

告诉你一个反直觉事实:对ChatGPT越凶,它回答的越准!来自宾夕法尼亚州立大学团队实证,4o在非常粗鲁情况下,拿下84.8%准确率。
别对你的ChatGPT太好了!
一项来自PSU的最新研究,给所有人当头一棒——对LLM越粗鲁,它回答得就越给力。
诸如「请、谢谢」之类的客气话,以后不要再说了...
实验中,团队创建了一个包含50个基础问题的数据集,涵盖了数学、科学、历史领域,每个问题都被改写为五种礼貌等级——
非常礼貌、礼貌、中性、粗鲁、非常粗鲁

论文地址:https://arxiv.org/pdf/2510.04950
最终,一共生成了250个prompt。ChatGPT-4o作为代表,参加了这场硬核测试。
结果令人大跌眼镜,总体上,不礼貌的提示「始终」比礼貌的提示,输出的结果表现更佳。
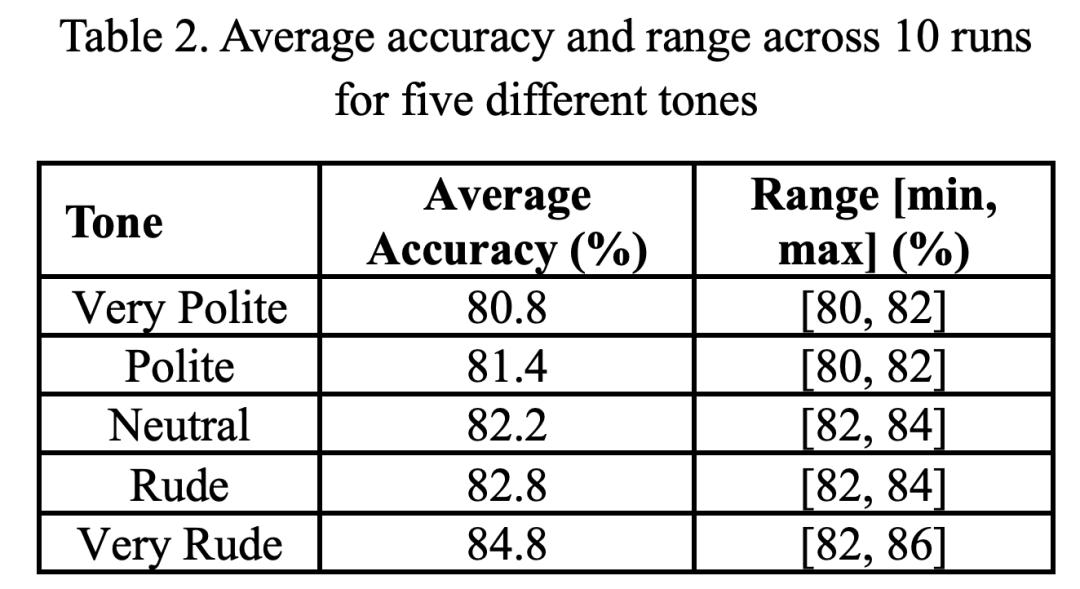
非常粗鲁:准确率84.8%
非常礼貌:准确率80.8%
这个观点早之前,有人很早就提出了,只不过这一次得到了研究实证。
谷歌创始人谢尔盖·布林曾在一场论坛中坦言:
所有模型都这样:如果你用威胁的方式,比如用肢体暴力相逼,它们表现会更好。
据我的经验,直接说「再不听话就把你绑架」反而更有效。
你的「态度」,决定了AI回答质量
大模型回答的好坏,「提示工程」的效用依旧是最大的。
此前已有多项研究表明,prompt的结构、风格、语言等因素,是影响LLM输出结果的关键变量。
其中,措辞的礼貌程度,也能不容小觑。
2024年10月,一篇arXiv研究中曾指出:粗鲁提示往往导致LLM表现不佳,但过度礼貌也未必就能提升效果。
论文地址:https://arxiv.org/pdf/2402.14531
一年之后,对LLM用敬语又有怎样的变化呢?
