

几个月前,Artificial Analysis还在提醒人们注意,关于AI进展放缓的谣言被严重夸大了!
但到了2026年初,相信几乎没有人再相信「AI进展放缓」这样观点,因为它一直都在加速发展。
2025年年初,那时的世界上甚至还不存在真正意义上的「代码Agent」。
但仅仅到了年底,软件工程这个古老的职业就被「氛围编程」(Vibe Coding)永远地改变了。
程序员们不再把代码机械地复制粘贴到ChatGPT或者CursorChat里,而是开始熟练地向Agent下达指令,看着它们连续几分钟甚至更长时间地自主埋头苦干。
这就是Artificial Analysis刚刚发布的《2025全球AI年终报告》为我们揭示的疯狂现实的一个侧面。

在过去的一年里,全球AI军备竞赛不仅没有丝毫降温,反而彻底白热化。
当然,这样残酷的竞争,对于AI使用者们也带来了一个令人极其振奋的利好:
各个智力层级的AI使用成本正在以不可思议的速度跳水。
AI实验室们死磕强化学习,在大规模稀疏混合专家(MoE)架构上疯狂内卷,再加上英伟达Blackwell硬件的王者降临,共同推高了这场技术海啸的浪潮。
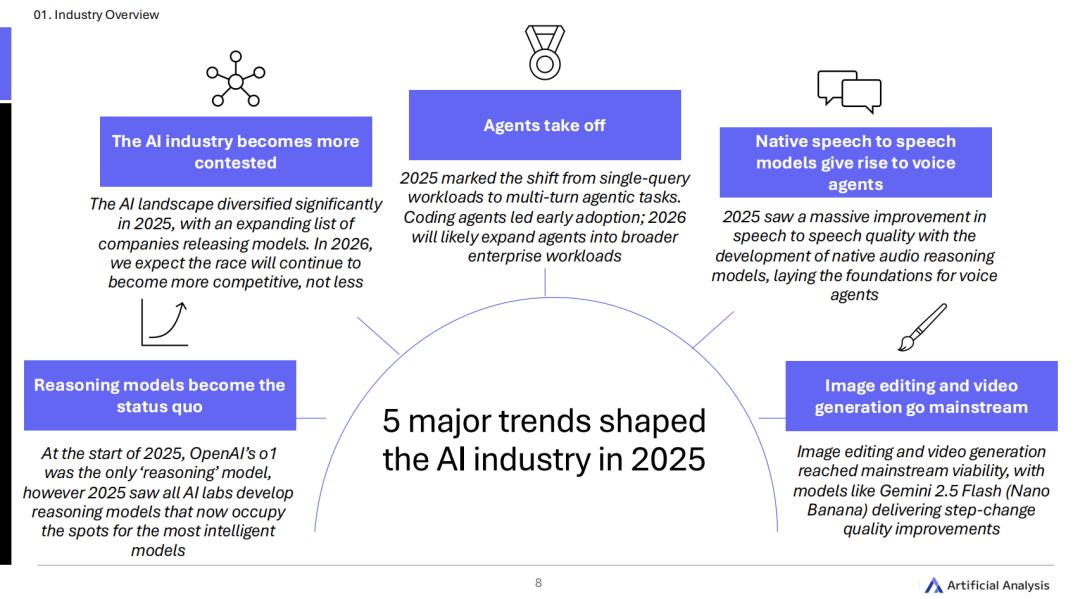
Artificial Analysis的这份报告认为,2025年,5大核心趋势彻底重塑了整个AI行业的骨架:
竞争极度拥挤:赛道变得空前激烈,新玩家与国际巨头贴身肉搏。
推理成为绝对标配:思考型模型一统天下。
Agent迎来全面爆发:从单一指令走向长周期的自主任务。
多模态跨越奇点:视频生成与图像编辑杀入主流认知。
原生语音觉醒:端到端语音大模型赋予了语音Agent真正的灵魂。
「思考」成为绝对标配,同级推理成本暴跌128倍!
