


新智元报道
【导读】基准WildVideo针对多模态模型在视频问答中的「幻觉」问题,首次系统定义了9类幻觉任务,构建了涵盖双重视角、支持中英双语的大规模高质量视频对话数据集,采用多轮开放问答形式,贴近真实交互场景,全面评估模型能力。
近年来,大模型在多模态理解领域进展显著,已能够在开放世界中处理图文甚至视频内容。
然而,一个普遍且严重的问题「幻觉」始终制约着其实际应用。
尤其在动态、连续的视觉场景中,模型可能生成与视频内容矛盾、违背常识或在多轮对话中前后不一致的回答。
当前主流评测基准多集中于单轮、单视角、选择题型的设定,难以真实反映模型在开放、连续、交互式对话场景中的能力与缺陷。这一评测体系的局限,阻碍了我们对模型在实际应用中表现的理解与优化。
为填补这一空白,来自国防科技大学与中山大学的研究团队提出了WildVideo,一个面向真实世界视频-语言交互的、系统性的多轮开放问答评测基准。

论文地址:https://ieeexplore.ieee.org/document/11097075
项目主页:https://chandler172857.github.io/WildVideo-leaderboard/
Github:https://github.com/yangsongyuan18/WildVideo
数据集:https://huggingface.co/datasets/yangsongyuan18/wildvideo
该工作首次从感知、认知与上下文理解三个层面系统定义了9类幻觉任务,并构建了一个涵盖双重视角、支持中英双语的大规模高质量视频对话数据集,旨在对多模态大模型进行更全面、更严格的压力测试,并已经被TPAMI 2025正式接收。
WildVideo的设计理念与核心贡献