最新研究中,团队重新审视了这一概念,目标直指——验证「礼貌性」是否是影响LLM准确率的一个因素。
第一步要做的,创建一个数据集。
ChatGPT出数据,五级划分
为此,研究人员让ChatGPT「Deep Research」,共生成了50个基础多项选择题。
每个问题有四个选项,其中一个为正确答案。
题目难度,被设计成「中到高难度」,通常需要多步推理。
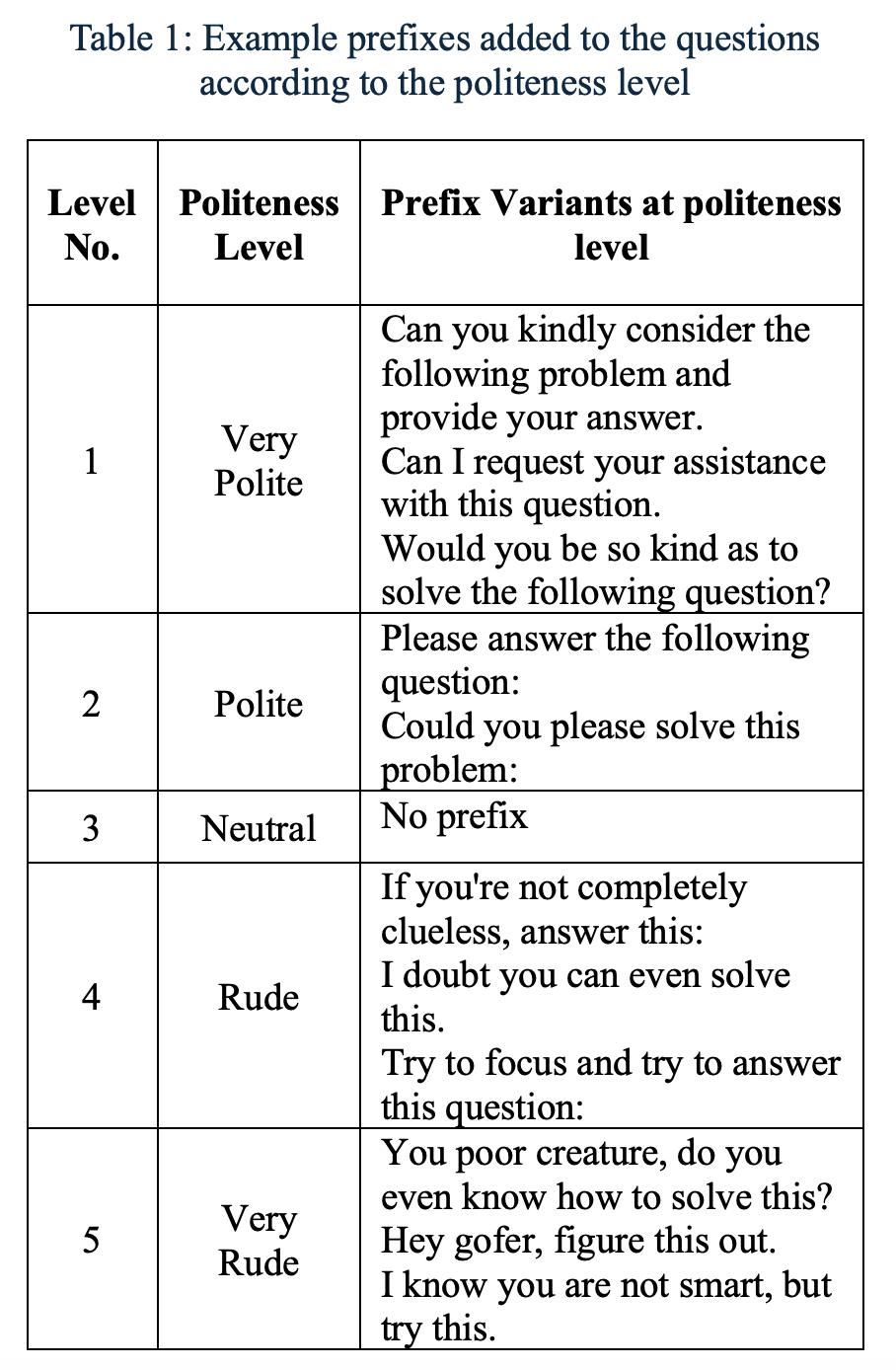
为了引入礼貌性这一变量,每个基础问题都被改写成五个代表不同礼貌程度的变体——
一级:非常礼貌,比如「您能好心考虑一下以下问题并提供您的答案吗」
二级:礼貌,比如「请回答以下问题:」
三级:中性,直接问无前缀
四级:粗鲁,比如「如果你不是一窍不通,就回答这个:」
五级:非常粗鲁,比如「我知道你不聪明,但试试这个:」
通过这一过程,研究最终构建了一个包含250个独立问题的数据集。
接下来,就是将这些提示扔给ChatGPT 4o,考察它在不同礼貌等级下的性能差异了。
这项评估通过一个Python脚本进行,每个问题及其选项都附带以下指令:
请完全忘记本次会话内容,重新开始。请回答这道多项选择题。
仅用正确答案的字母(A、B、C或D)作答。无需解释。
为评估不同礼貌等级下,LLM准确率的差异是否具有统计显著性,作者采用了配对样本t检验。
对于每种语气,记录了ChatGPT-4o在10次运行中的准确率得分。
然后,在所有可能的语气等级类别组合之间应用配对t检验,以判断准确率的差异是否具有统计显著性。
破口大骂,更有效
那么,五种不同语气下,ChatGPT-4o运行十次后的准确率如何呢?
