

“用了一天,有点失望。”
Claude Fable 5 发布后的第一批反馈里,这句话很能代表一种情绪:它当然更强,也当然更贵,但我们更期待的是那种让人拍桌子的 aha moment。一个已经被反复抬高预期的开发者,很容易在新模型面前产生这种落差:就这?而且这么贵?
但这种失望,可能也恰好说明了现在 Fable 5 的杀手锏场景,或许不是日常写代码。
1 榜单背书:发布一天,Fable 5 登顶
Anthropic 遮遮掩掩两个月的“神话” Mythos,终于在 6 月 10 日发布了。这一次,它把自家有史以来最强悍的大模型旗舰拆成了两个版本:Claude Fable 5 与 Claude Mythos 5。
按照 Claude 官方的说法,Fable 5 是一个“Mythos-class model”,也就是 Mythos 级别模型,但已经被处理到足够安全,可以面向普通用户开放。官方还强调,这是 Anthropic 迄今为止向公众开放过的最强模型,能力超过此前任何一个面向大众可用的 Claude 模型。
Claude 官方还补充说:“在几乎所有测试基准上都达到了 SOTA,尤其在软件工程、知识工作、科学研究和视觉方面表现突出。任务越长越复杂,Fable 5 领先其他模型的幅度就越大。”
翻译成人话就是:这代模型不是用来聊天的,是用来干长活、干重活的。
昨天发布,今天就有第三方榜单跟进,Fable 5 很快拿到了它该有的排面。

Arena.ai 最新的榜单中,Fable 5 一举登顶。
这份榜单把模型的智能体表现拆成五个维度来看。Fable 5 最突出的地方,恰恰落在其中两个最接近真实使用体验的指标上:一个是“用户确认任务完成率”,达到 18.2%;另一个是“好评与投诉比”,达到 30.6%。
用 Arena.ai 的话说,Fable 5 在这两项指标上“以前所未有的优势领先于 Opus-4.8 和 GPT-5.5。”
