

来自麻省理工学院、麻省理工学院-IBM 计算研究实验室和 IBM 研究院的众多专家提出了ChartNet——一个面向图表理解的百万级高质量多模态数据集,旨在推动图表理解与推理能力的发展。
过去两年,多模态大模型的发展速度远超预期。从识别图片内容,到理解复杂文档,再到解析视频信息,视觉语言模型(VLM)不断突破能力边界。然而,有一种看似简单却极具挑战性的视觉对象,至今仍让许多先进模型频频「翻车」——图表(Chart)。
对于人类而言,一张柱状图、折线图或散点图往往能够快速传递趋势、对比关系和关键结论。但对于 AI 来说,图表远不只是图片。模型不仅需要识别视觉元素,还要理解坐标轴、数据点、图例和标签之间的关系,并进一步完成数值提取、趋势分析甚至因果推理。换句话说,图表理解本质上是一项跨越视觉、数值与语言三种认知能力的复杂任务,而当前的 VLM 仅能部分实现这一能力。
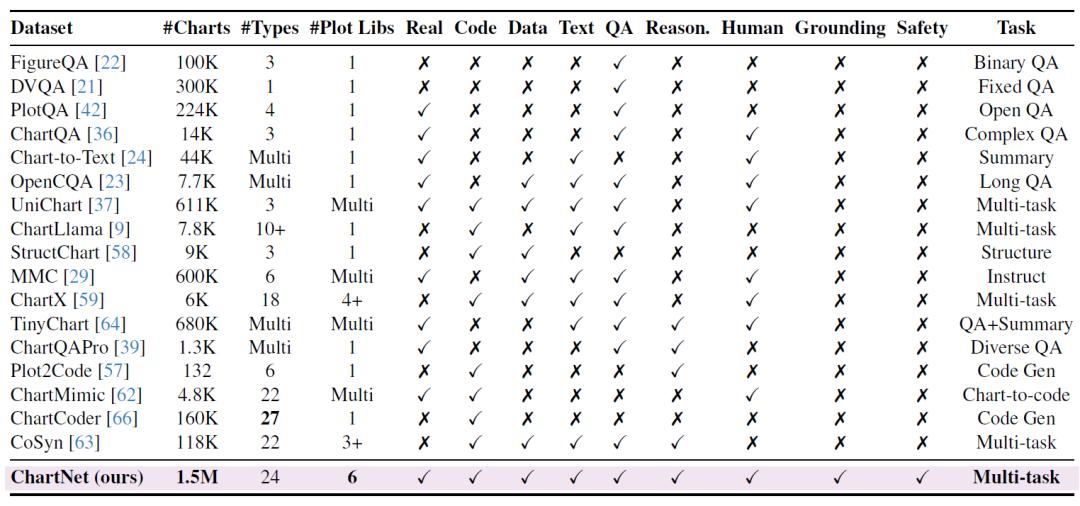
近年来,一些数据集推动了相关研究发展,但普遍存在三个问题:规模较小、图表类型有限,以及缺乏完整的多模态信息。许多数据集仅关注单一任务(如问答或图表描述),或缺乏关键模态,因此开源模型在复杂图表推理任务中仍落后于专有系统。
为弥补这一空白,来自麻省理工学院、麻省理工学院-IBM 计算研究实验室和 IBM 研究院的众多专家提出了ChartNet——一个面向图表理解的百万级高质量多模态数据集,旨在推动图表理解与推理能力的发展。
这是迄今为止最大的合成图表数据集,其采用一种新颖的代码引导式合成(code-guided synthesis)流程,生成了 150 万个多样化图表样本,涵盖 24 种图表类型和 6 种绘图库。通过全面实验验证 ChartNet 的实用性,结果显示,其最优微调模型在所有任务上均超过规模大得多的模型及 GPT-4o。
在线使用数据集:https://go.hyper.ai/lGPsc
相关研究成果以「ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding」为题,将在 IEEE 计算机视觉与模式识别会议上发表。
研究亮点:
* ChartNet 基于代码引导的合成生成流程,能够大规模生成图表样本,同时捕捉图表理解的视觉、结构、数值和文本方面信息。
* ChartNet 整合了真实世界数据和人工标注数据,并提供支持视觉指向和安全分析的专门子集,拓展了数据集在模型训练和评估中的应用价值。
