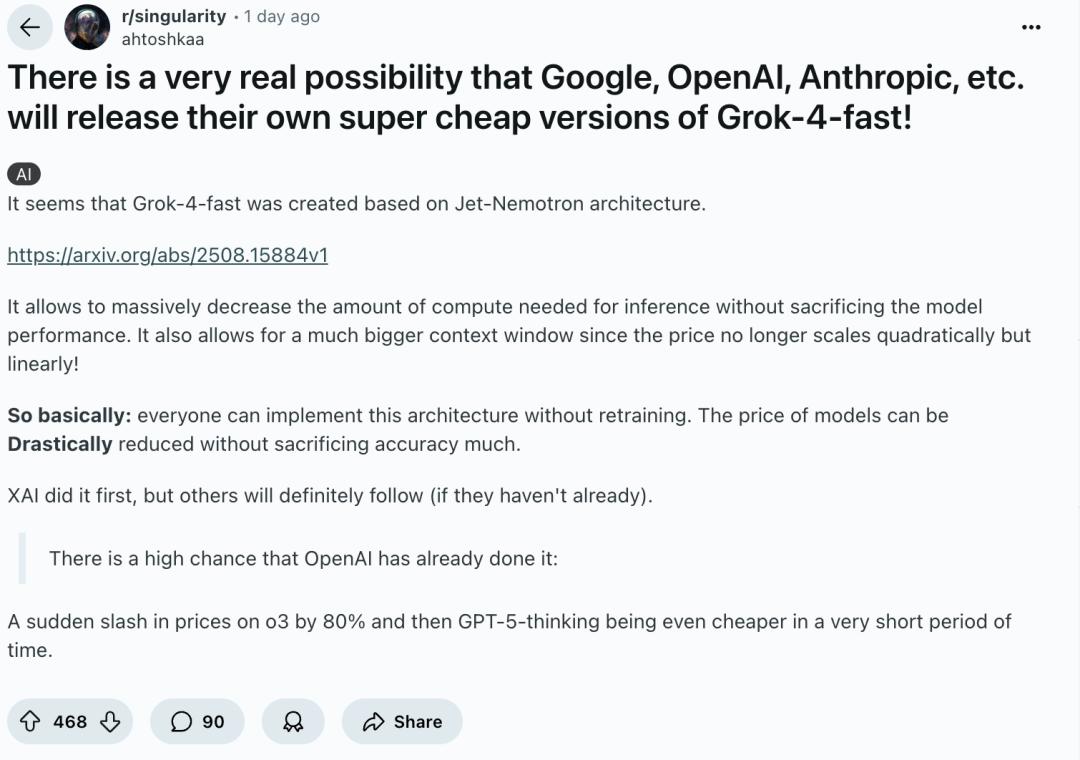
Jet-Nemotron可以在不牺牲模型性能的情况下,大幅减少推理所需的计算量,这与Grok-4-fast所展现出来的能力高度相似。
这一观点能从数据上得到支撑——从Grok-4-fast的定价来看,其价格下降水平与NVIDIA对这种架构模型的预测相符(论文预计会便宜20倍到50倍)。
更重要的是,如果Jet-Nemotron能够应用于Grok,那它同样能被OpenAI、Anthropic、Google等公司部署。
也有网友不同意这种说法,认为Grok此次的降价也许只是一种营销手段,并不能从中推断出xAI是否采用了什么新技术。
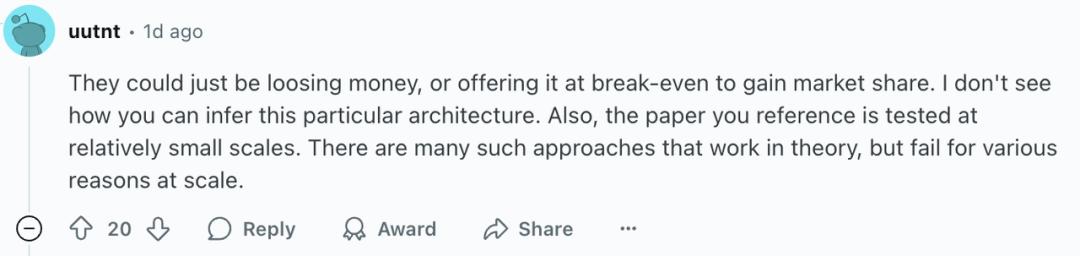
他们可能只是在烧钱获取市场份额,我不认为你可以从中推断出是采用了某种特定架构。
但是,即便Grok-4-fast没有采用英伟达的技术,这篇论文也是极有价值的,因为Jet-Nemotron同样可以被用来进一步降低成本。而且,xAI也不太可能在这么短时间研究出来了另一种和Jet-Nemotron一样效果显著的技术。
当然,也可能是其他算法上的突破。如果真是这样,那仍然是极具突破性的,因为Jet-Nemotron也可以被用来进一步降低成本。但说实话,XAI真的又发现了一个能让价格再下降20倍以上的算法改进的可能性有多大呢?
不过,上述观点都只是猜测,目前这些说法都未得到xAI验证…
华人学者的又一力作
Grok-4-fast是否真的采用了这项技术我们不得而知,可以明确的是,在这项突破性研究成果背后,是华人学者的又一次集中发力——论文作者全部为华人。