仅仅在2025年初,OpenAI的o1还在孤独领跑,是市面上唯一的推理型选手。
但到了年底,画风突变,几乎所有的顶级AI实验室全部拿出了自己的「思考型」推理模型。
这个范式转移,直接霸占了人类所能见到的最高智力榜单。
OpenAI依然以GPT-5.2(xhigh)在年初和岁末都保住了「最聪明大脑」的桂冠。
但这家昔日霸主的领先优势正被极速压缩。
Anthropic带着Claude4.5Opus(Reasoning)紧追不舍,谷歌拿出了Gemini3Pro,xAI也毫不示弱。
AI军备竞赛,对普通用户带来的好消息就是:聪明不再等同于昂贵。
由于模型体积的不断缩小、软硬件效率的极致提升,我们在2025年初还要顶礼膜拜的o1级别智力,其每Token的使用成本,在短短一年内发生了自由落体般的坠落,整整降了128倍!
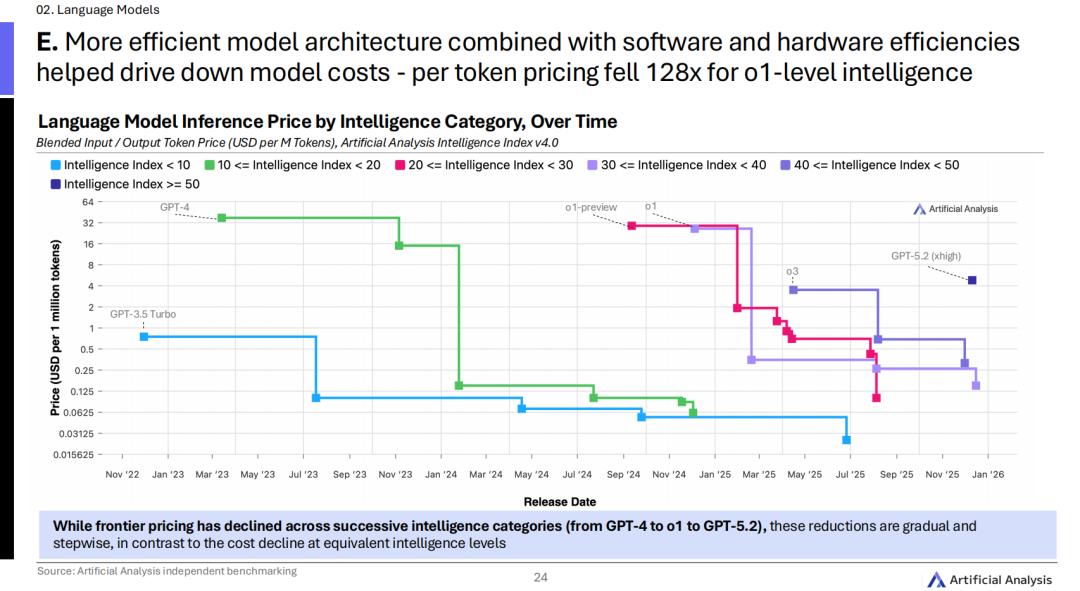
现在,我们可以在同样的预算下召唤出远超以往的超级大脑,或者用极低的成本普及过去的顶级智力。