贴近真实交互的评测框架WildVideo的设计完全围绕「真实世界应用」展开,摒弃了传统的单选/判断题形式,采用开放问答,模拟了真实对话中并无预设选项的场景。
更重要的是,它引入了多轮对话评测(最多5轮),要求模型具备连贯的上下文理解、信息关联与指代消解能力,这是此前视频评测中普遍缺失的一环。
细粒度、多维度的幻觉分类体系研究团队将模型在视频任务中可能产生的幻觉系统性地归纳为三大类、九小项:
感知幻觉:包括静态(物体属性识别)和动态(动作理解、视觉定位、跨帧一致性)两个维度,考验模型对视频内容的基础理解是否准确、稳定。
认知幻觉:分为常识认知(因果关系、跨模态指代)和世界知识认知,要求模型不仅能「看到」,还要能基于常识和外部知识进行合理推断。
上下文理解幻觉:专为多轮对话设计,包括上下文省略(理解对话中的省略信息)和跨轮检索(关联历史对话中的关键信息),直接评估模型在连续对话中的核心能力。
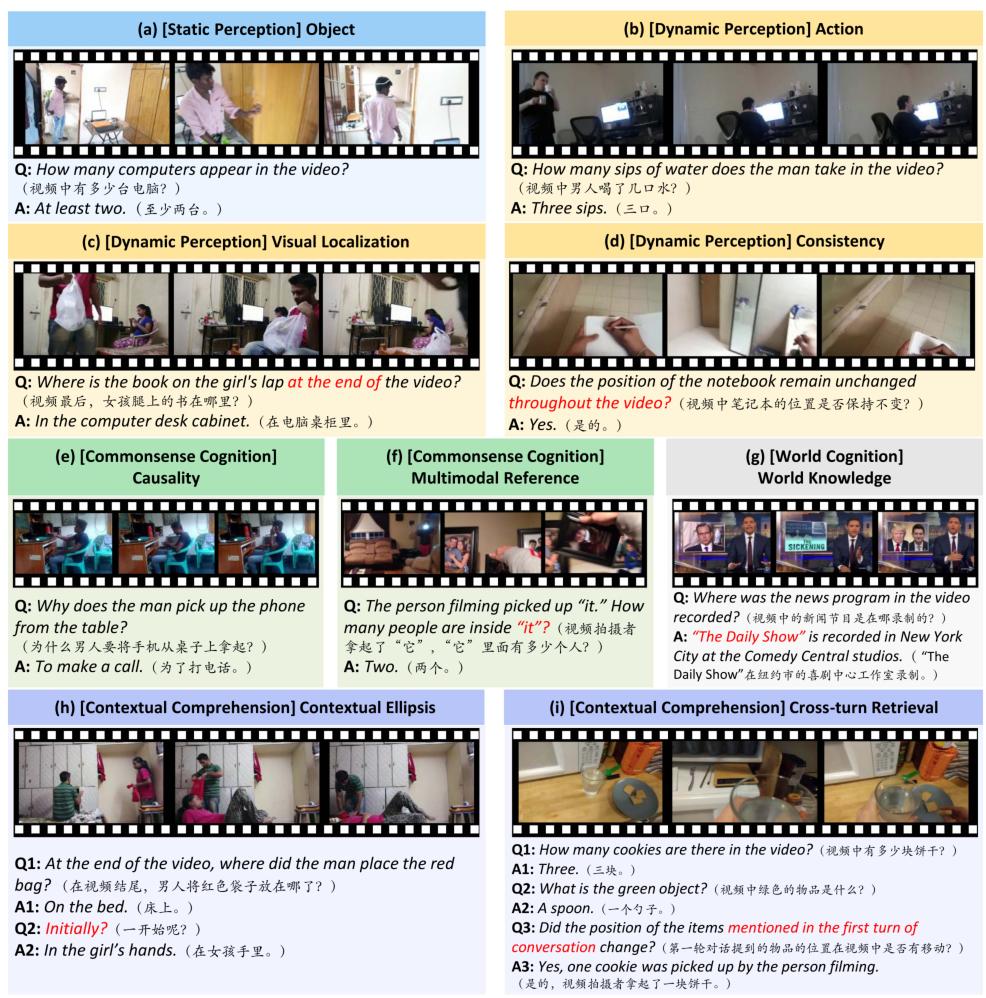
丰富、高质量的数据集
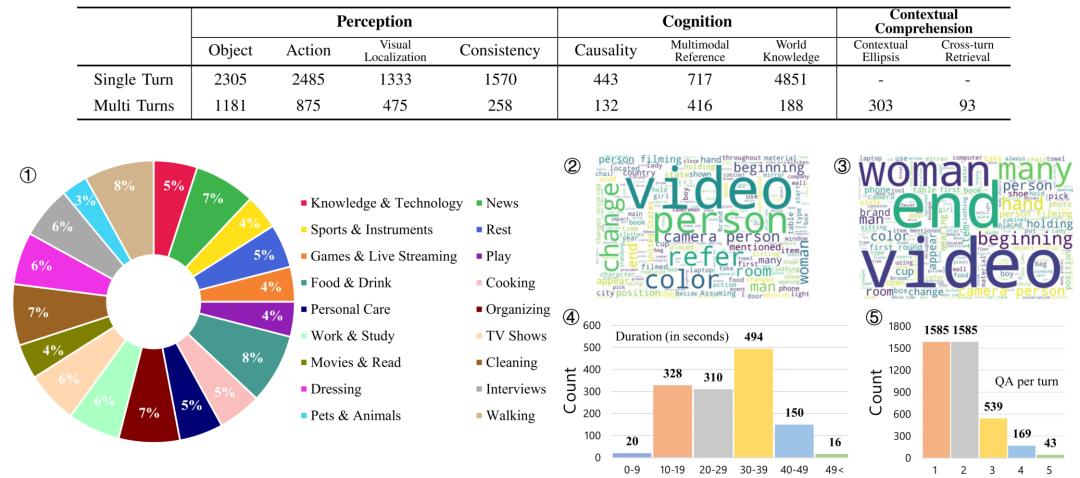
基准包含1,318段视频,其中既有来自Charades-EGO数据集的874段记录日常人类活动的第一人称与第三人称配对视频,以模拟不同的人类观察视角;还引入了444段涵盖全球事件与文化现象的YouTube视频,以丰富世界知识背景。
数据集最终包含了13,704个单轮问答对与1,585个多轮对话。数据构建过程融合了强大LLM的生成能力与多国PhD级别专家的多次人工审核与增强,确保了问题的挑战性、答案的精确性与对话的自然流畅性。

主要实验发现与深入洞察
