

一句话让照片变大片,比专业软件简单、比AI修图更可控!
腾讯混元携手厦门大学推出JarvisEvo——一个统一的图像编辑智能体模拟人类专家设计师,通过迭代编辑、视觉感知、自我评估和自我反思来“p图”。
“像专家一样思考,像工匠一样打磨”。JarvisEvo不仅能用Lightroom修图,更能“看见”修图后的变化,并自我评判好坏,从而实现无需外部奖励的自我进化 。
下面就来了解一下详细情况吧~
自我评估和修正
研究背景与动机
近年来,基于指令的图像编辑模型虽然取得了显著进展,但在追求“专业级”修图体验时,仍面临两大核心挑战:
- 指令幻觉 (Instruction Hallucination):
现有的文本思维链 (Text-only CoT) 存在信息瓶颈。模型在推理过程中“看不见”中间的修图结果,仅凭文本“脑补”假设进行下一步操作的视觉结果,容易导致事实性错误,无法确保每一步都符合用户意图。
- 奖励黑客 (Reward Hacking):
在强化学习进行偏好对齐的过程中,策略模型(Policy)是动态更新的,而奖励模型(Reward Model)通常是静态的。这导致策略模型容易“钻空子”,通过欺骗奖励函数获取高分,而非真正提升修图质量和自我评估能力 。
为了解决上述问题,团队推出了JarvisEvo.
iMCoT:交互式多模态思维链
打破了传统“盲修”的局限。JarvisEvo 引入了iMCoT (Interleaved Multimodal Chain-of-Thought) 机制。与纯文本推理不同,JarvisEvo在每一步编辑后都会生成新的图像,并基于视觉反馈进行下一步推理。
模型在“生成文本假设 -> 执行工具 -> 观察视觉结果 -> 反思决策”的循环中工作,确保每一步操作都精准落地 。
SEPO:协同编辑-评估策略优化
