

IT之家 1 月 8 日消息,据通义大模型消息,今日正式发布并开源 Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列,这两个模型基于 Qwen3-VL 构建,专为多模态信息检索与跨模态理解设计,为图文、视频等混合内容的理解与检索提供统一、高效的解决方案。
IT之家附官方介绍如下:

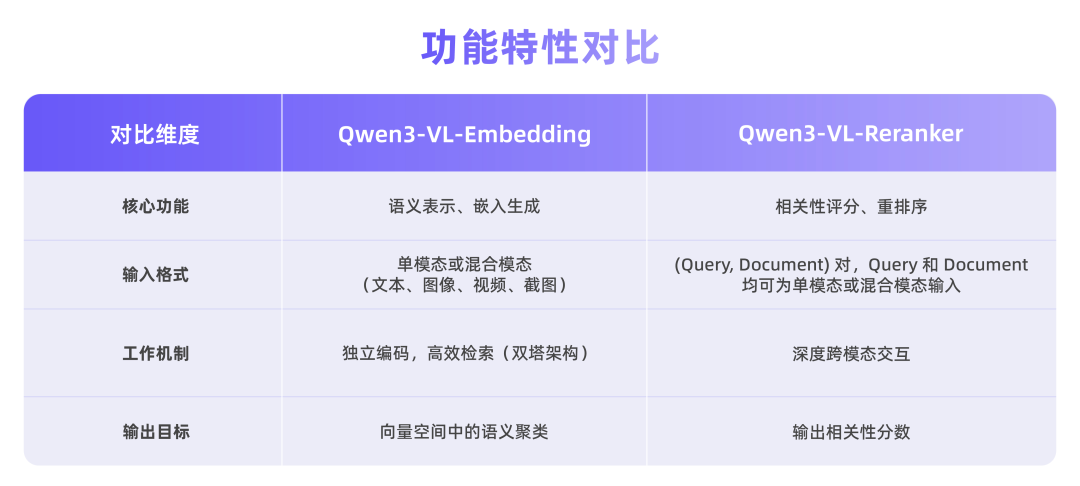
多模态通用性
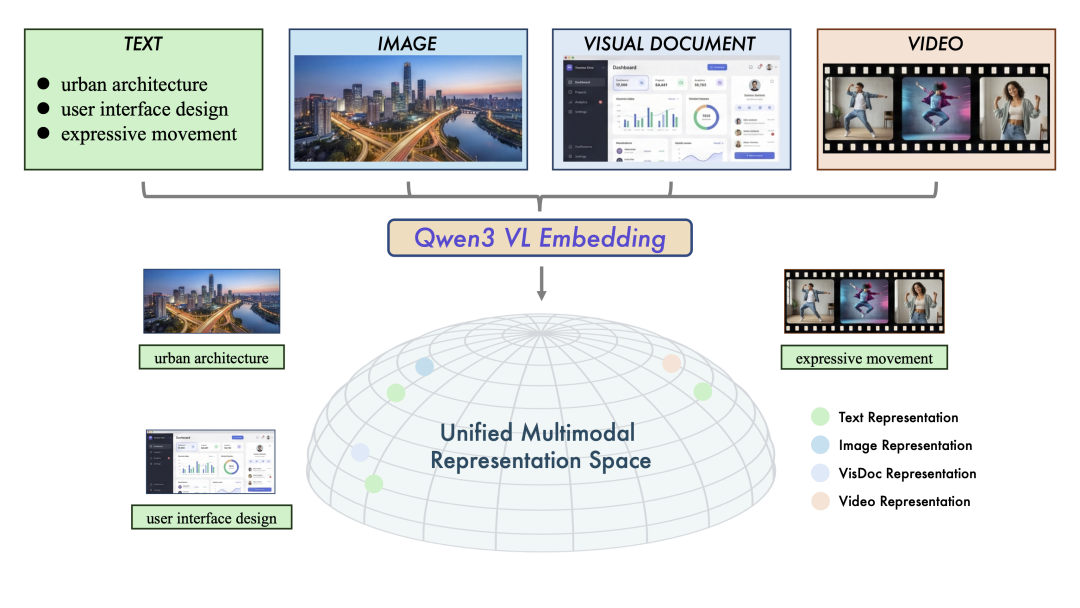
两个模型系列均能在统一框架内处理文本、图像、可视化文档(图表、代码、UI 组件......)、视频等多种模态输入。在图文检索、视频-文本匹配、视觉问答(VQA),多模态内容聚类等多样化任务中,均达到了业界领先水平。
统一表示学习(Embedding)
Qwen3-VL-Embedding 充分利用 Qwen3-VL 基础模型的优势,能够生成语义丰富的向量表示,将视觉与文本信息映射到同一语义空间中,从而实现高效的跨模态相似度计算与检索。
高精度重排序(Reranker)
作为 Embedding 模型的补充,Qwen3-VL-Reranker 接收任意模态组合的查询与文档对(eg:图文查询匹配图文文档),输出精确的相关性分数。在实际应用中,二者常协同工作:Embedding 负责快速召回,Reranker 负责精细化重排序,构成“两阶段检索流程”,显著提升最终结果精度。
卓越的实用性
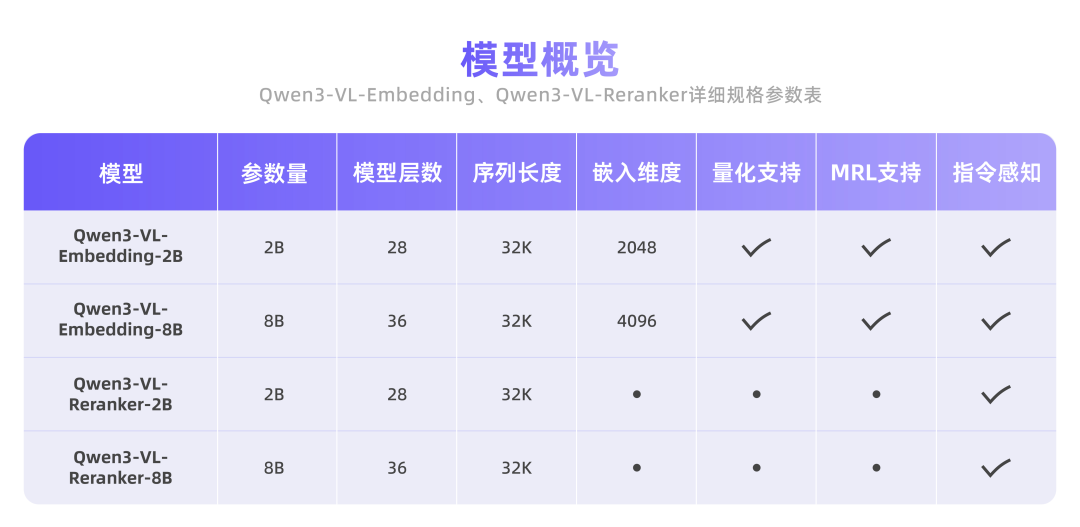