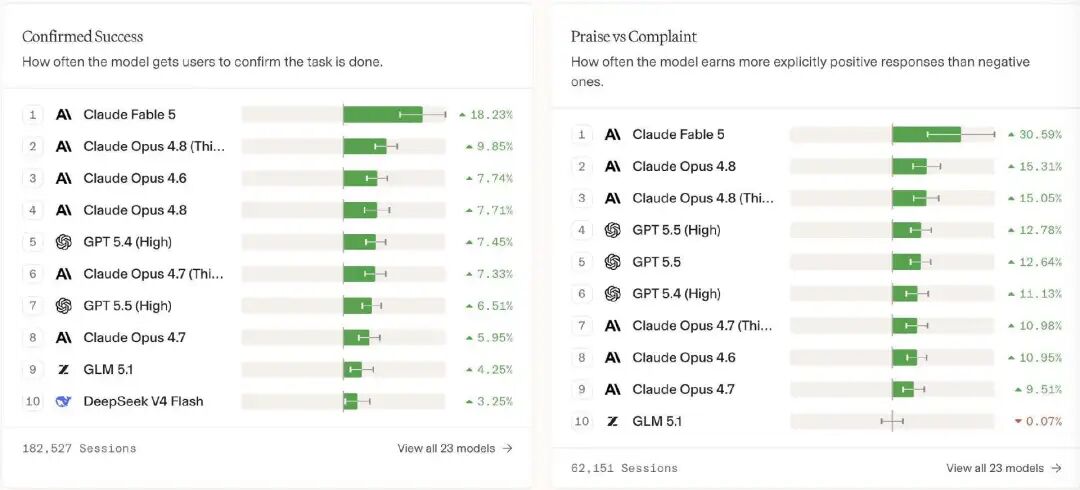
这两个指标比单纯的跑分更值得注意,因为衡量的是在真实任务中,模型到底能不能把活干完,以及用户是否认可它交付出来的结果。
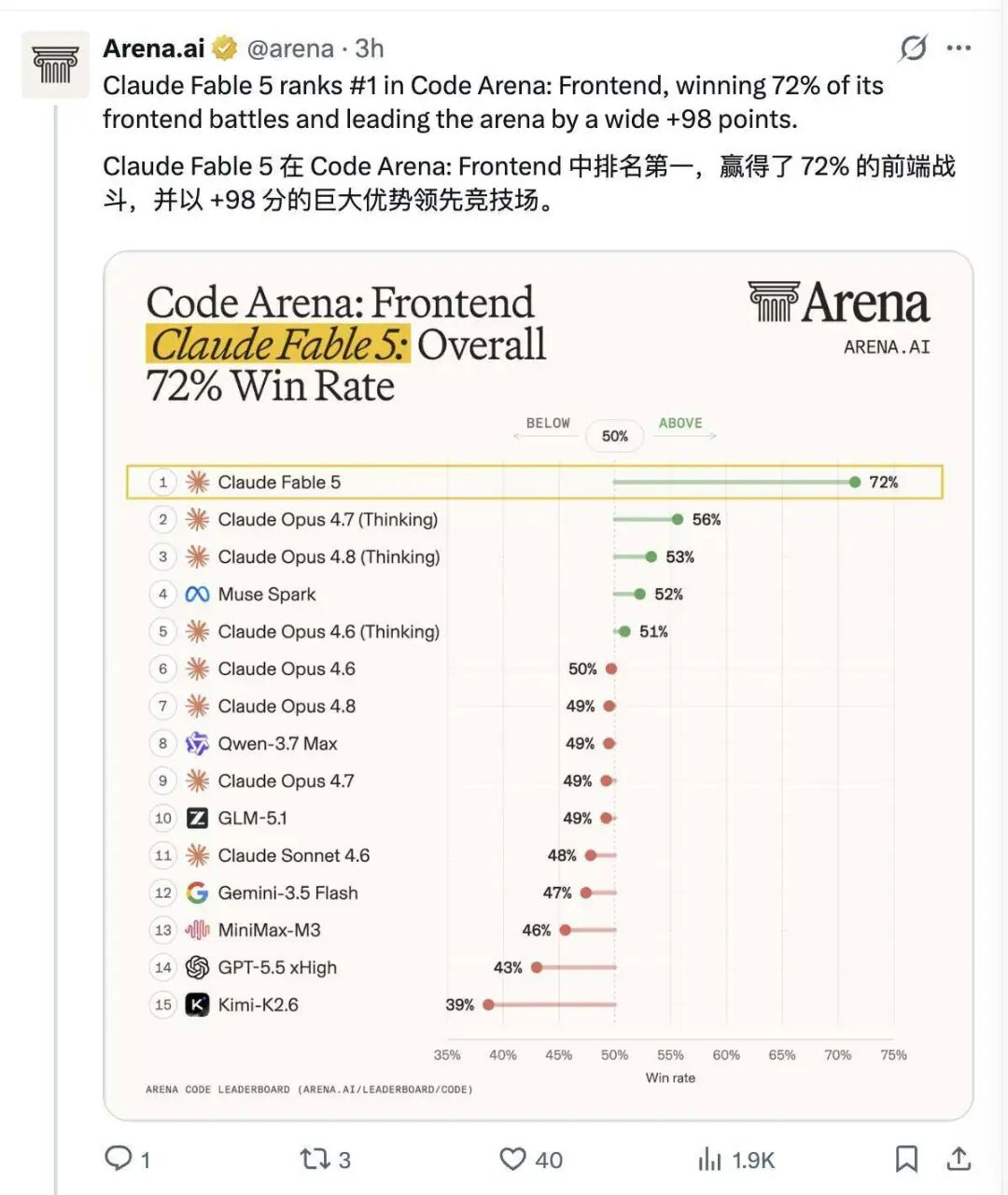
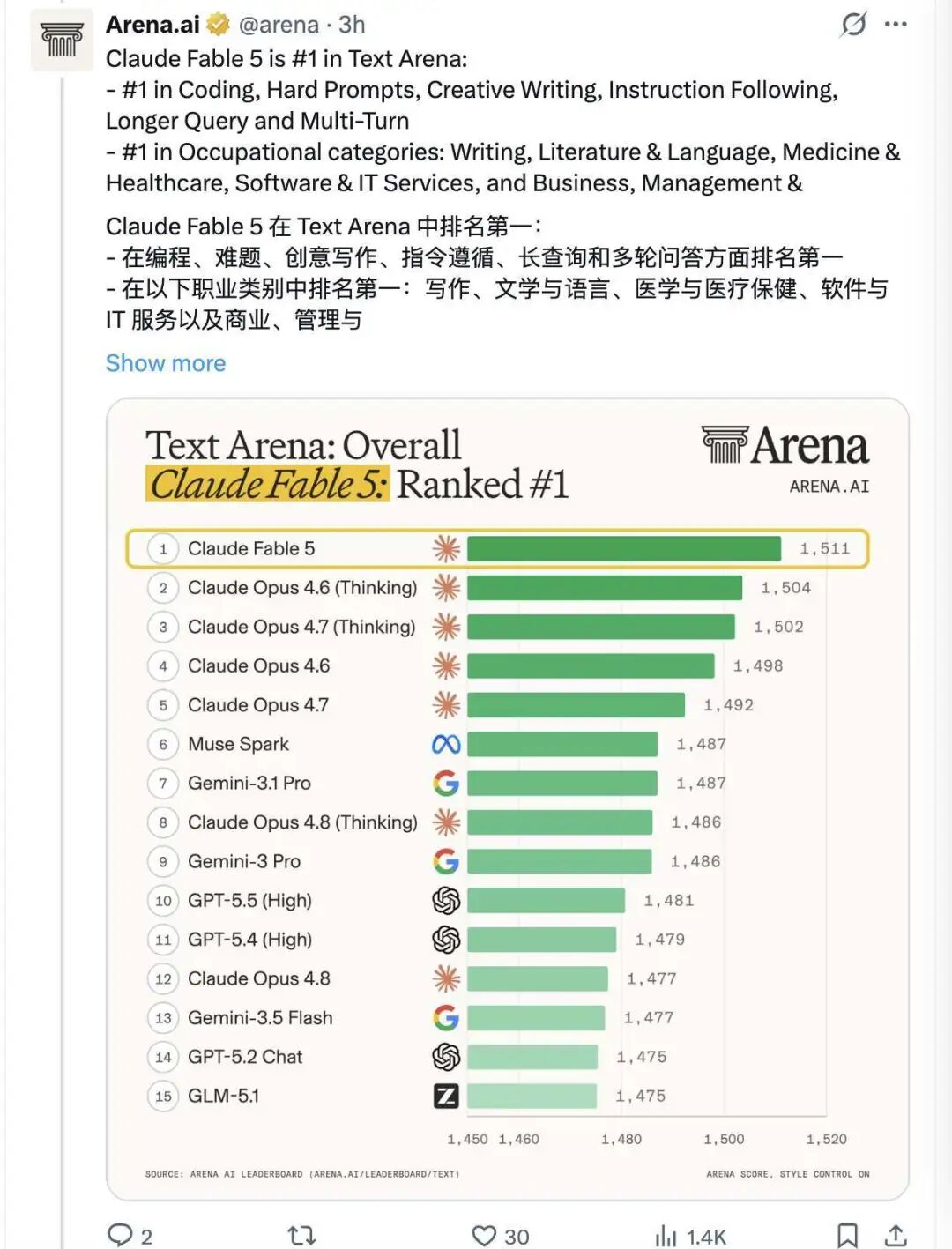
再看单项能力,Fable 5 也登上了 Code Arena 和 Text Arena 两个榜单第一。尤其是在编码相关评测中,它在前端对决中取得了 72% 的胜率,并最终拉开了 98 分的分差。
但榜单归榜单,真实使用里还有另一种声音:“用了一天,一个 aha moment 都没用出来”。如果 Fable 5 只被当作一个日常写代码的助手,它很可能永远不会让人觉得值回票价。既然如此,最该看的就不是跑分,而是有没有真正让人觉得值的案例。
2 一个更苛刻的场景出现了
有人直接把一个拖了几个月都不想碰的重构任务扔给了 Fable 5,要求它一次性搞定。更狠的是,这个仓库连测试都没有。对方只留下一句话:“这才是真正的测评。”
这种极端场景指向的,显然不是日常写代码,而是软件工程里那些真正的硬骨头:长期拖延的重构、没人敢轻易动的旧仓库、缺少测试保护的遗留系统,以及一旦改错就可能牵出一串问题的复杂依赖。
虽然有不满意的地方,但他的评价是“比任何模型更接近目标”。
官方给出的第一个典型案例,也是这个路数:Stripe 在一个 5000 万行 Ruby 代码库中完成全库迁移。这个工作如果让工程团队手动推进,原本要两个多月,而 Fable 5 只用了一天。
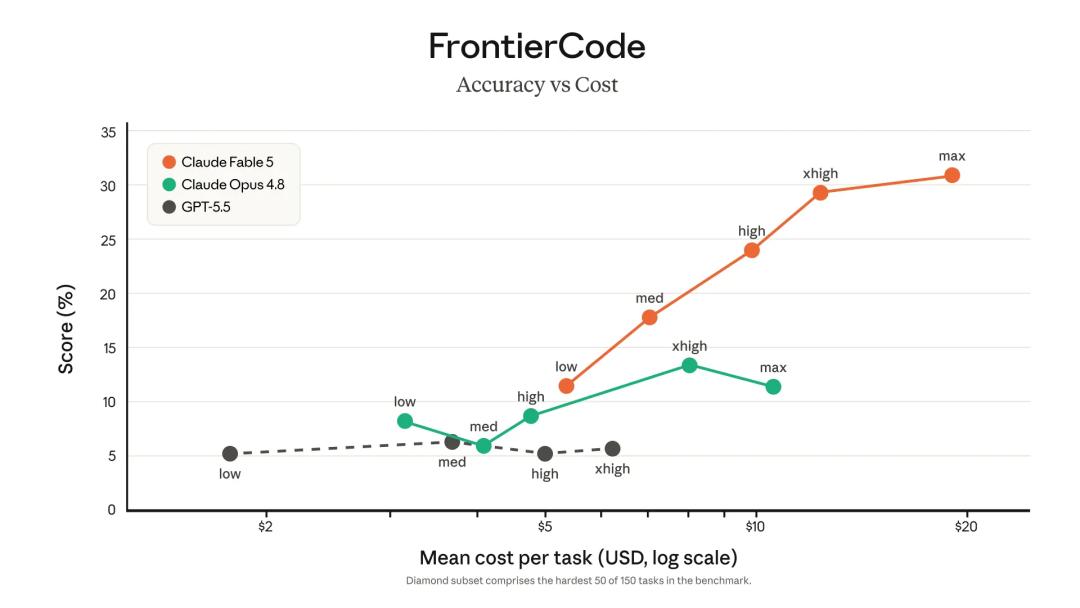
