

【导读】一文看懂CUDA Tile背后的算盘与野心。
英伟达的CUDA,刚刚宣布了该平台诞生20年来最重大的一次更新!

其中,最核心也是最颠覆性的更新的就是CUDA Tile,让开发者可以用Python代替C++写内核代码。
在CUDA 13.1版本中,他们引入了一种叫做CUDA Tile的技术——一种全新的显卡代码编写方式,让整个过程更省事,更具未来适应性。
旨在通过抽象化底层硬件(如Tensor Cores)细节,降低开发门槛。可以把它想象成从手动调乐团中的每件乐器,转变为单纯指挥音乐。

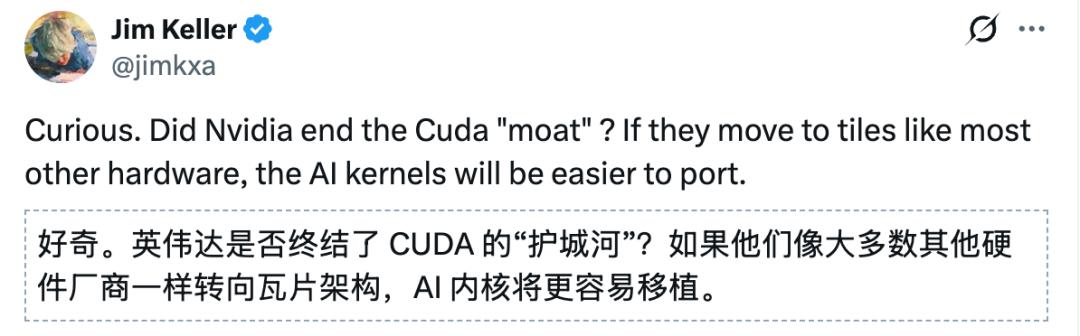
这一重磅更新迅速引来了芯片界传奇人物、Tenstorrent CEO Jim Keller的关注与质疑:
Jim Keller提出一个观点:这次更新是否终结了CUDA的「护城河」?

他的理由是当英伟达的GPU也转向Tile瓦片结构,而其他硬件厂商一样转向瓦片架构,AI内核将更容易移植。
但事实真是如此吗?
要想讨论清楚这件事,需要分析两个问题:
1. Jim Keller是谁?为什么他的话有分量
2. CUDA Tile此前是什么技术?CUDA护城河到底是什么
Jim Keller是当代芯片界最有代表性的CPU/SoC架构师之一,业内很多人直接叫他「传奇架构师」、「芯片圈GOAT之一」。
一句话,他是那种真正改写过CPU发展路线图的人。
凡是近二十多年x86、移动SoC、AI芯片的几次大级别翻身仗,背后大概率能看到Jim Keller的影子。

更细一点说:
- x86-64时代的奠基人之一:
作为x86-64指令集和HyperTransport的共同作者,他直接影响了今天几乎所有桌面、服务器CPU的ISA与互连方式。
- 多次带队完成「公司级」翻身战:
AMD Athlon/K8时代第一次让AMD在x86性能上正面硬刚Intel。Zen重新让AMD从「快死了」变成今天和Intel分庭抗礼。在Apple时期的A4/A5开启了iPhone自研SoC的路线,间接铺路到后面的M系列。
- 跨CPU、手机SoC、自动驾驶、AI加速器的「全栈」架构师:
很少有人像他一样,在 通用CPU、移动SoC、车载SoC、AI加速器 上都做过一线设计和架构决策。近几年他频繁在TSMC、三星等论坛谈未来工艺与架构,被称为「半导体设计传奇」。
所以Jim Keller的观点非常有参考性意义。
英伟达是否通过这次更新拆除了CUDA的「护城河」,还是以另一种形式将其加固?
去年,Jim Keller曾直言「CUDA是沼泽而非护城河」。
意思是CUDA的复杂性让开发者深陷其中无法脱身。