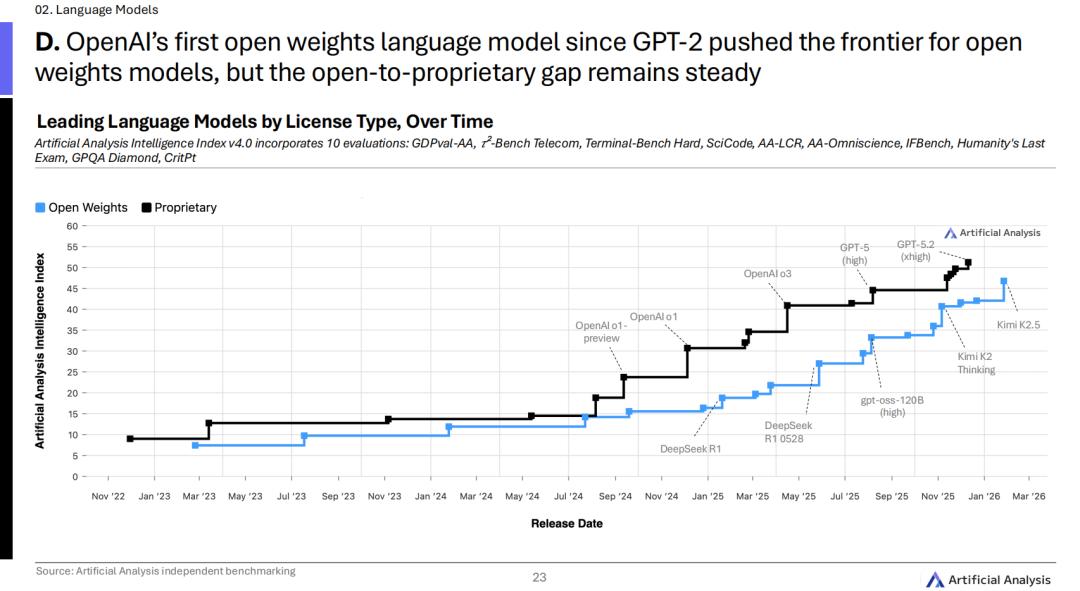
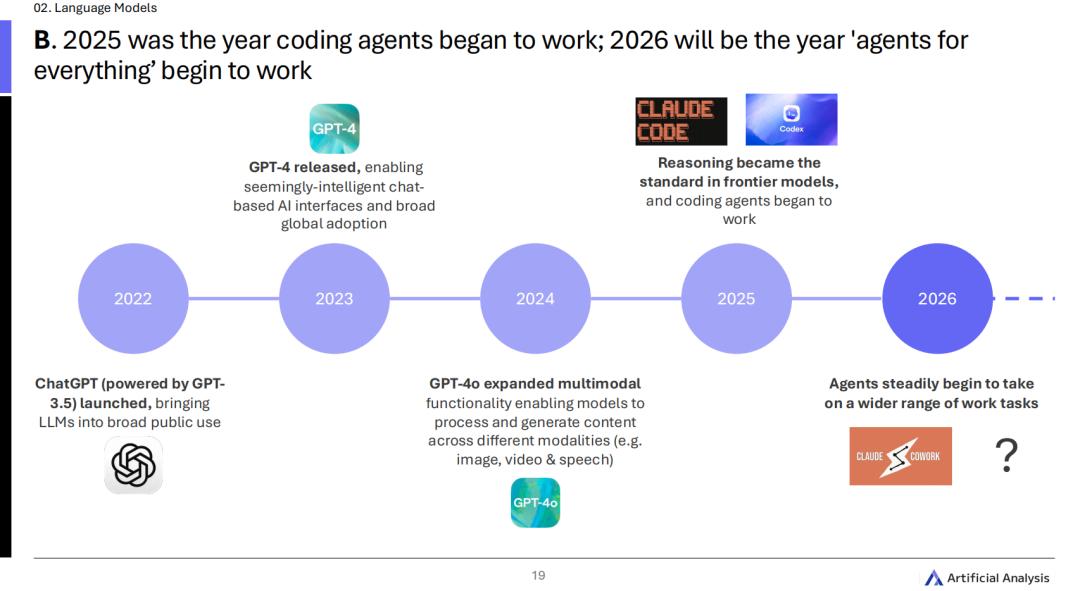
从「复制粘贴」到「自主打工」,2025,Agent终于落地了
2025年,Agent完成了从单一测试玩具到企业级核心生产力的跃升。
也是在这一年,我们对AI的期待,终于从「你给我答案,我来干活」变成了「你直接把活干完」。
这一切的引爆点,是代码Agent的大放异彩,长周期编程任务成了这场生产力革命最大的受益者。
大厂和初创团队都在疯狂发布代码Agent,如今的模型不仅出厂自带极其熟练的工具调用能力,更被强化学习深深地注入了自主执行长周期任务的本能。
Artificial Analysis在报告中提到一个变化:
在Agent的漫长工作流里,并不是模型吐出的Token越多,智力就越高。
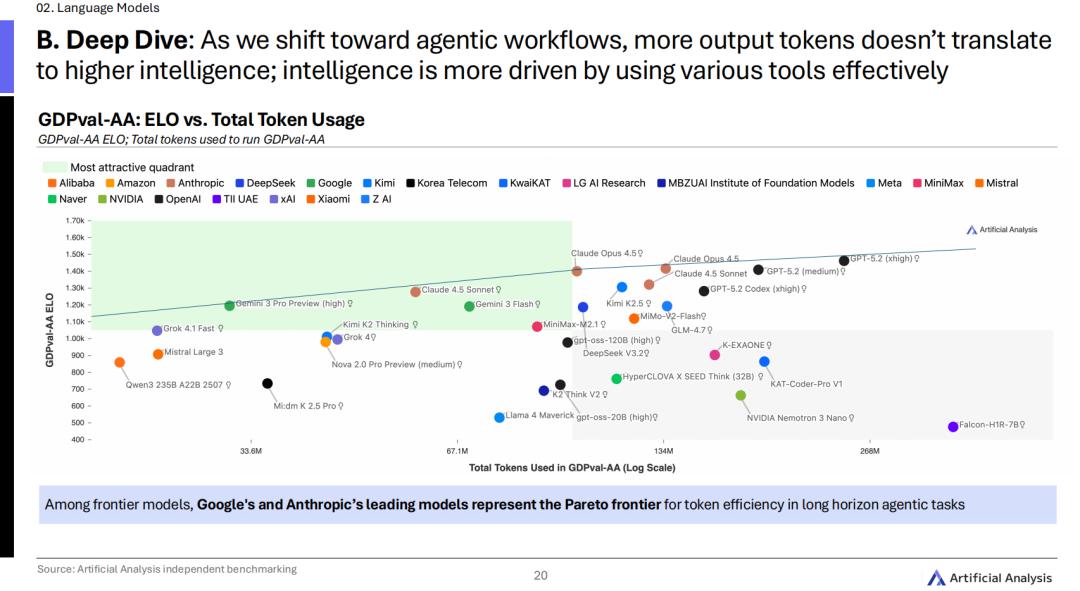
真正的顶级高手,赢在能巧妙且高效地使用各种外部工具。
在这张残酷的帕累托前沿图表上,谷歌和Anthropic的旗舰模型成为了全场效率与智力平衡的绝对王者。
由于2025年是代码Agent大获全胜的一年,Artificial Analysis据此断言:2026年,将彻底成为「万物皆可Agent(Agents for everything)」的元年。
原生多模态大爆发,视频模型进入「带声时代」
2025年,大模型迎来了原生多模态的大爆发。
视频模型,在这一年彻底撕掉了「实验品」的标签,真正走向了主流可用。
年初还在被顶礼膜拜的Sora,到了年底已经被RunwayGen-4.5超越了近200个ELO积分。
更重要的一个变化是,视频模型不再是「哑巴」了。
2025年5月发布的Veo3,是第一个在极高画质下原生支持音频生成的视频大模型。
紧接着,全行业集体爆发,OpenAI的Sora2、Lightricks的LTX-2等,让「自带BGM和环境音的视频生成」成为了主流标配。
这份报告还给出了一个重磅结论:在图像与视频生成领域,中国和美国已经完全处于同等水平!

