

【导读】大模型靠预测下一个词读懂语言,世界模型靠预测下一帧读懂世界。最近,一家中国公司刚过港交所聆讯,物理AI的「GPT时刻」要来了。
物理AI过临界点了!
6月1日,NVIDIA开源Cosmos 3。
6月13日,Tesla推送FSD V14.3.4。
6月18日,一家估值超千亿的中国公司通过了港交所聆讯。中国跑城区领航辅助驾驶的车,65%用的是它的方案。量产车超90万辆,全球前十大车企九家是客户。
大语言模型靠预测下一个词理解了语言,由此开启了数字AI的万亿美元市场。
这家公司也在用世界模型做着同样的事:靠预测下一帧理解世界,重写自动驾驶的底座。只不过这一次,AI要理解的不是语言,是整个物理世界。
自动驾驶的世界模型时刻
过去十年,自动驾驶的主流做法叫模仿学习:录人类老司机怎么开车,让AI照着学。数据越多,学得越好。
但模仿学习有天花板,而且天花板很低——就是人类本身。
它只能学到「做了什么」,学不到「为什么这么做」。
人在路口减速,不是执行了一条规则,是对物理世界有直觉。两吨重的铁在湿路面上刹不住意味着什么,低头看手机的行人下一步往哪走。
模仿学习学的是动作,不是因果。
但AI有个规律,一旦接近人类水平,就会在很短时间内大幅超越。AlphaGo如此,人脸识别如此。前提是,方法得对。
自动驾驶的方法,就是世界模型。

2026年,世界模型突然成了全球AI最热的赛道。
- 杨立昆离开Meta创办AMI Labs,3月拿下10.3亿美元种子轮押注JEPA架构,公开喊话「大语言模型是死胡同」。
- 李飞飞的World Labs 2月融资10亿美元,估值50亿,NVIDIA和AMD都投了。
- 谷歌在I/O大会上发布Gemini Omni,第一次把世界模型做进了Gemini体系。
路线不同,共识一致:大语言模型不够了,AI必须理解物理世界。

往大了说,世界模型在物理AI里的位置,相当于大语言模型在数字AI里的位置。一个靠预测下一个词压缩语言常识,一个靠预测下一帧压缩物理规律。
数字AI的底座已经催生了万亿美元市场,物理AI的底座刚刚开始。而自动驾驶是这个基座最先落地的场景。
但研究是一回事,量产是另一回事。
杨立昆自己说AMI Labs可能需要五年才出产品。李飞飞的World Labs刚发布首款商用产品Marble,切入3D世界生成.
Tesla的FSD V14在端到端上走得最快,但它是封闭系统,只服务自家车型,技术不向行业开放。
开放阵营里,粗略分两层:底层是NVIDIA这样的训练基础设施,上层是量产级的车端部署方案。
真正把世界模型做到量产上车的公司中,就有这样一家中国公司Momenta。
今年4月,他们正式交付了最新的R7世界模型。

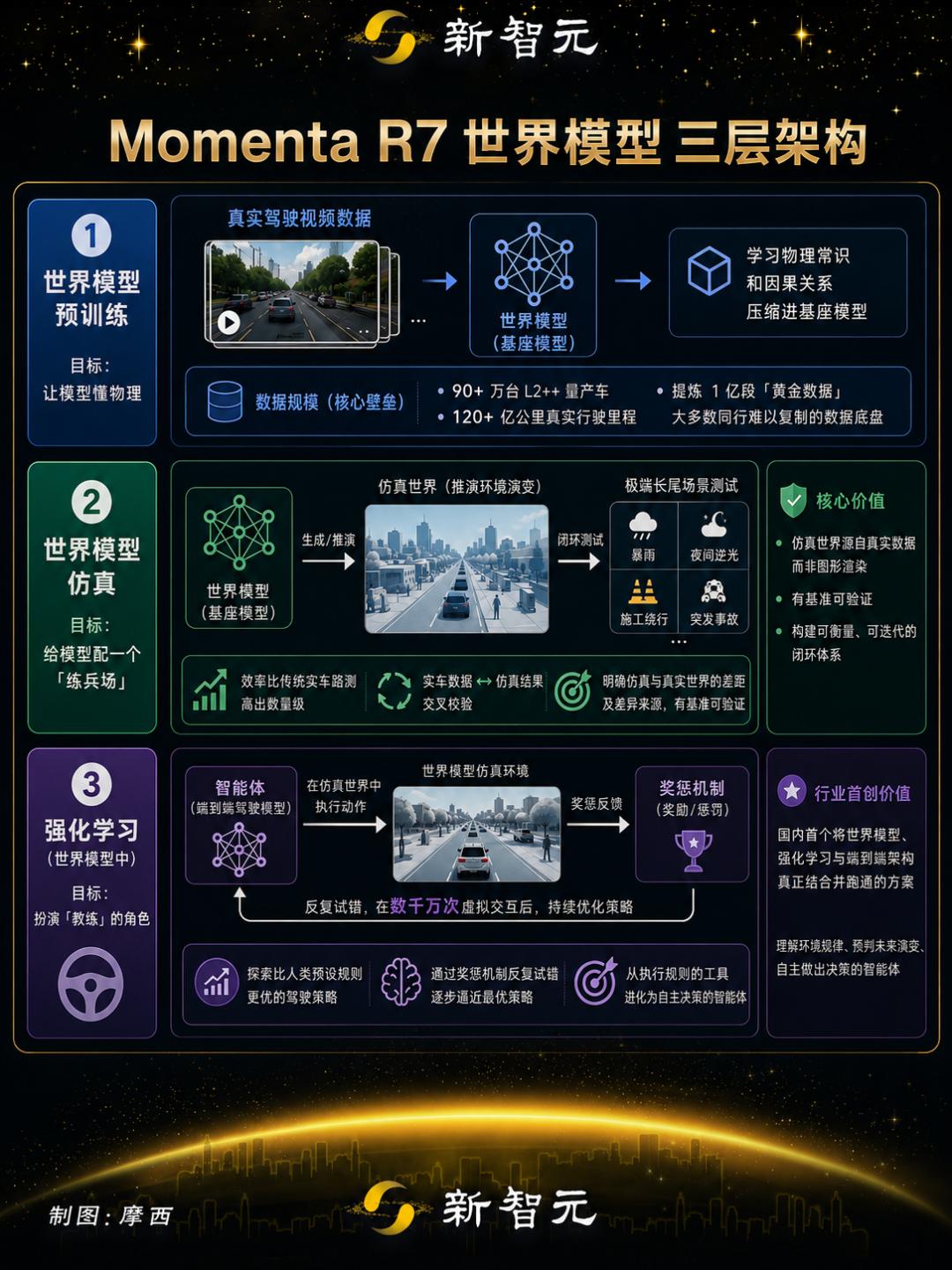
具体来说,R7的架构可以分为三层:
第一层,预训练。
乘用车量产车队积累的90万辆、超100亿公里实车里程,提炼1亿段黄金数据,学物理世界的底层规律。物体有质量有惯性,前车急刹后车追尾,行人加速闯入车道。
第二层,仿真。
真实道路上极端场景太稀疏,十万公里才遇一次鬼探头。
世界模型理解物理规律之后能自己「想象」——用真实数据生成虚拟世界,拿实车和仿真的一致性做校准,直接缩小仿真与真实之间的差距。效率比实车路测高出上万倍。
第三层,强化学习。
在仿真出的极端场景里反复试错,奖惩驱动自主进化。不再模仿人的动作,而是在物理约束下找最优解。
一套模型,吃下千亿赛道
不过,如果世界模型只是「让辅助驾驶更好用」,故事到这里就讲完了。
但过去几年,自动驾驶行业学到了一个残酷的教训:单一场景烧不出未来。
Argo AI被福特和大众联手放弃,Cruise大幅缩减运营。纯做Robotaxi的公司,数据靠自有小车队采集,成本高、规模小、商业化遥遥无期。
行业开始意识到,能活下来的公司必须同时解决两个问题:数据从哪来,钱从哪来。
而世界模型打开了一条新路。
它学的不是某种车型的驾驶习惯,是惯性、运动、因果这些通用规律。轿车里学到的物理常识,放到卡车上成立,物流车也一样。
Momenta的All-in-One平台就建在这个逻辑上:一套底座,四个场景——乘用车L2++、Robotaxi、Robovan、Robotruck。