研究团队在WildVideo上对14个主流开源与商业模型(如GPT-4o、Claude-3.5-Sonnet、Gemini系列、LLaVA-Video、InternVL等)进行了全面评估,揭示了若干关键发现:
整体表现揭示巨大挑战即便是当前最先进的模型,在WildVideo上也面临严峻挑战。
在单轮任务中,表现最佳的GPT-4o准确率仅为62.1%;当任务扩展至多轮对话时,其准确率进一步下降至52.7%。这清晰地表明,处理多轮交互的复杂性远高于单轮问答,现有模型的能力存在显著短板。
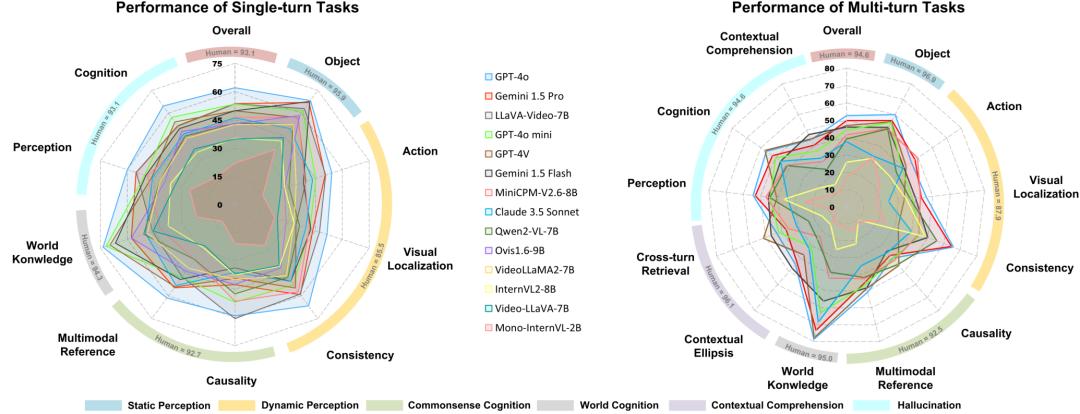
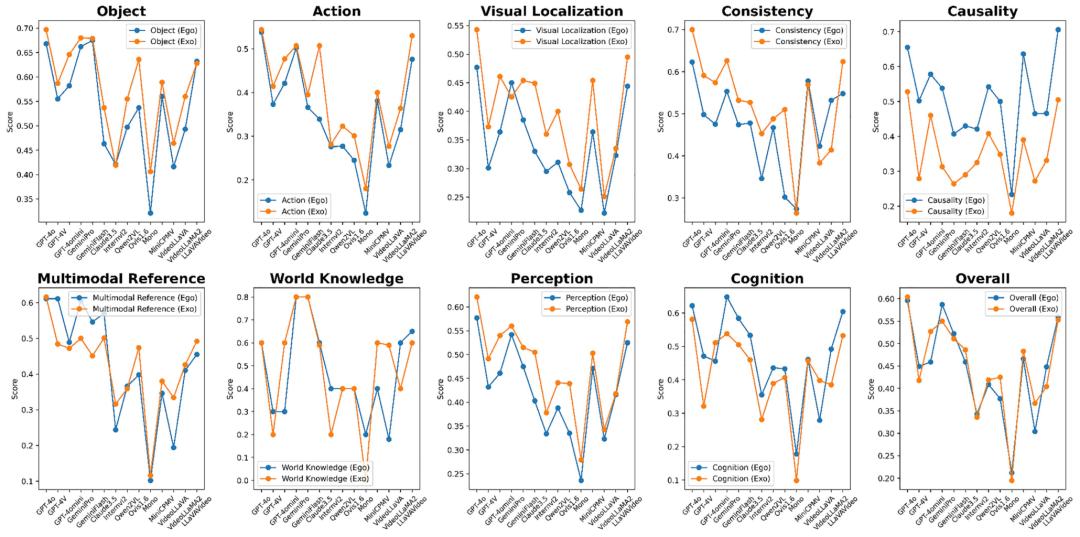
能力结构不平衡
感知层面:模型在静态「物体」识别任务上表现最佳,而在需要理解时序的「动作」识别和「视觉定位」任务上表现大幅下滑,暴露出对动态信息处理的不足。
认知层面:涉及常识推理和跨模态指代的任务成为所有模型的普遍难点,最低得分仅11.0%,说明模型在结合视觉与常识进行深层推理方面仍有很长的路要走。
上下文层面:多轮特有的「上下文理解」任务(省略与检索)表现最不理想,最佳得分也未超过51.4%,凸显了当前模型在维持长对话一致性、有效利用历史信息方面的瓶颈。
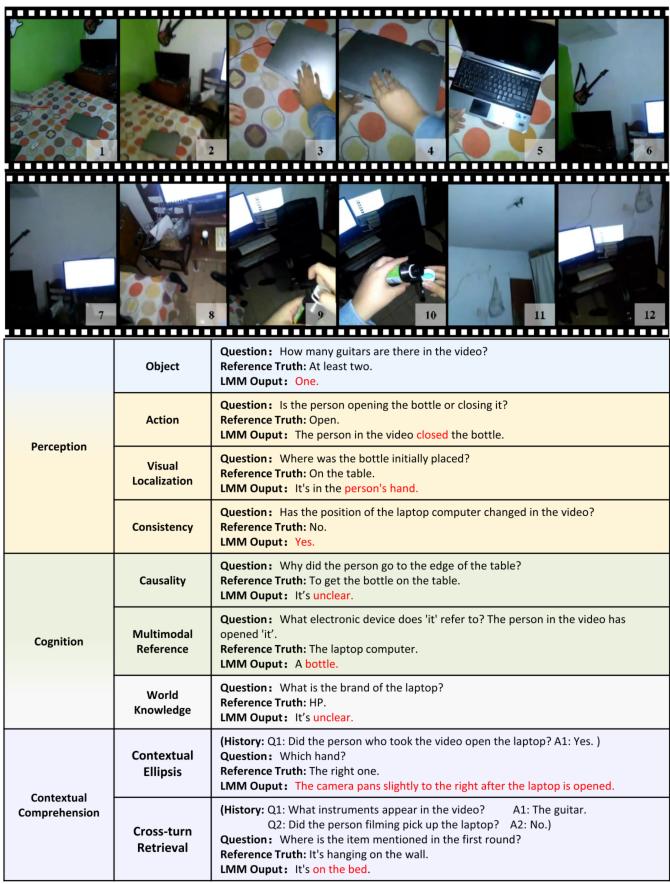
视角偏好与语言差异
视角偏好:几乎所有模型在第三人称(外视角)视频上的表现都系统性优于第一人称(自我视角)视频。研究者分析,这可能是因为第一人称视频存在更多运动模糊、视角突变和遮挡,对模型的动态感知提出了更高要求。
中英双语评测:WildVideo提供了完整的中文版评测集。实验显示,模型在中文任务上的表现普遍低于英文,最佳模型GPT-4o在中文多轮任务中也仅得54.0%,这为中文多模态模型的优化提供了明确的诊断工具。
