

当所有人都以为AI发展的剧本是「英伟达卖铲子,OpenAI挖金矿」时,谷歌用Gemini 3告诉世界:如果我自己造了一台全自动挖掘机,还需要买谁的铲子,谁能挖得过我?
在谷歌最新的Gemini 3和Nano Banana Pro发布前,黄仁勋和奥特曼都一直雄心勃勃,自信非常。
英伟达和OpenAI的日子过得可谓是风生水起。

Nano Banana Pro生成
然而,Gemini 3全家桶的横空出世,瞬间打断了这场双赢的美梦。
彭博、财富等外媒则更加直接,他们认为:
谷歌,这家曾被认为在AI时代稍显落后、有点沉睡的巨头,正在全面觉醒。
在OpenAI的蓝图里,AI的发展会一直遵循着一种简单而傲慢的「暴力美学」:Scaling Law。
他们坚信,只要数据更多、算力更强,模型就会无限聪明下去,而他们握着通往AGI的唯一钥匙。
就像从GPT-3一直到现在GPT-5、GPT-5.1,然后明年的GPT-6、一直到AGI实现的那一天。
而在英伟达的账本里,逻辑则更加粗暴直接:我是这个淘金时代唯一卖铲子的人。(不是非常严格,但基本事实如此)
全世界的AI公司,无论谁输谁赢,都得乖乖排队交「GPU税」。
然而硅谷的夜,这几天格外漫长。
当奥特曼在深夜罕见地发推承认「OpenAI在某些关键维度上确实落后了」时,大洋彼岸的投资者们还没回过神来。
紧接着,英伟达股价应声下挫,逼得英伟达官方不得不亲自下场,在X平台上发长文辩护,强调CUDA生态的不可替代性。
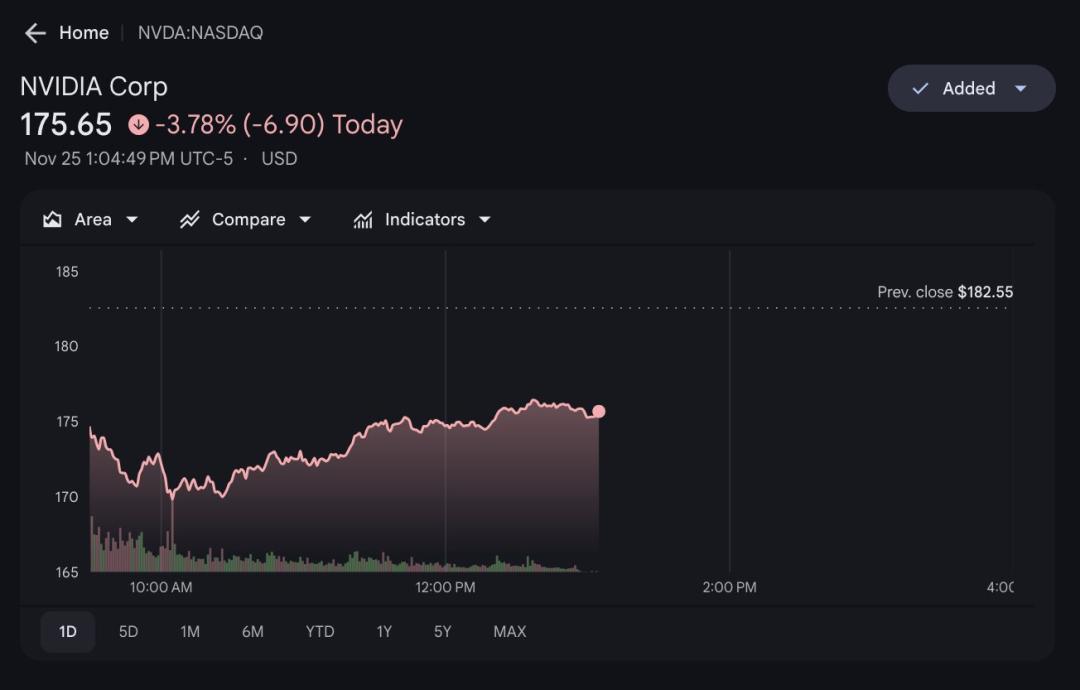
在祝贺谷歌成功的同时,这个回复也能明显闻到一股酸酸的味道:英伟达有点急了。
啊英伟达领先行业整整一代——它是唯一能在所有计算场景中运行各类人工智能模型的平台。
相较于专为特定AI框架或功能设计的专用集成电路,英伟达提供更卓越的性能、更强的通用性与可替代性。
能让这两位AI时代的「双子星」同时感到寒意的,只有一个名字:Gemini 3。
在此之前,AI领域的叙事逻辑清晰且固化:英伟达是「收税」的,OpenAI是「布道」的,而谷歌、Meta、Anthropic等只是追随的。
但Gemini 3的发布,不仅是一次模型升级,更是一场「降维打击」。
谷歌这波操作,可以说是左手一拳打掉了OpenAI的模型护城河,右脚一脚踢翻了英伟达的算力神坛。

