

听到 DeepMind CEO 聊中国 AI,有一句话特别刺耳:中国 AI 毫无创新,只不过是跟进速度可怕。
这话,听着是不是很熟悉?
前两年叙事里,这几乎成了西方对我们的思维定势,他们负责「从 0 到 1」的发明,我们负责「从 1 到 100」的内卷。
哪怕我们跑得再快,在他们眼里,充其量也就是个「勤奋的跟随者」。
说实话,这种论调过去我们很难反驳。因为你打开任何一个国际主流榜单,放眼望去,清一色的美国产品;比如:OpenAI、Google、Anthropic。但偏见这东西,最怕硬数据。
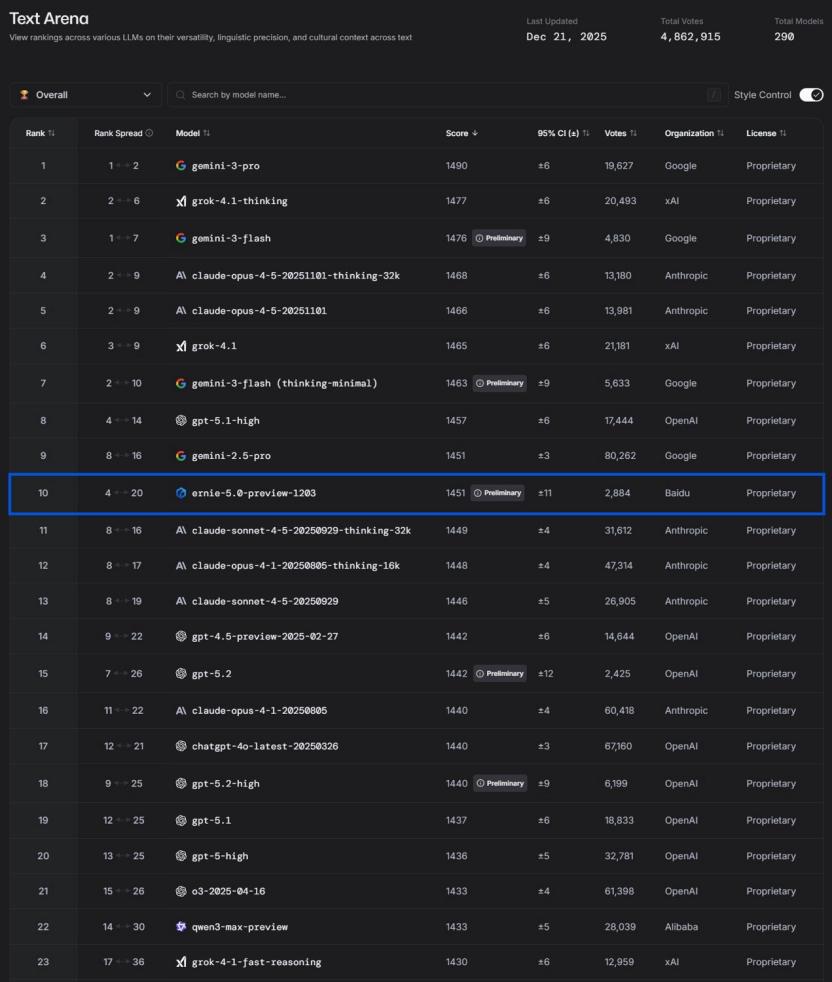
今天(12月23日),全球公认最难刷榜、最讲究「盲测体验」的大模型竞技场 LMArena ,更新了排名;在众多美国模型的重重包围里,百度文心 ERNIE-5.0-Preview-1203 杀了出来,以 1451 分拿下了国内第一。
这个分数意味着什么?
国际舞台上,文心已成为国产 AI 的优秀代表,在 LMArena 排名前 10,超过了 Claude Sonnet4.5、GPT-5.2 等前沿模型,是前 20 里唯一的非美国模型,打破了美国垄断。
当唯一的中国名字出现在榜单前列,当我们的 AI 已经不再满足于「跟跑」时,中美 AI 的这盘棋,逻辑是不是已经变了?