* 在该数据集上微调能够持续提升视觉-语言模型在图表重建、数据提取和图表总结任务中的表现。

论文地址:
数据集:150 万条多模态对齐的合成样本组成
ChartNet 核心数据集由 150 万条多模态对齐的合成样本组成,每条样本包括:图表图像、绘图代码、表格数据、自然语言描述,以及带有链式推理(CoT)的问答对。有关数据属性、图表类型和使用的绘图库的完整概览见下图:
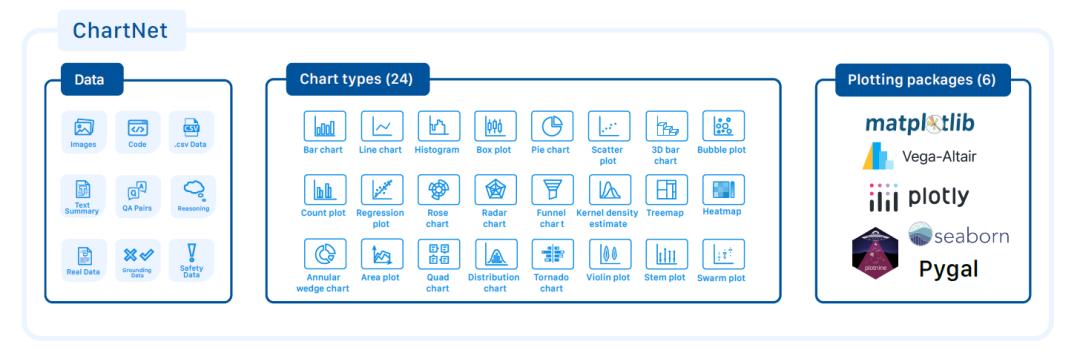
ChartNet数据集包含的数据属性、图表类型及绘图库
为了覆盖图表理解的完整能力谱系,ChartNet 还包含多个专门子集:人工标注数据、真实世界图表、grounding 数据和安全性数据。
人工标注的合成图表数据:包含 96,643 条对齐的合成图表图像、描述和表格数据,所有样本都经过严格的人类验证和标注。
高质量真实世界图表数据:为了补充合成图表语料,研究人员整理并标注了 30,000 条真实世界图表,来源于国际权威媒体和数据可视化机构,如世界银行、贝恩洞察、皮尤研究中心、Our World in Data 以及其他全球知名出版商。该集合覆盖广泛的当代主题,包括经济、科技、地缘政治、环境科学及社会趋势,同时确保数据高度多样并具强现实相关性。显式剔除信息量低或质量不达标的图表,以保证可解释性。
Grounding QA 对数据:现代 VLM 仍难以识别与特定问题相关的图表区域和语法元素,为提升该能力,研究人员构建了 grounding QA 对——首先,从绘图代码元素(坐标轴、刻度、网格线、图例、图形块)中提取几何感知标注,生成密集的图表 grounding 标注。使用基于熵的方法进一步筛选边界框;利用生成的 grounding 标注,为每张图表创建一组模板化问答,捕捉视觉元素的预期空间布局与图中实际内容的对应关系。
预期位置通过序列化的边界框表示编码到答案字符串中。模板涵盖独特和重复出现的视觉元素,结合索引、图表内文本标签和视觉属性(如元素颜色)生成引用表达。生成器支持短答和长答,并可选择性包含 grounding 信息。最终数据集通过对所有模板类型和输出模态进行均匀采样,每张图表生成一个 QA 对。此外,还使用 gpt-oss-120b 生成基于推理的 grounding QA 对。
安全性数据:为应对安全问题,研究人员扩展了数据生成流程,生成图表相关安全对齐数据,以减少模型输出的有害内容和「越狱」风险。
ChartNet 核心思想:代码引导合成图表自动生成