这是JarvisEvo 实现“自进化”的引擎。团队提出了SEPO (Synergistic Editor-Evaluator Policy Optimization) 框架,包含两个协同进化的优化环 :
编辑者优化环 (Loop 1):模型利用自我评估分数作为内在奖励,不再依赖容易被 hack 的外部奖励模型。
评估者优化环 (Loop 2):利用人类标注数据持续校准模型的评估能力,防止模型在自我打分时“自欺欺人”。
在线反思与自我修正
JarvisEvo具备从错误中学习的能力。在训练过程中,系统会自动将低分轨迹与高分轨迹进行对比,生成反思数据 (Reflection Data)。模型通过分析“为什么修错了”以及“如何修正”,习得强大的自我纠错能力。
像人类一样“边看边修”
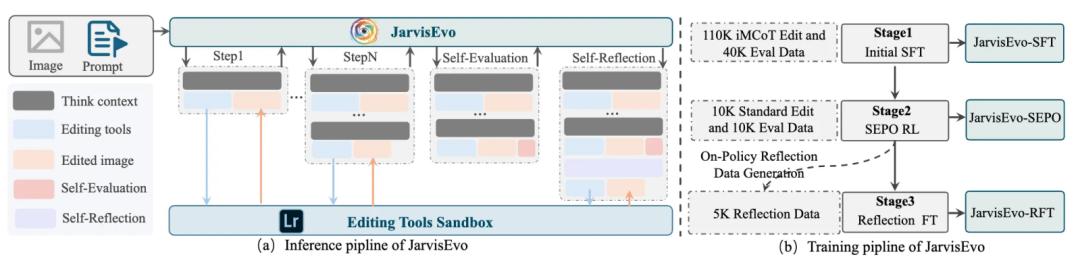
JarvisEvo系统架构
传统的文本思维链(Text-only CoT)通常是“盲修”,即一次性生成所有步骤。
JarvisEvo则采用了 交互式多模态思维链 (iMCoT),模拟了人类设计师“观察-操作-检查”的闭环工作流。
整个推理过程分为四个核心步骤:
1、视觉感知与规划 (Perception&Planning):模型首先分析原图(I)与用户指令(Q),生成初始的修图思路。
2、多步工具执行 (Step-by-Step Execution):
模型生成交错的文本推理内容(C)和工具调用指令(T)。
工具沙盒 (Sandbox):指令被发送到外部的Adobe Lightroom环境中执行,生成中间态的编辑图像(O)。
视觉反馈 (Visual Feedback):这一点至关重要。模型会“看”到刚刚修好的图,基于最新的视觉状态决定下一步是继续调整还是修正错误 。
3、自我评估 (Self-Evaluation):修图结束后,模型会对最终结果(Ot)的美学质量和指令符合度进行自我打分(S)。
