

你我都知道,在AI的趋势下,所有芯片都在疯狂涨价。在AI狂野发展的过程中,无疑有着巨大的算力缺口,英伟达也成了当下最赚钱的公司。不过,随着地缘政治摩擦日益加重,很多人关注AI芯片的发展。
数据显示,我国AI芯片,将在2028年进入万亿市场规模时代,约占全球市场的30%。可以说,面对旺盛的市场需求,提供自主可控的高质量AI算力,已成为我国抢占AI发展先机、赋能千行百业转型升级的重要基础。
近期,多家国产厂商接连宣布AI芯片的消息,我国AI芯片正在以惊人的速度高速发展。
阿里:自研芯片亮相
早前,央视《新闻联播》中就曾预告,阿里即将自研PPU芯片,不过,很长时间以来,这款芯片都很神秘。
1月29日上午,平头哥官网悄然上线一款名为“真武810E”的高端AI芯片,这是通义实验室、阿里云和平头哥组成的阿里巴巴AI黄金三角“通云哥”首次浮出水面。
“真武”PPU采用全栈自研架构,配备96G HBM2e内存及700 GB/s片间互联带宽,适用于AI训练、推理及自动驾驶。目前,该芯片已大规模用于千问大模型的训练与推理,并通过阿里云AI软件栈深度优化,为客户提供一体化服务。
“真武”PPU已在阿里云实现多个万卡集群部署,服务了国家电网、中科院、小鹏汽车、新浪微博等400多家客户。
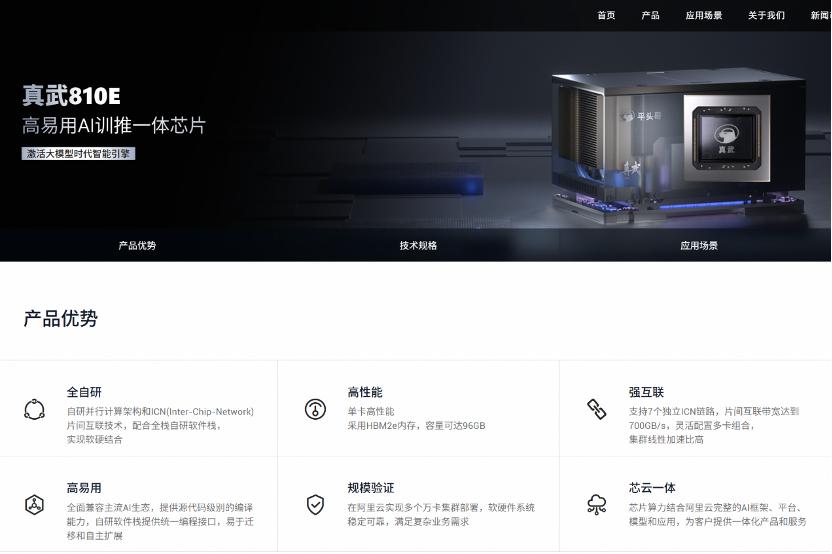
据业内分析,“真武”PPU整体性能超越英伟达A800及主流国产GPU,与英伟达H20相当。市场反馈显示,该芯片性能稳定、性价比高,处于供不应求状态。
阿里自2009年起布局云服务,2018年成立平头哥,2019年启动大模型研究,历经17年垂直整合,现已形成覆盖芯片、云平台与大模型的“通云哥”全栈AI的完整布局。目前,阿里与谷歌是全球仅有的同时在大模型、云服务与芯片三大领域具备顶尖实力的科技公司。
当然,阿里的未来也值得关注,据外媒最新报道,升级版“真武”PPU的性能强于英伟达A100。
奕行智能:首款RISC-V AI算力芯片
1月29日,国内AI芯片创企奕行智能表示,其研发的国内业界首款RISC-V AI算力芯片Epoch正在大规模量产出货中。该芯片在业界率先采用RISC-V + RVV指令集架构,结合自研的VISA技术,兼顾了AI计算的通用性与专用性。