让我们简单回顾下CUDA的历史。
而此次CUDA Tile之前,早在2006年,英伟达发布了G80架构和CUDA,CUDA的出现将这些并行的计算单元抽象为通用的线程(Threads),从而开启了通用GPU计算(GPGPU)的黄金时代。
二十年来,基于「单指令多线程」(SIMT,Single Instruction,Multiple Threads)的编程模型一直是GPU计算的「圣 经」。
开发者习惯了从单个线程的视角出发,思考如何将成千上万个线程映射到数据上。
在人工智能大爆发的今天,计算的核心原子不再是单一的标量数值,而是张量(Tensor)和矩阵。
传统的SIMT模型在处理这种块状数据时,显得日益笨重且效率低下。
技术的重构,CUDA Tile与SIMT的范式断裂
要理解CUDA Tile更新了什么,首先必须理解为什么旧方式行不通了。
SIMT模型的核心假设是:程序员编写一段串行代码(Kernel),GPU硬件负责将这段代码实例化为成千上万个线程。
粗暴一点理解:
想象一个包工头(GPU的控制单元)和32个搬砖工(线程,Thread)。比如要把一张图变亮,包工头只要一个命令,每个工人负责一个像素点,大家互不干扰,动作整齐划一。
这就是SIMT的精髓:虽然人多,但听同一个指令,处理各自的小数据。
这种模型在处理图像像素或简单的科学计算时非常完美,因为每个像素的计算是独立的。
然而,现代AI计算的核心是矩阵乘法。
AI运算(深度学习)的核心不再是处理单个像素,而是矩阵乘法。
在硬件层面,英伟达引入了Tensor Core(张量核心)来加速矩阵运算。
Tensor Core不是一次处理一个数,而是一次处理一个16x16或更大的矩阵块。
为了用 SIMT 模型去开动Tensor Core,程序员不得不同时指挥多个线程。
在SIMT中,程序员仍在控制单个线程。为了使用Tensor Core,程序员必须指挥32个线程(一个Warp)协同工作,手动将数据从全局内存搬运到共享内存,再加载到寄存器,通过复杂的wmma(Warp-level Matrix Multiply Accumulate)指令进行同步。
开发者必须精细地管理线程间的同步和内存屏障。稍有不慎,就会导致死锁或数据竞争。
不同代际的GPU其Warp调度机制和Tensor Core指令集均有不同。
针对Hopper架构优化的极致性能代码,往往无法在Blackwell上直接运行,需要重新调优。
这就是Jim Keller所说的「沼泽」——代码里堆积了针对不同硬件特性的补丁,既不美观也难以维护。
这就是「SIMT力不从心」的原因:试图用管理独立个体的逻辑(SIMT),去指挥一个需要高度协同的集体动作(Tensor Core)
CUDA Tile:瓦片化计算的诞生
CUDA 13.1引入的CUDA Tile彻底抛弃了「线程」这一基本原子,转而以「瓦片」(Tile)作为编程的核心单位。
核心概念:什么是Tile?
在CUDA Tile模型中,Tile被定义为多维数组的一个分块(Subset of arrays)。
开发者不再思考「第X号线程执行什么操作」,而是思考「如何将大矩阵切分成小块(Tiles),以及对这些块进行什么数学运算(如加法、乘法)」。
瓦片模型(左)将数据分割为块,编译器将其映射到线程。SIMT模型(右)将数据同时映射到块和线程。

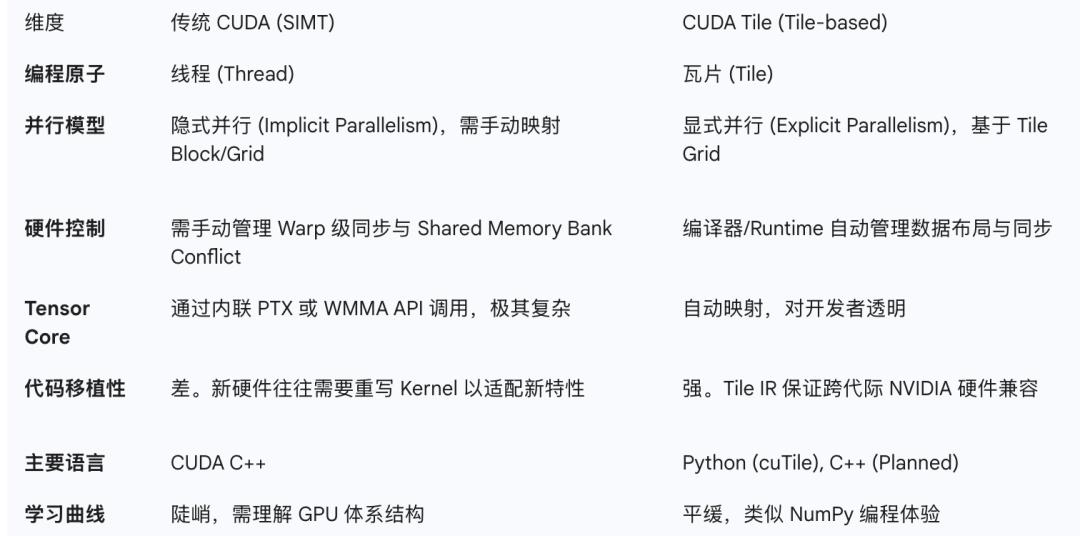
这种转变类似于从汇编语言跳转到了高级语言:
- SIMT:手动管理寄存器分配、线程掩码、内存合并。
- Tile:声明数据块形状(Layout),声明算子(Operator),编译器负责一切。
这种编程范式在Python等语言中很常见,像NumPy这样的库允许指定矩阵等数据类型,然后用简单的代码指定并执行批量操作。

