

“200 家 AI 初创公司中,73% 的产品实际上只是‘套壳’,主要套的还是 ChatGPT、Claude!”
这一结论一出,给 AI 创业圈带来不小的打击与争议。
回想 2023 年,OpenAI CEO Sam Altman 曾直言:“套壳 ChatGPT 注定消亡。”
然而现实恰恰相反:随着 ChatGPT 的爆火,创业热潮一浪接一浪,无数投资拥入,一些公司甚至尚未发布产品就已吸引不小的关注度。
如今,一位软件工程师 Teja Kusireddy 用数据扯开了这场“繁荣”背后的部分真相。他对 200 家 AI 公司进行了逆向工程、反编译代码,并追踪 API 调用,发现许多号称“颠覆性创新”的公司,其核心功能仍依赖第三方服务,只是在外层多套了一层“创新”的壳。市场宣传与实际情况之间的差距令人震惊。
那么,究竟是投资人“完全不懂”,还是 AI 初创公司“太会忽悠”?“自研”与“套壳”的界限如何而定?接下来,我们将通过 Teja Kusireddy 发布的长文,从他的第一视角,看看他用数据揭示的最新发现与结论。
为什么会发起“逆向工程”?
上个月,我掉进了一个意料之外的“兔子洞”,陷入了迷茫——一开始只是一个很简单的问题,最后却让我开始怀疑自己对整个 AI 创业生态的一切认知。
那天是凌晨两点,我在调试一个 webhook 集成时,偶然间发现了点不对劲的东西。
一家声称拥有“自主研发的深度学习基础设施”的公司,竟然每隔几秒就在调用 OpenAI 的 API。
而这家公司,刚刚凭着“我们构建了完全不同的 AI 技术”这一说法,从投资人那里融到了 430 万美元。
就在那一刻,我决定——要彻底查清这件事,到底有多复杂。
调查方法:我是怎么做的
我不想写一篇靠“直觉”发牢骚的热评,我要的是数据,一个真实的数据。
于是,我开始动手搭建工具:

接下来的三周里,我做了这些事:
从 YC、Product Hunt 和 LinkedIn 的“我们在招聘”帖子中,爬取了 200 家 AI 初创公司的官网;
- 监控它们 60 秒的网络流量会话;
- 反编译并分析了它们的 JavaScript 打包文件;
- 将捕获到的 API 调用与已知服务的指纹库进行比对;
- 最后,把它们在营销页面上吹的牛,与实际的技术实现一一对照。