奕行智能是类TPU的AI芯片。根据其分享,区别于单纯追求CUDA兼容的传统GPGPU路径。随着谷歌TPU等ASIC芯片在生态适配上的突破,以及英伟达在GPU中持续增强DSA特性,该方向正成为AI算力发展的重要趋势。
从性能上来看,其在运行ResNet-50、BERT、Llama 2等模型时,Epoch性能较竞品高出25%~52%;在FlashAttention-3等关键算子中算力利用率优势明显。

技术上,有三个关键点:一是率先采用RISC-V + RVV指令集构建AI芯片,保障通用计算能力的同时,支持定制AI指令,契合张量计算与稀疏计算需求,借助RISC-V全球生态,兼容主流编译器与AI框架;二是VISA虚拟指令架构,在软件与硬件间建立中间抽象层,隔离硬件迭代对上层软件的影响,提升编译效率,降低算子开发难度,兼顾计算的通用性与执行效率;三是Tile级动态调度架构,基于数据分块(Tile)编程范式,提供更友好的编程界面,通过硬件调度与编译器协同,实现动态资源调度,充分挖掘并行潜力,提升算力利用率。
生态肯定会是走这样一条路线必须考虑的问题。根据其分享,公司将持续完善软件栈,兼容主流AI框架,并通过与开源社区合作,推动RISC-V DSA生态建设。基于类TPU的能效优势与自主技术创新,奕行智能有望在AI算力竞争中实现差异化突破。
天数:公布四代AI芯片路线图
1月26日,国产GPU企业天数智芯在合作伙伴大会上发布四代架构路线图,可以看出这家公司的野心很大。
路线图显示,其计划在2025年推出的“天枢”架构将超越英伟达Hopper;2026年的“天璇”架构对标Blackwell,同年的“天玑”架构将实现超越;2027年的“天权”架构目标超越Rubin;2027年后将转向突破性计算芯片设计。

天数智芯介绍了四代架构的关键细节:
天枢架构:支持从高精度科学计算到AI精度计算,在执行注意力机制时算力有效利用率超过90%;
天璇架构:新增ixFP4精度支持;
天玑架构:实现全场景AI与加速计算覆盖;
天权架构:融入更多精度支持与创新设计。
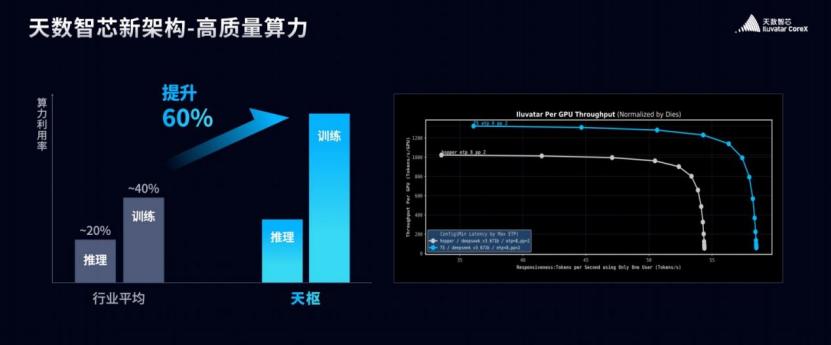
针对天枢架构,其通过三项核心技术创新显著提升了效率:
TPC广播机制:通过数据广播减少重复访存,等效提升带宽并降低功耗;
多指令并行处理系统:支持多类型指令并行处理,增强复杂任务处理能力;
动态线程组调度系统:通过动态调度避免资源争抢,提升计算资源利用率。
这些创新使天枢架构的效率较行业平均水平提升60%,在DeepSeek V3场景中的平均性能比英伟达Hopper架构高出约20%。
曦望:公布三年产品路线图
曦望(Sunrise)这家公司可能你没有听说过,但商汤你一定听说过,这家公司的前身便是商汤大芯片部门,2024年底分拆独立运营。这家公司在1月28日,也公布了自己的产品路线。
根据其路线图,国内首款采用LPDDR6的GPGPU芯片的启望S3今年上市,高性能推理GPU芯片启望S4将于2027年上市,安全可控推理GPU芯片启望S5将于2028年上市。
其前两代产品,2018年研发的S1(视觉推理芯片)已实现IP授权予索尼、小米,2020年实现上万片量产;2021年流片的S2(高性能GPGPU)则在主流大模型推理性能上达到国际巨头80%水平,软件栈CUDA兼容性达95%。

启望S3是本次发布的重点,核心设计理念是追求真实业务场景下的单位token成本、能耗与稳定性最优,而非单纯追求峰值算力。相比上一代产品,单芯片推理性能提升5倍,单位token推理成本下降约90%。
技术亮点上,S3支持FP16至FP4多精度灵活切换,契合MoE、长上下文等模型推理需求;国内首款采用LPDDR6的GPGPU推理芯片,显存带宽、容量显著提升;遵循大模型“算力访存比”黄金原则,实现资源高效利用;采用先进工艺节点与第三方高速接口IP。
围绕S3,曦望推出寰望SC3超节点解决方案,面向千亿/万亿参数模型的推理部署,支持单域256卡一级互联,适配大专家并行(EP)等复杂场景。在大EP部署下,吞吐率可提升20~25倍。采用全液冷设计,支持模块化快速部署。在同等算力下,可将系统整体交付成本从“亿元级”降至“千万元级”。
软件兼容性上构建了高度兼容CUDA的基础软件体系,支持驱动、算子库、通信库等,已适配国内外百余种主流大模型。推理云平台上,通过与商汤、范式等伙伴合作,构建以MaaS(模型即服务)为核心的推理云平台。
遂原:即将IPO