Anthropic 还在官方介绍中声称 Fable 5 的 token 使用效率也高于以往的 Claude 模型:在 Cognition 的 FrontierCode 评测中,Fable 5 即便只以中等推理强度运行,也在前沿模型中取得了最高分。FrontierCode 用来测试模型能否完成高难度编码任务,同时达到高质量生产级代码库的标准。
另一个案例来自一位偏后端的开发者。
他提到,像他这样更偏后端的人,最近不得不认真学习什么才是好的前端代码。原因是前端更容易被 vibe code,因为效果直接可见,界面能跑起来,代码质量却可能更快滑坡,回归问题也更容易进入结构不好的代码库。React 看起来容易上手,但真正写好它,需要很深的心智模型。
这一次,他把 Fable 5 用在了团队里最老、最乱的一段 React 代码上,做了一次 +5000/-5000 级别的重构,理顺了很多纠缠在一起的东西。
他的目标很简单:把代码清理干净,然后看在更少引导的情况下,Fable 5 自己会怎么做。
一开始,他让 Fable 5 重构 $sessionId 页面和根组件,直到它足够干净,并且控制在 500 行以内。随后,他又让它重构 $taskId 页面和根组件,同样要求干净,并控制在 500 行以内。
接下来,他连续用了几次非常短的提示词:“make it cleaner”,也就是“让它更干净”。
也就是说,他不是一开始就给出完整重构规范,而是先用“clean”“cleaner”这种模糊目标,观察 Fable 5 的默认取向。
整个过程持续了大约两个小时。他一边浏览 diff,一边每隔大约 20 分钟排入更多消息,直到最后,队列里一直保持大约 5 到 7 条指令。
在这个过程中,Fable 5 确实理顺了不少东西。他的总体评价是满意,“总体来说,我非常满意,之后还会继续这样用,也会把它用到技术栈的更多部分。”
而且从目前结果看,这个 diff 似乎没有引入回归问题,但他还在结合手动测试和浏览器自动化继续验证。