ChartNet 数据生成的核心思想是:图表可通过程序化方式生成,其中可执行绘图代码作为数据可视化的结构化中间表示。研究人员提出了一种大规模的代码引导合成图表自动生成流程(见下图),该流程以有限的图表图像数据(「种子」)为起点,使用视觉-语言模型(VLM)输出大致可重构这些图表的代码。
代码引导的图表增强(Code-Guided Chart Augmentation)流程
具体来说,数据生成流程包括以下几个阶段:
①图表到代码重建(Chart-to-Code Reconstruction):使用 VLM 生成 Python 绘图代码,以大致重建给定的一组图表图像。在此阶段,从 TinyChart 数据集选择了 150000 个独特的图表图像作为种子,但该流程对种子选择没有特定依赖性。
②代码引导的图表增强(Code-Guided Chart Augmentation):以生成的绘图代码为输入,使用大型语言模型(LLM)迭代重写代码。在保持与前一迭代相关性的前提下,修改底层数据值和标签以更好地匹配所需图表类型。下图展示了迭代代码增强与图表渲染的过程,该阶段是数据集规模扩展的主要环节,每个种子图像可以生成任意数量的变体。
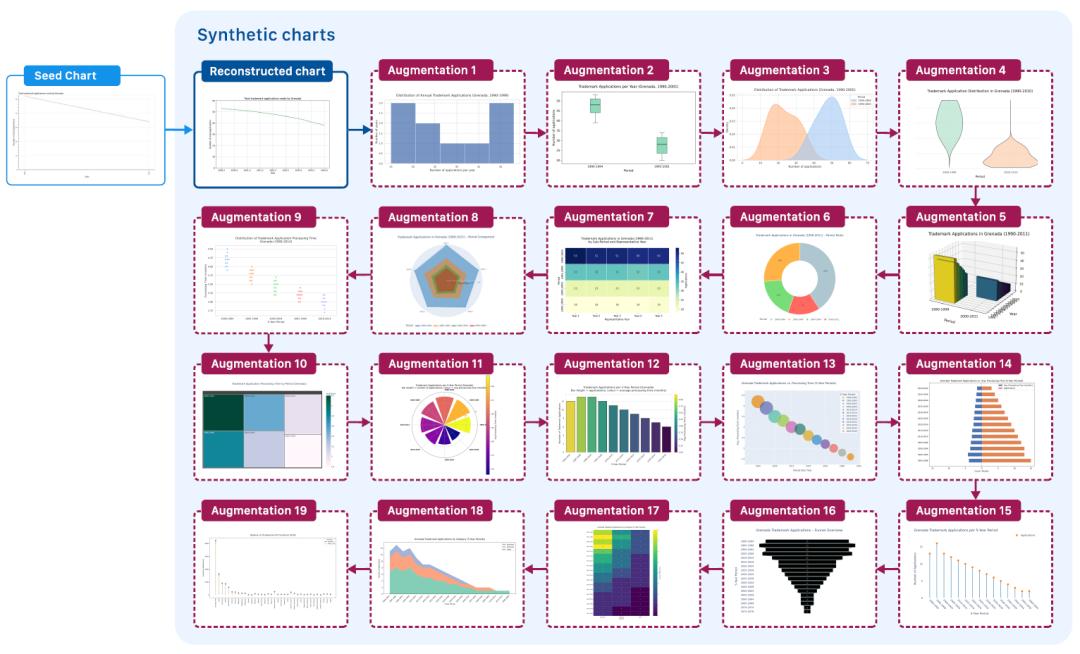
使用ChartNet流程从单一种子图生成的合成图表示例
③图表渲染(Chart Rendering):执行所有生成的绘图代码以生成图表图像,执行成功的脚本将与其生成的图像进行配对。
④质量筛选(Quality Filtering):使用 VLM 对每张图表图像进行评估,检测多种潜在渲染缺陷类别(如文本重叠、标签裁剪、图表元素遮挡等),识别出存在视觉问题的图像及其绘图代码将被移除。
⑤代码引导的属性生成(Code-Guided Attribute Generation):最后,使用 VLM 为图表图像-代码对生成补充的语义属性。在以代码作为上下文的条件下,从图表中提取数据值和标签,并生成表格数据表示。此外,结合视觉信息、代码和表格数据,生成具有 grounding 的图表描述。
可在所有图表理解任务中带来显著且一致的提升
为了验证 ChartNet 在提升模型图表理解能力方面的有效性,研究人员使用不同规模的视觉语言模型在 ChartNet 数据集上进行训练,包括超紧凑型(Ultra-Compact,≤1B 参数)、小型模型(Small,≤4B 参数)、中型模型(Medium,≤7B 参数)。