1月22日,上海AI芯片公司燧原科技的科创板IPO申请获上交所受理。该公司成立于2018年3月,已自主研发并迭代了四代架构、共五款云端AI芯片。
根据产品规划,燧原科技计划在2025年发布第四代AI推理卡及ESL32/64超节点集群,2027年推出第五代云端AI芯片及相关训推产品,并于2029年发布第六代系列芯片。目前,公司已构建涵盖AI芯片、加速卡及模组、智算系统与集群,以及AI计算软件平台的完整产品体系。
国产AI芯片大爆发
自美国实施AI芯片限制后,中国自主AI芯片产业加速发展。目前,国内AI芯片主要分为GPU与非GPU两大技术路线,近期均呈现快速发展态势。
国内GPU企业近期迎来上市热潮,并依据团队背景形成不同派系:
NVIDIA系:代表企业有摩尔线程、天数智芯,这些企业创始人和核心人员都有NVIDIA基因,打法是优先兼容CUDA生态切入市场,再通过自研架构不断发展;
AMD系:代表企业有壁仞、沐曦,创始人和核心人员都有AMD基因,AMD作为英伟达挑战者,一直以差异化为竞争核心,这些流派玩家打法和AMD类似;
国家队:比如景嘉微创始人及核心团队均来自国防科技大学,通过军用图形显控起步稳扎稳打进入信创市场,并不断拓展至AI计算领域,再比如海光、龙芯、兆芯研究集成GPU与CPU配合;
拆分系:商汤作为AI公司,2024年底也拆分独立了曦望Sunrise公司,此前公司刚完成近10亿元融资,主要围绕自己AI产品进行开发产品。
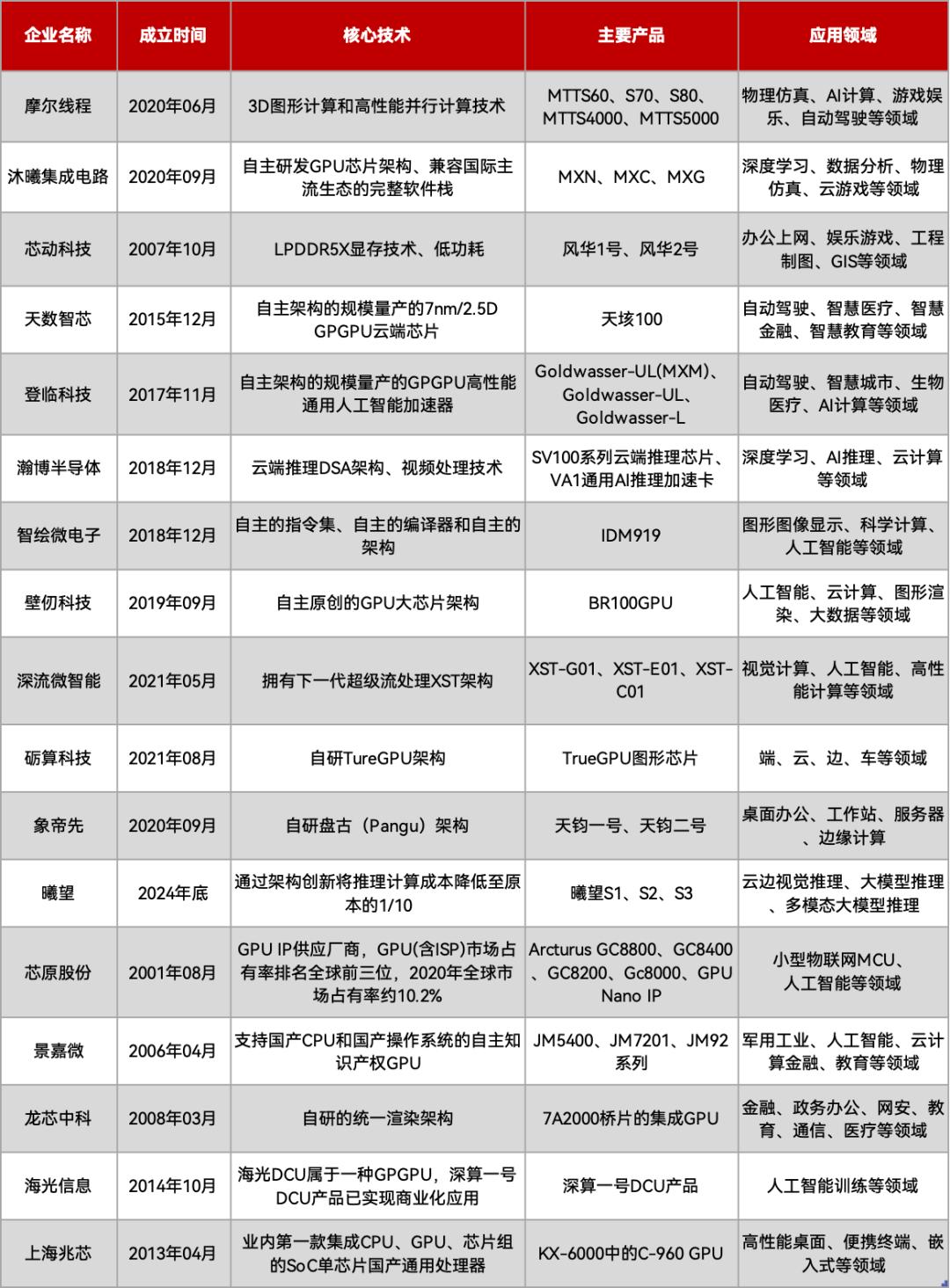
国产GPU不完全盘点,制表丨EEWorld
非GPU路径呈现多元化发展,不同企业选择不同架构以实现差异化竞争:
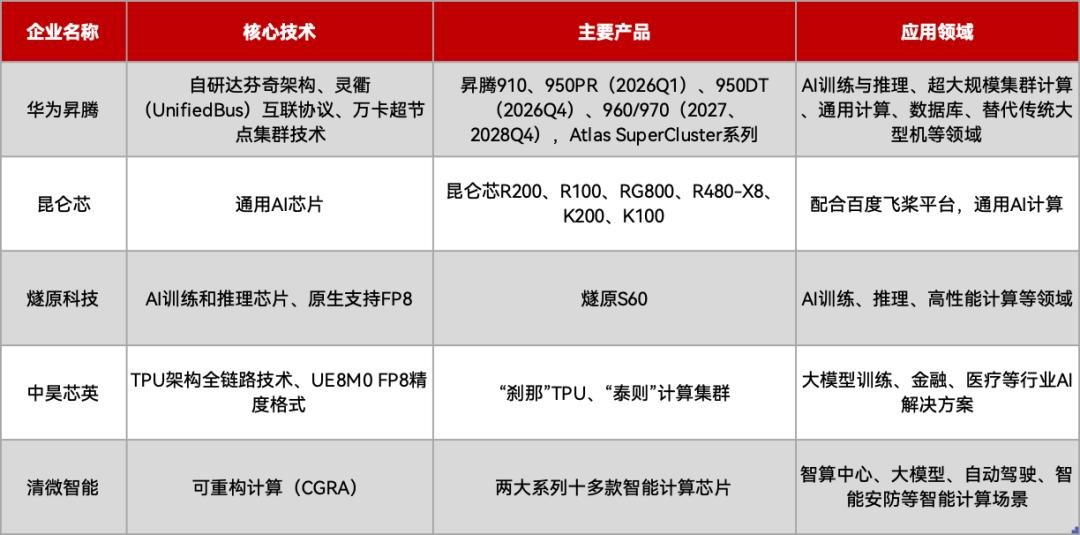
国产非GPU AI芯片不完全盘点,制表丨EEWorld
当前,国产AI芯片正通过 “兼容追赶” 与 “创新超越” 双轨并行的策略快速发展:GPU路线直面生态挑战,通过资本市场支持持续投入,力图在主流赛道上实现突破;非GPU路线(如CGRA、TPU、ASIC等)则通过架构创新,在能效、成本或特定场景上建立优势,开辟新赛道。
随着AI芯片这条路线的入局玩家增加,国产AI芯片的市场更加热闹了。