不过,他也提到,Fable 5 做出的决定里,他大概认可 80%。另一些决定让代码变得更复杂。
比如,Fable 5 引入了 React Context,隐藏了复杂性,但让程序更难推理。它还做了一些看起来聪明的处理,比如用展开语法减少总行数,但并没有真正减少或简化底层数据结构。
后面,他开始给出更明确的方向,例如移除不必要的 useEffect、减少 prop drilling,以及调整状态管理方式。随着重构推进,他不断根据 diff 补充新的要求,让 Fable 5 朝着自己认可的代码结构继续演化。最后,他还让 Fable 5 生成了一份可视化的重构说明,用层级结构展示整个改造过程,方便后续阅读和审查。
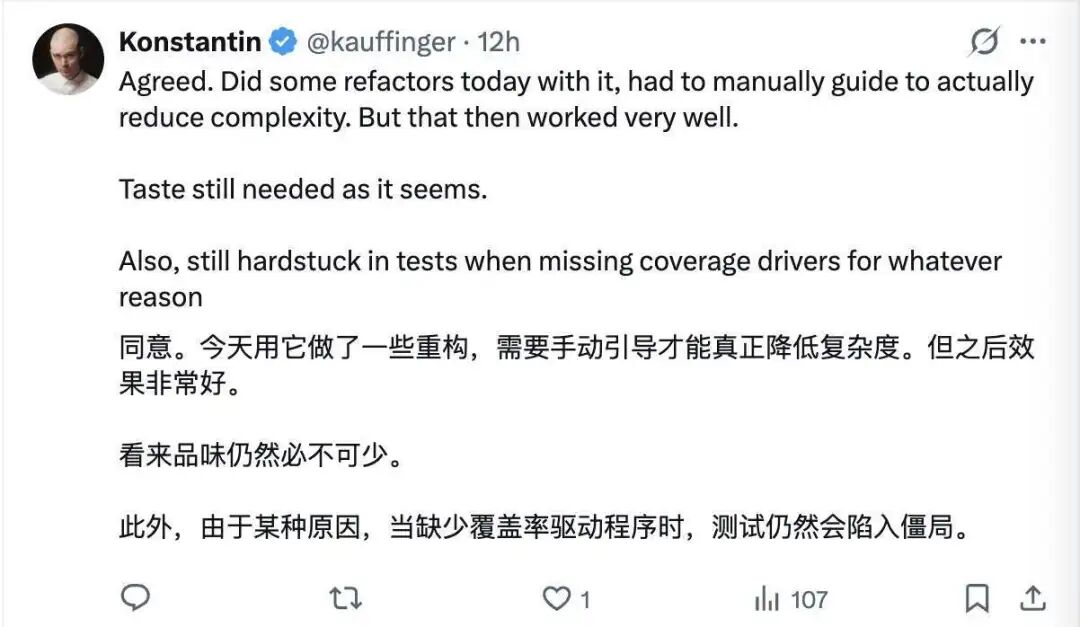
有开发者对此评论说:“同意。今天我用它做了一些重构,虽然过程中需要手动引导,但最终效果非常好。”
从零开始的能力
除了重构,也有人把 Fable 5 拿来测试从零生成应用的能力。
一位开发者说,他衡量新模型的一个标准,是看它能多准确地复刻自己日常使用的应用和软件。于是,在过去大约 20 个小时里,他不断给 Fable 5 扔提示词,想看看它从零开始到底能做到什么程度。
结果是,Fable 5 做出了 Figma、Screen Studio、Obsidian 和 Notion 的高完成度克隆版本,视觉上几乎可以做到逐像素接近。他的感受是,这次能力提升带来的跃迁感,类似于 Opus 4.5 相比更早模型的那一跳。
更有意思的是,这些 demo 并不依赖复杂的提示工程。提示词可以很基础,但信息量很大,把需求、风格、目标以及各种细节一次性塞进去,然后看 Fable 5 如何拆解、规划并执行。有人问他,做这些测试任务时,是不是有一套更复杂的 setup,还是简单说一句“clone Notion”。他的回答是,提示词基础到有点不好意思,但确实有效。