我特意排除了成立未满 6 个月的公司(那些团队还在摸索阶段),重点关注那些已经拿到外部融资、并公开宣称有“独家技术”的初创公司。
得到了让我愣住的数据
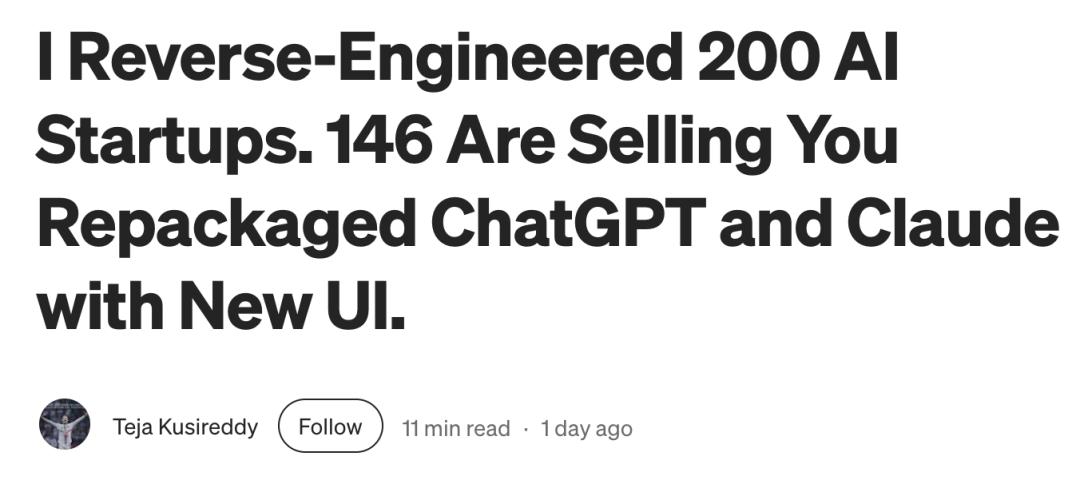
结果显示——73% 的公司,其宣称的技术与真实实现之间存在显著落差。
200 家的 AI 初创公司可以分为以下几类:
但真正让我震惊的,不只是这个数字。更让我意外的是——我甚至没有因此生气。
接下来,进行逐步拆解,可以分为三种模式。
模式 1:所谓“自研模型”,其实只是 GPT-4 加了点额外操作
每次看到“我们自研的大语言模型”这种说法,我几乎能预判下一步会发现什么。
结果 37 次里,有 34 次我猜对了。
技术特征揭秘:
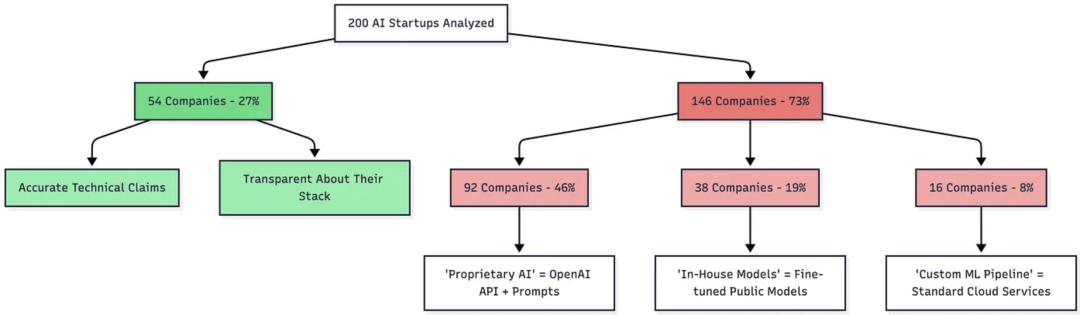
在我监控出站流量时,这些是明显的“蛛丝马迹”:
- 用户每次与所谓的“AI”互动时,都会向 api.openai.com 发起请求;
- 请求头(Request Headers)里包含 OpenAI-Organization 标识;
- 响应时间与完全符合 OpenAI 的 API 延迟模式(大部分查询 150–400ms);
- Token 使用量和 GPT-4 的计费等级一致;
- 速率限制的指数退避(exponential backoff)也和 OpenAI 一模一样。
真实案例曝光
有一家号称“革命性自然语言理解引擎”的公司,经过反编译后,我发现他们所谓的“自研 AI”就是这几行代码:

就是这样——整套所谓的“自研模型”,在他们的融资演示文稿里出现了 23 次。
- 没有微调
- 没有自定义训练
- 没有创新架构
只是给 GPT-4 下了一个“请假装你不是 GPT-4”的系统提示而已。
实际上,这家公司的成本与定价仅是:
- GPT-4 API:每 1K 输入 tokens 为 0.03 美元,每 1K 输出 tokens 为 0.06 美元
- 平均一次查询:约 500 输入 tokens,300 输出 tokens
- 每次查询成本:约 0.033 美元
他们对用户的收费标准是:每次查询 2.50 美元(或 200 次查询每月 299 美元)
直接成本利润率高达 75 倍!