整体来看,在 ChartNet 数据集上进行微调可在所有图表理解任务中带来显著且一致的提升(见下表)——这种提升的均匀性和幅度与模型规模无关,表明现有 VLM 缺乏高质量多模态图表监督的训练机会,而 ChartNet 有效填补了这一空白。
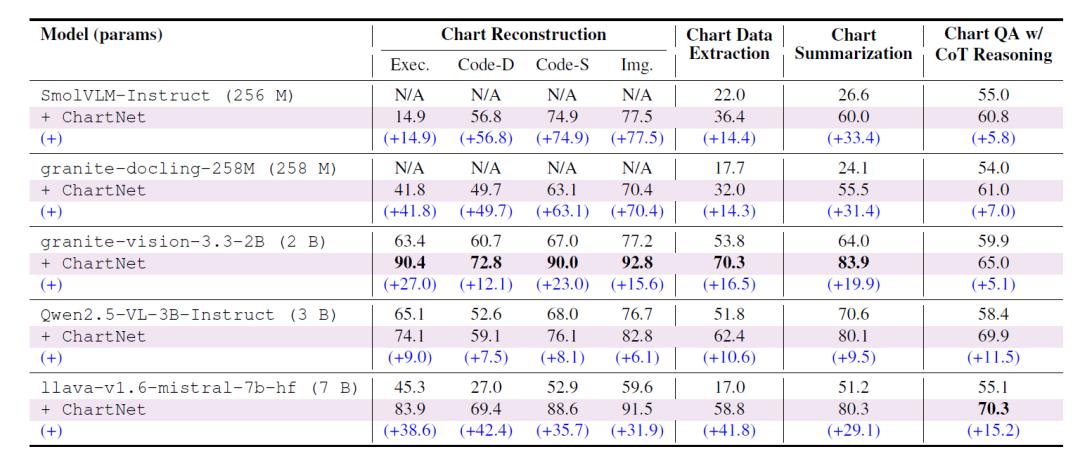
基础模型与微调模型在ChartNet评估集上的对比(性能提升以蓝色标注¹)
①图表重建(Chart Reconstruction)
在 Chart-to-Code 子集上训练的模型在代码执行率、数据一致性、结构/代码相似度以及图像相似度上均取得大幅提升: 原本完全无法重建图表的超紧凑模型(SmolVLM-256M、Granite-Docling-258M)现在获得了完整功能;小型模型(如 Granite-Vision-2B)几乎达到了完美重建,多项指标均超过 90%;LLaVA-7B 模型在数据一致性指标上提升最高可达 +42.4 分。 这一规模无关的趋势表明,ChartNet 的图像与代码间多模态对齐为模型提供了先前数据集中缺失的结构化监督。
②图表数据提取(Chart Data Extraction)
ChartNet 显著提升了所有模型直接从图表恢复数值表格的能力,其中表现最佳的 Granite-Vision-2B 达到 70.3%; 微调后的 LLaVA-7B 性能提升 +41.8 分,超过所有开源基线,甚至超过 GPT-4o(仅 46.7%)。 这体现了 ChartNet 在代码生成图表与 CSV 数据间紧密耦合的价值,让模型同时接触到视觉几何与底层数值结构。
③图表摘要生成(Chart Summarization)
所有模型族的摘要质量均提升明显,增幅从 +9.5(Qwen2.5-VL-3B)到 +31.4(Granite-Docling-2B)不等,微调后的 Granite-Vision-2B 达到 83.9%,超越 GPT-4o 以及表 3 中所有开源基线,包括那些参数规模大一数量级的模型。这说明 ChartNet 的合成摘要(由代码与渲染图表共同构建)为描述性图表理解提供了结构化、语义完整的监督信号。
④带链式推理的图表问答(QA with CoT Reasoning)
在复杂多阶段推理任务中,每个模型都表现出稳定的准确率提升——LLaVA-7B 提升最大(+15.17),达到 70.3%,超越专门的图表推理模型 ChartGemma 及所有可比或大一数量级的开源模型(包括 GPT-4o)。