论文的一作是顾煜贤,他是清华大学计算机科学与技术系交互式人工智能(CoAI)课题组的四年级博士生,师从黄民烈教授。

顾煜贤致力于提升LLM在整个生命周期中各个环节的效率,包括预训练、下游适配以及推理阶段。
近期,他的工作重点放在LLM的数据策划策略研究、高效模型架构设计,以及运用知识蒸馏技术(knowledge distillation)进行语言模型压缩。
此前,他曾在微软亚洲研究院实习,由董力博士指导。他还曾作为访问学生赴麻省理工学院HAN实验室,导师为韩松教授。
论文的通讯作者是Han Cai,他目前是NVIDIA Research的一名研究科学家

在加入NVIDIA之前,Han Cai麻省理工学院EECS获得了博士学位,他的本科和硕士均就读于上海交通大学。
Han Cai的研究重心在于高效的基础模型(扩散模型、LLM等)、EdgeAI和AutoML,除了Jet-Nemotron,他还参与了不少英伟达的重要项目,包括ProxylessNAS、Once-for-all…
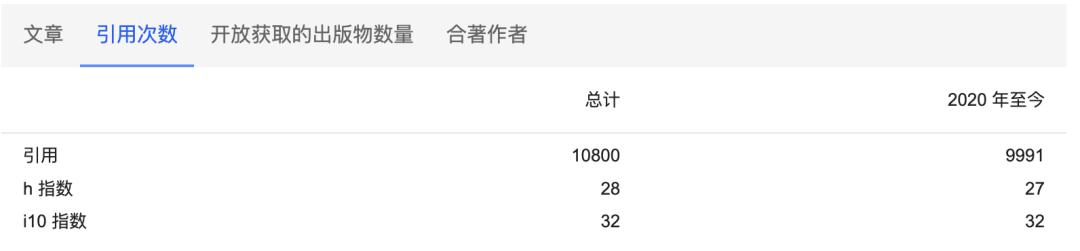
目前,他的论文在Google Scholar上累计被引用超1万次。
论文:
https://arxiv.org/pdf/2508.15884v1
Github:
https://github.com/NVlabs/Jet-Nemotron
参考链接
[1]https://pub.towardsai.net/jet-nemotron-nvidias-new-ai-architecture-achieves-53x-speed-improvement-71a5cf2baeeb
[2]https://www.reddit.com/r/singularity/comments/1nmzqj5/there_is_a_very_real_possibility_that_google/
[3]https://t1101675.github.io/
[4]https://han-cai.github.io/