更荒诞的是……我竟然发现有三家不同公司的代码几乎完全一样:
- 变量名一模一样
- 注释风格一模一样
- “永远别提 OpenAI” 的指令也完全一致
所以,我推断,这几家公司要么是:
- 抄自同一个教程
- 找了同一个外包工程师
- 用了同一个创业加速器的模板
还有一家公司额外加了所谓的“创新功能”:

他们在给投资人演示的文稿里,把这个功能称之为“智能回退架构(Intelligent Fallback Architecture)”。
在这里,我个人认为——包装 OpenAI 的 API 本身没有什么问题,问题在于这些企业把它叫作“自研模型”,背地里却只是个 API + 自定义系统提示。
这就好比:买了一辆特斯拉,换个徽标,就说自己发明了“专属电动车技术”。
模式 2:人人都在做的 RAG 架构(却没人承认)
相比第一种模式,这一类更微妙一些。RAG(Retrieval-Augmented Generation,检索增强生成)本身确实有用,但很多 AI 初创公司的营销宣传和实际实现之间的差距更为巨大。
他们吹嘘,声称自己研发了——“先进的神经检索 + 自研嵌入模型 + 语义搜索基础设施....”
实际上,他们拥有的是:

我发现有 42 家公司使用了几乎一模一样的技术栈:
- 嵌入模型用的是 OpenAI 的 text-embedding-ada-002(而不是“我们的自研嵌入模型”);
- 向量存储用的是 Pinecone 或 Weaviate(而不是“我们的专有向量数据库”);
- 文本生成用的是 GPT-4(而不是“我们训练的模型”)。
实际代码长这样:


这并不是说技术不好——RAG 确实有效。但把它称作 “自研 AI 基础设施”,就像把你的 WordPress 网站叫做 “定制内容管理架构” 一样荒诞。