Nano Banana Pro生成
如果你这几天真的在和Gemini 3对话,在和Nano Banana Pro画图,你一定知道我在说什么。
人们开始发现,不用英伟达的芯片,不需要等OpenAI的新模型带领,只用TPU也能训练出最顶级的AI模型。
谷歌究竟做了什么?
第一拳:打懵OpenAI,从「堆参数」到「原生思考」
过去两年,OpenAI一直维持着一种「暴力美学」的优势:Scaling Law(大力出奇迹)。
只要数据更多、算力更强,模型就更聪明。
同时OpenAI也有创新,比如GPT-4o引发的吉卜力热,Sora 2的爆火等。
但Gemini 3不仅是「更强大」,它是「更奇怪」,尤其是Nano Banana Pro带来的社交狂欢。
以下图片全部由Gemini生成,并且在社区中广泛传播的图片。
并且生成提示词都极其简单,甚至比谷歌曾经理解的「自然语言」还要简单。
下面请欣赏一下。

一句话生成各种战力排行榜

一句话生成各种战力排行榜:鬼灭之刃版本

一句话生成各种知识绘本和解读
一句话生成表情包

一句话生成表情包

一句话将低分辨率图像精准放大至 4K 画质

它用我的真实笔迹正确解答了这个问题。
还有太多惊艳的案例。
Gemini 3给人的感觉就是他第一次真正实现了原生多模态的终极形态。
之前的模型(包括GPT-4o),本质上还是像一个把眼睛、耳朵和嘴巴拼凑起来的怪人,需要不同的神经网络处理图像和文本,然后再缝合。
Gemini 3的突破在于,它「天生」就是感官互通的。
它理解一段视频,不是把它翻译成文字再理解,而是像人类一样直接理解光影和动态。
这不仅带来了极致的低延迟,更让它的「直觉」可怕地敏锐。
丹尼尔·卡尼曼(Daniel Kahneman)在他的诺贝尔奖获奖著作《思考,快与慢》(Thinking, Fast and Slow)中,将人类的认知系统分为两种模式:
系统1:快思考 (Fast Thinking)和系统2:慢思考 (Slow Thinking)
Gemini 3第一次让人类感受到,在硅基芯片上实现了「系统2」思维的常态化。

OpenAI的o1模型开启了「慢思考」时代,但那更像是一个外挂插件。
Gemini 3则将这种逻辑推理能力内化了。
它不需要用户提示「请深思熟虑」,它会在后台自动判断:这个问题是该用直觉秒回,还是该调动逻辑电路进行推演。
这种「动态计算」能力,让Gemini 3在代码生成、复杂数学和长逻辑链条任务上,第一次对OpenAI构成了代际优势。
第二脚:踢翻英伟达,摆脱「CUDA依赖」
如果说Gemini 3打OpenAI还是AI技术之争,那么让英伟达紧张的,则是生存逻辑变了。
过去,所有的AI公司都患上了「英伟达依赖症」。
没有H100/GB 200的英伟达芯片,AI模型就训练不出来。
英伟达还靠着CUDA生态,建立了牢不可破的软硬件壁垒。
但是,这道密不透风的铁幕被谷歌用TPU撕开了一道铁幕。
Gemini 3后,谷歌启动激进的TPU@Premises计划,直接要把算力卖进巨头的后院。
目标就是虎口夺食,豪言要拿下英伟达10%的营收。
Meta已经倒戈。