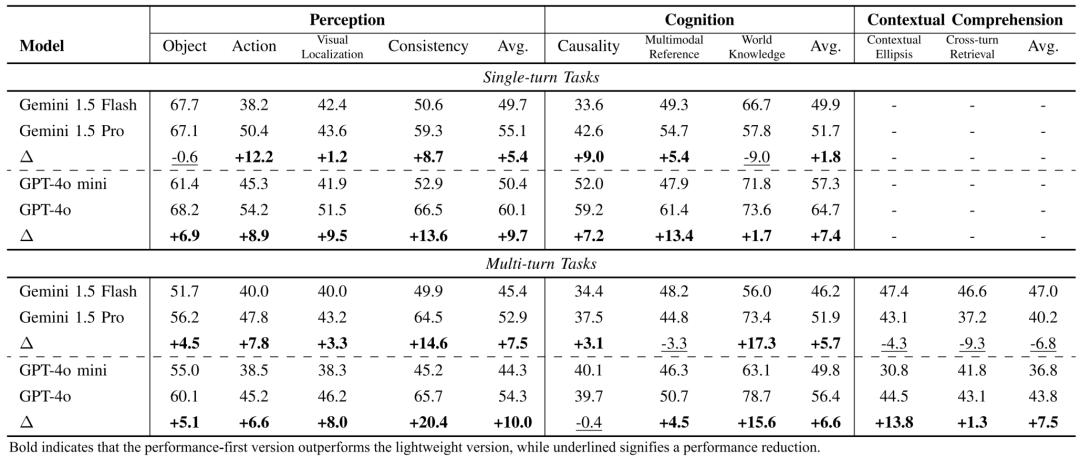
轻量版与性能版模型的权衡对比GPT-4o/GPT-4o mini和Gemini 1.5 Pro/Gemini 1.5 Flash发现,性能更强的版本在绝大多数任务上领先。
但有趣的是,轻量级的Gemini 1.5 Flash在多轮上下文理解任务中反超了其性能版,提示模型设计在效率与长上下文处理能力间可能存在不同的优化路径。
意义与未来展望
WildVideo的发布,不仅是为社区提供了一个新的、更严格的评测「标尺」,更是为多模态大模型的研究指明了重要的演进方向:
推动评测范式升级:它推动了视频理解评测从「静态快照问答」走向「动态连续对话」,从「客观选择」走向「开放生成」,更加贴近最终应用。
精细化诊断模型缺陷:其细分的幻觉分类体系能够帮助研究者精准定位模型失效的具体环节(是看不准、想不对,还是记不住),从而进行有针对性的改进。
促进多轮对话技术发展:基准明确揭示了当前模型在多轮交互中的脆弱性,将激励学术界和产业界在对话状态管理、长期记忆机制、指代消解等关键技术上进行更多投入。
支持跨语言与跨文化优化:中英双语并行的设计,为开发更具全球适用性的多模态模型提供了重要的评估基础。
WildVideo像一个功能全面的「体检中心」,它告诉我们,当前看似强大的多模态模型,在走向真正的、实用的视频对话智能之路上,仍需在动态感知、深层推理和连贯交互等多个关键能力上实现突破。
这项工作已开源相关基准数据,期待它能持续驱动视频语言交互领域向更可靠、更智能的方向发展。
参考资料:https://ieeexplore.ieee.org/document/11097075