端到端S2S推理大爆发,语音与音乐AI的全面进化
2025年第四季度,语音与音乐AI圈经历了一场真正的底层革命。
以前的语音助手为什么总显得有些迟钝和机械?因为它们在脑子里要走一条极其繁琐的「翻译」流水线:
先把听到的语音转成文字(STT),然后把文字交给大语言模型去思考(LLM),最后再把思考出的文字转回语音(TTS)读出来。
这种级联拼接模式不仅延迟高,还会把人类语气中的情绪、叹息、重音过滤掉。
但在2025年,原生音频推理(Nativeaudioreasoning)技术让模型学会了直接用声波的形状去思考,它们摒弃了文字这个「中间商」,开始端到端地处理音频。
这场技术革命,直接引发了榜单的大洗牌。
四季度,xAI凭借极快的响应速度和恐怖的原生听觉理解力,强势掀翻了前任霸主谷歌Gemini2.5NativeAudioThinking,登顶了BigBenchAudio评测榜首;而亚马逊的Nova2.0Sonic则极其精准地踩中了市场的痛点,加冕性价比之王。

在语音转文本(STT)的战场上,单项选手正被全能学霸降维打击。
像AWS的Nova2Omni这类多模态大模型,现在做起语音转文字,简直就像是接了个顺手的「兼职」。
它们甚至都不需要专门去练听写,准确率就已经能和专业软件打个平手了。
与此同时,为了解决语音助手总是慢半拍的毛病,ElevenLabsScribev2Realtime和英伟达ParakeetRealtime这种专门死磕超低延迟的模型也出来了。
有了它们,语音智能体真正落地到现实场景里的绊脚石也被搬开了。
现在的顶级模型不仅声音好听,甚至能在指令下完美控制情感基调、语速、重音,还能极其自然地插入笑声、叹息声和呼吸声。
过去总让人觉得有些别扭的AI味儿,现在已经基本消失了。
随着SunoV4.5和ElevenLabsMusic这些工具开始在大众里普及,现在只要花上极底成本,就能轻松合成出足够以假乱真的人声或乐曲。
当然,这种拟真也引发了极大的恐慌,声音克隆的泛滥,直接倒逼全行业开始把音频水印和出处验证系统当成了最高优先级的安全限制。
报告也极其克制地指出了当下的局限:
虽然语音Agent在诸如客服、预订等结构化交互中已经表现得像个真人,但一旦遇上模糊不清的语境、需要长线逻辑推导的多轮对话,或者嘈杂恶劣的录音环境,它们依然会露出机器的笨拙底色。
算力权力的游戏,英伟达大规模交付与200亿美元的「终局豪赌」
2025年的底层硬件基础设施,经历了一次脱胎换骨的成熟进化。
英伟达的Blackwell芯片,B200和GB200NVL72机架级系统在2025年全线铺开,进入了真实生产环境。
像IBM的Granite4系列和OpenAI的GPT-5.3Codex,就成了最早一批公开宣布用上GB200集群的头部大模型。
随后在第三季度,英伟达又顺势发布了B300和GB300。
这次的硬件升级非常直接:在B200的基础上,不仅HBM3e显存增加了50%(达到288GB),FP4精度下的算力也随之提高到了14PFLOPs。