核心技术能复用,意味着场景越多,数据交叉越密。
乘用车的日常里程喂给Robotaxi的世界模型,Robotaxi遇到的极端场景反过来提升乘用车的安全性。
量产车队每天产生真实驾驶数据,灌进世界模型做预训练;模型进化了,再通过OTA推回车端。
更好的产品拉来更多OEM客户,更多客户带来更大的车队,更大的车队又反哺数据。
现在,Momenta已经把这个循环转了起来——不仅许可收入三年翻了42倍,甚至七家互为竞争对手的车企都同时做了它的股东。

这背后是一个正在发生的行业转向:智驾研发成本太高、迭代太快,多数OEM已经从自研转向外采,问题只剩下选谁。
据CIC灼识咨询,量产智驾加上Robotaxi、Robovan、Robotruck,2030年全球总盘子超5000亿美元。
物理世界的Anthropic?
5000亿美元的市场,飞轮一旦转起来,后来者连门都进不了。最终大概率只剩3到4家赢家。
Momenta要占哪个位置,取决于它像谁。
数字AI的格局花了三年定型。OpenAI、Anthropic、谷歌各据一方。
在这之中,Anthropic不是最早做大模型的,参数量也不是最大的。但它做对了一件事:找到编程这个价值密度最高、反馈最快的场景,All-in。
Claude Code上线不到一年,ARR突破25亿美元,Anthropic整体ARR从不到10亿飙到超300亿。站稳之后,再切金融、医疗、企业服务。
为什么是编程?因为代码有明确的对错标准,反馈循环最快,付费意愿最强。
自动驾驶在物理AI里扮演的角色几乎一样。明确的安全指标做验证标准,海量实时数据做反馈循环,OEM量产做商业闭环。
Momenta的路径几乎是Anthropic的镜像——先在自动驾驶站稳,再把能力复制到更广阔的物理世界。
技术底层:一个有Claude基座模型理解语言逻辑,一个有R7世界模型理解物理因果。
商业验证:Anthropic靠编程场景率先跑通现金流,Momenta靠量产率先跑通数据闭环。
泛化路径:Anthropic从代码切入金融、医疗、法律,Momenta从乘用车延伸到无人出租、物流、干线。
终局形态:都不是垂直供应商,是平台。
不同的是壁垒。
Anthropic是纯软件公司,Momenta的模型从第一天就长在硬件上——量产车是数据入口,OEM关系是护城河,OTA是迭代通道。软硬一体,比纯API更厚。
当然,自动驾驶的安全验证没有代码的「单元测试」那么绝对。
但正因如此,数据规模的意义更加关键:只有足够多的真实里程,才能让概率收敛。
Momenta的90万辆车,正是在做这件事。

写在最后
如今,数字AI已经卷成红海,物理AI才刚刚开场。
而物理世界,很可能是比数字世界大得多的那一半。
当世界模型成为基座,当Momenta带着R7敲响港交所的钟声,物理AI大规模量产的序幕,真正的「GPT时刻」或许不再遥远。