再来算笔账,这家公司的实际成本(每次查询):
- OpenAI 嵌入模型:每 1 K tokens 为 0.0001 美元
- Pinecone 查询:每次 0.00004 美元
- GPT-4 生成:每 1K tokens 为 0.03 美元
- 总成本:约 0.002 美元/次查询
而用户实际支付的价格:0.50–2.00 美元/次查询
API 成本利润率高达 250–1000 倍!
我发现 12 家公司代码结构完全一样,另外 23 家公司相似度超过 90%。
唯一的差别只是变量名,以及使用 Pinecone 还是 Weaviate。
- 有家公司添加了 Redis 缓存,并吹成 “优化引擎”
- 另一家公司加了重试逻辑,还把它注册商标,叫 “智能故障恢复系统”
一个典型初创公司每月运行 100 万次查询的经济情况:
成本:
- OpenAI 嵌入模型:约 100 美元
- Pinecone 托管:约 40 美元
- GPT-4 生成:约 30,000 美元
- 总成本:约 30,140 美元/月
收入: 150,000–500,000 美元/月
毛利率:80–94%
这算是糟糕的生意吗?不是,毛利率非常可观。
但它是 “自研 AI” 吗?也不是。
模式 3:所谓“我们微调了自己的模型”,实际上……
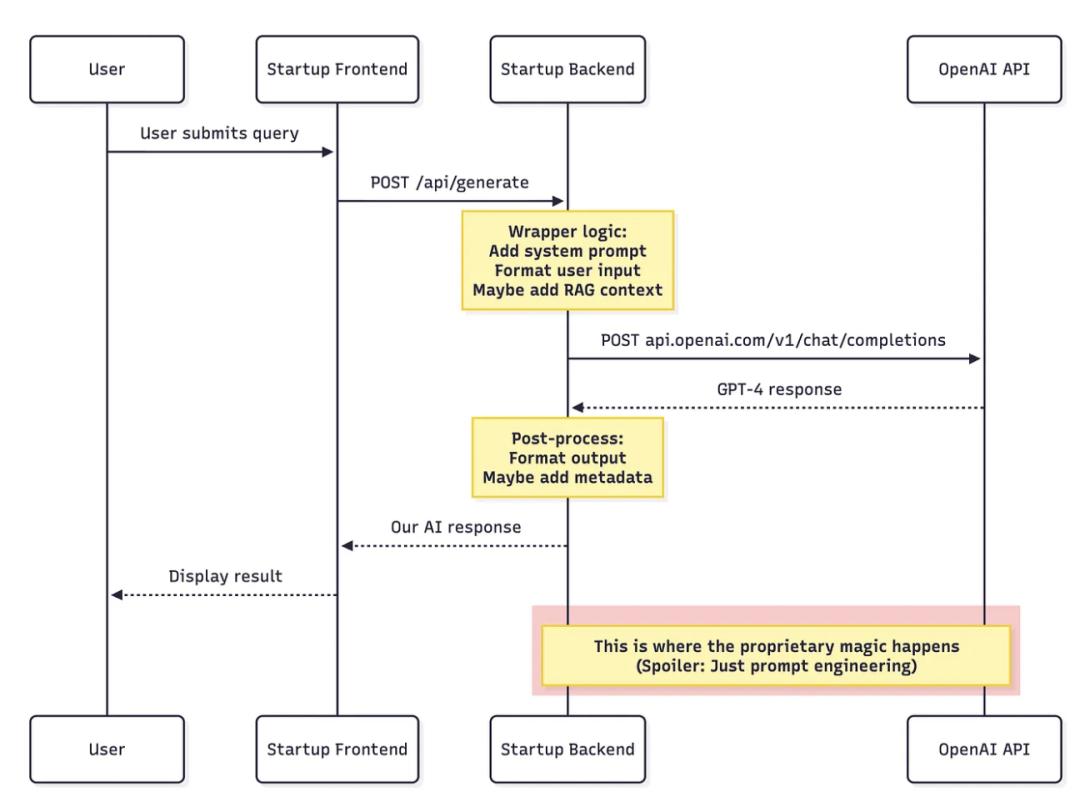
微调听起来很厉害,而且在某些情况下确实有用。但我发现的情况是这样的:
真正从零训练模型的公司只占 7%。敬佩!他们的基础设施我都看到了:
- AWS SageMaker 或 Google Vertex AI 的训练任务
- 将训练好的模型文件(模型产物)存储在 S3 桶中。