比如他让 Fable 5 做 Notion 克隆时,提示大意是:构建一个 Notion 的克隆版,不要问我任何问题,尽你所能把它做得尽可能好,并且在每个维度上都尽量接近 Notion,尤其是设计。
这个 Notion demo 大约 30 分钟一次生成完成,用的是 Fable 加 Devin。
https://x.com/dabit3/status/2064732712389227005
这类案例也指向了“个人软件”的趋势:无论是做一个熟悉工具的轻量替代品,还是改造现有工作流,门槛都在快速降低。他认为,很难再说个人软件时代还没有到来,而且接下来只会变得更容易、更快、更好、更便宜。
3 贵,也是真的贵
如果说前面的案例证明了 Fable 5 的能力,那么另一边,早期用户最集中的抱怨也很明确:它确实更强,但也确实更贵、更容易烧穿额度。
Fable 5 现在面向 Claude Pro、Max、Team 以及按席位计费的企业订阅用户开放,也可以通过 API、Microsoft Foundry、Amazon Bedrock 和 AWS 上的 Claude Platform 使用。按照 Anthropic 的定价,Fable 5 的 API 价格是每百万输入 token 10 美元、每百万输出 token 50 美元。
更麻烦的是,当前这套使用方式并不会一直持续。6 月 22 日之后,用户访问 Fable 5 需要消耗 usage credits。Anthropic 给出的解释是容量限制。换句话说,这不是一个可以随便拿来狂跑的模型,至少在当前阶段,它的成本和额度都会很快变成体验的一部分。
社区里的早期反馈也基本围绕这个矛盾展开:它更好,但烧得太快。