在底层,正确的操作会自动执行,计算过程完全透明地继续进行。
架构支撑:CUDA Tile IR
这次更新不仅仅是语法糖,英伟达引入了一套全新的中间表示——CUDA Tile IR(Intermediate Representation)。
CUDA Tile IR引入了一套虚拟指令集,使得开发者能够以瓦片操作的形式对硬件进行原生编程。
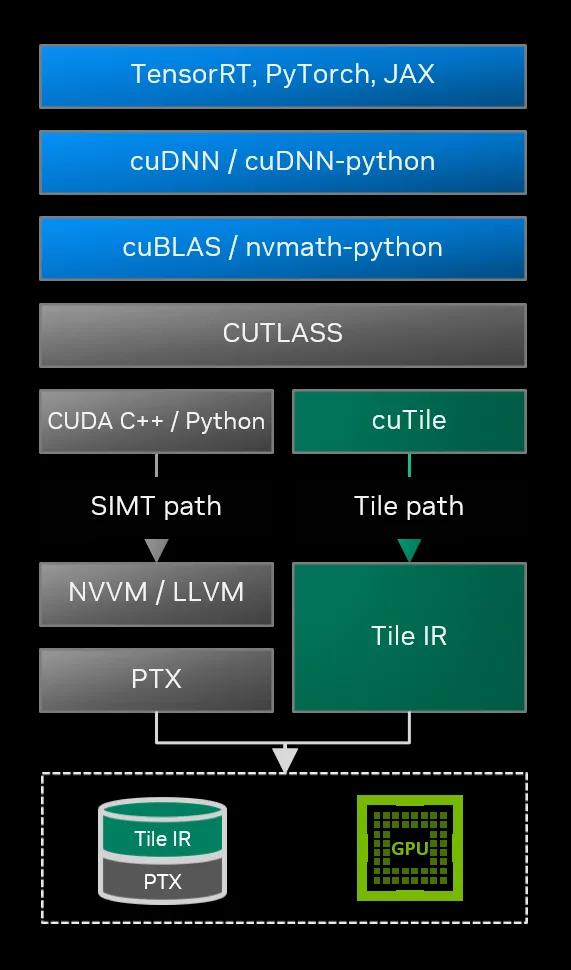
开发者可以编写更高层级的代码,这些代码只需极少改动即可在多个世代的GPU上高效执行。
通过这种对比可以看出,CUDA Tile实际上是英伟达对AI编程范式的一次「降维打击」——将复杂的硬件细节封装在编译器内部,只暴露算法逻辑。
在过去的CUDA版本中,C++始终是一等公民。
然而在CUDA 13.1中,英伟达极其罕见地首发推出了cuTile Python,而C++支持则被延后。
这一策略转变深刻反映了AI开发生态的现状:Python已经成为AI的通用语言。
在此之前,AI研究员如果想优化一个算子,不得不离开Python环境,学习复杂的C++和CUDA。
cuTile的出现旨在让开发者留在Python环境中即可编写高性能Kernel。
根据英伟达的技术博客,我们可以通过一个向量加法的例子来感受cuTile的变革。
传统SIMT方式(伪代码概念):

cuTile Python方式:

在这个例子中,开发者不需要知道GPU有多少个核心,也不需要知道Warp是什么。
ct.load和ct.store在底层可能会调用Blackwell架构最新的异步内存复制引擎,但这对开发者是透明的。
CUDA Tile对抗的是谁?
要回答「是否终结了护城河」,必须引入另一个变量:OpenAI Triton。
Triton是OpenAI为了摆脱对英伟达闭源库(如cuDNN)的依赖而开发的开源语言。
Triton的核心理念与CUDA Tile惊人的一致:基于块(Block-based)的编程。

这或许是CUDA此次更新的最大针对者。
分析了这么多,英伟达此次更新是否终结了CUDA的护城河,转向瓦片架构是否使AI内核更易移植?
在社区中,更多的声音指向如下结论。

英伟达代际间的移植性:这是CUDA Tile主要解决的问题。
从Hopper移植到Blackwell,甚至未来的Rubin,使用TileIR编写的代码将无缝运行且自动优化。
这一点上,移植性极大增强。
跨厂商的移植性:这是行业希望解决的问题(比如从英伟达移植到AMD MI300)。
这一点上,CUDA Tile几乎没有任何帮助,甚至让移植变得更难。

