

一串长达百万碱基的非编码 DNA 序列,曾如天书般无从解读,如今其调控功能与变异影响皆可被精准预测;一个与癌症相关的罕见突变,曾让病因成谜,现在却能通过序列分析直接揭示其激活致病基因的全过程。
这都得益于登上权威科学期刊 Nature最新封面的统一 DNA 序列模型 AlphaGenome,这是 Google DeepMind Alpha 系列 AI 的新成员。

AlphaGenome 是一个能够统一预测长 DNA 序列功能的深度学习模型。它突破了以往技术的诸多限制,能够一次性处理长达 100 万个碱基对的 DNA 序列,并以极高的分辨率精准预测数千种与基因调控相关的分子信号。
更令人振奋的是,AlphaGenome 不仅能“读懂”基因组,还能在短短一秒内评估出遗传变异对多种生物过程的影响。

论文链接:https://www.nature.com/articles/s41586-025-10014-0
为了推进科学研究,AlphaGenome 现已向全球科研界开放:研究人员可以通过 AlphaGenome API 进行非商业研究,并且可以在 GitHub 上访问模型代码和权重。
这一突破引发了学界的高度关注。弗朗西斯·克里克研究所基因组学负责人 Robert Goldstone 评价道:AlphaGenome 是基因组人工智能领域的一个重要里程碑,其针对非编码DNA的高分辨率预测将技术从理论兴趣转向实际应用,使科学家能够以编程方式研究和模拟复杂疾病的遗传根源。
EMBL 欧洲生物信息学研究所(EMBL-EBI)真核生物注释团队负责人 Fergal Martin 也表示道,该模型不仅可加速解读人类基因组差异,未来更有望拓展至植物、动物和微生物等更多物种的 DNA 解读。
这一成果的问世,标志着破译基因组“调控密码”迈出了关键一步。该模型不仅是解析非编码变异致病机制的强大工具,也将加速罕见病诊断、药物研发及合成生物学进程,为未来生命科学研究开启了全新的可能。
AlphaGenome:为生命科学研究开启全新可能
AlphaGenome 是一款全新的人工智能深度学习模型。与以往专注于特定任务的工具不同,它是一个通用的“基因组解码器”,旨在解决生物学中最核心的难题之一:理解非编码DNA序列的功能及其变异的影响。
它具备强大的核心能力,能够一次性处理长达 100 万个碱基对(1 Mb)的超长 DNA 序列,并基于人类和小鼠基因组数据,同时预测包括基因表达、剪接、染色质可及性及三维结构在内的数千种关键分子信号,提供全景式的基因组功能图谱。
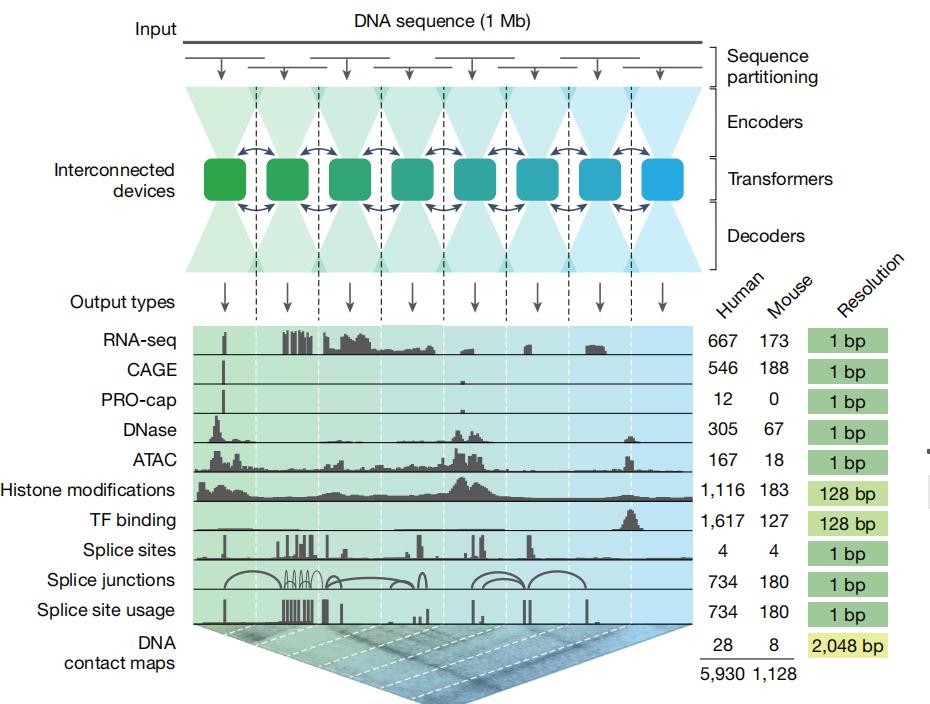