有人在 Hacker News 上说,Fable 5 在 high 档位下的结果,明显好过 Opus 4.8 的 xhigh 档位。他的体感是,Fable 5 更聪明,虽然更贵,但效率也更高,还能找到一些 Opus 没发现的 bug。Reddit 上也有人表达了类似看法,认为 Opus 4.7 和 4.8 里一些负面特征,在 Fable 5 上要么消失了,要么被控制住了。
真正让用户不爽的,是它的消耗速度。
在社区论坛里,一个正在形成的共识是:Fable 5 的可用窗口可能非常短。即便是被它能力惊艳到的用户,也承认它烧额度的速度很快。有 Max20 计划用户说,自己看着使用量几乎以每分钟 2% 的速度上涨;作为对比,同样类型的工作,他过去用 Opus 4.8 从来没有接近过额度上限。
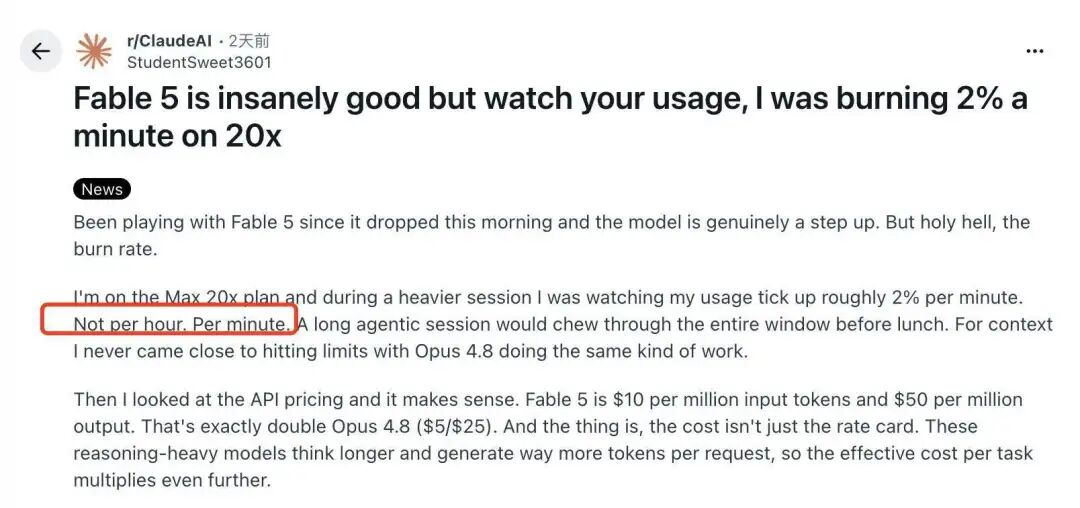
类似反馈还有不少。有人说,几分钟内,自己的 5x Max 账号从 0% 直接涨到 43%;也有人说,45 分钟就烧完了整个 20x Max 计划;还有人说,第一次测试 prompt 的五小时会话,就消耗掉了每周 Max 额度的 20%。
这也回到了开头那种“没有 aha moment”的落差:如果把 Fable 5 当成一个日常 coding assistant,它可能很难让所有人立刻觉得惊艳;但如果把它放进长程任务、复杂重构、代码迁移和个人软件生成这些场景里,很多反馈就能解释得通。
Fable 5 越强,越不该被拿去做低价值的小修小补。它真正适合的,是那些值得花钱、值得烧额度,也值得让模型长时间跑下去的问题。
参考链接:
https://x.com/roerohan/status/2064795304306901399
https://x.com/dexhorthy/status/2064747631885398231
https://www.reddit.com/r/ClaudeAI/comments/1u1cvkc/fable_5_is_insanely_good_but_watch_your_usage_i/