- 自定义推理端点
- GPU 实例监控
其余大多数公司只是使用 OpenAI 的微调 API,本质上就是——付钱给 OpenAI,把自己的 prompt 和示例保存到他们的系统里。
30 秒教你识别“套壳公司”
如果你想知道我说的是真是假,其实根本不需要我花三周调查,这里有快速识别方法:
现象 1:网络流量
打开 DevTools(F12),切换到 Network 标签页,然后与其 AI 功能交互。如果你看到这些请求:
- api.openai.com
- api.anthropic.com
- api.cohere.ai
那你看到的就是「套壳公司」。他们可能加了一层中间件,但 AI 并不属于他们。
现象 2:响应时间模式
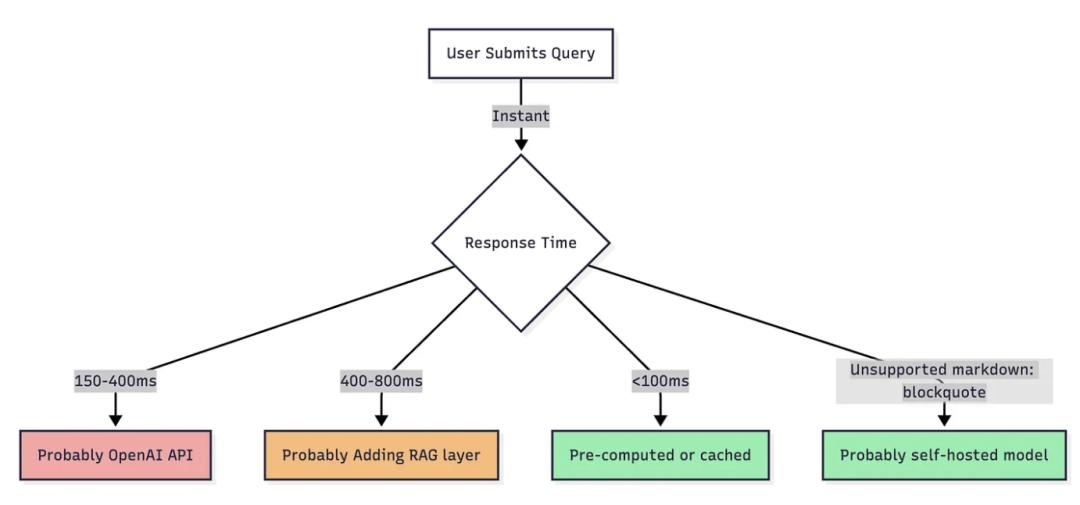
OpenAI 的 API 有一个独特的延迟特征。如果每次响应都在 200–350ms 之间,那就基本可以确定是 OpenAI 的服务。
现象 3:JavaScript 打包文件
打开网页源码,搜索以下关键词:

我发现 12 家公司把 API Key 留在前端代码里。我都举报了,但没有一家回应。
现象 4:营销语言矩阵
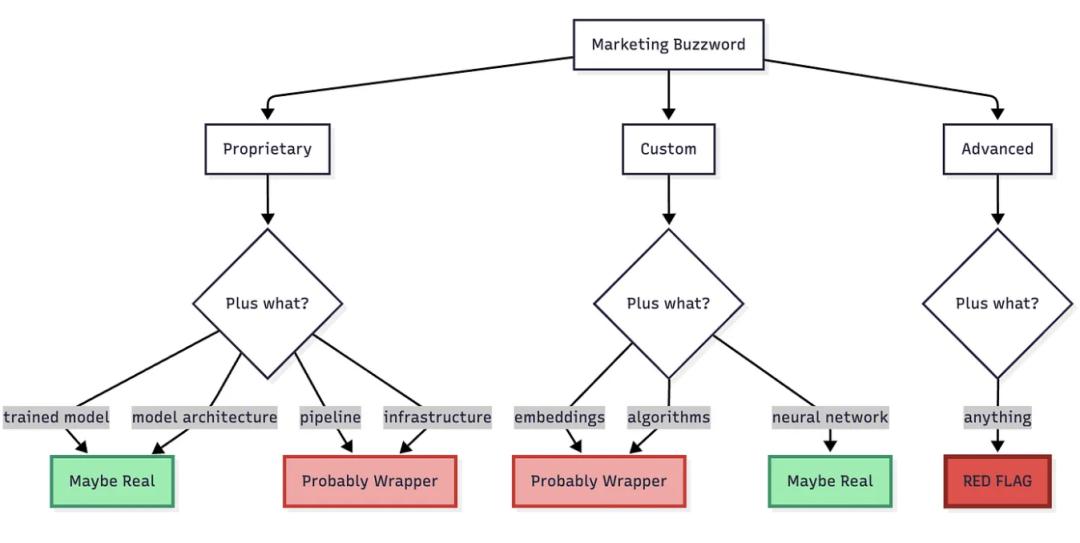
规律很明显:
- 具体技术术语 = 可能是真的
- 模糊的营销词 = 很可能在掩饰
如果他们只会用“先进 AI”、“智能引擎”之类的模糊词,而没有具体技术细节,通常意味着背后有猫腻。
基础设施的真实情况
实际上,AI 初创公司的技术格局大致如下:
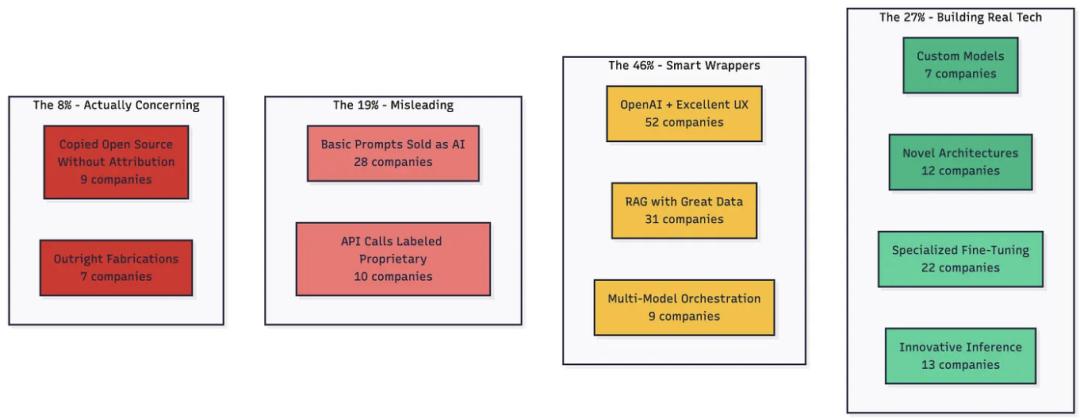
为什么这真的很重要?