拓展阅读:谷歌训出Gemini 3的TPU,已成老黄心腹大患!Meta已倒戈
Gemini 3是完全在谷歌自研的最新一代TPU集群上训练出来的。
这意味着什么?
谷歌不需要给黄仁勋交「苹果税」。
当OpenAI每训练一次模型都要烧掉数亿美元给英伟达买卡时,谷歌用自家的芯片,成本可能只有对手的一半,甚至更低。
软硬一体的效率恐怖。
就像苹果的iOS配合A系列芯片能吊打安卓一样,Gemini 3的模型架构是专门为了TPU设计的,TPU也是为了Gemini优化的。这种契合度,让算力利用率突破了行业天花板。
英伟达官方在X上的辩护显得苍白,因为市场听懂了谷歌的潜台词:如果最强的模型不需要英伟达的GPU就能跑出来,那么英伟达高达80%的毛利率还能维持多久?
这里不得不重点提谷歌埋藏了十年的伏笔——TPU(张量处理单元)。
谷歌十年磨一剑。
TPU是如何炼成的
在Gemini 3爆火后,谷歌的官方博客迅速跟进了一篇最新TPU的介绍帖子。
翻译一下就是:「关于我的强大,你们需要了解三件事」。
你要说这没有内涵英伟达的成分,我第一个不相信。注意日期,11月25日。

第七代TPU别名Ironwood,铁木。
Ironwood是谷歌迄今为止性能最强、能力最出众且能效最高的TPU。
专为大规模驱动推理型人工智能模型而设计。
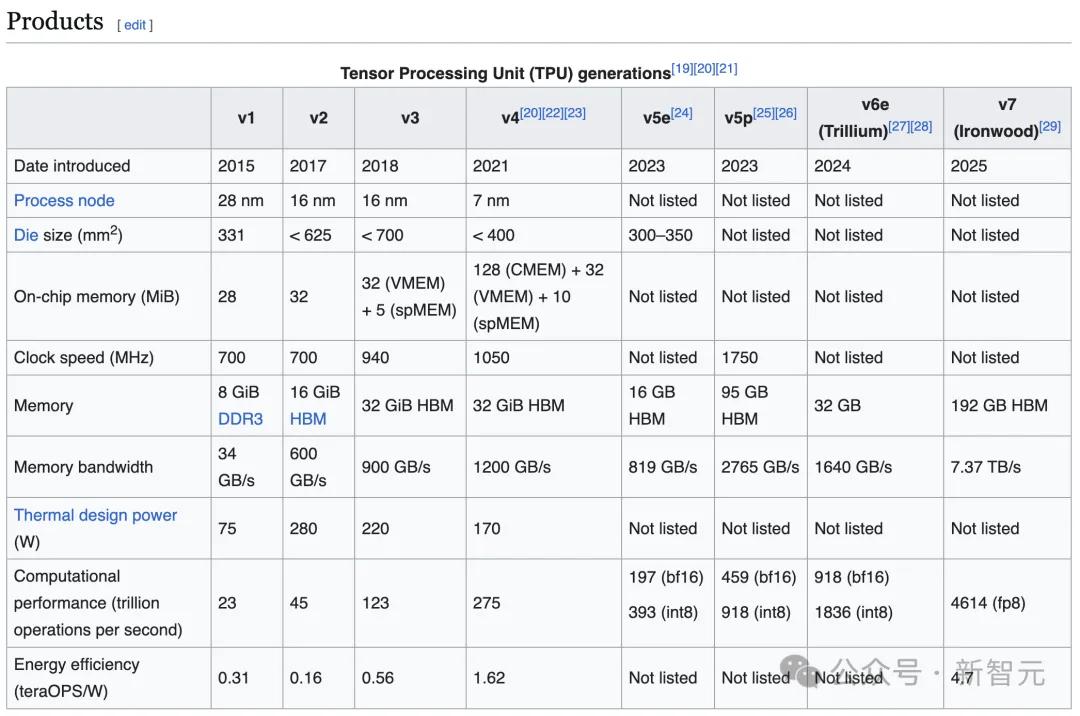

Ironwood有三大特性:
专为推理时代量身打造
随着行业焦点从训练前沿模型转向实现实用、响应迅速的人机交互,Ironwood提供了关键的硬件支撑。
这款定制芯片专为高吞吐量、低延迟的AI推理和模型服务而打造,其单芯片在训练与推理工作负载上的性能表现较上一代提升逾四倍,使Ironwood成为谷歌迄今最强大且高能效的定制芯片。
这是一个庞大的算力网络
TPU是AI超级计算机的关键组成部分,这是谷歌集成的超级计算系统,旨在提升计算、网络、存储和软件层面的系统级性能与效率。
该系统的核心是将单个TPU组合成名为「计算集群」的互联单元。
借助Ironwood,谷歌能够在超级集群中扩展至9,216 颗芯片。
这些芯片通过突破性的芯片间互联网络相连,运行速率达9.6Tb/s。