该系列继承了 Qwen3-VL 的多语言能力,支持超过 30 种语言,适合全球化部署。模型提供灵活的向量维度选择、任务指令定制,以及量化后仍保持的优秀性能,便于开发者集成到现有系统中。

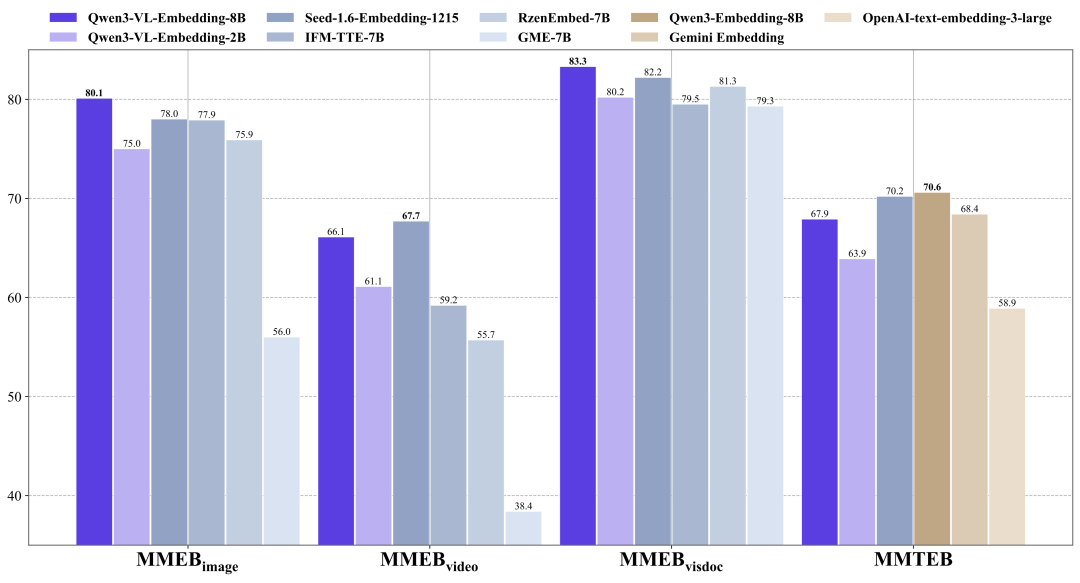
在 MMEB-v2、MMTEB 等权威多模态检索基准测试中,Qwen3-VL 系列模型展现出了强劲实力。
Qwen3-VL-Embedding
Qwen3-VL-Embedding-8B 模型在 MMEB-V2 上取得了业界领先的结果,超越了所有先前的开源模型和闭源商业服务。
在纯文本多语言 MMTEB 基准测试上,Qwen3-VL-Embedding 模型与同等规模的纯文本 Qwen3-Embedding 模型相比虽然有少许的性能差距。但与评测排行榜上其他同等规模的模型相比,它仍然展现出极具竞争力的性能表现。
Qwen3-VL-Reranker
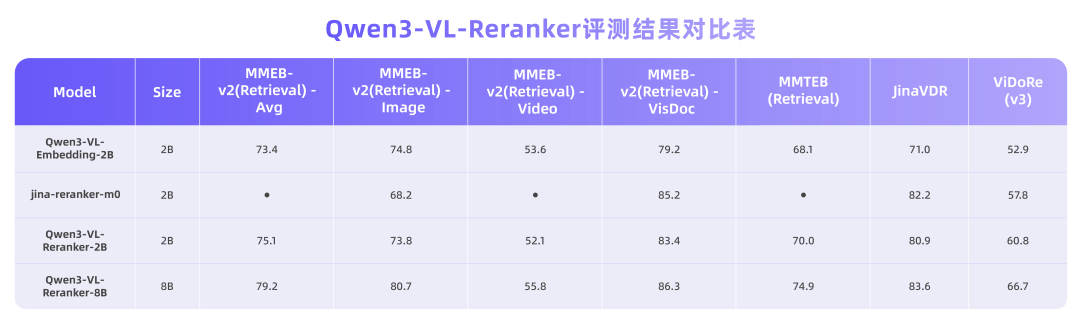
我们使用了 MMEB-v2 和 MMTEB 检索基准中各子任务的检索数据集进行评测。对于视觉文档检索,我们采用了 JinaVDR 和 ViDoRe v3 数据集。
评测结果表明,所有 Qwen3-VL-Reranker 模型的性能均持续优于基础 Embedding 模型和基线 Reranker 模型,其中 8B 版本在大多数任务中达到了最佳性能。
这些性能表现的背后,是针对多模态检索流程量身定制的架构设计。

Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 采用了不同的架构设计,分别针对检索流程的不同阶段进行优化。
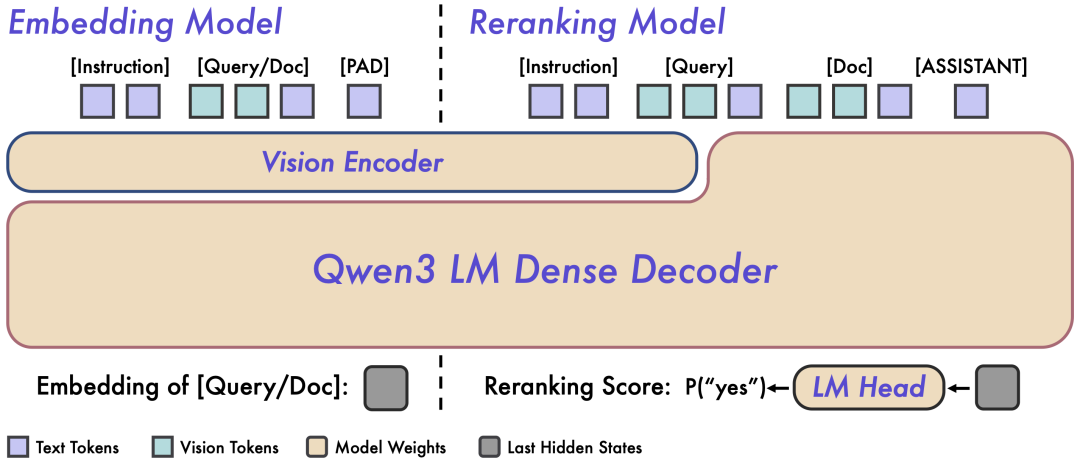
Qwen3-VL-Embedding 采用双塔架构,可以高效地将不同模态的内容独立编码为统一的向量表示,特别适合处理海量数据的并行计算。
Embedding 模型接收单模态或混合模态输入,并将其映射为高维语义向量。我们提取基座模型最后一层中对应 [EOS] token 的隐藏状态向量,作为输入的最终语义表示。这种方法确保了大规模检索所需的高效独立编码能力。
Qwen3-VL-Reranker 采用单塔架构,通过内部的交叉注意力机制,深度分析查询与文档之间的语义关联,从而输出精确的相关性分数。
在实际工作中,Reranking 模型接收输入对 (Query, Document) 并进行联合编码。它利用基座模型内的交叉注意力机制,实现 Query 和 Document 之间更深层、更细粒度的跨模态交互和信息融合。模型最终通过预测两个特殊 token(yes 和 no)的生成概率来表达输入对的相关性分数。
GitHub 仓库:https://github.com/QwenLM/Qwen3-VL-Embedding
魔搭 ModelScope:
https://modelscope.cn/collections/Qwen/Qwen3-VL-Embedding
https://modelscope.cn/collections/Qwen/Qwen3-VL-Reranker