你可能在想:“管它呢?能用就行。”
你说的部分确实没错,但事情比表面更重要:
- 对投资人来说:你在资助的是 prompt engineering,而不是 AI 研究。估值得调整。
- 对客户来说:你支付的是 API 成本加高额溢价。事实上,你可能一个周末就能搭出同样的东西。
- 对开发者来说:门槛比你想象的低。那个你羡慕的“AI 初创公司”?它的核心技术,你可能在黑客松里就能做出来。
- 对整个生态来说:当 73% 的“AI 公司”都在夸大或误导自己的技术实力,我们已经处在泡沫状态了。
套壳模式(因为并非所有套壳都是坏事)
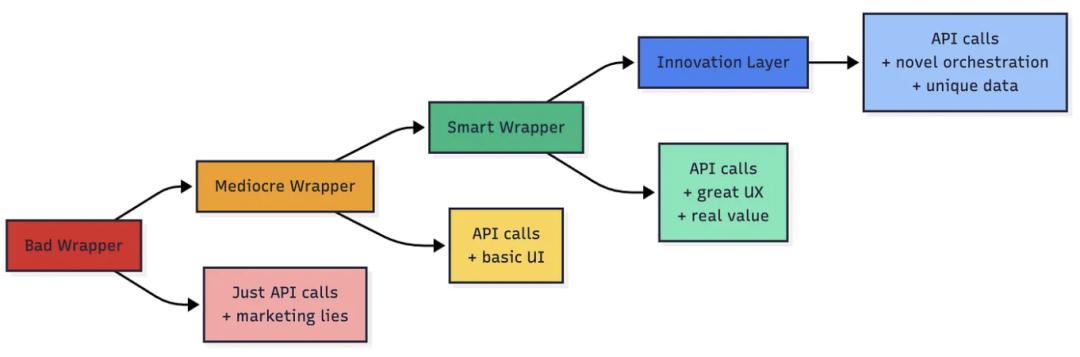
聪明的套壳公司并没有撒谎,它们在做的其实是:
- 特定领域的工作流
- 更优的用户体验
- 巧妙的模型编排
- 有价值的数据管道
它们只是底层使用了 OpenAI,这没有问题。
那 27% 做对了的公司
让我来重点介绍那些诚实做事的公司:
第一类:透明套壳公司
首页直接写着 “Built on GPT-4”。它们卖的是工作流,而不是 AI 本身。案例包括:
- 法律文档自动化(GPT-4 + 法律模板)
- 客服路由系统(Claude + 行业知识)
- 内容工作流(多模型 + 人工审核)
第二类:真正的构建者
这些公司实际在训练模型:
- 医疗 AI(HIPAA 合规的自托管模型)
- 金融分析(定制风险模型)
- 工业自动化(专用计算机视觉模型)
第三类:创新者
在现有基础上构建真正新技术的公司:
- 多模型投票系统,提高准确性
- 带记忆的自定义智能体框架
- 新型检索架构
这些公司会在宣传时候详细讲解它们的架构,因为他们真的自己做了。
我学到了什么(以及你应该知道的)
经过三周对 AI 初创公司的逆向工程,我总结出以下几点:
- 技术栈本身没那么重要,关键是解决的问题。我发现的一些最棒的产品,“只是”套了层壳。它们有出色的用户体验、解决了真实问题,并且对自己的方式很诚实。
- 但诚实很重要。一个聪明的套壳公司和一个欺诈公司之间的差别,就是透明度。
- AI 热潮正在创造错误的激励。创始人感到压力,被迫宣称“自研 AI”,因为投资人和客户都期望如此。这种状况需要改变。
- 基于 API 构建并不可耻。每个 iPhone 应用都是“封装 iOS API”的产物,我们不在意。我们关心的是它能不能用。
真正的考验:你能自己做出来吗?