图|模型概述。AlphaGenome 可处理 1 Mb 的 DNA 序列及物种身份(人类/小鼠),预测 5930 条人类或 1128 条小鼠基因组轨迹,涵盖多种细胞类型及 11 种输出类型,并提供特定分辨率(最右侧)。
AlphaGenome 突破了长期以来限制该领域发展的技术瓶颈,并在严苛的性能测试中展现了卓越实力。
1.破解两大核心权衡
基于深度学习的序列功能预测模型长期面临着两大根本性的取舍难题,而 AlphaGenome 的出现彻底改变了这一局面。
过去,模型若想捕捉远端调控元件的长距离影响(如 200 kb 以上),往往不得不以降低输出分辨率(128 bp或32 bp区间)为代价;反之,若追求单个碱基级的高分辨率,则只能处理极短的序列。AlphaGenome 通过创新的模型架构——结合卷积层(检测局部模式)与 Transformer(处理长距离依赖),并利用分布式计算在 TPU 上进行高效训练,成功将这两者完美结合。它实现了在 1 Mb 超长序列上下文下的单碱基级高分辨率预测,且计算效率惊。
目前若干 SOTA 模型高度专精于单一模态,例如用于剪接位点预测的 SpliceAI4,但这些模型通常视野狭窄。AlphaGenome首次将多模态预测、长序列上下文和碱基对分辨率整合于单一框架,实现了对剪接连接点的直接建模,填补了现有技术在剪接变异细节分析上的空白,提供了更全面、深入的生物学洞察。
2.全面预测能力
AlphaGenome 模型以 1 Mb DNA 序列作为输入,能够跨越多种细胞类型,对多样化的基因组轨迹进行精准预测。在具体的预测功能上,AlphaGenome 实现了重要突破。特别是在剪接预测领域,它引入了全新的剪接连接点预测方法,并结合了剪接位点使用预测。这种双重预测能力提供了对RNA剪接过程更细致、更全面的分析视角。
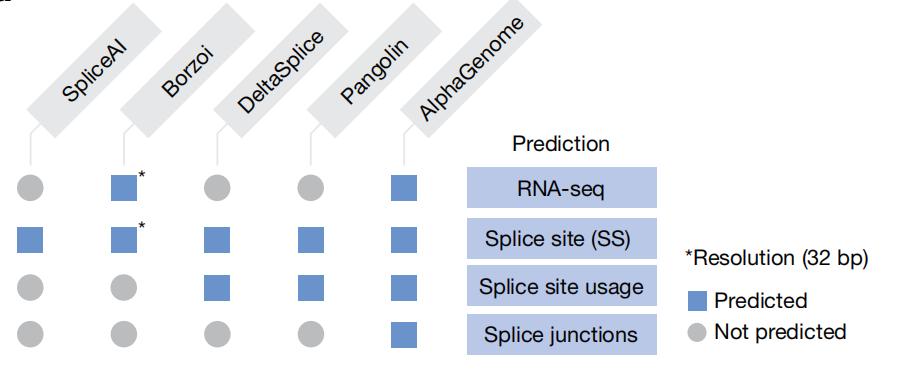
图|深度学习模型预测输出对比。除 Borzoi(32 bp)外,所有模型均以 1 bp 分辨率进行预测。Borzoi 通过 RNA-seq 覆盖度隐含预测剪接位点,而其他模型则生成明确预测结果。
AlphaGenome 的全面不仅体现在预测模态的多样上,更体现在其处理变异效应的高效性。
除了预测多种分子特性外,AlphaGenome 还能在一秒钟内高效地评估遗传变异对所有特性的影响。它通过高效对比突变序列与参考序列的预测差异,对所有预测模态进行综合打分。这种高效性使得在全基因组范围内大规模筛选致病变异成为可能。
3.性能卓越,多项基准测试登顶 SOTA