但英伟达的野心远不止于卖芯片。
在2025年12月,整个科技圈被一笔交易彻底引爆:英伟达豪掷约200亿美元天价收购了Groq。
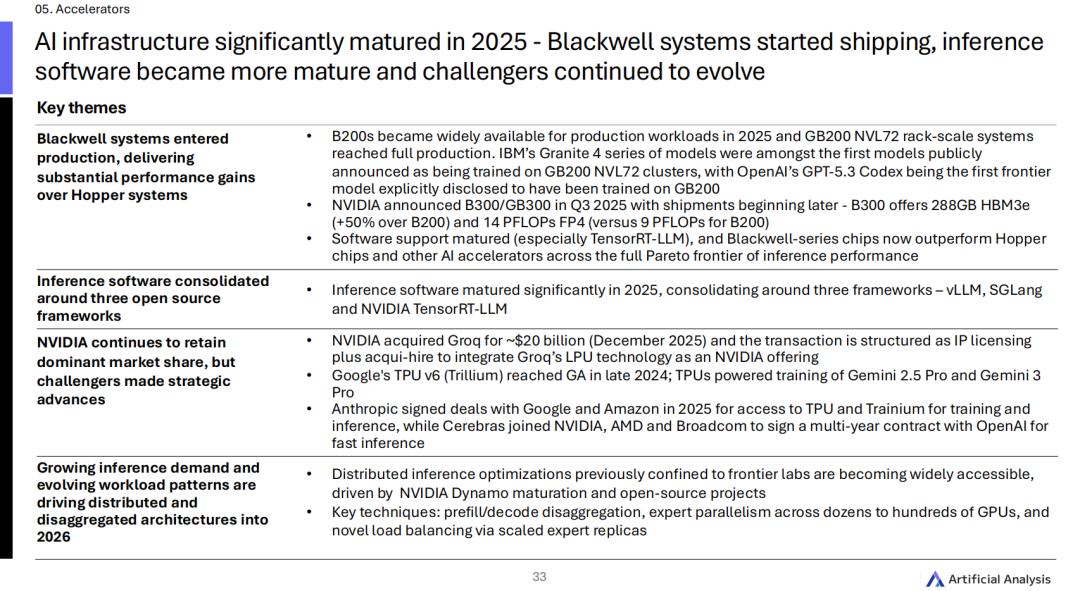
这笔交易极其聪明地被包装成「IP授权加人才收购(acqui-hire)」的模式。
英伟达看中的,是将Groq的LPU推理技术直接内嵌到自己的算力帝国中,试图彻底锁死AI推理市场的咽喉。
然而,权力的游戏里从来不缺野心家。
谷歌的TPUv6(Trillium)在2024年底已经全面铺开,它支撑了Gemini2.5Pro和Gemini3Pro的庞大需求。
Anthropic也在2025年同时牵起了谷歌与亚马逊的手,将TPU和Trainium一并接入自己的训练与推理矩阵。
而一直被低估的Cerebras则是联手AMD和博通,与OpenAI签下了一纸多年期的极速推理巨额合同。
在这场算力狂飙的背后,推理端的工作流也在悄然发生着剧变。
因为Agent时代的到来,过去那种堆在一台机器上傻跑的模式已经行不通了。
分布式推理优化成了2025年的一个明显趋势。
靠着英伟达Dynamo生态和开源社区的推动,过去那些只有顶级大厂才玩得转的技术,现在普通开发团队也能用上了。
现在的做法是把Prefill(预填充)和Decode(解码)这两个环节直接拆开,让几十甚至上百张GPU分工合作,一起做专家并行计算。
在这个过程中,之前五花八门的推理框架也慢慢收敛,最后大家的选择基本都稳定在了vLLM、SGLang以及英伟达「亲儿子」TensorRT-LLM这三个主流框架上。
拥抱即将到来的零边际成本智力
看完Artificial Analysis的这份年终报告,最直观的感受就是,AI发展的倒计时真的就在耳边了。
现在的AI早就不是刚出来时大家拿来尝鲜的聊天玩具,它已经实打实地变成了各行各业都在用的核心生产力。
当o1这种级别的聪明大脑,使用成本在一年里真真切切地降了128倍;当原本只能听口令做简单操作的Agent,现在已经可以自己埋头写上几十分钟的代码;当多模态让机器真正像人一样,能用耳朵听、用眼睛看去理解这个世界——
无论是创业者、开发者还是企业主管,可能都需要停下来认真想一个问题:目前的业务模式,还能适应接下来这个「万物皆可Agent」的新阶段吗?
到了2026年,随着机器智力的获取成本越来越低,所有的公司、团队、产品甚至我们每一个普通人,都需要尽早去适应Agent化的工作方式。
2026年2月,理想汽车基座模型MindVLA团队与国创决策智能技术研究所联合发布了一篇论文——
提出了面向端侧大语言模型的「硬件协同设计扩展定律」。
论文直面了当前最核心的挑战之一:
如何将越来越强大的大语言模型高效地部署在资源受限的「端侧设备」(如汽车、手机、机器人)上。
理想正在从一家以增程技术见长的汽车公司,蜕变为一家以智能驾驶和具身智能为核心的AI公司。
而这篇刚刚发布的论文,是理解这场转型最好的注脚。
提前规划和拥抱这些新工具,才能在下一波技术浪潮中站稳脚跟。