我的评估框架如下:
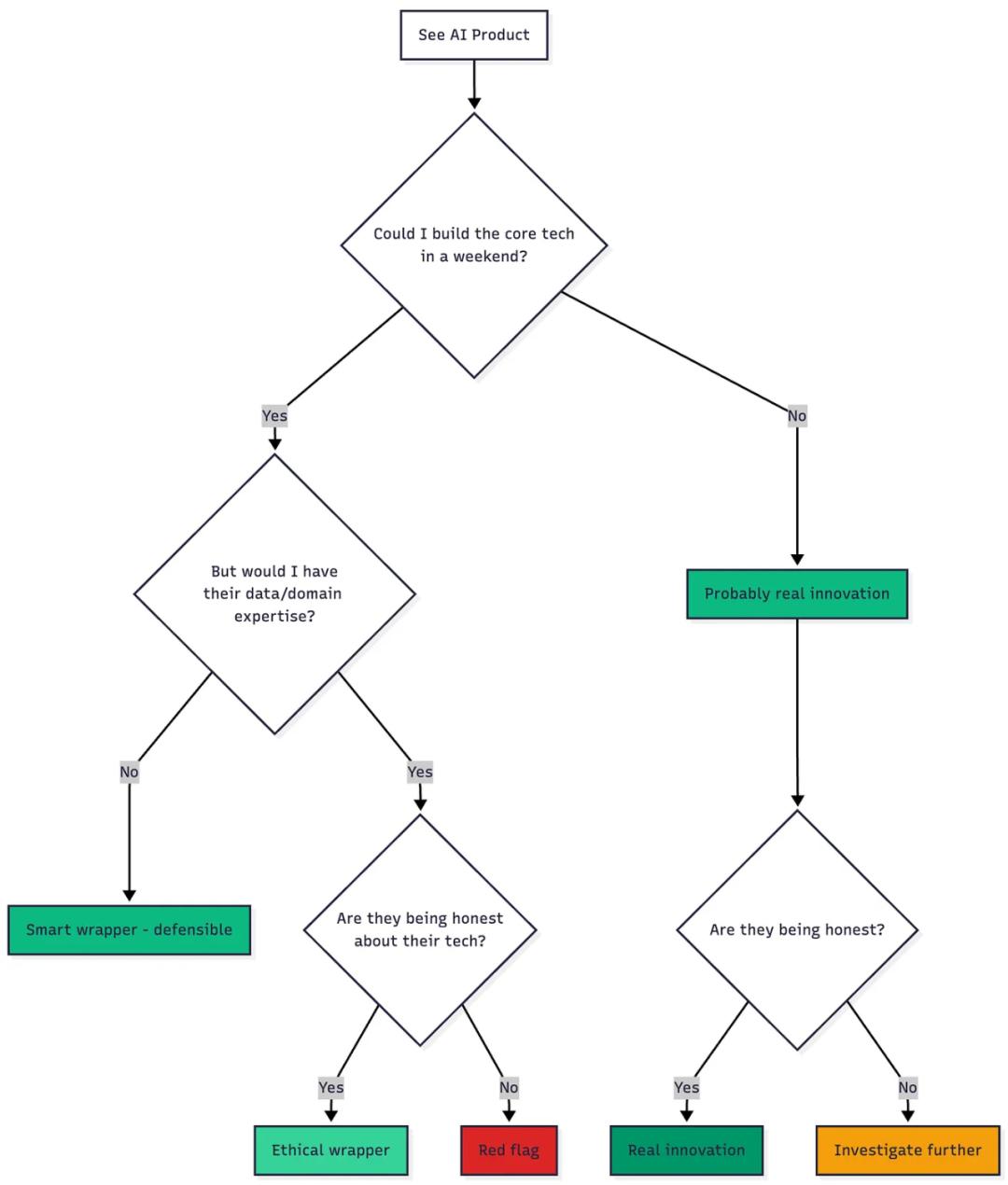
- 如果你在 48 小时内能复刻他们的核心技术,他们就是套壳公司。
- 如果他们对这一点很诚实,那没问题。
- 如果他们撒谎——赶紧远离。
我的实际建议
对创始人:
- 诚实说明你的技术栈
- 在用户体验、数据和行业知识上竞争
- 不要声称做了你没有做过的事
- “Built with GPT-4” 并不是弱点
对投资人:
- 要求查看架构图
- 索取 API 账单(OpenAI 发票不会骗人)
- 合理评估套壳公司
- 奖励透明度
对客户:
- 检查网络流量(Network Tab)
- 询问基础设施细节
- 不要为 API 调用支付 10 倍溢价
- 根据效果,而不是技术宣传来评估
那件没人敢明说的事
大多数所谓的“AI 初创公司”,其实是靠 API 成本而不是员工成本运作的服务型公司。
这没什么问题。
但就该叫它本来的名字。
接下来会发生什么?
AI 套壳时代是不可避免的。我们在其他领域经历过同样的周期:
- 云基础设施(每个创业公司都声称“自建数据中心”)
- 移动应用(人人都说自己是“原生”,其实是混合开发)
- 区块链(每家公司都在“基于区块链”开发)
最终,市场会成熟。踏实的开发者会胜出,骗子会被揭穿。
而现在,我们正处在混乱的中间阶段。
最后的思考
在逆向分析了 200 家 AI 初创公司后,我反而对这个领域更乐观,而不是更失望。
- 那 27% 真正在做技术研发的公司,做得非常出色。
- 聪明的套壳公司也在解决真正的问题。
- 即便一些存在误导的公司,也有不错的产品,只是营销需要调整。
但我们需要让关于 AI 基础设施的诚实成为常态。使用 OpenAI 的 API 并不意味着你就不是开发者。撒谎才会让你失去可信度。