一系列全面的基准测试对该模型进行了严格评估,涵盖了其在未见 DNA 序列上准确预测基因组轨迹的能力以及变异效应预测任务的有效性。在对单个 DNA 序列进行预测时,AlphaGenome 在 24 项基因组轨迹预测任务中有 22 项达到了当前 SOTA 水平;而在预测变异的调控效应时,在 26 项预测评估中,它在 25 项上均达到 SOTA 性能。
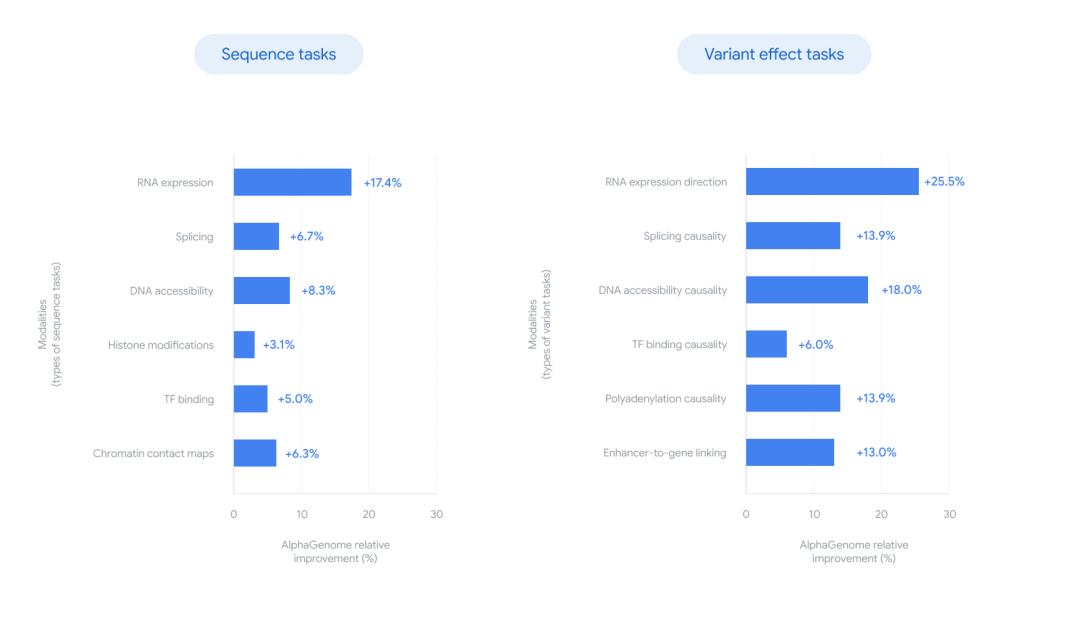
图|柱状图显示 AlphaGenome 在选定 DNA 序列及变异效应任务中的相对改进情况,并与各类别当前最佳方法的结果进行对比。
值得注意的是,这些被超越的模型中不乏许多专精于单一任务的特化模型。AlphaGenome 在多领域的反超充分证明了其通用架构的强大潜力,科学家们无需再维护多个模型工具箱,仅凭 AlphaGenome 即可高效应对多种预测任务。
AlphaGenome的应用前景
AlphaGenome 为未来的生命科学研究和医学应用开辟了广阔的前景,其强大能力将在以下三大领域发挥关键作用:
1.疾病理解与诊断
在罕见病诊断领域,AlphaGenome 能够为现有变异注释流程提供强有力的功能证据。特别是对于那些非编码的意义未明变异(VUS),模型能帮助研究人员更准确地判断其致病性,从而为罕见病(如孟德尔遗传病)患者开辟新的诊断途径。
对于癌症等复杂疾病,AlphaGenome 能够揭示非编码区变异如何通过复杂的调控网络导致疾病。例如,在 T 细胞急性淋巴细胞白血病(T-ALL)的研究中,AlphaGenome 成功模拟了特定突变引入 MYB 结合 motif 进而激活致癌基因 TAL1 的过程。这种能力有助于科学家发现新的治疗靶点,并深入理解疾病的生物学根源。
对此,伦敦大学学院儿科血液肿瘤学临床教授 Marc Mansour 评价道,AlphaGenome 为识别驱动性非编码变异带来了跨越式进步,将相关研究周期从数月显著缩短至数周,它不仅对癌症研究至关重要,也将在疾病特征关联分析、合成生物学及功能基因组学等多个前沿领域发挥关键价值。
2.合成生物学与基因治疗
AlphaGenome 的预测能力可以转化为设计能力,指导科学家创造出具有特定功能的合成 DNA。例如,研究人员可以设计出仅在神经细胞中激活、而在肌肉细胞中保持沉默的“组织特异性增强子”,从而实现精准的基因调控。
在基因治疗领域,模型的实时预测功能可直接用于优化治疗工具。在设计治疗性反义寡核苷酸(ASO)时,AlphaGenome 可以预测其修饰效果,帮助研究者筛选出最安全、有效的候选药物,加速新疗法的开发进程。