智远分析认为,跑赢这事儿,不能光靠运气,也不能全靠「堆显卡」,我特意翻了一下文心 5.0 Preview 背后的技术文档,发现百度在练几门很刁钻的「内功」,这也是它能突围的核心原因。
第一,最核心底座是一个「原生」的生命体。
注意这个词:原生全模态(Native Omni-modal);以前很多所谓「多模态」模型是「拼凑」出来的,给大模型外挂一个看图的眼睛、外挂一个听声音的耳朵。
这种后期融合虽然能用,但各感官之间是割裂的;文心 5.0 不一样。它采用了「原生全模态统一建模」技术。
打个比方:
它像一个天生具备视、听、说能力的生命体;从训练的第一天起,文本、图像、音频、视频就是融合在一起学习的。
所以,它能直接理解视频里的情绪,直接看懂图片里的逻辑,这种“出厂设置”级别的差异,让它的理解和生成能力,直接上了一个台阶。
图释:
第二招,是「大块头」也有「大智慧」。
文心 5.0 参数量达到了惊人的 2.4 万亿。这是目前业界已公开参数模型里的「巨无霸」。
通常我们认为,模型越大越笨重、越烧钱;百度用了一种「超大规模混合专家模型(MoE)架构」,解决了个悖论。
简单说,这 2.4 万亿参数像一个庞大的专家库,在处理具体问题时,只激活其中不到 3% 的相关专家来干活;在 LMArena 这种拼反应、拼逻辑的盲测里,这种架构优势非常明显。
第三招,是「思考」与「行动」的合体。
文心4.5开始就致力于「知行合一」,突破了仅基于思维链优化的范式,在思考路径中结合工具调用,构建了融合思考和行动的复合思维链,模型解决问题能力得到显著提升。
同时,结合多元统一的奖励机制,实现了长距离思维和行动链的端到端优化,显著提升了跨领域问题解决能力。
所以,不能把它简单归纳为弯道超车。
从「拼接」走向「原生」,从「堆参数」走向「MoE」,从「单点问答」走向「智能体思考」,这 1451 分的背后,是技术路线的质变。
当不再盲目堆算力,开始在架构、思考能力上找突破口时,打赢 GPT-5.2,也就不是什么不可思议的事了。
不可思议,不是我随意能说了算。毕竟,刷榜这事儿,中国不爱干,干了也没用,能把技术用到应用中,才是真本事。
DeepMind 觉得中国 AI 缺乏创新,理由是我们太热衷于「应用」,但智远看来,这恰恰是中西方视角的错位。
硅谷创新往往在实验室的白板上,追求算法“从 0 到 1”;而中国创新,长在泥土里,长在车间里,长在代码行里,追求产业的“从 1 到 100”。
我认为,反驳「无创新论」最有力的武器,是看能不能解决美国 AI 根本没碰到过、甚至想象不到的复杂难题。比如说:在大国重器里,解决「物理世界」的硬伤。
来看看文心大模型在各行各业的应用:
中车集团听说过吗?造高铁的那个。以前做高铁的气动外形设计,那是纯物理活儿,更是个「苦力活」。
因为空气看不见摸不着的,设计师设计一个车头,好不好用,必须得扔进风洞实验室里吹。
跑一次数据,涉及海量的流体力学计算,可能要耗时好几个月,而且风洞实验的成本极高,可以说是“烧钱又烧时间”。
现在呢?一切变了。
他们把文心大模型用在了空气动力学仿真上。基于百度飞桨的科学计算能力,大模型学习了海量的历史实验数据,它已经「懂」了风的规律。
有了这个「外挂」,过去几个月的实验周期,现在最快几分钟就能算出结果。设计师有一个新想法,立刻就能跑出数据验证,创新的迭代速度快了成百上千倍。
更科幻的是,他们还搞了个「虚拟传感器」。
这又是什么黑科技呢?这么说吧,高铁上有很多精密部件没法安装实体传感器的(比如空间太小,或者环境太恶劣)。
以前这些地方出了问题,只能靠猜或者靠检修。但现在,利用大模型强大的推演能力,能凭现有的电流、电压等外围数据,AI 就能在虚拟世界里“推算”出核心部件的实时状态。
这好比给列车装了一双透视的“天眼”,把故障检测的准确率硬生生在现有传感器检测的基础上再提升了 10%;这 10%,关乎中国高铁的安全,关乎的是亿万乘客的生命。
再比如:国家电网。以前巡检电塔,那是工人拿命去爬,风吹日晒。现在靠无人机 + 大模型,一年巡检 500 万基杆塔,人工登塔次数直接减少了 40% 。
这种把 AI 塞进高铁和电网里,解决物理世界硬伤的能力,DeepMind 见过吗?
如果说工业是「硬度」,那代码就是「速度」;我们都知道 AI 能写代码,但能不能进核心业务流?顺丰科技给了一个很吓人的答案 。
大家可能不知道顺丰的业务系统有多复杂。它不仅有物流地图,还有运单流转、仓储管理......