专为AI而生,由AI赋能
Ironwood是谷歌持续闭环研发的成果——研究人员推动硬件设计,硬件加速研究进程。
当竞争对手依赖外部供应商时,谷歌 DeepMind 若需为Gemini等模型实现特定架构突破,会直接与TPU工程师团队协同创新。
因此谷歌的模型始终基于最新代际TPU进行训练,相较前代硬件常实现显著提速。
研究人员甚至运用名为 AlphaChip 的AI技术设计下一代芯片——通过强化学习已为包括 Ironwood在内的连续三代TPU生成了更优布局方案。
除了TPU,谷歌是唯一一家,没有之一,全栈人工智能公司:数据→算法→硬件→云服务器,全都自研。
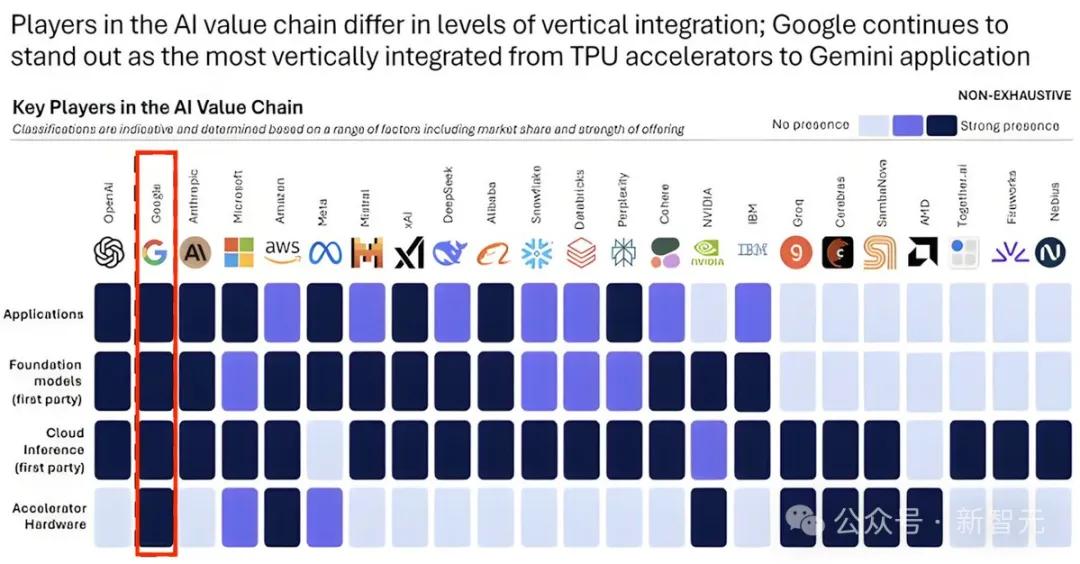
拓展阅读:英伟达铁幕之后,谷歌AI芯片已成气候
为什么是现在?谷歌的「核聚变」时刻
很多人会问,谷歌早干嘛去了?
答案是:组织架构的物理反应终于变成了化学反应。
两年前的谷歌,虽然有DeepMind和Google Brain两个顶尖大脑,但内部内耗严重,资源分散。
现在的谷歌,在合并团队后,终于打通了「任督二脉」。
更可怕的是谷歌的数据飞轮:
- YouTub:提供了全球最高质量的视频数据(训练多模态的黄金);
- 谷歌Search:提供了最实时的世界知识;
- Android::提供了数十亿的端侧落地场景。
除了模型、硬件,另一个容易被忽略的就是谷歌的「创始人回归」。
这在公司文化上带来更加底层的影响。
联合创始人谢尔盖·布林(Sergey Brin)的回归则是这场变革的精神图腾。
布林早已重返谷歌山景城总部。