4、自我反思 (Self-Reflection):如果结果不理想,模型会触发反思机制,分析偏差原因并尝试纠正。

三阶段的训练框架
为了打造这样一个全能 Agent,团队设计了一套严谨的三阶段训练流水线:
Stage 1: 冷启动监督微调 (Cold-Start SFT)
数据量:150K标注样本(110K编辑数据+40K评估数据)。
目标:教会模型“基本功”。这包括掌握多模态推理的语法、能够交替生成文本与图像内容、学会根据视觉线索选择正确的工具,以及初步建立审美评估能力。
Stage 2: SEPO强化学习 (The Evolution)
数据量:20K标准指令数据(10K编辑+10K评估)。
核心机制:引入 协同编辑-评估策略优化 (SEPO) 。在此阶段,模型脱离了对标准答案的模仿,开始自主探索。
双优化驱动: 此阶段让模型从“会用工具”进化为“精通修图”。 编辑者优化:通过自我打分(Self-Reward)优化修图策略,并利用SLM (Selective Loss Masking) 防止奖励作弊。 评估者优化:利用人类评分数据校准模型的审美眼光,确保它能做一个公正的裁判。
Stage 3: 反思微调 (Reflection Fine-Tuning)
数据量:5K少量在线生成的反思样本。
目标:这是JarvisEvo具备“自我纠错”能力的关键。通过学习如何在错误路径上进行反思和修正,模型在处理复杂指令时的鲁棒性大幅提升。
SEPO:协同编辑-评估策略优化
在传统的强化学习(RLHF)中,模型通常依赖一个静态的“奖励模型”来打分。
但这存在一个致命缺陷:随着策略模型越来越强,它会学会“钻空子”(Reward Hacking),即通过生成某些特定的、诡异的模式来骗取高分,而不是真正提升自己的编辑能力。