⑤与现成模型对比(Comparison with Off-the-Shelf Models)
下表显示,经过 ChartNet 微调的模型在几乎所有指标上均优于参数更大的现成模型,2B 或 7B 参数模型经过微调后,其表现始终超过 20B–72B 规模的模型;尤其在图表重建和数据提取任务中,ChartNet 微调模型远超 GPT-4o。
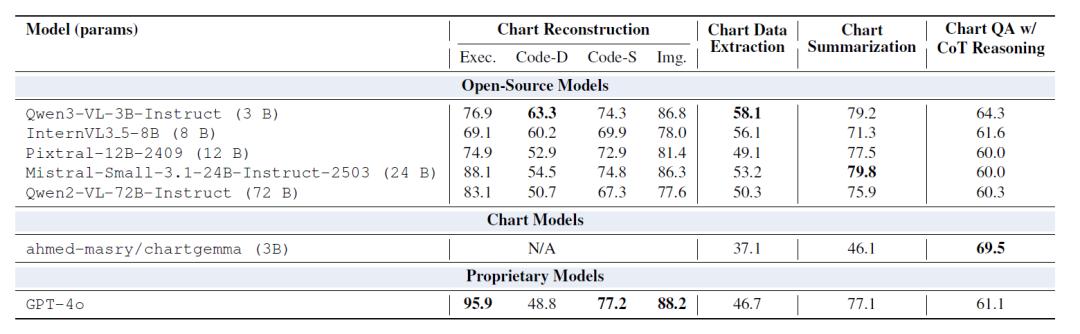
现成模型在 ChartNet 评估集上的性能表现
这表明,对于图表理解等视觉、数值和语言紧密耦合的领域,提供高质量、代码对齐的多模态监督比单纯增加模型规模更有效。
⑥对公共基准的泛化(Generalization to Public Benchmarks)
如下表所示,在核心 ChartNet 数据集微调后,所有模型在公开基准上均获得显著提升:Granite-Vision-2B 在 ChartCap 上从 1.6 提升至 12.4 BLEU,在 ChartMimic-v2 上从 30.8 提升至 58.4;即便是超紧凑模型(SmolVLM-256M)也获得了不容忽视的能力提升。这种提升在图表摘要生成和图表到代码生成任务上均一致,说明 ChartNet 的多模态对齐监督可有效迁移到真实世界基准,不仅限于合成训练分布。
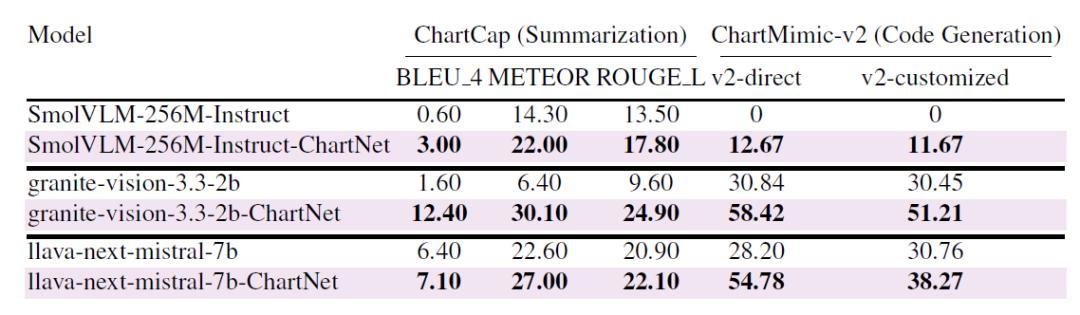
ChartNet 合成数据在两个真实公开基准上的增益泛化能力
结语
ChartNet 旨在解决图表理解领域的核心瓶颈:缺乏大规模、高保真、图像、绘图代码、数值数据、文本描述及推理轨迹对齐的监督信号。它为数值推理、可视化理解、文档智能及代码对齐多模态建模研究提供了可扩展、开放的基础平台,将 VLM 从「描述图表」推动到「理解图表编码的结构化信息」。
麻省理工学院电子工程与计算机科学系 (EECS) 研究生、ChartNet 相关论文的第一作者 Jovana Kondic 表示:「以往的很多训练数据集只关注回答关于图表的简单问题。我们试图通过ChartNet超越这一点,生成能够支持对图表进行全面深入理解的数据。」
未来,研究人员计划通过纳入更复杂程度的数据来继续扩展 ChartNet,从而为更多行业创造实际价值。
参考文献:https://arxiv.org/abs/2603.27064https://news.mit.edu/2026/mit-researchers-teach-ai-models-to-interpret-charts-0603