3.基础研究加速器
AlphaGenome 能够快速生成科学假设,并对海量基因序列进行功能预测,帮助科研人员在开展昂贵的实验之前,优先筛选出最有可能成功的实验对象,从而大幅提高研究效率。
同时,AlphaGenome 也能预测并验证那些由生成式模型创造出的全新 DNA 序列的功能特性,从而增强基于 DNA 序列训练的生成模型的能力,共同推动生物学发现的边界。
局限性和未来展望
尽管 AlphaGenome 在破译基因组调控密码方面取得了显著进展,但作为一个前沿的科研工具,它仍面临一些挑战。
例如,准确捕捉那些距离目标基因超过 100000 个碱基对的极远端调控元件的影响,仍是一个尚未完全攻克的难题。这些长距离相互作用对于基因的正确表达至关重要,但建模难度极大。
虽然模型已能预测数百种细胞类型的轨迹,但精准复现不同生理、病理或发育状态下,细胞和组织特有的细微调控模式,并准确预测变异在这些特定环境中的效应,仍有提升空间。
此外,AlphaGenome 在物种与模态覆盖上存在局限。目前训练数据和评估主要集中于人类和小鼠,对更多物种的泛化能力有待拓展。同时,其预测主要集中在蛋白质编码基因的相关模态上,对非编码 RNA(如 microRNA)等领域的覆盖尚可丰富。
目前尚未针对个人基因组预测对该模型进行基准测试,这是该领域模型普遍面临的薄弱环节。由于 AlphaGenome 仅预测变异的分子效应,而复杂性状和疾病往往涉及发育、环境等更广泛的生物学过程,这超出了模型直接的“序列-功能”关联范畴,限制了其在复杂性状分析中的直接应用。
为解决这些局限性,Google DeepMind 团队将在未来的工作中推动多项研究方向的发展。
例如,他们将通过检测更多物种或大规模扰动非编码调控元件来增加输入基因组的多样性。这将有助于构建下一代变异效应预测模型,提升其泛化能力。
同时,提升变异预测的准确性和实用性是另一个关键方向,例如通过任务特异性校准、在扰动数据集上进行微调,或整合单细胞数据。研究团队也将为模型整合更广泛的数据模态,如 DNA 甲基化和 RNA 结构特征,以提供更全面的生物学视角。
另外,将 AlphaGenome 的预测结果与其他变异效应评估指标(如基于保守性的评分)以及现有的基因功能和生物通路数据相结合,有助于推进对常见与罕见变异的深入分析,实现多学科知识的交叉验证。
未来的基础模型还将探索利用 DNA 语言模型、扩展多物种能力,并开发鲁棒的检测偏差校正方法。此外,对模型确定性的评估也将有助于更好地解释预测结果,从而为解读 DNA 序列中编码的复杂细胞过程奠定更坚实的基础。