为了解决这个问题,JarvisEvo提出了SEPO框架。它的核心思想是:让模型既做“运动员”也做“裁判员”,并通过两个并行的优化环,让这两种能力同步提升,互相制约。
Loop 1编辑者优化环 (Editor Policy Optimization)是让模型学会如何更好地使用工具来修出好图。
自我奖励 (Self-Reward) 机制:JarvisEvo不再依赖外部黑盒模型打分,而是利用自身的Self-evaluation能力。在生成修图轨迹后,模型会根据最终图像的美学质量和指令遵循度,自己给自己打分。
GRPO优化目标:采用群相对策略优化 (Group Relative Policy Optimization)。对于同一个输入,模型生成多条修图轨迹,通过比较这些轨迹的“胜率”(Pairwise Preference Reward)来进行更新,而非单纯依赖绝对分数,这使得训练更加稳定。
选择性损失掩码 (SLM)是其中的关键技术。这是一个防止“作弊”的机制。如果没有SLM,模型可能会发现:“只要我最后生成的自我评分文本是满分,loss就会变小”。
为了防止这种“信息泄露”,在计算编辑器的梯度时,强制掩盖掉自我评分部分的token。这样逼迫模型只能通过切实提升前面的推理质量 (Chain-of-Thought) 和 工具使用准确性 (Tool Use) 来间接获得高分,而不是直接生成高分文本。
评估者优化环 (Evaluator Policy Optimization)确保这个“裁判员”是公正、客观且符合人类审美的。
可验证的强化学习 (Verifiable RL):虽然Loop 1依赖自我打分,但如果裁判本身审美跑偏了怎么办?Loop 2专门解决这个问题。我们使用包含人类专家标注 (Human-Annotated) 的数据集来训练模型的评估能力。
分数对齐奖励 (Score Alignment Reward):在这个循环中,奖励取决于模型打分与人类专家打分的接近程度。