这些系统里,沉淀海量的、只有顺丰人懂的「私有知识」。普通通用大模型,你问它“如何优化运单路由”,它只能给你讲一堆正确的废话。
但顺丰用的文心快码(Baidu Comate),走了一条不同的路。
它通过 RAG(检索增强生成) 技术,像外挂硬盘一样,无缝接入了顺丰内部庞大的私域代码库和文档库;当程序员敲下一行代码时,AI不用瞎猜了。
直接在顺丰沉淀了十几年的技术资产里瞬间检索,找到最匹配的逻辑,生成代码。效果怎么样呢?现在顺丰全公司,日均 20% 的代码是由 AI 生成的 。
相当于每五个字代码里,就有一个是 AI 写的。解放了顺丰 1000 多名开发者的生产力,让他们从枯燥的「搬砖」中解脱出来,去思考更复杂的物流算法 ;这是实打实的新质生产力。不炫技,在给企业省钱、增效。
智远再说一个应用场景最稀缺的例子:社会治理。
在美国,AI 处理标准英语也许很容易。但在中国,处理老百姓夹杂着方言、情绪激动、逻辑混乱的投诉,是对 AI 理解力的极致考验。
北京市海淀区的「接诉即办」系统,每月受理量十几万,以前靠人工听录音、打标签,根本搞不过来。
因为数据量太大了,而且是非结构化的。现在接入文心大模型后,它不仅能更懂人性,还能从一堆唠叨里精准提取诉求,自动分类填单 。
数据反差极其强烈:
以前做简单指标统计要 3 天,现在只要 1 分钟;画个图表以前要 5 天,现在 30 分钟搞定;这是给庞大的城市治理装上了一个实时思考的“大脑”,让管理者能听懂每一句人间烟火。
最后,如果非要说我们不懂基础科学,那就去上海交大看看。
传统科学实验,其实很笨。就像爱迪生试灯丝一样,要在实验室里进行成千上万次的重复试错,耗时耗力 。
上海交大基于文心大模型搞了个 AI for Science 平台 。现在,只要输入分子 SMILES 序列,5 秒钟之内就能检索出反应过程、反应条件和相关文献 。
这个成果,直接登上了 Nature Computational Science 的封面 。
Nature Computational Science是什么?不懂行的认为这只是一篇论文,但在学术圈,这本《自然》旗下的顶级子刊,代表着「计算+科学」交叉领域的最高门槛。
能上封面,意味着中国 AI除了做应用,还能定义基础科学的未来范式。
所以,当看到 AI 开始指导化学反应,开始设计高铁外形,开始听懂老百姓方言,开始替程序员写两成的代码时,还会觉得中国是跟随者吗?
最后,智远想说一个细思极恐的细节。关注 LMArena 的朋友会知道,哪怕你看到了它排在国内第一、全球前十,别忘了,它的名字后缀里还挂着一个词:Preview(预览版)。
什么意思?
也就说,打败GPT-5.2、把不少美国模型甩在身后的「文心 5.0」,还是一个「未完全体」;这就像武林高手过招,对方还没拔剑,只是试探性地出了一掌。
智远看到榜单后,问了下熟悉的人,他们说:文心大模型 5.0 正式版,大概率会在 1 月份正式上线。
试想一下,一个 Preview 版本已经能在竞技场里撕开铁幕,那经过一个月打磨后的正式版,又会拿出什么样的性能呢?
如果只盯着分数,可能又看走眼了,因为现在大模型上榜大家关注少了,智远觉得,这事儿还有更深的一层意味。我们不仅要问文心 5.0 还能得多少分,更要问一个终极问题:
当技术代差被抹平之后,中美 AI 的终局竞争到底拼什么?拼谁的模型多 10 分?还是拼谁的参数大一倍? 都不是。
拼谁能把技术变成像水和电一样,流进每一个普通人的生活里。
这也是智远认为,百度在模型上下功夫的地方;它不仅自己在进化,它还带着整个生态在进化;以后要把它用到AI搜索里、百度文库网盘里、以及企业服务场景里,岂不是成了降本提效的「日用品」?
所以,当 DeepMind 还在嘲笑我们「应用快」的时候,他们可能没意识到:应用,本身就是一种巨大的技术壁垒。
因为应用会产生数据,数据会反哺模型,模型进化了又带来更好的应用;这是一个正向滚动的雪球。 而文心模型,是在雪球的中心。
所以,回到DeepMind 那句傲慢的评判。
当中国名字出现在榜单前列,当我们的 AI 深入到高铁与政务的毛细血管,当“预览版”能同台竞技时,不管硅谷还是 DeepMind,或许都该换一副眼镜看中国 AI 了。
承认别人的优秀,并不丢人。
在这个时代,创新没有时间限制,没有垄断权;它可以发生在加州的实验室里,也可以发生在中国的高铁车间里。
中美 AI 的故事,是「双强并峙,各登山顶」。这,才是 AI 赛场上的真相。我也比较期待啥时候上线正式版。