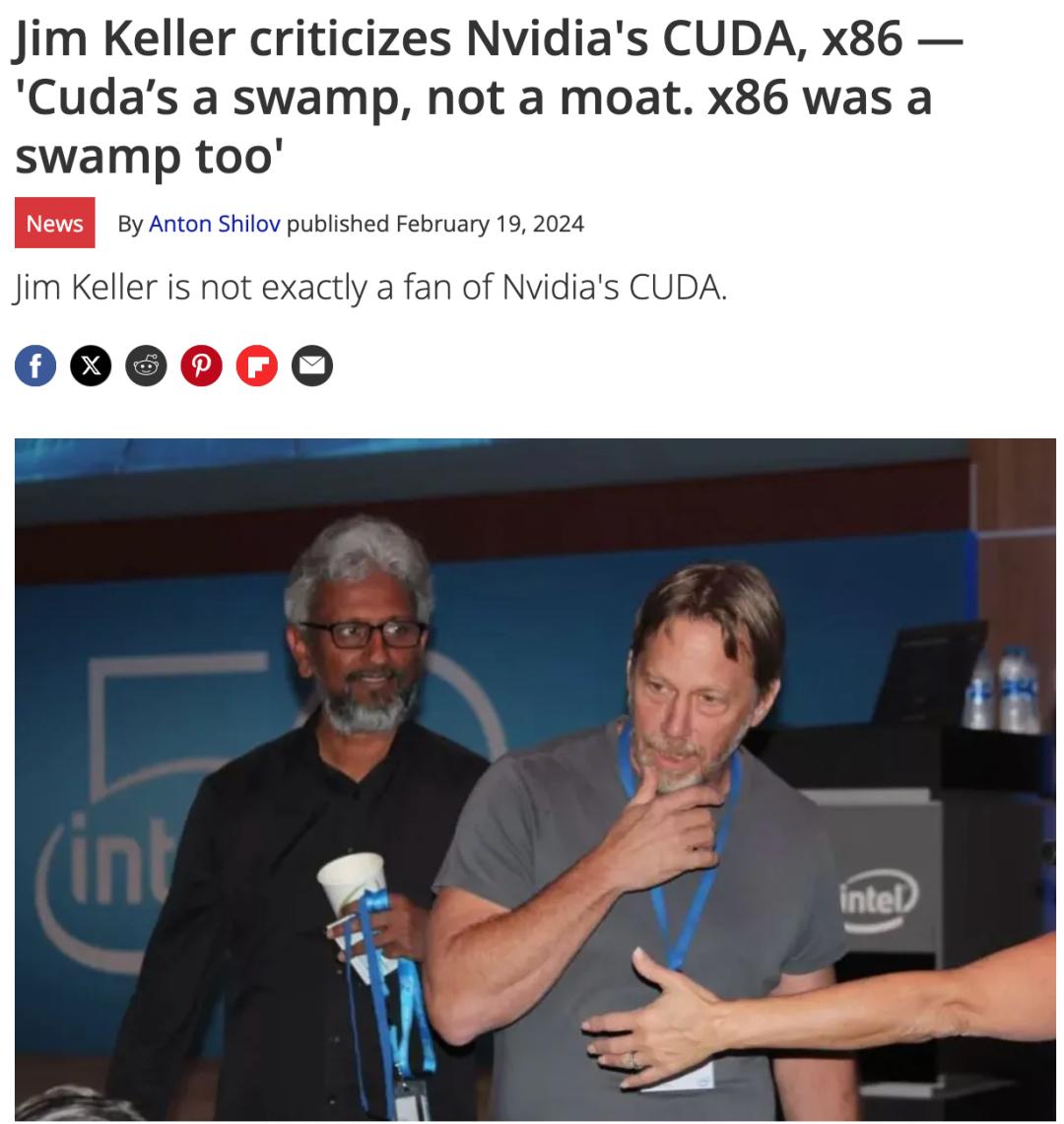
Jim Keller本人一点不喜欢CUDA,称CUDA为「沼泽」,意指其复杂性让开发者深陷其中无法脱身。
综上所述,英伟达并没有拆除护城河,而是将护城河的墙修得更漂亮、更易于攀爬(进入),但在墙内构建了更舒适的迷宫(Tile IR生态),使得用户更不愿意离开。
瓦片架构使AI内核在英伟达硬件之间极易移植,但在不同厂商硬件之间更难移植。
Jim Keller也许是对的,CUDA曾经是沼泽。
但英伟达刚刚在沼泽上铺设了一条高速公路(CUDA Tile IR)。
而这条路,目前只通向英伟达的城堡。
参考资料:
https://x.com/jimkxa/status/1997732089480024498
https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware/
https://developer.nvidia.com/blog/nvidia-cuda-13-1-powers-next-gen-gpu-programming-with-nvidia-cuda-tile-and-performance-gains
https://developer.nvidia.com/blog/simplify-gpu-programming-with-nvidia-cuda-tile-in-python
https://www.tomshardware.com/tech-industry/artificial-intelligence/jim-keller-criticizes-nvidias-cuda-and-x86-cudas-a-swamp-not-a-moat-x86-was-a-swamp-too