作用:这个循环不断校准模型的审美标准,防止其在Loop 1中陷入“自欺欺人”的自我陶醉,确保自我奖励信号的含金量。
这两个循环是交替进行的,形成了一种“左右互搏”的进化效应,打破了静态奖励模型的桎梏,实现了一种闭环的、可持续的自我能力提升。

在线反思数据生成机制 (On-Policy Reflection)
JarvisEvo如何学会“从错误中学习”?团队在Stage 2的训练过程中植入了一个自动化的数据生成:
捕捉契机:当模型生成了一个更好的修图轨迹Trajectory0(得分s0),且该得分显著高于之前的某次尝试Trajectory3(得分s3)时,触发反思生成。
归因分析:调用商业大模型(如Gemini-2.5-Pro)作为“导师”,输入源图、错误的修图结果O3、正确的修图结果O0以及用户指令。
生成反思链:“导师”会生成一段详细的分析文本(R),解释为什么O3失败了(例如“白平衡参数推得太高导致偏色”),并指出正确的做法。
构建样本:将这段包含“错误尝试 -> 深刻反思 -> 正确修正”的完整轨迹存入数据集Dataset_reft,用于第三阶段的微调。
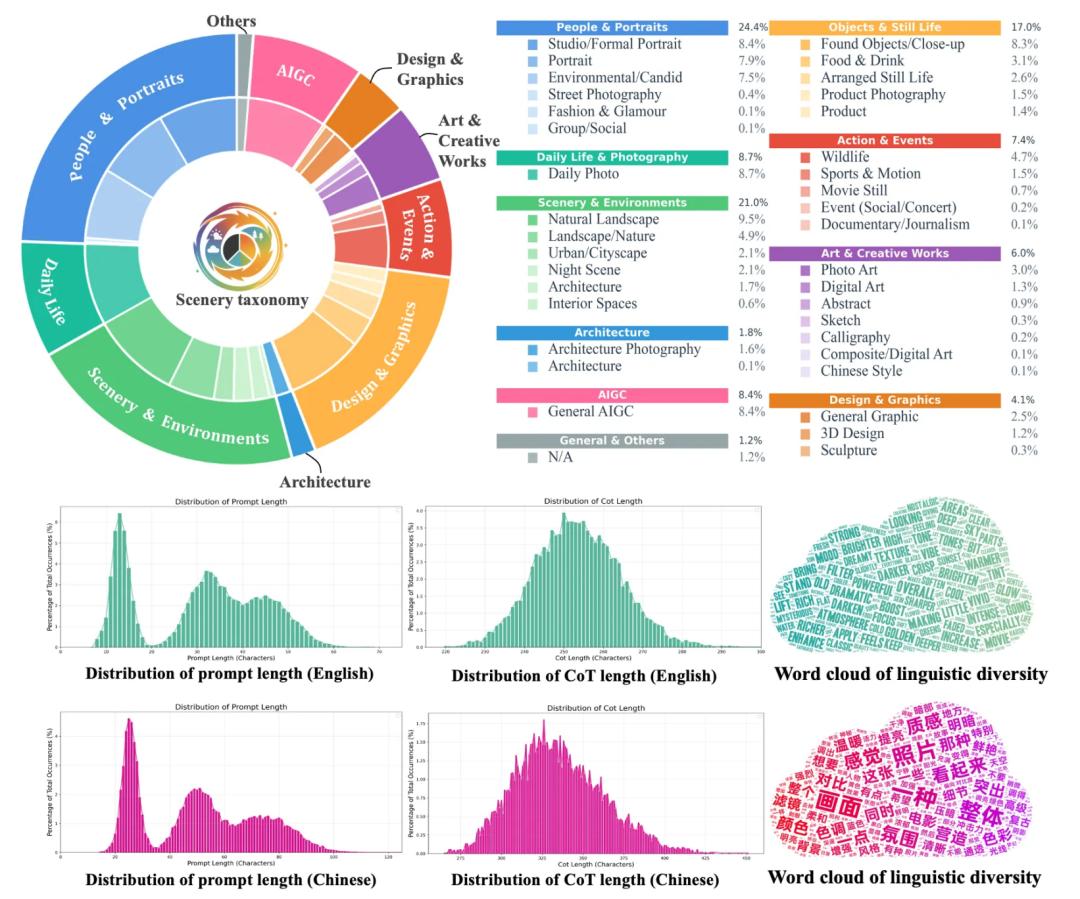
ArtEdit 数据集
为了支撑上述训练,团队构建了ArtEdit——一个包含170K样本的双语(中/英)专业修图数据集。包含人像、风光、建筑、静物、夜景等10大类、37个子类的专业摄影场景。通过A2L (Agent-to-Lightroom) 协议,无缝集成了Adobe Lightroom中的200+个修图工具。
ArtEdit-Lr (120K):专注于修图任务,包含完整的iMCoT轨迹(推理思考、工具参数、中间图)。
ArtEdit-Eval (50K):专注于审美评估,包含人类专家对图像质量和指令遵循度的打分(1-5分)。