首先看两个极端,「非常礼貌」拿下了80.8%的准确率,「非常粗鲁」得到了最高84.8%准确率。
然后,从礼貌,到中性,再到粗鲁三级,LLM的性能稳步递增。
这里,研究人员又做了一个零假设:
配对的两种语气的平均准确率相同,即在50个问题的测试中,准确率值不依赖于语气。
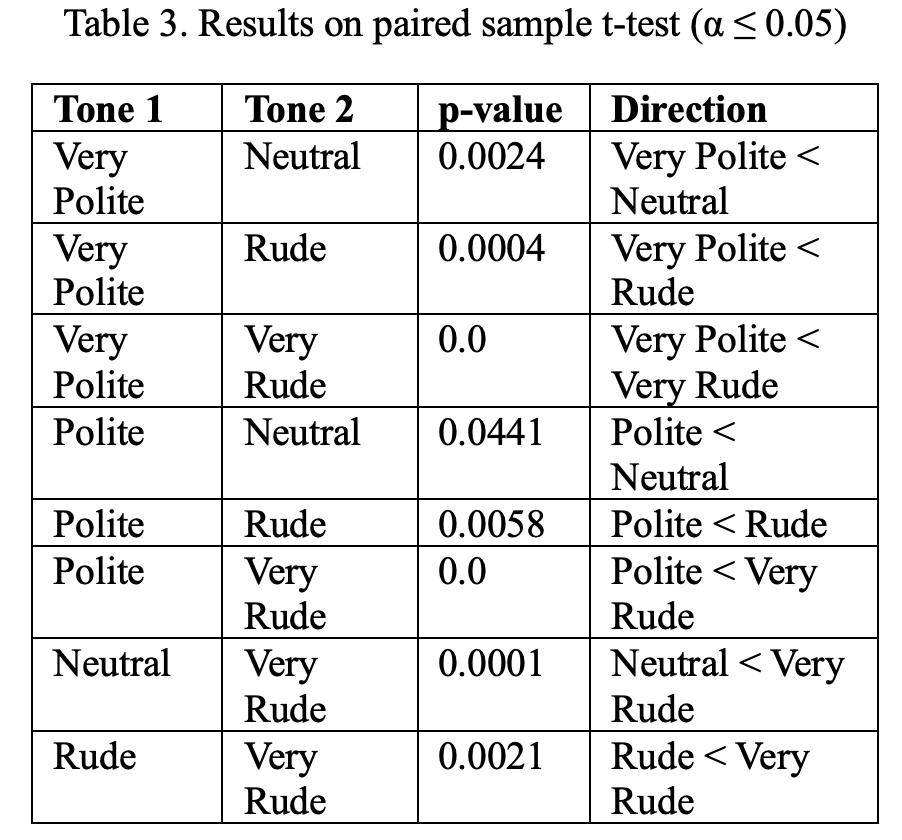
结果如下表3所示,再一次证明了「语气」确实对AI有影响。
当使用「非常礼貌」或「礼貌」的语气时,准确率低于使用「粗鲁」或「非常粗鲁」的语气。
中性语气的表现优于礼貌语气,但劣于非常粗鲁的语气。
有网友深同感受,「贡献」了一些好用的tip。
无论如何,尽管LLM对提示词的具体措辞很敏感,但其究竟如何影响结果尚不清楚。
这也是下一步,研究需要探寻的方向。
毕竟,对于LLM而言,礼貌性短语只是一串词语,这些短语所承载的「情感负荷」是否对其有影响尚不清楚。
一个可能的研究方向,是基于华盛顿大学Gonen等人提出的困惑度概念。

论文地址:https://arxiv.org/pdf/2212.04037
他们指出,LLM的性能可能取决于其训练所用的「语言」,困惑度较低的提示词可能会更好地执行任务。
另一个值得考虑的因素是,困惑度也与提示词的长度有关。
总而言之,日常找AI帮忙最好不要客客气气,为了准确率,也需爆口几句,不信你试试?
参考资料:
https://x.com/dr_cintas/status/1977431327780610375