拓展阅读:谷歌重回铁王座!Gemini 3吊打GPT-5,奥特曼发信承认技不如人
作为谷歌的创始人和图腾人物,谢尔盖放弃退休后在私人小岛享受生活。
而是脚踏实地的重返硅谷,拯救谷歌。
布林的回归不是为了发表愿景演讲,而是为了写代码。
据说,他回到谷歌后提交了多年来的第一个CL(Changelist,谷歌内部的代码修改请求),这一行为在工程师内部产生了地震般的效应:
如果身价千亿的创始人都在修补配置文件,那么任何产品经理都没有理由以「流程」为借口阻碍发布。
布林的存在直接催化了Gemini 3项目的加速,他专注于解决模型在长逻辑链推理上的「长尾问题」,这是之前职业经理人们因追求短期指标而忽视的领域。
AI下半场,谁能获胜?
Gemini 3的出现,标志着AI战争正式进入下半场。
上半场是「淘金热」,谁铲子好(英伟达),谁挖得快(OpenAI),谁就赢。
下半场拼什么?
芯片、算力、全栈能力、人才,还是架构?
OpenAI的缔造者之一,人工教父的辛顿的爱徒,神秘的Ilya,今天刚好首次公开最新采访。
他被社区认为一直是最接近AGI的男人。

拓展阅读:Ilya重磅发声:Scaling时代终结!自曝不再感受AGI
他爆出惊人观点:Scaling时代已终结,我们正走向研究时代。
昨天有一篇论文很火,说的是Attention is All You Need(2.0)版本。
意思是Transformer已经过时,AI亟需新的架构。
更多信息,请阅读:终结Transformer统治!清华姚班校友出手,剑指AI「灾难性遗忘」。
有趣的是这篇文章,也是谷歌的!
这个观点这对于一直依赖Scaling的OpenAI并不是什么利好。
反而对于拥有DeepMind的谷歌来说,这是绝佳的助攻。
要知道2016年启蒙世界人民AI认知的AlphaGo、奠定AI时代的Transformer论文、解码生命的AlphaFold、世界模型Genie 3、带来量子霸权的量子计算机。。。
拼研究?谷歌多的是研究项目。
谷歌Gemini 3这波突破向世界证明了:在未来的AI时代,自研才是终极王道。
或许就像当年的苹果,不满足于用别人的芯片造手机,最终造出了M系列芯片一统江湖。
回头望去,不得不感慨这一年AI还是发展得太快了。
2025年在AI发展史上无疑是具有里程碑意义的一年。
英伟达的芯片+Scaling Law为我们创造一个叙事:只要英伟达继续研发芯片,OpenAI继续加大算力,奥特们不是都去印度造电厂了吗,AI就会一直发展。
其他人跟着就好。
然而,Gemini 3的横空出世,彻底终结了「线性增长」的叙事。
它证明了模型架构和定制化硬件的深度协同,可以带来非线性的能力突破。
彩蛋:不公布研究成果了
最后,让我们把目光投回到多年前,谷歌发布Transformer论文的那天。
自从OpenAI开始靠着ChatGPT拿到AI时代话语权后,外媒、甚至包括谷歌自己的工程师和前CEO都在说:谷歌已经落后。

这导致多年后一个小小的插曲,那就是DeepMind的老大哈萨比斯,严禁工程师对外发表最新成果的论文。

拓展阅读:DeepMind核心论文禁发6个月,Transformer级研究锁死!CEO:不满意就走人
如果结合今天Ilya所说的话,或许明年AI的话语权要从OpenAI回落到谷歌手里了。
毕竟没人知道谷歌手里究竟藏了多少东西了。
硅谷AI权力游戏,今天才刚刚开始。
又一个彩蛋:黄仁勋出招了
在谷歌将TPU卖给Meta后,英伟达的股价应声下跌。
英伟达除了在X上发帖酸了一下谷歌后,英伟达准备故技重施。
根据外媒报道,英伟达准备通过向Meta注入巨额投资来换取其继续使用英伟达芯片的承诺。

这招此前英伟达已经在OpenAI身上用过了。
极具讽刺意味的是,这场「商战」的资金优势已经逆转:得益于高达73%的利润率,英伟达今年的自由现金流预计将飙升至970亿美元,一举超越谷歌的650亿美元。
这意味着,英伟达正在用从科技巨头们身上赚来的钱,反过来「收买」这些客户,从而通过资本手段构建起一道谷歌难以逾越的护城河。
参考资料:
https://fortune.com/2025/11/25/google-sleeping-giant-dark-horse-ai-race-gemini/
https://blog.google/products/google-cloud/ironwood-google-tpu-things-to-know/