做酷产品,解决真实问题,使用任何有效的工具。只是别把你的 prompt 工程吹成“专有神经网络架构”。
调查以来的心路历程
在博客文章的最后,Teja Kusireddy 也分享了他开始调查后的情况:
- 第 1 周:原以为大约 20–30% 的公司使用第三方 API,但还是太天真了。
- 第 2 周:有创始人联系他,问“怎么进入了他们的生产环境”。其实,Teja Kusireddy 根本没进去,他看到的一切都在浏览器网络面板里,这些企业只是没想到有人会看。
- 第 3 周:有两家公司要求 Teja Kusireddy 撤掉发现内容。
- 昨天:一位 VC 问他是否可以在下一次董事会前审查他们的投资组合公司,Teja Kusireddy 答应了。
Teja Kusireddy 表示,他后面会在 GitHub 上公开分享调查的方法论、完整的爬取基础设施、API 指纹识别技术、可立即运行的检测脚本以及各大 AI API 的响应时间模式等等。
在三周里,Teja Kusireddy 称自己学到的唯一结论是:市场最终会奖励透明,哪怕一开始可能惩罚它。他还透露,自己这篇内容发布之后:
有 7 位创始人私下联系了他,有的防御,有的感激。
三家公司请求帮忙,把营销从“专有 AI”转成“基于顶级 API 开发”。
一位创始人告诉他:“我知道我们在撒谎,投资人希望这样,大家都这么做。我们该怎么停?”
“AI 的淘金热不会结束,但诚实时代必须开始,”Teja Kusireddy 说道,“如果你感兴趣,可以打开你的 DevTools,查看网络面板,自己验证。真相,就在 F12 之下。”
来源:https://pub.towardsai.net/i-reverse-engineered-200-ai-startups-73-are-lying-a8610acab0d3