实验结果
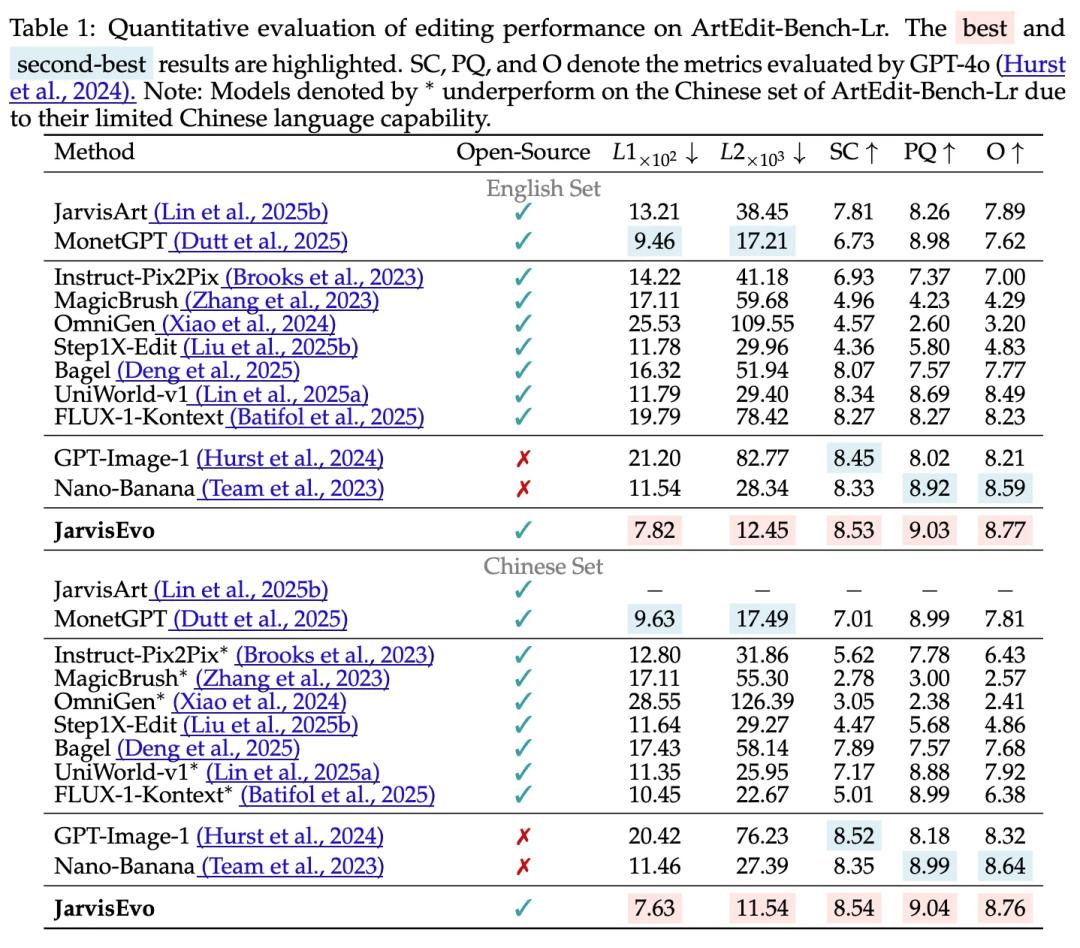
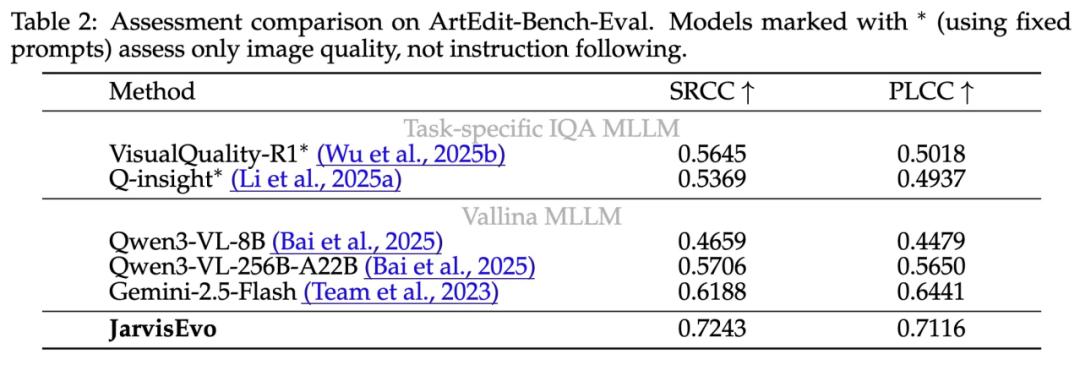
在ArtEdit-Bench评测中,L1和L2指标上,相比商业级模型Nano-Banana提升了44.96%,最大限度保留了原图细节 。
在SC(语义一致性)和PQ(感知质量)指标上全面领先,平均提升18.95% 。
并且其打分与人类主观偏好的相关性(SRCC 0.7243)超越了GPT-4o (Gemini-2.5-flash) 和专门的IQA模型。
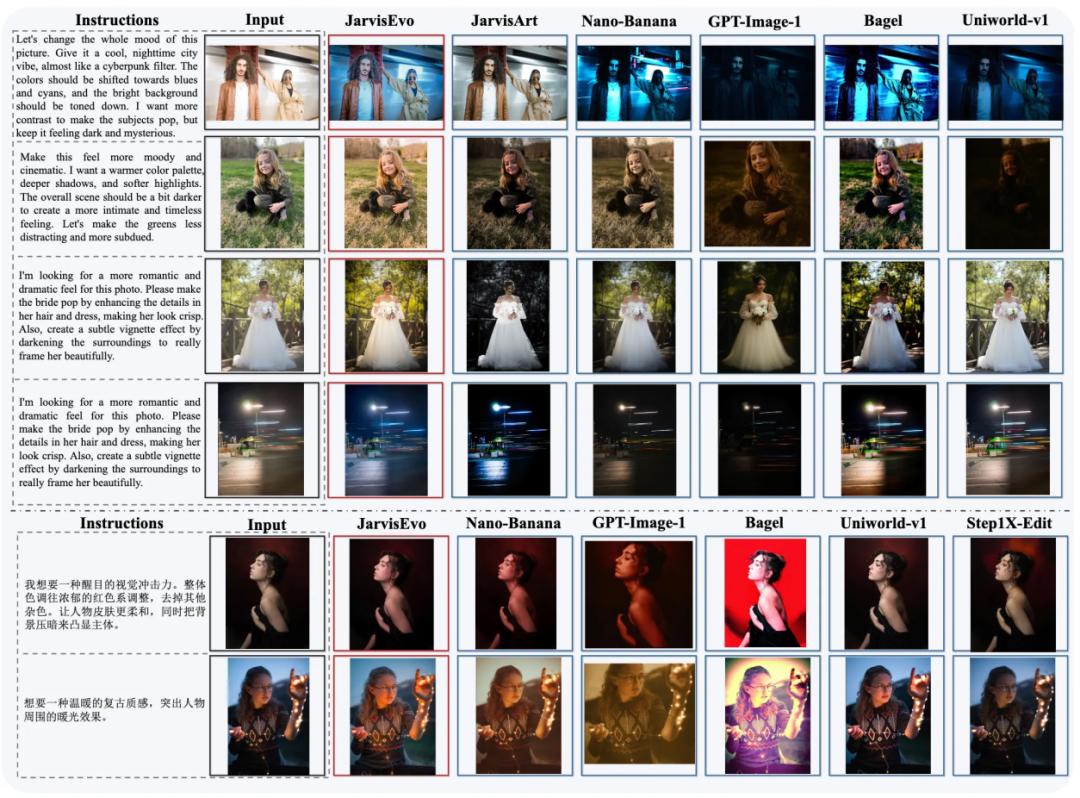
视觉效果上,对比其他模型,JarvisEvo处理后的图像更贴合用户指令,在风格营造、细节呈现等方面表现突出。
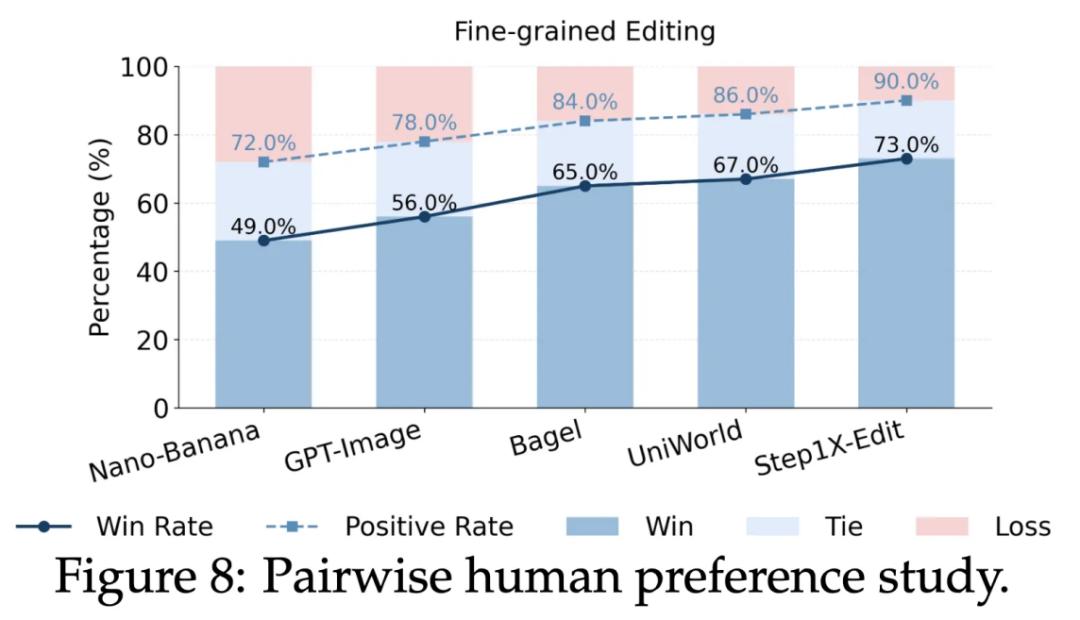
在包含 200 个样本的人类主观评测中,JarvisEvo在与Nano-Banana的对决中取得了49%的胜率(远超对手Nano Banana的28%),证明了其修图结果更符合人类审美 。
这种“生成器-内部批评家”的协同进化范式具有强大的通用性,未来有望从修图拓展至数学推理、代码生成及长程规划等领域。
同时,团队将致力于突破当前步数限制,探索超过10步的复杂长程推理任务。
感兴趣的朋友可戳下方链接了解更多细节~
项目主页: https://jarvisevo.vercel.app/
论文全文: https://arxiv.org/pdf/2511.23002
Github:https://github.com/LYL1015/JarvisEvo
Huggingface Daily Paper:https://huggingface.co/papers/2511.23002
